音视频处理(二): 一文讲清楚音频处理流程:采样、压缩和播放
文章目录
- 一、前言
- 二、音频采样
- 2.1 模数转换-量化
- 2.1.1 采样率
- 2.1.2 采样大小(位深)
- 2.1.3 声道数
- 2.2 采集数据的保存
- 2.2.1 PCM数据格式
- 2.2.2 WAV文件格式
- 三、音频压缩
- 3.1 码率
- 3.2 音频压缩
- 3.2.1 有损压缩
- 3.2.1.1 频域掩蔽
- 3.2.1.2 时域掩蔽
- 3.2.1.3 核心有损压缩算法
- 3.2.1.4 关键技术实现
- 3.2.2 无损压缩
- 3.2.2.1 主要无损格式对比
- 3.2.3 音频压缩算法性能对比
- 3.2.3.1 音质与码率关系
- 3.2.3.2 计算复杂度比较
- 3.2.3.3 延迟特性
- 3.2.4 音频压缩技术发展轨迹与趋势
- 3.2.4.1 技术演进历程
- 3.2.4.2 未来发展趋势
- 3.2.4.3 总结与工程实践建议
- 四、音频播放
- 4.1 重采样-多退少补
- 4.2 ffmpeg音频重采样
- 4.2.1 命令行方式
- 4.2.2 编程方式(使用 Swresample 库)
- 4.2.3 重要注意事项
- 五、总结
- 六、参考资料
一、前言
当前音视频技术很火,在IPC、无人机、手机、直播等各行各业都需要用到音视频技术,本文针对音频处理全流程:采样、数据保存、压缩、播放做一个详细介绍。
- 音频源端处理流程
- 播放端处理流程
二、音频采样
2.1 模数转换-量化
音频采集设备产生的是模拟电平数据,计算机中存储的是数字信号,需要进行采样、量化成数字信号。音频采样有如下几个参数:
- 采样率
- 位深
- 通道数
2.1.1 采样率
以一段声音信号为例,我们按固定时间间隔(如每0.25单位)进行采样,采样时间频率就是采样率。
那这里有几个常见的:一个是8K,第二16K,32K,44.1K,48K,这都是我们常见的采样率。采样率越高,我们的数字信号与模拟信号之间的模仿的就越接近,它的误差就越小。采样率越低,有一些很敏感的信息就忽略掉了。对于我们通常打电话来说,一般都是8K的采样率,是有一些失真的。但是如果你是48K的这个采样率,实际基本上就完全还原了人的这个声音,和面对面的说话音质基本接近。
