【C++】stack和queue:使用OJ题模拟实现
因为我们在数据结构的部分已经学过栈和队列了,所以在介绍和使用方面只是简单提及,感兴趣的同学可以看博主之前讲栈和队列的文章:
【数据结构】队列 【数据结构】栈
目录
一 stack的介绍和使用
1 stack的介绍编辑
2 stack的使用
二 queue的介绍和使用
1 queue的介绍
2 queue的使用
三 典型OJ题
1 最小栈
2 栈的压入,弹出序列
3 逆波兰式求值
4 二叉树的层序遍历
四 stack和queue的底层实现
1 stack模拟实现
(1)手动内存管理的栈
(2)容器适配器的栈
2 队列模拟实现
五 容器适配器
六 vector和list的优缺点
1 vector的优缺点
(1)优点
(2)缺点
2 list的优缺点
1 优点
2 缺点
七 了解deque-----双端队列
1 deque的原理介绍
2 deque的缺陷
3 deque为什么适合做stack和queue的默认适配容器
一 stack的介绍和使用
1 stack的介绍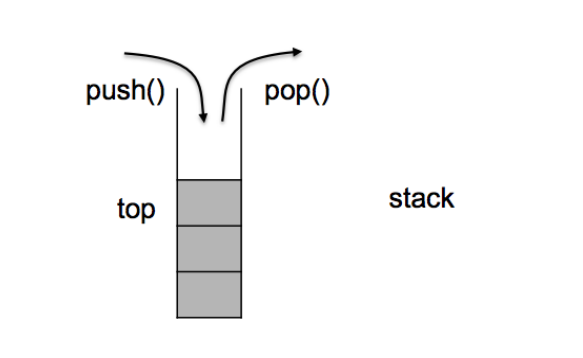
stack的文档介绍
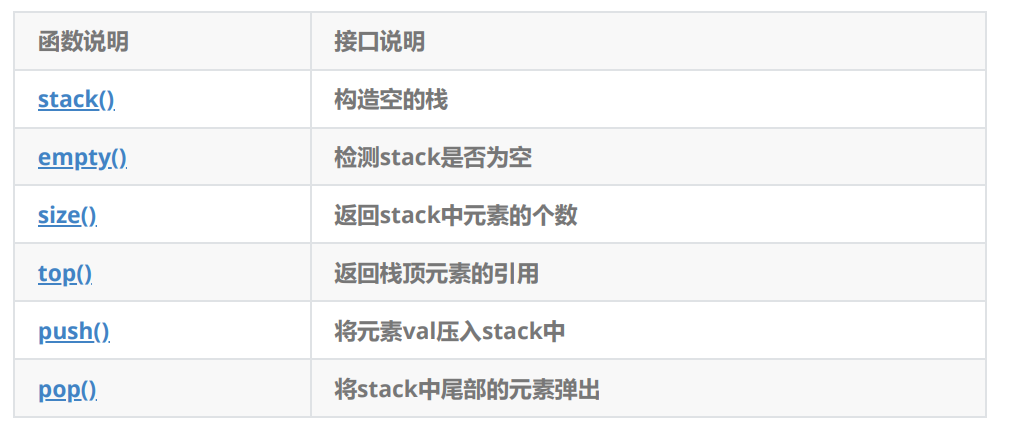
2 stack的使用
栈是不支持迭代器的:因为要严格保证数据是后进先出的
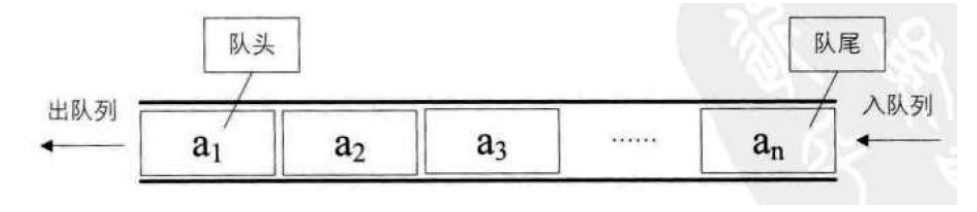
二 queue的介绍和使用
1 queue的介绍
队列的头文件下有两个队列,一个是普通队列,一个是优先级队列

优先级队列的底层是堆,优先级队列我们到后面再讲,现在先来看普通队列
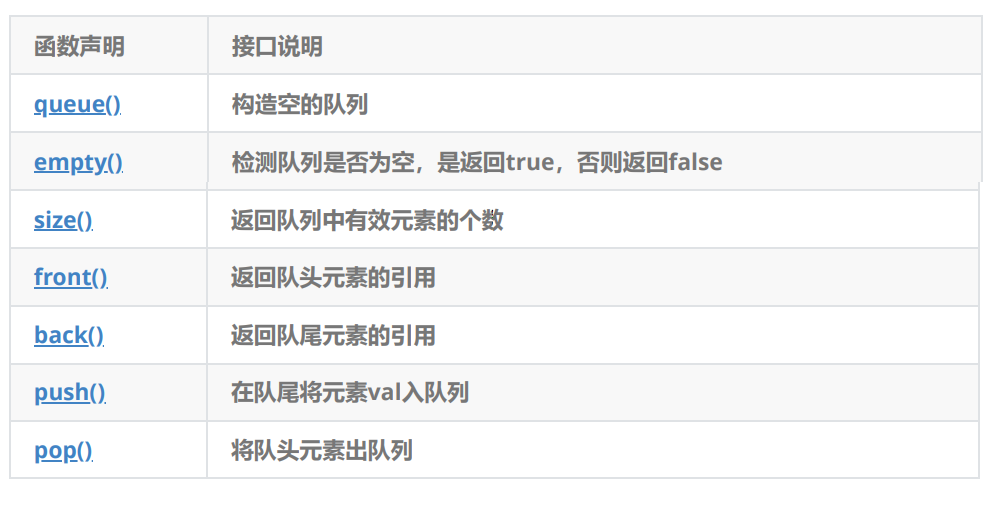
queue的文档介绍
