Linux修炼:库制作与原理(一)
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路!
我的博客:<但凡.
我的专栏:《编程之路》、《数据结构与算法之美》、《C++修炼之路》、《Linux修炼:终端之内 洞悉真理》、《Git 完全手册:从入门到团队协作实战》
感谢你打开这篇博客!希望这篇博客能为你带来帮助,也欢迎一起交流探讨,共同成长。

目录
1、什么是库
2、静态库
创建库的头文件(mylibrary.h)
实现库的源文件(mylibrary.cpp)
使用库的主程序(main.cpp)
编译和链接
3、动态库
4、ELF文件
4.1、认识ELF格式
ELF头部(ELF Header)
程序头表(Program Header Table)
节头表(Section Header Table)
节(Sections)
4.2、谈链接过程
静态链接的过程
关键特点
1、什么是库
库就是已经写好的可以复用的代码。库是一种可执行代码的二进制形式,可以被操作系统载入到内存执行。库有两种:
静态库 .a[Linux]、.lib[windows]
动态库 .so[Linux]、.dll[windows]
2、静态库
程序在编译链接的时候把库的代码链接到可执行文件中,程序运行的时候将不再需要静态库。
我们首先自己写一个库来理解一下什么是库:
我们准备三个文件,一个是创建库的头文件,一个是实现库的源文件,还有一个是使用库的主程序。
创建库的头文件(mylibrary.h)
#ifndef MYLIBRARY_H
#define MYLIBRARY_Hnamespace MyLibrary {class Calculator {public:static int add(int a, int b);static int subtract(int a, int b);};void greet(const char* name);
}#endif // MYLIBRARY_H
实现库的源文件(mylibrary.cpp)
#include "mylibrary.h"
#include <iostream>namespace MyLibrary {int Calculator::add(int a, int b) {return a + b;}int Calculator::subtract(int a, int b) {return a - b;}void greet(const char* name) {std::cout << "Hello, " << name << "!" << std::endl;}
}
使用库的主程序(main.cpp)
#include "mylibrary.h"
#include <iostream>int main() {// 使用库中的类std::cout << "5 + 3 = " << MyLibrary::Calculator::add(5, 3) << std::endl;std::cout << "5 - 3 = " << MyLibrary::Calculator::subtract(5, 3) << std::endl;// 使用库中的函数MyLibrary::greet("World");return 0;
}
编译和链接
要将上述代码编译为库并链接到主程序,可以按照以下步骤操作:
-
编译库文件为对象文件(注意是把库的实现文件编译成.o):
g++ -c mylibrary.cpp -o mylibrary.o -
将对象文件打包为静态库:
ar rcs libmylibrary.a mylibrary.o -
其中,ar是创建,修改,提取,静态库文件的命令,rcs是三个命令选项,其中r是替换或添加文件到归档中,c是静默模式,不显示警告信息,s是创建或更新归档索引。我们要把目标文件mylibrary.o打包成静态库libmylibrary.a。库必须以lib开头。
-
编译主程序并链接库:
g++ main.cpp -L. -lmylibrary -o myprogram -
-L.是指定链接器搜索库文件的路径是当前目录。链接器会在当前目录寻找libmylibrary。-lmylibrary为我们要链接的库名。-l自动补全前缀lib和后缀。-o myprogram指生成的可执行文件名为myprogram
-
运行程序:
./myprogram
库其实就是把程序员写好的源代码,编译成.o,然后打了个包。
此时如果我们使用ldd命令去查看myprogram的依赖库信息,会发现查不到。这是因为静态库会把自己的代码合并到目标文件,即一旦形成可执行程序,就不再依赖静态库了。
一般官方的库都被装在了系统的默认路径下,而gcc/g++编译程序时,一般会在默认路径下查找。所以,假设我们的可执行程序中只包含了stdio.h这个头文件,那么我们不需要-L来指示库的位置,因为C标准库就在系统的默认路径中。所谓的库的安装,主要就是把库文件拷贝到系统的默认路径下。
又因为gcc是专门编译C语言的,所以他默认就要认识libc。因此在编译的时候,我们不需要带着-lc。第三方的库都需要带-l来表示库名称。
假设我们现在想把自己写的静态库中的头文件在include的时用<>包含起来,我们需要怎么做呢?
