强化学习推荐系统:不同的探索策略——高斯探索策略(4.2)
阅读《强化学习与大模型推荐系统》应具备一定的深度学习和推荐系统技术基础,适合于对大模型和强化学习推荐技术感兴趣的读者学习参考。
《强化学习与大模型推荐系统》全书下载地址:https://github.com/ByShui/Book_RL-LLM-In-RS。
强化学习推荐系统:不同的探索策略——高斯探索策略(4.2)
一个优秀的探索策略要能够同时满足探索和利用的需求,以下代码构造了一个具有5个动作的策略评估环境,以此来对不同探索策略的累计遗憾值进行分析:
class Bandit:def __init__(self, arm_count):self.arm_count = arm_countself.generate_arms()def generate_arms(self):self.arms = []for _ in range(self.arm_count):mean = np.random.normal(0, 1)std_dev = np.random.uniform(0.5, 1.5)self.arms.append((mean, std_dev))def reward(self, arm):mean, std_dev = self.arms[arm]return np.random.normal(mean, std_dev)def optimal_arm(self):return np.argmax([mean for mean, _ in self.arms])if __name__ == "__main__":arm_count = 5bandit = Bandit(arm_count)
具体来说,策略评估环境中设置了5个臂,摇动臂的奖励rewarda\text{reward}_arewarda服从不同的正态分布:rewarda=N(μ,σ)\text{reward}_a=\mathcal{N}(\mu,\sigma)rewarda=N(μ,σ)其中,μ\muμ和σ\sigmaσ分别是正态分布的均值和方差,它们是随机生成的。定义拥有最大均值的动作是最优动作a∗a_*a∗,最优价值V∗V_*V∗从最优臂的价值分布中采样得到。
优化策略需要牺牲短期利益,因为需要通过探索搜集更多的信息以获得更优的动作,使得智能体最终能够获得更多回报。探索和利用是强化学习中的一对矛盾体,这意味着在学习过程中,智能体需要在已知和未知的情况下做出最优的决策。
其中,利用是指在已知情况下选择已知最优的策略来获得收益,而探索是指在未知情况下,为了获取更多的信息和收益,选择不同的策略进行尝试。
探索是指在不确定性的环境中,探索新的策略或动作来获得更高的奖励或效用,包含两个部分:一是尝试未知的行为,以期找到更好的策略并更新模型;二是平衡已知和未知的行为,以确保不会错过可能的好策略。
在推荐系统中,探索可以包括推荐新的项目、向用户提供个性化的推荐建议或者探索不同的推荐策略(如多臂机)。探索和利用需要平衡,以确保推荐系统具有长期的优化效果。
一个标准的强化学习算法包括探索和利用两个步骤——探索帮助智能体充分了解其状态空间,利用则帮助智能体找到最优的动作序列。
用来平衡探索和利用的方法包括:贪心探索策略、高斯探索策略、UCB探索策略、玻尔兹曼探索策略、汤普森采样探索策略和熵正则化探索策略等,本篇博客我们介绍一下高斯探索策略。
贪心探索策略请查看:强化学习推荐系统:不同的探索策略——贪心探索策略(4.1)
高斯探索策略
高斯探索策略是一种广泛应用于确定性策略的探索方法,它通过向确定性策略中加入随机噪声来实现探索:a∼π(s)+ϵϵ∼N(0,σ)\begin{aligned} a&\sim \pi(s)+\epsilon \\ \epsilon&\sim\mathcal{N}(0,\sigma) \\ \end{aligned}aϵ∼π(s)+ϵ∼N(0,σ)
其中,利用由确定性的策略π\piπ完成,探索由服从正态分布的噪声ϵ\epsilonϵ完成。具体的做法是对每个动作的价值施加一个随机噪声:Qtnoise(a)=Qt(a)+ϵQ^{\text{noise}}_{t}(a)=Q_t(a)+\epsilonQtnoise(a)=Qt(a)+ϵ