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元 素,另一端提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供 一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少 支持以下操作: empty:检测队列是否为空 size:返回队列中有效元素的个数 front:返回队头元素的引用 back:返回队尾元素的引用 push_back:在队列尾部入队列 pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器 类,则使用标准容器deque。
队列也没有迭代器
2 queue的使用
三 典型OJ题
1 最小栈
题目链接:https://leetcode-cn.com/problems/min-stack/
题目中的常数时间内完成表示时间复杂度为O(1)

我们的常规思路可能是存储数据到栈中,然后遍历寻找最小的元素,但是这样写太过于麻烦,因为在栈中遍历是一件很麻烦的事情,下面讲一下简易思路。
解题思路:
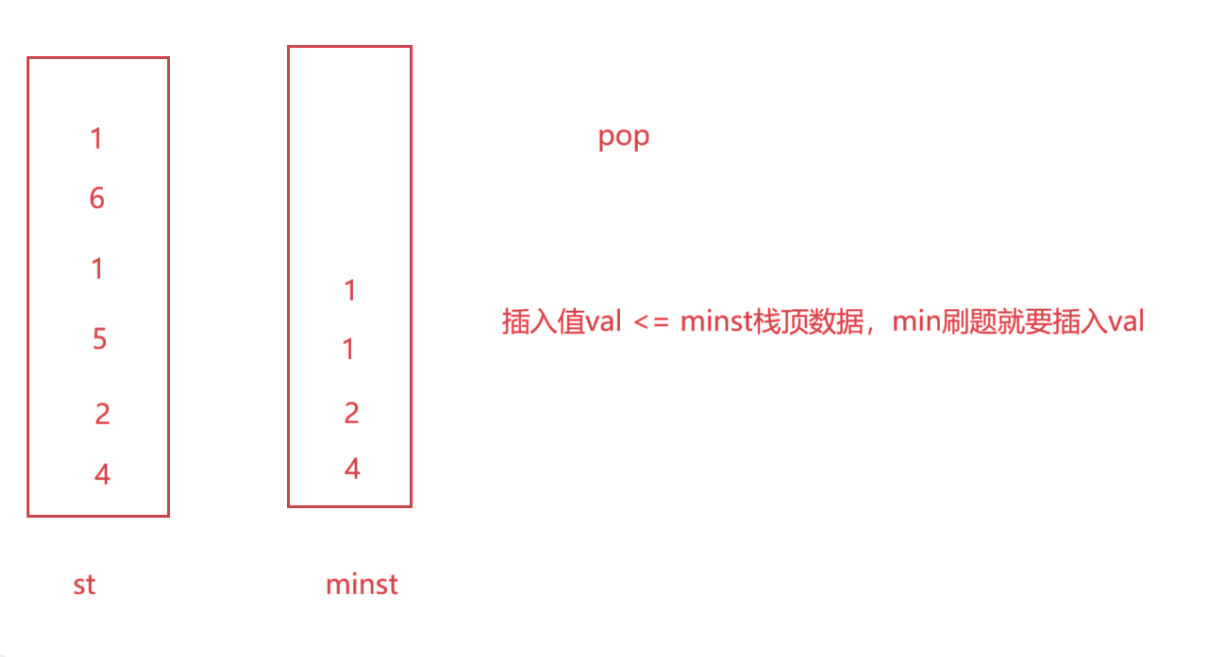
我们可以使用两个栈,第一个个栈st正常存储元素,第二个栈minst用来存储较小元素:在st存入数据时,minst和自己栈顶元素比较,如果比栈顶元素小,则入栈,反之,则不入栈。(注意,相等的时候也要入栈,否则会出错),最后在minst栈顶的就是最小元素。
class MinStack {
public:MinStack() {}void push(int val) {_st.push(val);if(_minGet.empty() ||val<=_minGet.top()){_minGet.push(val);}}void pop() {if(_st.top()==_minGet.top()){_minGet.pop();}_st.pop();}int top() {return _st.top();}int getMin() {return _minGet.top();}