第一种方法就是在执行命令时,加上-I.,表示在当前路径搜索头文件。第二种方式就是把我们的头文件也拷贝到系统的指定目录下。我们把libmylibrary移动到默认路径下,再把头文件拷贝到系统的指定目录之后,我们就可以通过执行以下命令成功编译程序:
g++ main.cpp -lmylibrary -o myprogram
库=头文件+库文件。库的使用需要搜索找到头文件(-I),库路径(-L),库是谁(-l)。库如果不想过多使用上面的选项,就需要把库安装到指定了系统特定路径。一般情况下,头文件拷贝到/user/include,而库文件拷贝到/lib64。
现在我们正儿八经的用make构建制作静态库的流程:
libmyc.a:mymath.o mystdio.oar -rc $@ $^
%.o:%.cgcc -c $<.PHONY:clean
clean:rm -f *.a *.o.PHONY:output
output:mkdir mylibcmkdir -p mylibc/includemkdir -p mylibc/libcp *.h mylibc/includecp *.a mylibc/libtar czf mylibc.tgz mylibc 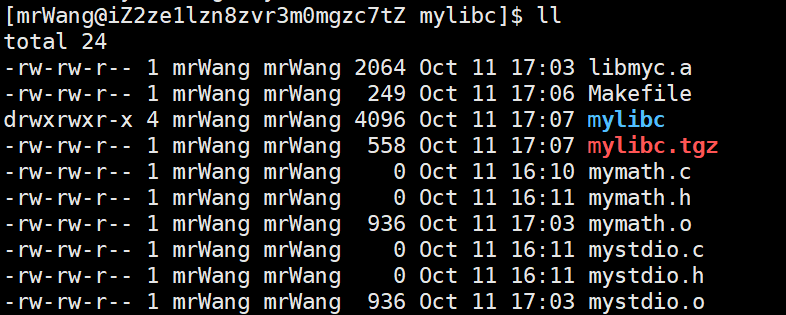
执行make,会自动生成静态库的压缩包。
3、动态库
如果想创建动态库(共享库),可以使用以下命令:
-
编译为动态库:
g++ -shared -fPIC mylibrary.cpp -o libmylibrary.so -
