目录
- 简介
- 核心概念
- 训练数据结构
- 两大类型
- 1. 分类问题(Classification)
- 2. 回归问题(Regression)
简介
- 监督学习的核心特点是使用带标签的训练数据来训练模型,简单来说,就是通过输入xxx(特征)推导出输出yyy(标签),算法的目标是学习从输入到输出的映射关系,以便于对新的、未见过的数据进行预测。
核心概念
训练数据结构
- 特征(features):输入变量,用xxx表示
- 标签(labels):目标变量,用yyy表示
- 训练集:包含特征和标签的数据集合
两大类型
1. 分类问题(Classification)
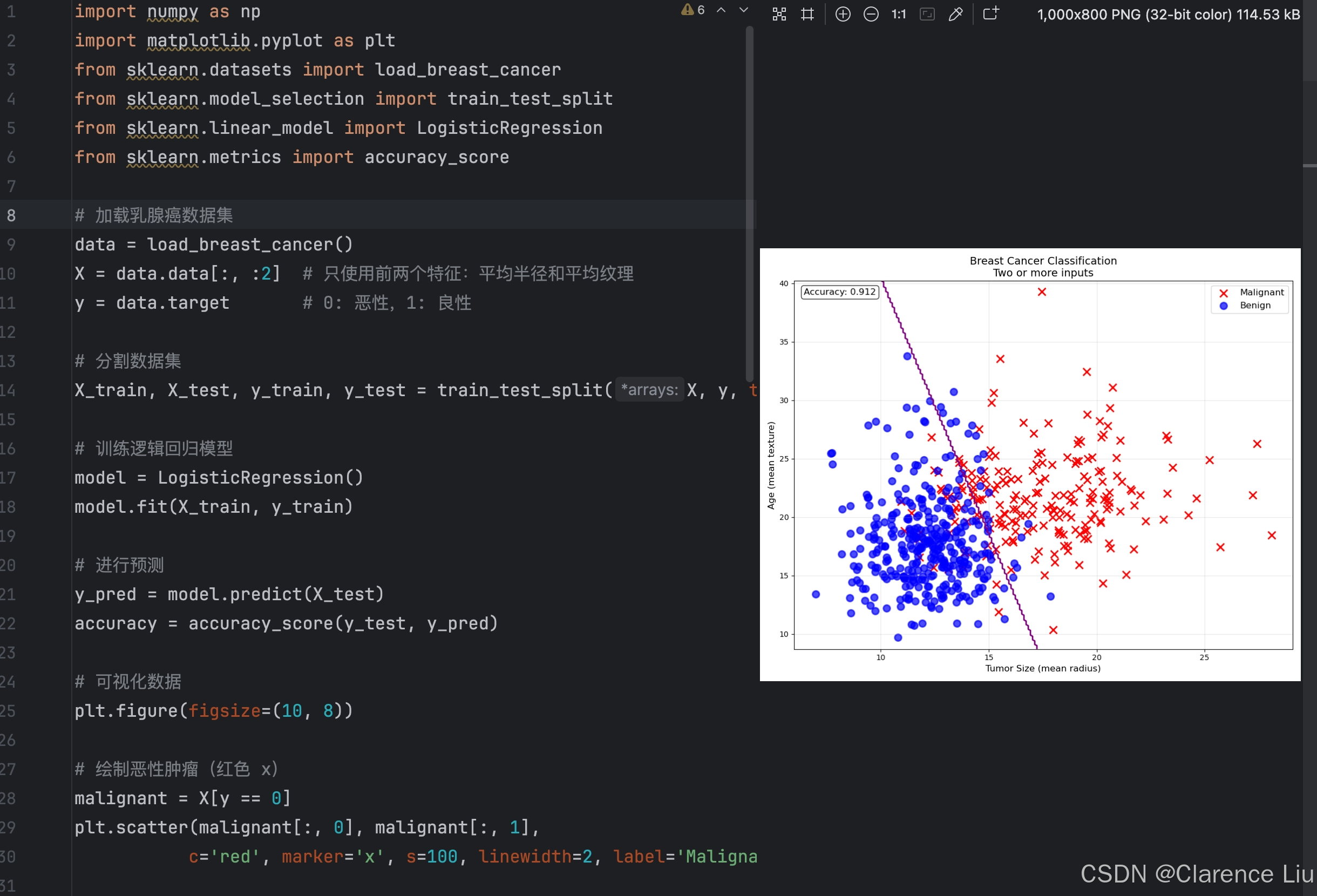
- 分类问题是要找到一条拟合的边界线 ,把两种类别的数据划分开来
- 下面使用一个测试用的乳腺癌数据集来演示分类问题,想通过平均半径和平均纹理来寻找判断良性和恶性肿瘤的划分方式
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
X = data.data[:, :2]
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
plt.figure(figsize=(10, 8))
malignant = X[y == 0]
plt.scatter(malignant[:, 0], malignant[:, 1],c='red', marker='x', s=100, linewidth=2, label='Malignant')
benign = X[y == 1]
plt.scatter(benign[:, 0], benign[:, 1],c='blue', marker='o', s=80, alpha=0.7,facecolors='none', edgecolors='blue', linewidth=2, label='Benign')
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0.5], colors='purple', linewidths=2)
plt.xlabel('Tumor Size (mean radius)', fontsize=12)
plt.ylabel('Age (mean texture)', fontsize=12)
plt.title('Breast Cancer Classification\nTwo or more inputs', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