private:
stack<int> _st;
stack<int> _minGet;
};
为什么没写初始化堆的函数呢?因为内置类型,如果没有给构造函数的话,系统会调用它自己的构造函数
2 栈的压入,弹出序列
题目链接:https://www.nowcoder.com/practice/d77d11405cc7470d82554cb392585106?tpId=13&&tqId=11174&rp=1&ru=/activity/oj&qru=/ta/coding-interviews/question-ranking
解题思路:
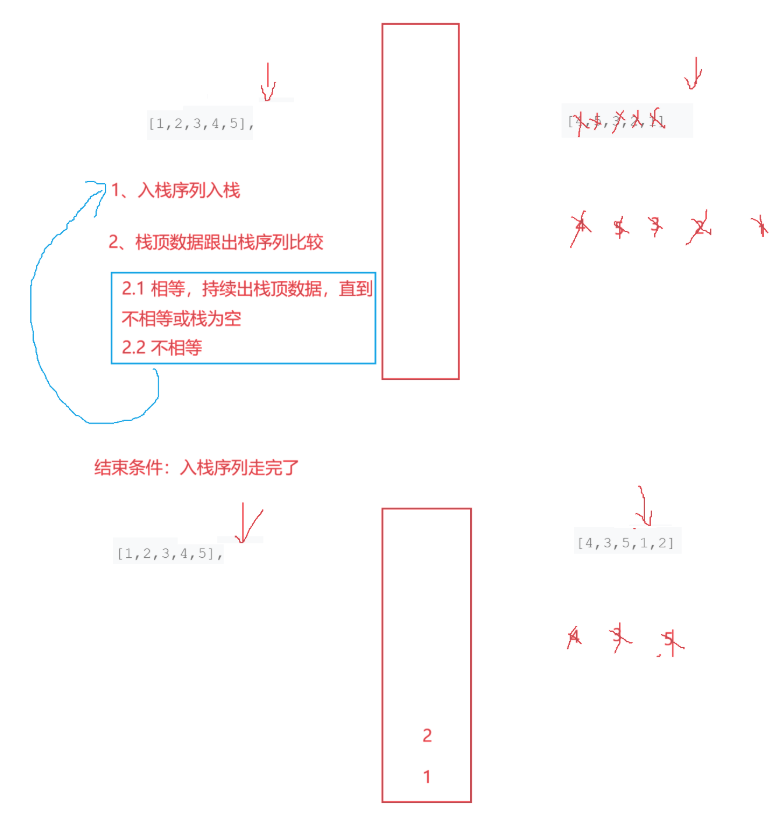
我们有两个整数序列,我们把入的栈命名为 _st,一定是栈顶·元素·和出栈序列去比较,而不是遍历入栈序列和出栈序列比较。如果入栈序列走完了,栈内还有元素,就代表出栈序列是不合法的的。
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code heresize_t pushi=0,popi=0;stack<int> _st;while(pushi < pushV.size()){_st.push(pushV[pushi]);while(!_st.empty()&&_st.top()==popV[popi]){_st.pop();popi++;}pushi++;}return _st.empty();}
};3 逆波兰式求值
题目链接:https://leetcode-cn.com/problems/evaluate-reverse-polish-notation/