其中,-shared指示编译器生成动态链接库(共享库),而不是可执行文件。-fPIC指生成位置无关代码,这时动态链接库必需的,确保代码可以在内存中任意位置加载。动态库的名称一般以.so为后缀。
-
链接动态库:
g++ main.cpp -L. -lmylibrary -o myprogram -
运行前需要设置库路径:
export LD_LIBRARY_PATH=.:$LD_LIBRARY_PATH ./myprogram
现在我们自动化构建动态库:
libmyc.so:mymath.o mystdio.ogcc -o $@ $^ -shared
%.o:%.cgcc -fPIC -c $<.PHONY:clean
clean:rm -rf *.so *.o mylibc *.tgz.PHONY:output
output:mkdir mylibcmkdir -p mylibc/includemkdir -p mylibc/libcp *.h mylibc/includecp *.so mylibc/lib tar czf mylibc.tgz mylibc
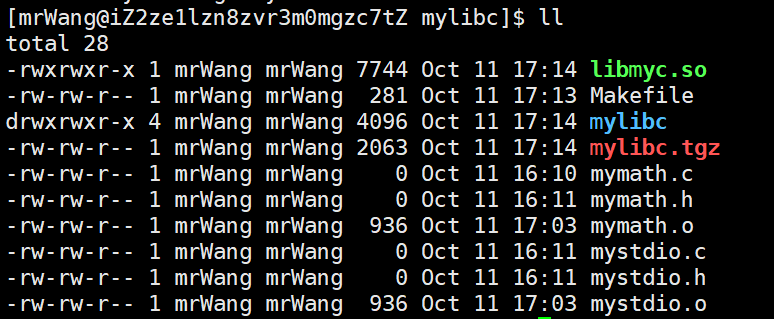
使用libmyc.so时,我们需要指示库的路径,头文件的路径,以及库的名字:
gcc test.c -I mylibc/include. -L mylibc/lib/ -lmyc在我们配置编译器环境时,比如vs,它会自动给我们下载一堆东西,这堆东西中就有各种我们需要用的的库和头文件。