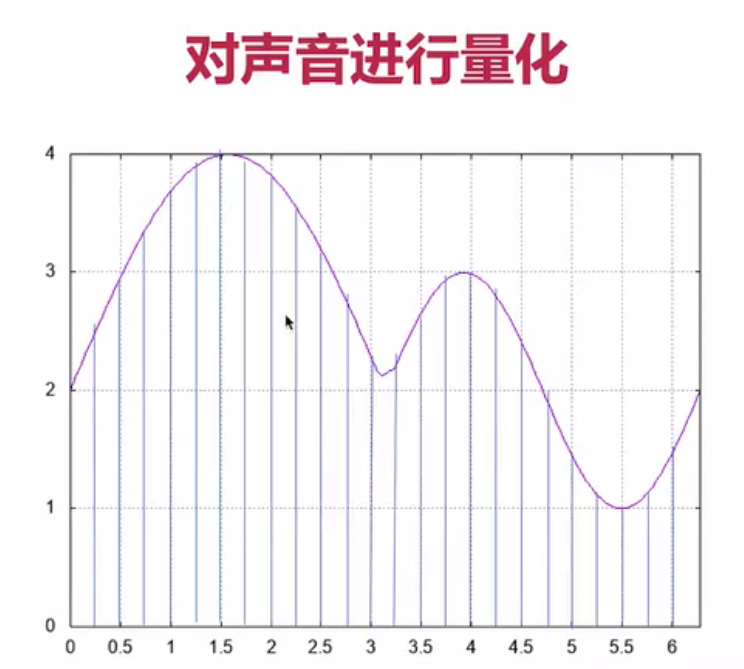
一般通话时的采样率为8KHz,常用的媒体采样率有44KHz,对于一些蓝光影片采样率高达1MHz。
- 48000 Hz(48k)
- 44100 Hz(44.1k)
- 32000 Hz
- 16000 Hz
- 8000 Hz(最低常用值)
2.1.2 采样大小(位深)
采样大小,或者叫做位深,每个采样值用多少位的数据表示,如8bit、16bit等,位深越大,声音越清晰细腻。最常见的是16位的位深,那表示的范围是-32768到32768。
2.1.3 声道数
声道数分为单声道、双声道和多声道(立体声)
2.2 采集数据的保存
2.2.1 PCM数据格式
采集到的音频原始数据是以二进制形式在计算机中存储传输的,比如音频采集设备和CPU之间就是通过二进制方波进行传输。这些二进制数据其实就是PCM数据,PCM(脉冲编码调制),所谓脉冲:指的是音频原始采样量化后的数据,像一个个脉冲。调制指的是将十进制数据转换成二进制数据传输。
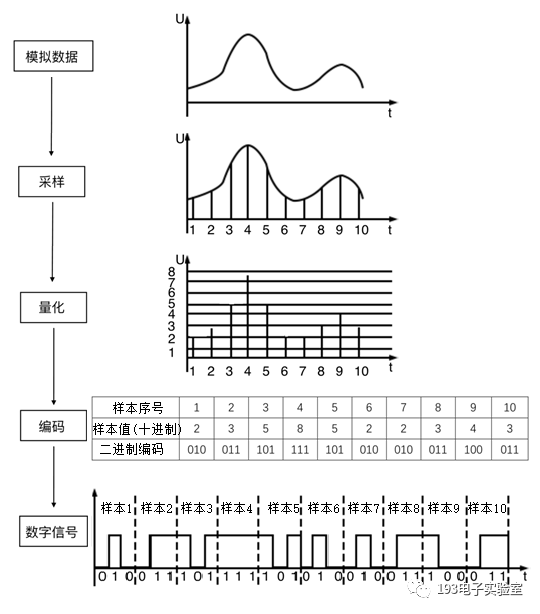
如果是多通道的数据,PCM数据是交叉排列:
+---------+-----------+-----------+-----------+-----------+----FL | FR | FL | FR | FL |
+---------+-----------+-----------+-----------+-----------+----
PCM数据是原始数据流,是不包含描述信息的比如通道、采样率、位深等信息。在设备之间传输时需要先传输额外的描述信息,比如CPU和MIC直接传输时,音频驱动会设置好采样率等信息。但是通过网络传输,或者跨设备之间传输,描述信息回丢失,导致音频数据无法播放。所以需要文件形式保存,加上额外的描述头信息,这就是WAV数据格式。
2.2.2 WAV文件格式
WAV是文件格式,在PCM的基础上增加描述信息,便于传输。WAV文件一般保存的是未经压缩的数据,所以文件是较大的,当然也可以保存压缩数据,由头部字段控制。但大多数情况下 99% 我们都用WAV来存储PCM原始数据。
头部保存哪些音频关键信息?