plt.text(0.02, 0.98, f'Accuracy: {accuracy:.3f}',transform=plt.gca().transAxes, fontsize=12,verticalalignment='top', bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))plt.tight_layout()
plt.show()
print(f"数据集形状: {X.shape}")
print(f"恶性样本数量: {np.sum(y == 0)}")
print(f"良性样本数量: {np.sum(y == 1)}")
print(f"模型准确率: {accuracy:.3f}")
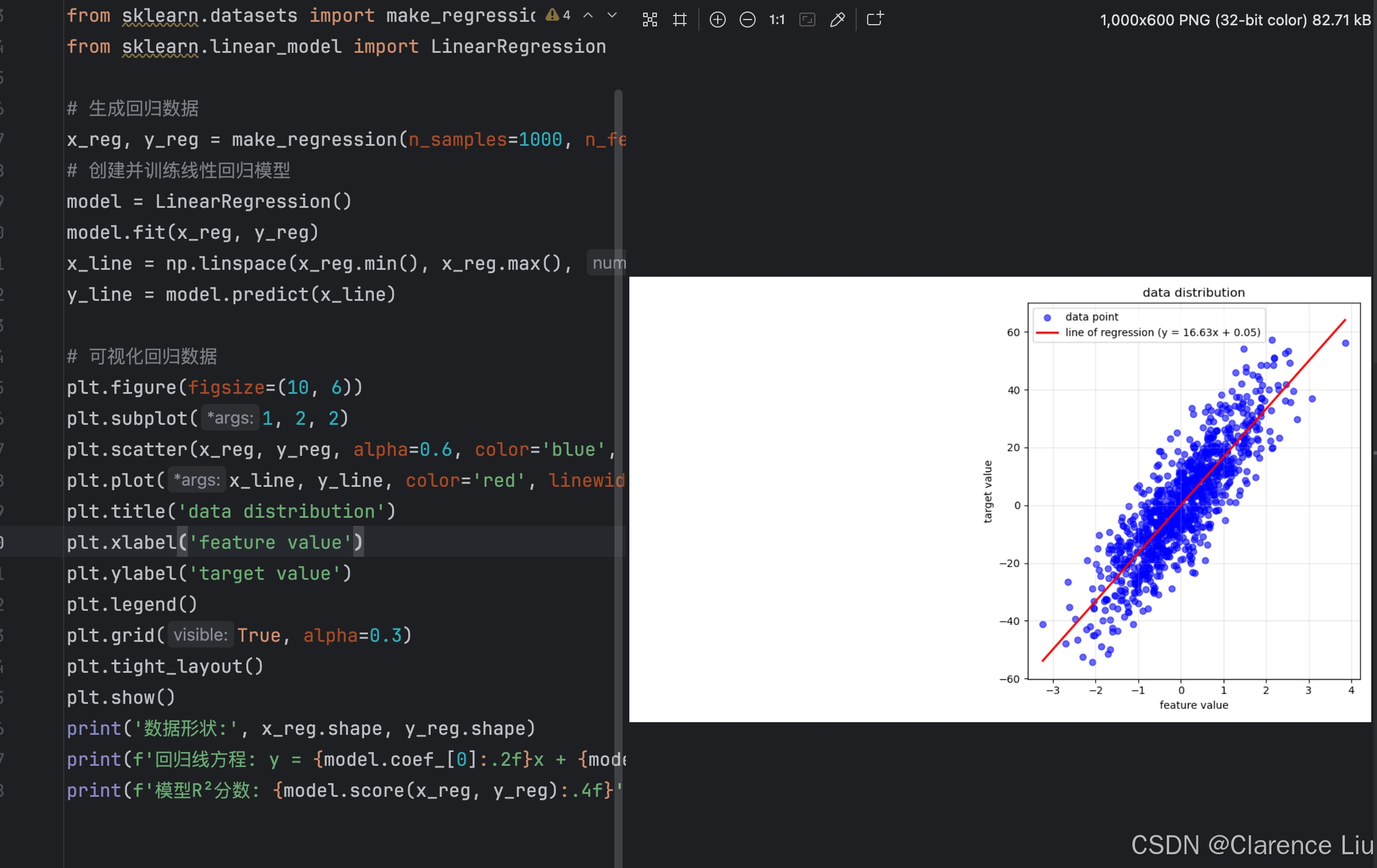
2. 回归问题(Regression)
- 下面是一个回归的例子,通过一些数据,得到xxx和yyy之间的映射关系
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
x_reg, y_reg = make_regression(n_samples=1000, n_features=1, noise=10, random_state=42)
model = LinearRegression()
model.fit(x_reg, y_reg)
x_line = np.linspace(x_reg.min(), x_reg.max(), 100).reshape(-1, 1)
y_line = model.predict(x_line)
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 2)
plt.scatter(x_reg, y_reg, alpha=0.6, color='blue', label='data point')
plt.plot(x_line, y_line, color='red', linewidth=2, label=f'line of regression (y = {model.coef_[0]:.2f}x + {model.intercept_:.2f})')
plt.title('data distribution')
plt.xlabel('feature value')
plt.ylabel('target value')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print('数据形状:', x_reg.shape, y_reg.shape)
print(f'回归线方程: y = {model.coef_[0]:.2f}x + {model.intercept_:.2f}')
print(f'模型R²分数: {model.score(x_reg, y_reg):.4f}')