运算符的顺序,分为中缀运算和后缀运算,我们平时使用的方法是中缀运算 什么是中缀和后缀呢
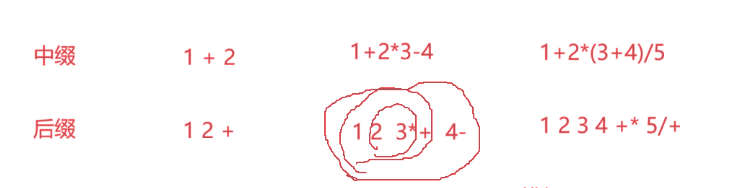
在逆波兰式运算中,使用的就是后缀运算方法,但是式一个排列好的运算符优先级。
解题思路:
1 运算数入栈
2 当遇到运算符时,取栈顶的两个数据运算,运算结果继续入栈

class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> st;for(auto& str: tokens){if(str=="+"|| str=="-"|| str=="*"||str=="/"){int right = st.top();st.pop();int left = st.top();st.pop();switch(str[0]){case '+':st.push(right+left);break;case '-':st.push(left-right);break;case '*':st.push(left*right);break;case '/':st.push(left/right);break;}}else{st.push(stoi(str));}}return st.top();}
};要点解释:
1 vector<string>:每个运算符和运算数都是一个string,把它放到了vector中给我们。
2 for范围中,一定要加上&,因为如果面对的是复杂的自定义类型的话,不加&就会出错/
3 switch的括号内,一定要是整型,如果直接用str,系统会报错,所以用str[0],因为char类型也算作整型
4 为什么要设立左右操作数:因为对于除和减运算,哪个数字在前,在后非常重要,不能混淆
5 else语句中,要使用stoi把字符转化成整型才能存入栈。
4 二叉树的层序遍历