然后,选取QtnoiseQ^{\text{noise}}_{t}Qtnoise最大的动作作为当前动作:at=arg maxa∈AQtnoise(a)=arg maxa∈A(Qt(a)+ϵ)\begin{aligned} a_t & = \argmax_{a\in A}Q^{\text{noise}}_{t}(a) \\ & = \argmax_{a\in A}(Q_t(a)+\epsilon) \\ \end{aligned}at=a∈AargmaxQtnoise(a)=a∈Aargmax(Qt(a)+ϵ)
如下代码实现了高斯探索策略:
def gaussian_exploration(bandit, T, sigma=1):arm_count = bandit.arm_countQ = np.zeros(arm_count)N = np.zeros(arm_count)cumulative_regret = [0]for t in range(1, T+1):noise = np.random.normal(0, sigma, arm_count)arm = np.argmax(np.add(Q, noise))reward = bandit.reward(arm)N[arm] += 1Q[arm] += (reward - Q[arm]) / N[arm]optimal_reward = bandit.reward(bandit.optimal_arm())cumulative_regret.append(cumulative_regret[-1] + (optimal_reward - reward))return cumulative_regretif __name__ == "__main__":arm_count = 5T = 1000bandit = Bandit(arm_count)cumulative_regret_gaussian_exploration = gaussian_exploration(bandit, T, sigma=0.5)
以上代码定义了gaussian_exploration()方法,它接收3个参数:
- bandit(一个多臂机实例);
- T(试验轮次,即在多臂机上探索/利用的轮次);
- sigma(超参数σ\sigmaσ,用于调整高斯噪声的标准差)。
我们在每轮试验中向臂的价值中加入高斯噪声,实现小幅度的探索。相比于ϵ\epsilonϵ-贪心策略,高斯探索策略可以有效收敛到最优臂,因为当臂之间的价值差距大于所设定σ\sigmaσ的3倍时,施加的噪声几乎不会影响最优臂的排名(3σ\sigmaσ原则),为了加大前期探索,超参数σ\sigmaσ也可以设置为随试验轮次衰减。
高斯探索策略的应用不局限于探索,在强化推荐中,如果状态和项目都是向量化的,那么可以利用高斯探索策略在训练过程中施加随机性,以得到更具健壮性的推荐策略。
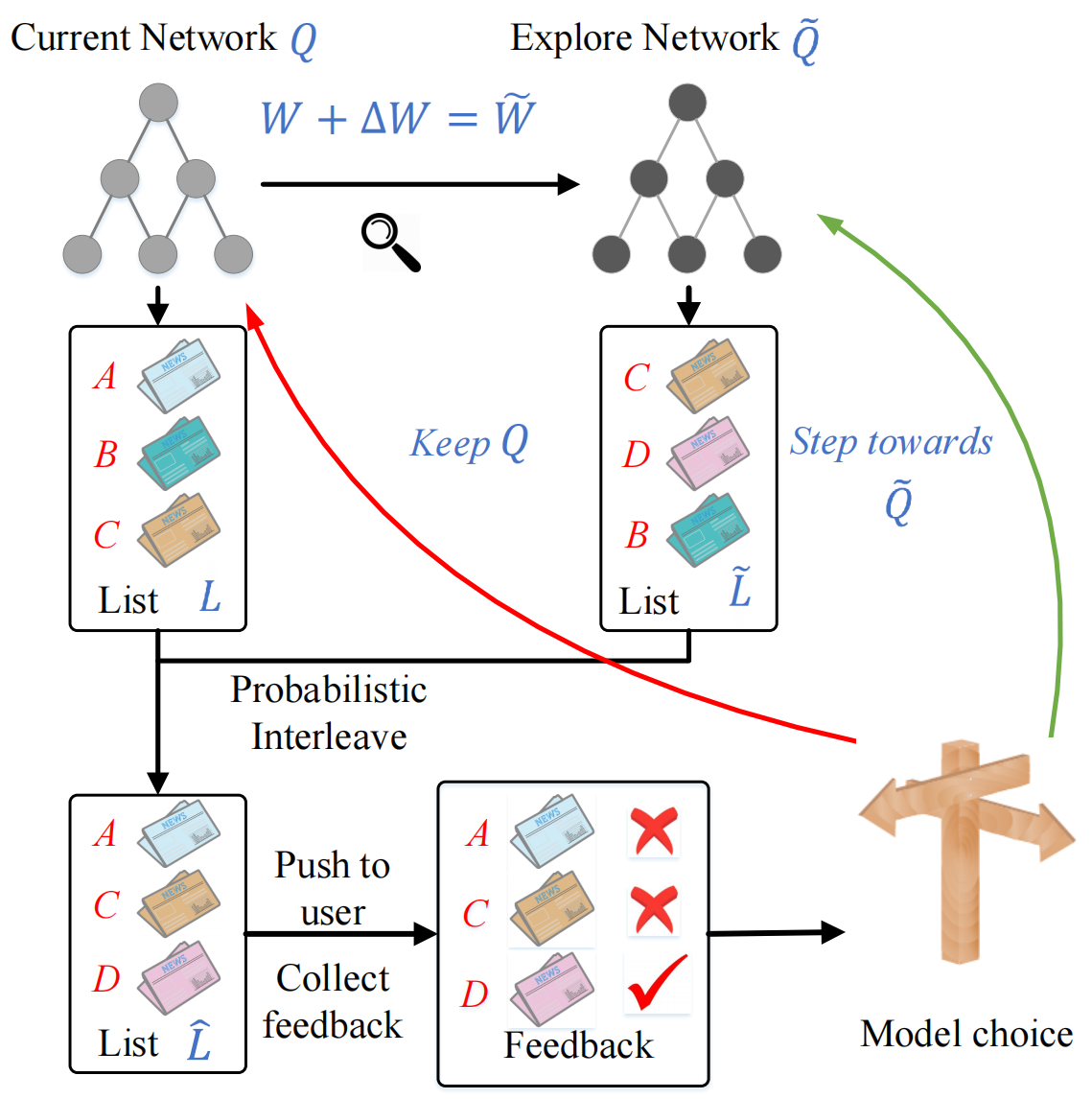
例如DRN算法中使用的DBGD探索方法维持了一个探索网络,探索网络的参数W~\tilde{W}W~由当前网络的参数WWW施加随机干扰ΔW\Delta WΔW得到。在进行推荐时,当前网络和探索网络同时产生推荐列表,然后将这两个列表通过概率交错的方式混合排序展示给用户:ΔW=α⋅rand(−1,1)⋅WW~=W+ΔW\begin{aligned} \Delta W&=\alpha \cdot \text{rand}(-1,1)\cdot W \\ \tilde{W}&=W+\Delta W \\ \end{aligned}ΔWW~=α⋅rand(−1,1)⋅W=W+ΔW
其中,α\alphaα是一个超参数,rand(−1,1)\text{rand}(-1,1)rand(−1,1)指的是区间为(-1,1)的随机数,随机干扰ΔW\Delta WΔW在当前网络的参数WWW的基础上应用权重α⋅rand(−1,1)\alpha \cdot \text{rand}(-1,1)α⋅rand(−1,1)计算得到。