在讲解文件格式前,从原理方面先想一下如果让我们设计一个文件头格式,该如何设计,其实就是搞清楚音频解码时需要哪些关键信息:
音频量化信息:
1) 采样率
2)位深
3)通道数4)数据压缩格式
5)数据长度
6) 时长
- RIFF格式,3个trunk
WAV文件遵循RIFF文件规范,RIFF(Resource Interchange File Format) 是windows平台广泛使用的文件规范。它基本单位是trunk,每个trunk描述一个类型的资源,用ID表示类型,size表示trunk数据的大小。RIFF文件有一个公共的头RIFF头,其中使用asiic码WAVE表示WAV文件类型。 WAV另外还有两个trunk:fmt和trunk
| trunk | 说明 |
|---|---|
| RIFF trunk | RIFF文件通用头,WAVE表示WAV文件 |
| fmt trunk | 音频描述信息,fmt表示音频格式。保存量化信息:采样率、位深、通道数 |
| data trunk | 音频数据信息,保存PCM数据 |
 |
WAV也可以保存音频压缩数据,但是常见的是PCM,文件头中的AutioFormat编码格式取值如下:
| 格式编码 | 格式名称 | fmt 块长度 | fact 块 |
|---|---|---|---|
| 0x01 | PCM / 非压缩格式 | 16 | |
| 0x02 | Microsoft ADPCM | 18 | √ |
| 0x03 | IEEE float | 18 | √ |
| 0x06 | ITU G.711 a-law | 18√ | |
| 0x07 | ITU G.711 μ-law | 18√ | |
| 0x031 | GSM 6.10 | 20 | √ |
| 0x040 | ITU G.721 ADPCM | √ | |
| 0xFFFE | 见子格式块中的编码格式 | 40 |
音频的量化参数使用fmt trunk来表示,那么时间长度是如何保存的呢?
音频时长参数不用额外记录,根据采样频率,按照采样频率顺序往下播放就可以。
- 查看原始数据
hd /home/share/samba/sample-15s.wav -n 128
00000000 52 49 46 46 24 9c 33 00 57 41 56 45 66 6d 74 20 |RIFF$.3.WAVEfmt |
00000010 10 00 00 00 01 00 02 00 44 ac 00 00 10 b1 02 00 |........D.......|
00000020 04 00 10 00 64 61 74 61 00 9c 33 00 0f f8 0f f8 |....data..3.....|
00000030 f3 fb f3 fb 66 0a 66 0a 49 09 49 09 83 fc 83 fc |....f.f.I.I.....|
00000040 fd fd fd fd b2 06 b2 06 b1 03 b1 03 86 02 86 02 |................|
00000050 f5 0c f5 0c 85 0d 85 0d fc 02 fc 02 8f 06 8f 06 |................|
00000060 d2 12 d2 12 11 0e 11 0e 02 01 02 01 a9 02 a9 02 |................|
00000070 9b 09 9b 09 2e 05 2e 05 4c 02 4c 02 53 09 53 09 |........L.L.S.S.|
00000080
说明:
- 52 49 46 46:对应的 ASCII 字符为 `RIFF`
- 24 9c 33 00:ChunkSize,对应的十六进制是 0x339c24=3382308 + 8 和上面的文件大小一致
- 57 41 56 45:对应的 ASCII 字符为 `WAVE`
- 66 6d 74 20:对应的 ASCII 字符为 `fmt`
- 10 00 00 00:FmtSize 0x10=16 代表 PCM 编码方式
- 01 00:对应为 1,代表 PCM 编码方式
- 02 00:通道个数,通道数为 2
- 44 ac 00 00:采样频率 0xac44=44100=44.1KHz
- 10 b1 02 00:传输速率,转化为十六进制为: 0x2b110=176400 通过此值可以计算该音频的时长:3382308/176400 = 19.174s
- 04 00:数据对齐单位
- 10 00:采样位数 0x10=16
- 64 61 74 61:对应的 ASCII 字符为 `data`
- 00 9c 33 00:对应该音频的 raw 数据的大小,转化为十六进制为 0x339c00=3382272,此值等于 0x339c24 - 44
三、音频压缩
3.1 码率
码率bitrate指的是音频播放时的数据吞吐量速率,实时直播的场景时也表示网络传输的数据量大小,PCM未经压缩的数据,码率是比较大的。可以根据位深、采样率和通道数计算出码率信息。
码率 = 采样率x位深x通道数
例如,采样率44.1k,位深为16bit,通道数是2,那么码率=44.1k x 16 x 2 = 1411.2kb/s。已经是1.4Mbps的速率,是很大的,比如实时直播的场景,再加上视频数据,网络带宽占用很大,所以需要对音频数据进行压缩。
3.2 音频压缩
音频压缩技术是保证人耳听觉效果不失真的情况尽可能的压缩数据,分为:
- 有损压缩
- 无损压缩
音频压缩的本质是消除两种冗余信息:
- 统计冗余:音频信号在时域和频域上的相关性
- 感知冗余:人耳听觉特性无法感知的音频信息
3.2.1 有损压缩
有损压缩的核心是根据人耳的听觉效应,从原始数据中去掉一些人耳无法辨识的一些冗余信息。比如人耳有以下特性,以及对应的压缩算法处理。
心理声学基础:
1)人耳只能听到20-20KHz之间的声音,其他的听不到。 => 去掉低频和高频数据。
2)多个人说话只能听到声音大,高频会覆盖低频。=> 频率掩蔽。
3)人耳对不同频率的敏感度不同(如2-4kHz最敏感)。=> 其他频率低于阈值的信号可忽略。
4)短时间内出现的弱信号可能被强信号掩盖。=> 时域掩蔽。
下面重点讲一下频率掩蔽和时域掩蔽技术。
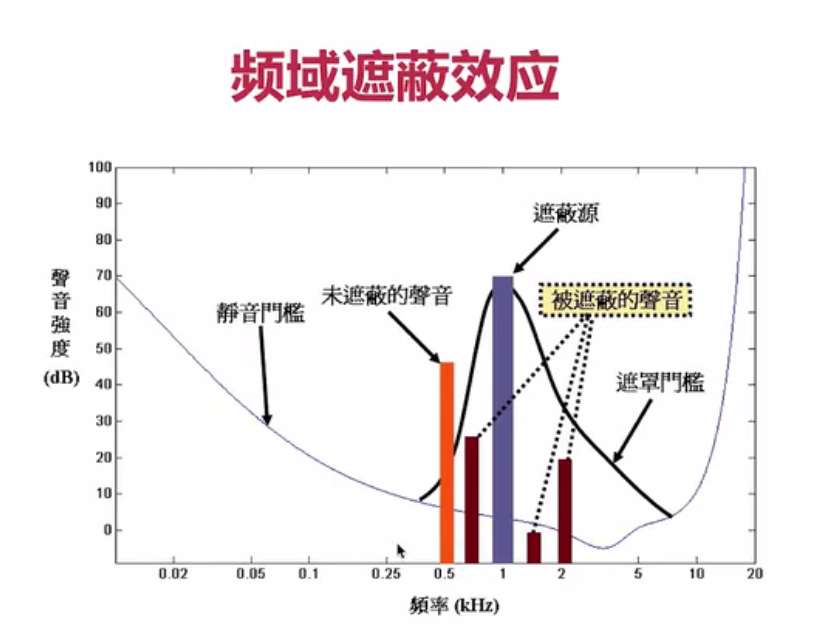
3.2.1.1 频域掩蔽
下图描述了频域遮蔽,音频数据是时域的,但是可以使用傅里叶变换转成频域的,频域上高频遮蔽低频信号。低于遮蔽源会产生一个遮罩门槛,低于遮蔽门槛的信号都被遮蔽掉,这些信号进行压缩时可以去掉。
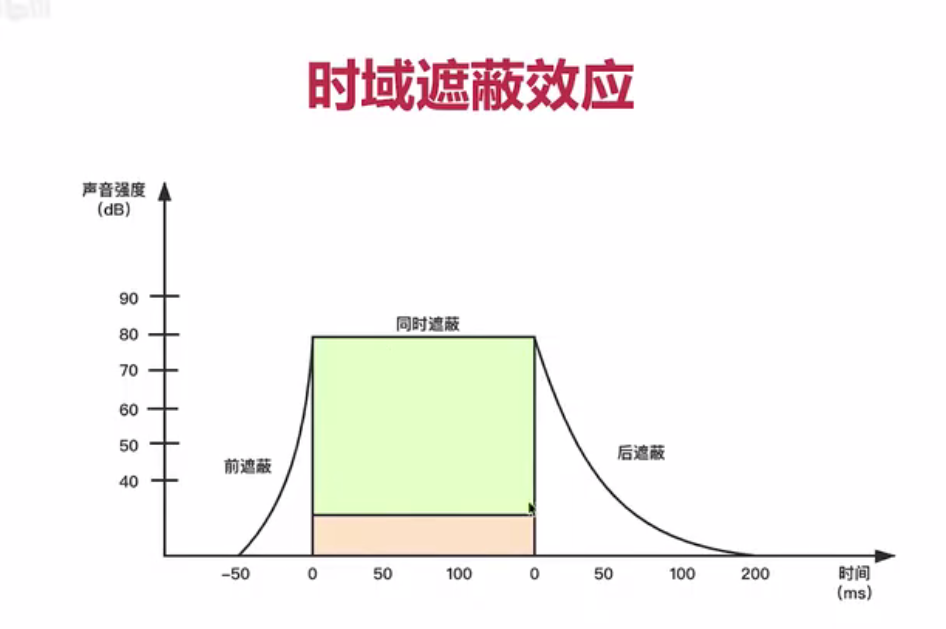
3.2.1.2 时域掩蔽
时域遮蔽表示遮蔽源的高频声音对时间前后的数据做一定影响,导致人耳听不到。前后时间内越靠近遮蔽源时间越容易被遮蔽,下图是时域遮蔽示意图。
3.2.1.3 核心有损压缩算法
下表对比了主流有损压缩算法的特点:
| 算法 | 压缩比 | 主要特点 | 应用场景 |
|---|---|---|---|
| MP3 (MPEG-1 Audio Layer III) | 10:1-12:1 | 使用MDCT变换和心理声学模型,兼容性极佳 | 音乐存储、网络音频传输 |