题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/description/
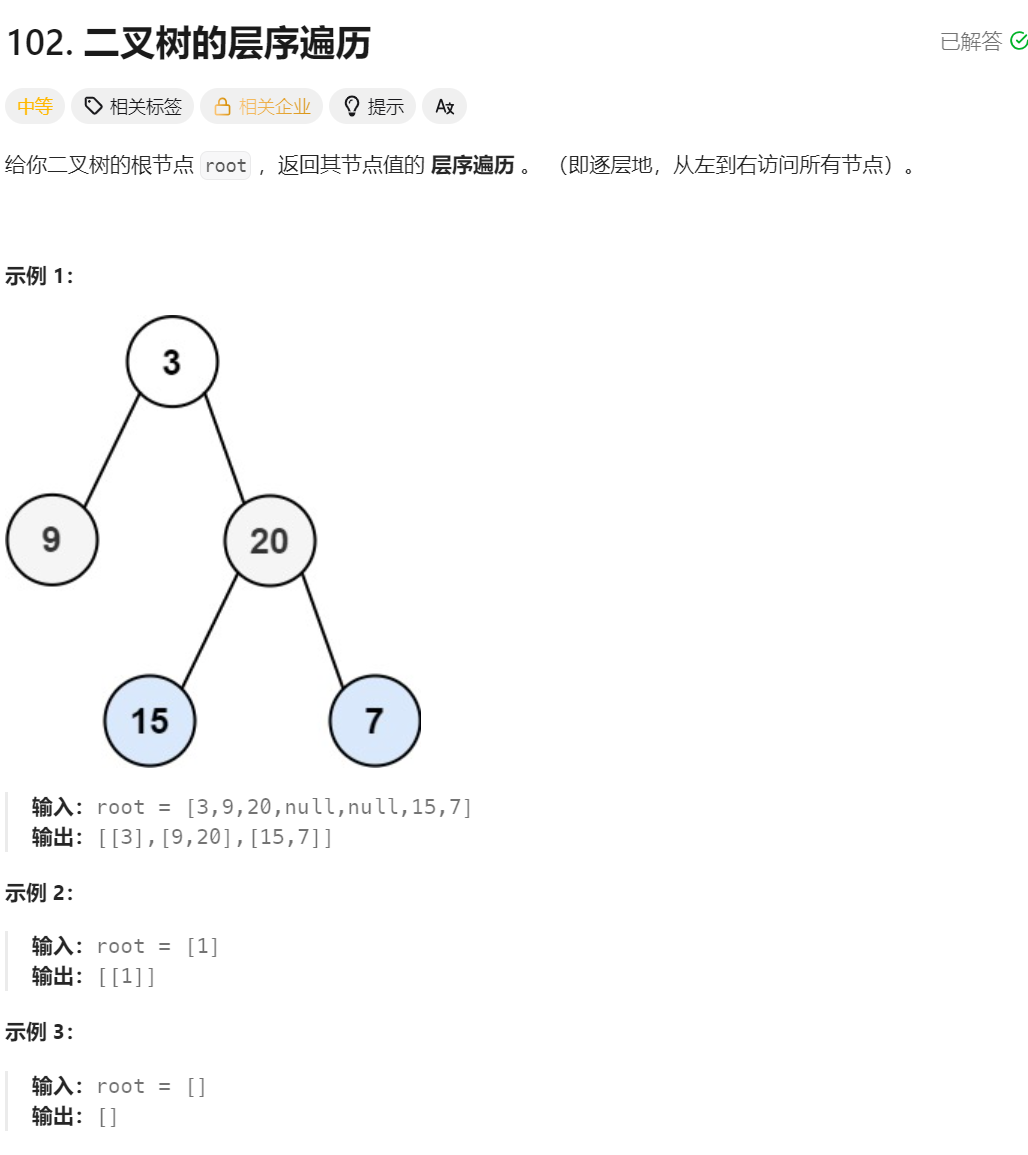
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {queue<TreeNode*> q;int levelSize=0;if(root){q.push(root);levelSize=1;}vector<vector<int>> vv;while(!q.empty()){vector<int> v;while(levelSize--){TreeNode* front=q.front();q.pop();v.push_back(front->val);if(front->left){q.push(front->left);}if(front->right){q.push(front->right);}}levelSize=q.size();vv.push_back(v);}return vv;}
};代码逻辑
- 初始化队列与层级大小:使用队列
q来辅助层序遍历,levelSize用于记录每一层的节点数量。如果根节点root存在,就将其入队,并将levelSize初始化为1(根节点所在层只有 1 个节点)。 - 外层循环:只要队列不为空,就持续进行层序遍历。
- 内层循环处理每一层:
- 先创建一个子向量
v,用于存储当前层的节点值。 - 通过
levelSize控制,依次取出当前层的节点。对于每个取出的节点,将其值存入v,然后将其左右子节点(如果存在)入队。 - 当前层处理完毕后,将
v存入结果二维向量vv,并更新levelSize为下一层的节点数量(即当前队列的大小,因为下一层的节点已经入队)。
- 先创建一个子向量