接着我们运行程序,发现会报错,这是因为我们的动态链接要求在运行时也要能找到动态库。我们时刻需要访问动态库。而之前在编译时,我们只是告诉了编译器动态库在哪里,但是系统(中的加载器)并不知道动态库在哪。
我们可以把动态库拷贝到lib64(即系统默认路径)中,这样系统和编译器就都能找到了。当然我们还有别的方法,我们还可以在libb64目录下,以软连接的方式进行关联。软连接的名字应当与库名称一样。其实一般情况下,我们所有的库都是放在lib64中的。
除了这两种方式以外,还有一种方式就是通过环境变量。我们可以配置指定的环境变量,让系统找到指定的动态库。即上面第4条介绍的那种方式。这种方式是临时方式。
除此之外,我们还可以将动态库查找路径全局有效,更改系统配置文件。在这里就不演示了,因为我们常用的是第一二种方法。
动态库和静态库同时存在的时候,gcc/g++默认优先使用动态库。默认进行动态链接。一个可执行程序,可能会依赖多个库。如果我们只提供静态库,即使我们是动态链接,gcc也没有办法,只能对只提供静态库的库进行静态链接。
我们在编译时可以使用--static选项,要求必须采用静态链接。这种情况下,静态库必须存在。
大部分系统只安装了C/C++的动态库,没有安装静态库。我们可以通过以下指定手动安装静态库:
#C语言
sudo apt/yum install glibc-static
#C++
sudo apt/yum install libstdc++-static
4、ELF文件
4.1、认识ELF格式