| AAC (Advanced Audio Coding) | 优于MP3(尤其在低码率下) | MDCT变换、预测编码、噪声整形,MP3的继任者 | iTunes、YouTube、iOS系统默认音频格式 |
| Ogg Vorbis | 比MP3高约30% | 完全开源,灵活的块大小和真VBR支持 | 开源软件、视频游戏 |
| Opus | 可变(支持低比特率语音到高保真音频) | 结合SILK(语音)和CELT(音频)算法,低延迟 | 实时通信、WebRTC默认音频编码 |
3.2.1.4 关键技术实现
- 感知编码:利用掩蔽效应,在强信号附近减少或删除弱信号的编码精度。
- 频域变换:通过MDCT(改进型离散余弦变换)将时域信号转换为频域表示,便于按频率子带分别处理。
- 量化与比特分配:根据心理声学模型动态分配比特资源,对重要频段高精度量化,次要频段粗量化。
- 立体声编码:利用左右声道的相关性,采用联合立体声、强度立体声等技术减少冗余。
3.2.2 无损压缩
无损压缩式是不会丢失原数据信息,常见的zip、gz都是属于无损压缩。音频无损压缩技术主要利用huffman编码,将高频出现的信息使用小的值表示建立查找表,减少占用空间。核心技术原理如下:
- 线性预测编码:利用音频信号的短时相关性,用过去样本预测当前样本,编码预测残差而非原始信号。 预测公式为:x1=∑i=1paix[n−i] 残差计算公式为:e[n]=x[n]−x2。这里和视频压缩h264编码中的I帧和P帧的概念类似,都是基于时间相关性保存差值的。
- 熵编码:根据符号出现概率分配变长码字,常见方法包括: Rice编码:专为小整数优化的Golomb-Rice编码,FLAC主要采用 霍夫曼编码:构造最优前缀码,用于ALAC、WAVPACK等格式。huffman编码主要是利用信息出现的频率进行
- 通道去相关:对立体声信号采用Mid/Side编码: Mid(中) = (L + R) / 2 Side(边) = (L - R) / 2。
3.2.2.1 主要无损格式对比
| 格式 | 压缩率 | 特点 | 应用领域 |
|---|---|---|---|
| FLAC | 30%-50% | 开源免费,硬件支持广泛,使用线性预测+Rice编码 | 音乐流媒体(Tidal)、数字音乐商店(Bandcamp) |
| ALAC | 近似FLAC | Apple专属格式,兼容苹果生态系统 | iOS、macOS设备 |
| WAVPACK | 可调 | 支持混合模式(有损+无损) | 特殊需求的音频归档 |
| APE | 较高 | 高压缩率但编解码效率较低 | 个人音乐收藏 |
3.2.3 音频压缩算法性能对比
实际应用中,算法选择需综合考虑多种因素:
3.2.3.1 音质与码率关系
- 有损压缩在128kbps以上码率通常能达到透明音质(大多数人无法区分与原始音频的差别)
- 无损压缩保持100%音质,但文件体积通常比同源有损压缩大3-5倍
3.2.3.2 计算复杂度比较
- 低复杂度:G.711、ADPCM(适合嵌入式系统和实时通信)
- 中复杂度:MP3、AAC(平衡压缩效率与计算需求)
- 高复杂度:Opus、无损编码(需要较高计算性能)
3.2.3.3 延迟特性
- 电话语音编码(G.723、G.729):延迟最低(5-30ms)
- 普通音频编码(MP3、AAC):中等延迟(50-100ms)
- 高质量无损编码:延迟较高(100ms以上)
3.2.4 音频压缩技术发展轨迹与趋势
了解技术演进历史有助于把握未来发展方向:
3.2.4.1 技术演进历程
- 早期波形编码(1980s前):G.711(64kbps)、ADPCM(32kbps)
- 第一代感知编码(1990s):MP3、MP2(MPEG-1 Layer 2)