- 返回结果:最终返回存储了各层节点值的二维向量
vv。
front接口是返回容器中的第一个元素
四 stack和queue的底层实现
1 stack模拟实现
(1)手动内存管理的栈
template<class T>class stack{// ...private:T* _a;size_t _top;size_T _capacity;};(2)容器适配器的栈
下面的Container就是容器适配器
#include<list>
#include<deque>namespace bit
{template<class T, class Container = deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}第二个模板参数 Container = deque<T>:指定底层用于存储元素的容器类型,默认使用 deque<T>(双端队列),也可以指定为 list<T> 等支持 push_back、pop_back、back 等接口的容器
2 队列模拟实现
实现方式也和栈类似,也可以使用容器适配器
#pragma once
#include<vector>
#include<list>
#include<deque>namespace bit
{// ÈÝÆ÷ÊÊÅäÆ÷template<class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front(){return _con.front();}const T& back(){return _con.back();}size_t size() const{return _con.size();}bool empty() const{return _con.empty();}private:Container _con;};
}那么到底什么是容器适配器讷?我们下面来讲解
五 容器适配器
1 什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设 计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
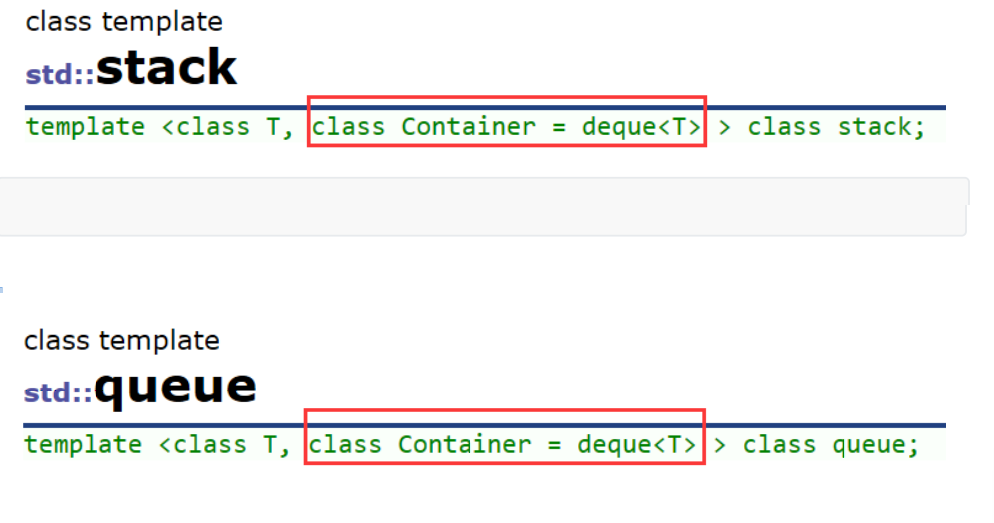
2 STL标准库中stack和queue的底层结构 虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为 容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认 使用deque,比如:

六 vector和list的优缺点
1 vector的优缺点
(1)优点
1 支持快速下标随机访问
2 尾删尾插效率很高
3 CPU高速缓存访问命中率高,数据访问效率高
(2)缺点
1 头部或中间位置插入效率很低 O(N)
2 插入需要扩容,扩容也有一定性能消耗,扩容也存在一定的空间浪费
例如:归并排序和快速排序的效率相差不大,但是如果是100万个数组排序(快排)和链表排序(归并),二者是有一定差异的,因为vector扩容是有性能消耗。
2 list的优缺点
1 优点
1 任意位置插入效率很高O(1)
2 插入不存在扩容,按需申请释放内存
2 缺点
1 不支持快速访问下标
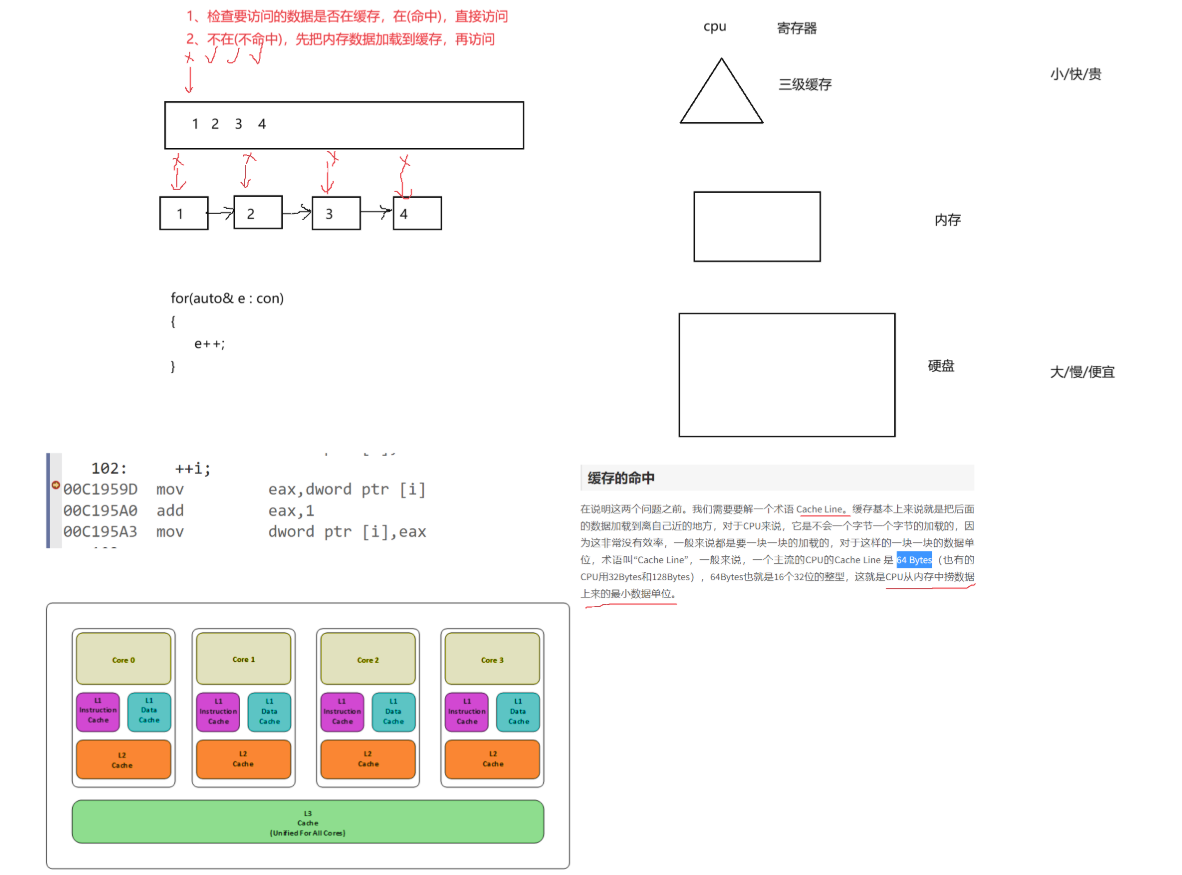
2 CPU高速缓存访问命中率低,数据访问效率低
基于CPU高速缓存访问命中率,这里推荐陈皓老师的一篇文章------与程序员相关缓存问题
有同学感兴趣这部分内容可以看看
七 了解deque-----双端队列
设计出兼容vector和list优点的数据结构:deque