在过去的一段时间里,我们接触过几种特殊的文件,包括可重定位文件(.o为后后缀),可执行文件,共享目标文件(.so为后缀),内核转储。以上这些文件都是ELF文件。
以人类的眼光看,我们直接打开ELF文件,里面的内容都是乱码。其实这些乱码也是有固定的存储规则的。
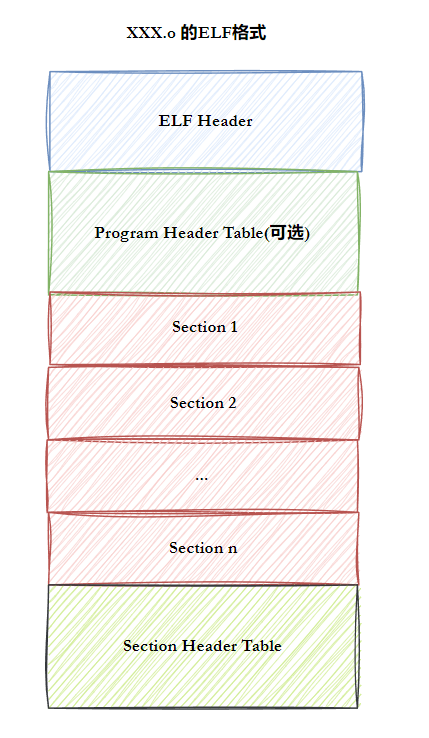
ELF文件由以下部分组成:
ELF头部(ELF Header)
描述文件的基本属性,如文件类型(可执行、目标文件等)、目标架构(如x86、ARM)和程序入口地址。
程序头表(Program Header Table)
仅存在于可执行文件和共享库中,定义如何将文件加载到内存。每个条目描述一个段(如代码段、数据段)的内存布局。
节头表(Section Header Table)
包含文件中所有节(section)的描述信息,如代码节(.text)、数据节(.data)和符号表(.symtab)。目标文件通常依赖此表进行链接。
节(Sections)
存储实际内容,例如:
.text:可执行代码。.data:已初始化的全局变量。.bss:未初始化的全局变量(不占文件空间)。.rodata:只读数据(如字符串常量)。
我们可以通过readelf命令来获取ELF文件的各种信息,比如我们可以查看ELF Header中的信息: 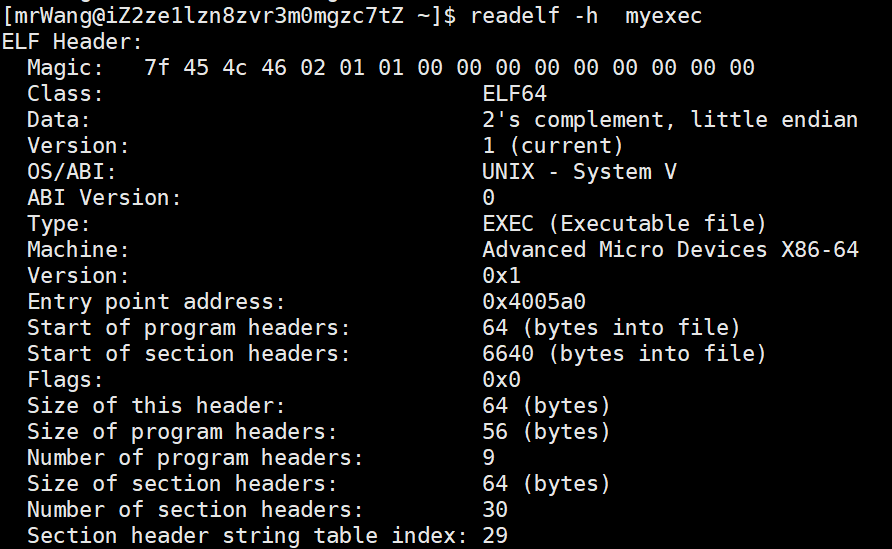
ELF(Executable and Linkable Format)文件的开头是一个固定大小的头部结构(ELF Header),它描述了整个文件的基本属性和布局。以下是 ELF Header 中存储的关键信息:
-
Magic Number
- 前 4 字节为
0x7F、'E'、'L'、'F',用于标识文件是否为 ELF 格式。 - 后续字节包含 ELF 文件的类别(32/64 位)、字节序(大端/小端)和版本信息。
- 前 4 字节为
-
文件类型
- 2 字节字段,标识文件类型,如:
ET_REL(可重定位文件,如.o文件)ET_EXEC(可执行文件)ET_DYN(共享库,如.so文件)
- 2 字节字段,标识文件类型,如:
-
机器架构
- 2 字节字段,指定目标机器的 CPU 架构,例如:
EM_X86_64(x86-64)EM_ARM(ARM)EM_RISCV(RISC-V)
- 2 字节字段,指定目标机器的 CPU 架构,例如:
-
ELF 版本
- 4 字节字段,通常为
EV_CURRENT(当前版本)。
- 4 字节字段,通常为
-
程序入口地址
- 8 字节字段(64 位)或 4 字节字段(32 位),指定可执行文件的入口点(即
_start函数的地址)。
- 8 字节字段(64 位)或 4 字节字段(32 位),指定可执行文件的入口点(即
-
Program Header 和 Section Header 的位置
e_phoff:Program Header 表在文件中的偏移量。e_shoff:Section Header 表在文件中的偏移量。
-
标志与对齐信息
- 处理器特定的标志(如 ABI 版本)。
- Program Header 和 Section Header 的条目大小及数量。