- 第二代感知编码(2000s):AAC、Ogg Vorbis
- 现代通用编码(2010s至今):Opus(融合语音与音频编码)
3.2.4.2 未来发展趋势
- AI驱动编码:基于神经网络的音频编码器(如Lyra、SoundStream)
- 自适应码率:根据网络条件动态调整音频质量
- 沉浸式音频:支持三维声场的下一代编码技术
- 端侧智能编码:在设备端实现更高效的智能压缩
3.2.4.3 总结与工程实践建议
作为音视频开发工程师,在选择音频压缩算法时需要考虑以下因素:
- 应用场景需求:实时通信优先低延迟编码器(Opus),音乐存储考虑音质与体积平衡(AAC/FLAC)
- 目标平台兼容性:移动端考虑硬件解码支持,跨平台需测试兼容性
- 计算资源约束:嵌入式设备选择低复杂度算法,服务器端可考虑高质量但高复杂度编码
- 系统集成复杂度:评估编码器集成、许可协议、专利费用等非技术因素
四、音频播放
4.1 重采样-多退少补
音频播放设备支持的采样率等信息可能跟音频数据不一致,这时就需要重采样。重采样的的核心策略是“多退少补”。对于音频数据采样率低于播放设备的,采用插帧处理,copy一份相同数据播放。对于对于音频数据采样率高于播放设备的,丢弃一帧数据。
关键原则:保持时长不变
重采样过程中有一个至关重要的原则:音频的总播放时长不应改变 。这意味着,一段 10 秒的音频在经过重采样后,播放时长应该仍然是 10 秒。实现这一点的关键在于正确处理采样率和样本数量的关系。计算公式如下
输出样本数 = 输入样本数 × 输出采样率 / 输入采样率
FFmpeg 提供了 av_rescale_rnd函数来安全高效地完成这个计算,避免整数溢出。
4.2 ffmpeg音频重采样
FFmpeg 提供了强大的工具来进行音频重采样,既可以通过命令行快速完成,也可以通过 API 编程进行集成。
4.2.1 命令行方式
使用 FFmpeg 命令行工具可以非常便捷地完成重采样任务。基本命令格式如下 :
ffmpeg -ar <输入采样率> -ac <输入声道数> -f <输入采样格式> -i <输入文件> -ar <输出采样率> -ac <输出声道数> -f <输出采样格式> <输出文件>
参数说明 :
-ar:指定音频采样率(如 44100, 48000)。-ac:指定音频声道数(如 1 表示单声道,2 表示立体声)。-f:指定采样格式(如s16le,s32le,f32le)。
实例演示
将名为 44100_s16le_2.pcm的音频文件(44100 Hz, 16位有符号整数, 立体声)转换为 48000_f32le_1.pcm(48000 Hz, 32位浮点数, 单声道):
ffmpeg -ar 44100 -ac 2 -f s16le -i 44100_s16le_2.pcm -ar 48000 -ac 1 -f f32le 48000_f32le_1.pcm
4.2.2 编程方式(使用 Swresample 库)
对于集成到应用程序中的需求,FFmpeg 的 libswresample库是更强大的选择。其核心步骤和关键函数如下 :
- 创建并初始化重采样上下文:使用
swr_alloc_set_opts函数创建SwrContext结构体,并设置输入和输出的音频参数(声道布局、采样格式、采样率),然后调用swr_init进行初始化 。 - 分配输入/输出缓冲区:使用
av_samples_alloc_array_and_samples函数为音频数据分配内存空间 。 - 循环读取、转换、写入:在一个循环中,不断从输入源(如文件)读取原始 PCM 数据,然后调用核心函数