1 deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端 进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与 list比较,空间利用率比较高。
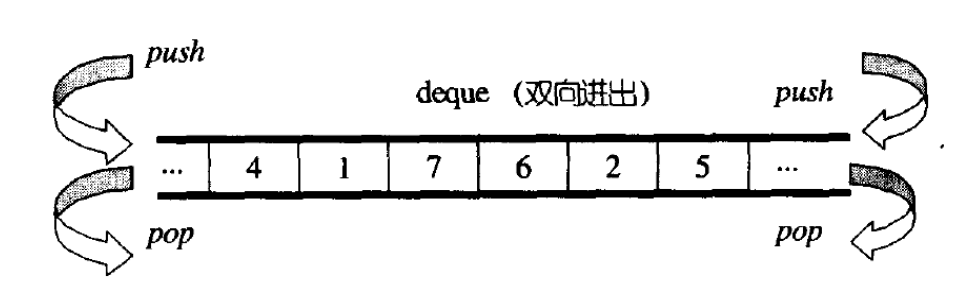
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个 动态的二维数组,其底层结构如下图所示:
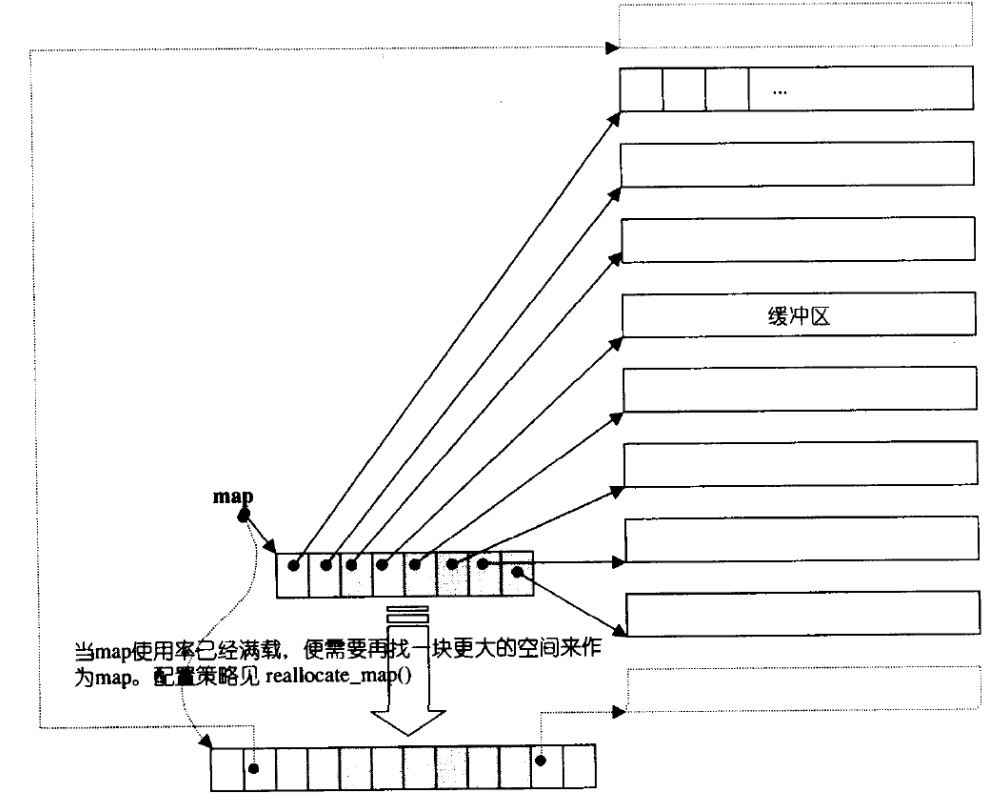
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问 的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
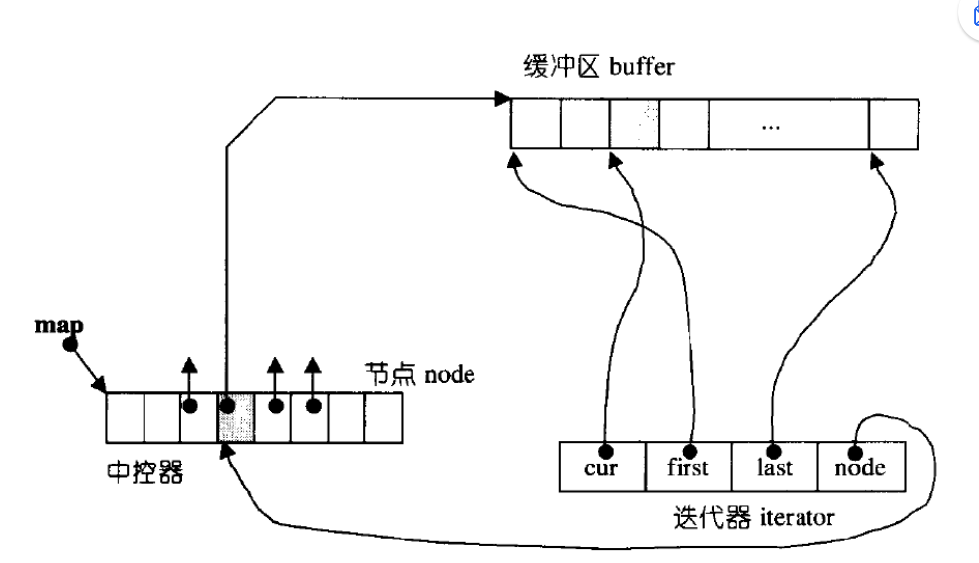
那deque是如何借助其迭代器维护其假想连续的结构呢?
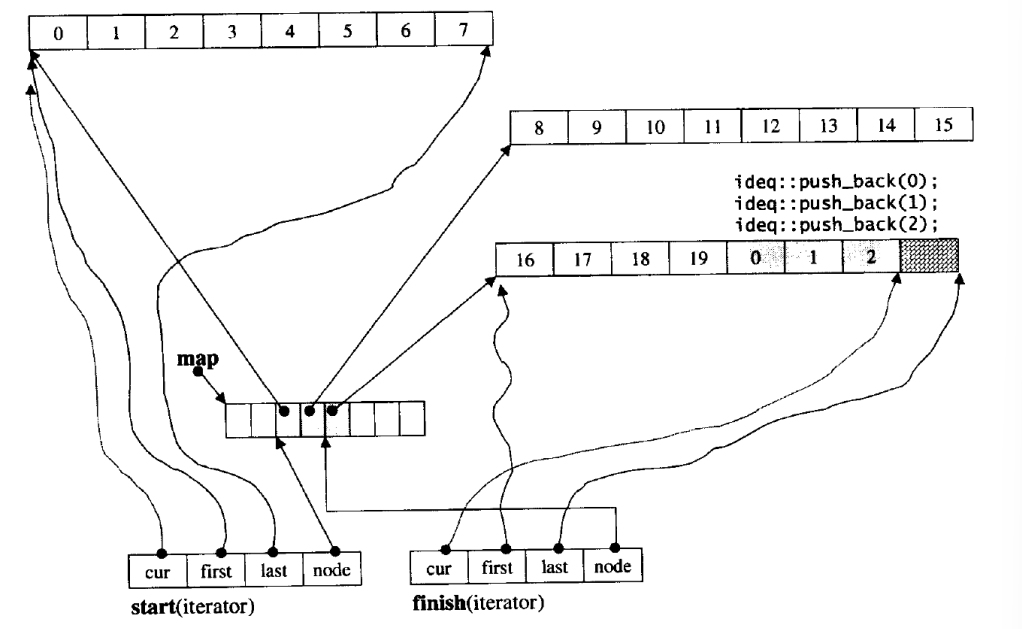

2 deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩 容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其 是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实 际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看 到的一个应用就是,STL用其作为stack和queue的底层数据结构。
3 deque为什么适合做stack和queue的默认适配容器
1 deque的头尾删除效率都不错
2 CPU高速缓存命中率也不错,数据访问效率也高