我们可以通过指令来读一下节头表中的内容:
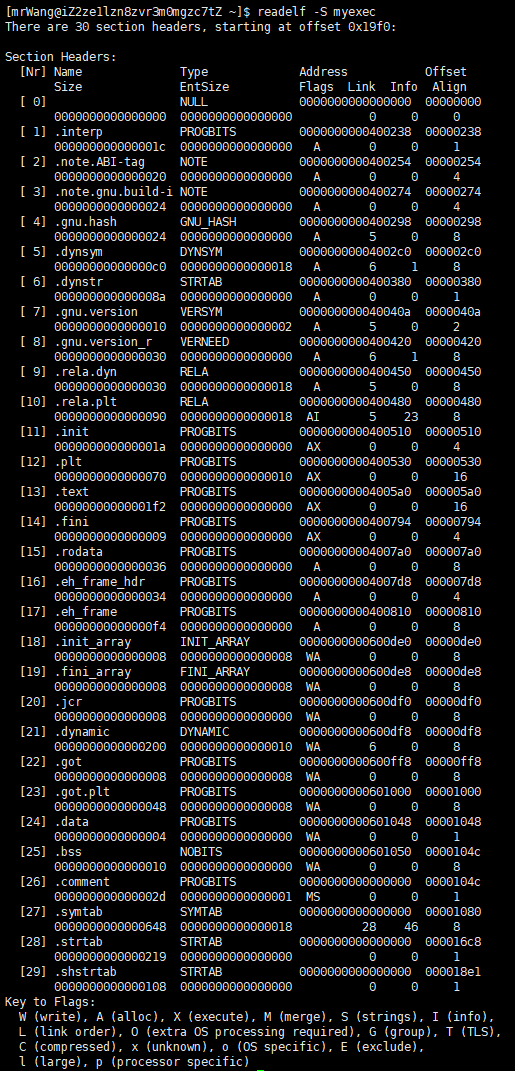
其中包含了各个节的名称,比如text(文本),rodate(已初始化全局数据区)等等。Section Header会记录一共有多少个节,并且记录每个节的大小、偏移量和权限等等。
节的大小不一定是4KB,但操作系统每次读取数据都是以4KB为单位的。而且,不同的节也可能会有相同的属性。所以,我们每次IO的时候,都需要将多个属性相同的section合并,对齐4KB(对齐4KB的倍数)。合并之后的数据节叫数据段(segment)。没错,我们之前学过的什么BSS段,数据段,代码段,都是从ELF文件中加载进来的。ELF加载到内存的时候,会被OS自动合并成为多个segment,加载到内存中。而程序头表(Program Header Table)就是合并成为segment的方法表。也就是说,合并的方式在ELF文件被创建的时候就已经规定好了,就像所有命运馈赠的礼物早就被暗中标好了价格。
Section合并的主要原因是为了减少页面碎片,提高内存使用效率。如果不进行合并, 假设页面大小为4096字节(内存块基本大小,加载,管理的基本单位),如果.text部分 为4097字节,.init部分为512字节(.init和.text属性相同),那么它们将占用3个页面,而合并后,它们只需2个页面。此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个大的 segment,这样就可以实现不同的访问权限,从而优化内存管理和权限访问。