swr_convert进行实际的重采样计算。该函数会返回转换后的样本数量,随后将结果写入输出目标 。 - 处理延迟(排空重采样器):在所有输入数据转换完毕后,重采样器内部可能还存在一些缓存的数据。需要再次调用
swr_convert,但将输入参数设置为NULL和0,直到没有更多数据输出为止,以确保所有数据都被处理 。 - 清理资源:最后,务必释放所有分配的资源,包括缓冲区 (
av_freep) 和重采样上下文 (swr_free) 。
下面是一个简化的代码逻辑片段,展示了这一流程:
// ... 变量定义(SwrContext*, 输入输出缓冲区等)和参数设置// 1. 创建并初始化重采样上下文
SwrContext *swr_ctx = swr_alloc_set_opts(NULL, out_ch_layout, out_sample_fmt, out_sample_rate,in_ch_layout, in_sample_fmt, in_sample_rate, 0, NULL);
swr_init(swr_ctx);// 2. 分配输入输出缓冲区
av_samples_alloc_array_and_samples(&in_data, &in_linesize, in_channels, in_samples, in_sample_fmt, 0);
av_samples_alloc_array_and_samples(&out_data, &out_linesize, out_channels, out_samples, out_sample_fmt, 0);// 3. 循环读取、转换、写入
while ((read_size = input_file.read(in_data[0], read_size)) > 0) {int ret = swr_convert(swr_ctx, out_data, out_samples, (const uint8_t **)in_data, in_samples);// ... 将转换后的数据(out_data)写入输出文件
}// 4. 排空重采样器,获取缓存的样本
while ((ret = swr_convert(swr_ctx, out_data, out_samples, NULL, 0)) > 0) {// ... 写入排空得到的数据
}// 5. 清理资源
if (in_data) av_freep(&in_data[0]); av_freep(&in_data);
if (out_data) av_freep(&out_data[0]); av_freep(&out_data);
swr_free(&swr_ctx);
4.2.3 重要注意事项
- 音质影响:重采样,尤其是有理数倍数的采样率转换(如 48 kHz 转 44.1 kHz),可能会引入音质损失。FFmpeg 的重采样器内部使用了高质量的滤波器来尽量减少这种影响,但在对音质要求极高的场合仍需谨慎选择转换参数 。
- 性能考量:重采样是计算密集型操作,特别是在高采样率和复杂声道布局的情况下。在处理大量音频数据或实时流时,需要关注性能 。
- 声道布局:除了声道数量,有时还需要指定具体的声道布局(如
AV_CH_LAYOUT_STEREO立体声),可以使用av_get_channel_layout_nb_channels函数通过声道布局获取声道数 。
五、总结
本文从音频数据采集、保存、压缩、播放等方面讲解音频全流程处理的关键技术,希望对大家有所帮助,有什么疑问也可以在评论区一起探讨,博主定期会进行回复,一起加油,奥利给!
六、参考资料
音频处理——详解PCM数据格式_pcm格式-CSDN博客
RIFF文件格式详解 - 知乎
一文搞懂 wav 文件格式 - 知乎
数字音频基础-从PCM说起 - 知乎
n ↩︎
n ↩︎