我们可以通过指令查看程序头表(Program Header Table)中的内容:
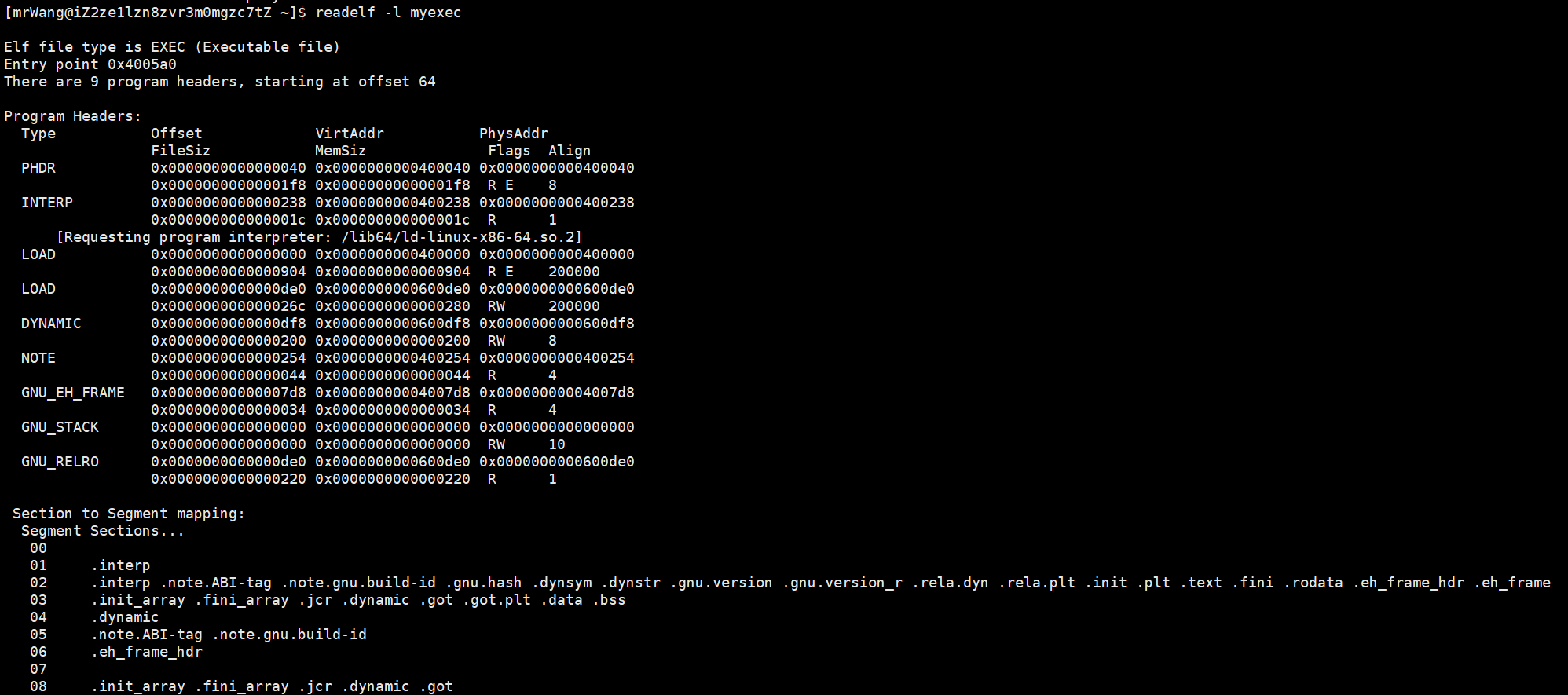
合并之后就变成了八个数据段,分别对应编号01到08,最后合并成的数据段的个数是不固定的,不同文件可能不一样。
一个ELF文件要有两种视角,一种视角是编译器视角(section),另一种是系统视角(segment)。
4.2、谈链接过程
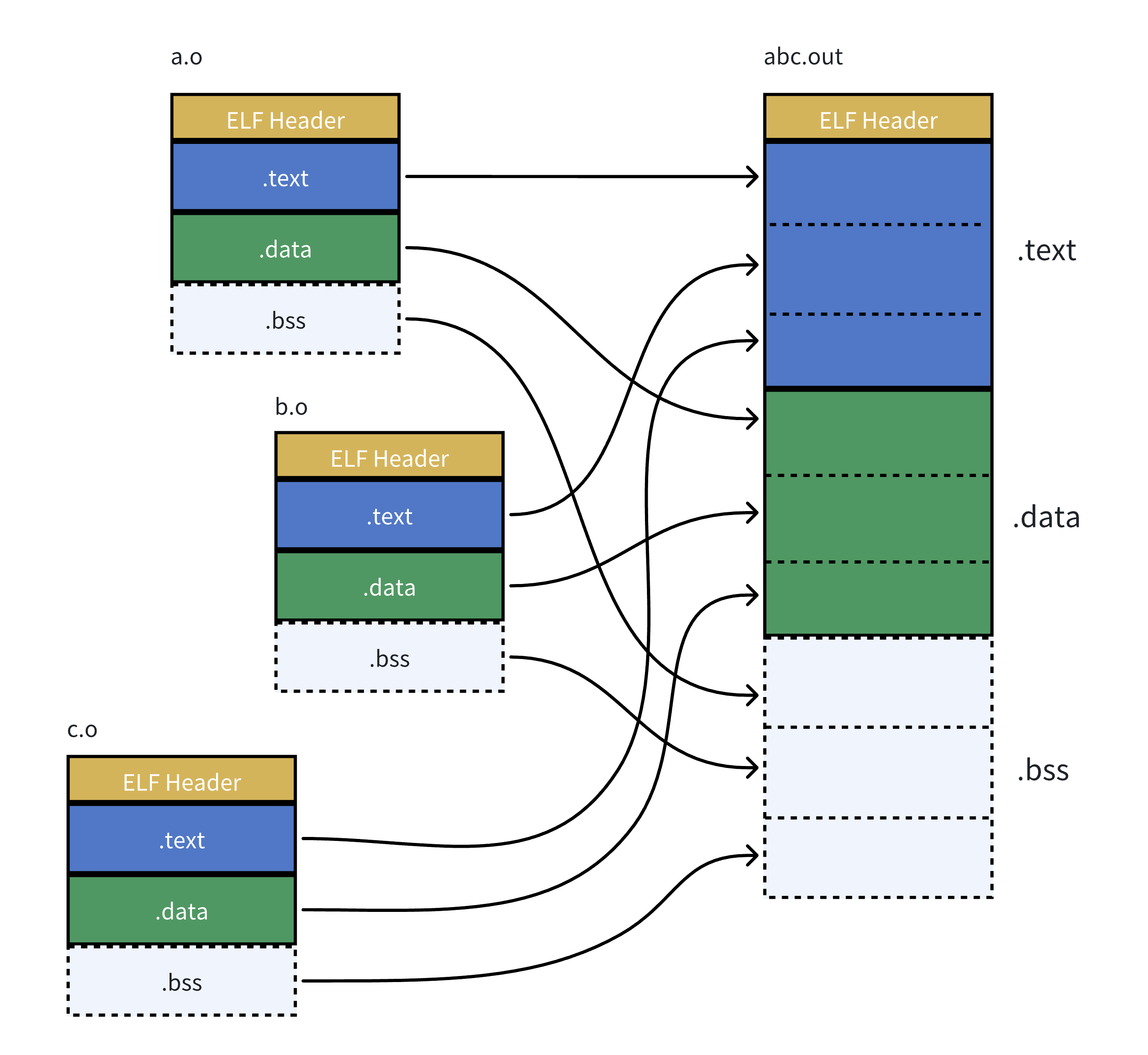
链接其实就是把多个ELF文件中对应的属性相同的section合并到一起:
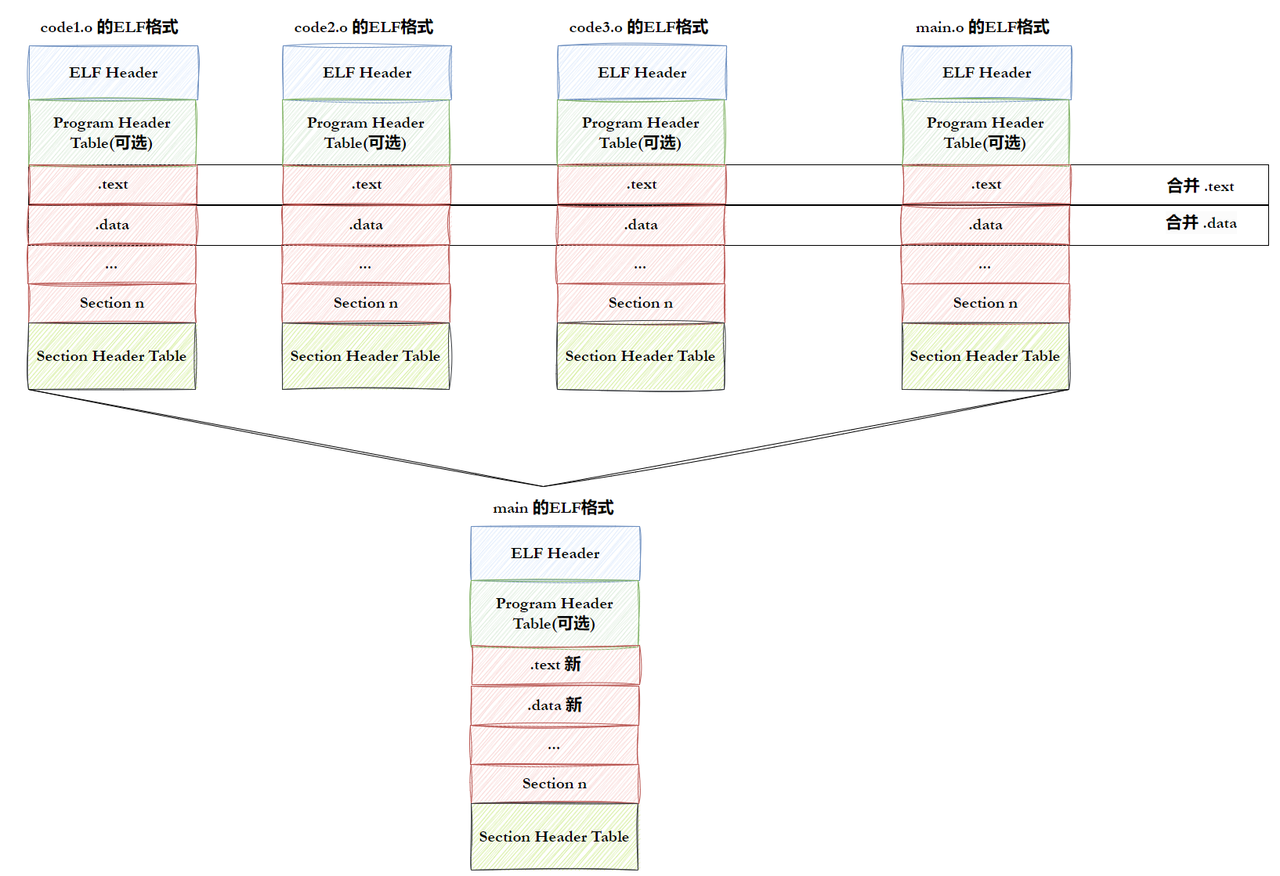
当然实际上的链接要复杂的多。
静态链接的过程
符号解析
链接器读取所有输入的目标文件,检查每个目标文件中的符号定义与引用。确保每个符号有且仅有一个定义,解决所有未解析的符号引用。
地址与空间分配
为输出文件中的代码段、数据段等分配运行时内存地址。合并所有目标文件的同类段(如.text、.data),并确定每个段在最终可执行文件中的大小和位置。
重定位
修改目标文件中的符号引用地址,使其指向正确的运行时地址。根据段合并后的新基址,调整代码和数据中的相对地址或绝对地址引用。
生成可执行文件
将重定位后的代码、数据及必要的头部信息(如ELF头、段表)写入输出文件,形成可直接加载运行的静态可执行文件。
关键特点
- 所有外部符号在链接时已解析并绑定。
- 最终文件独立运行,无需运行时加载动态库。
- 文件体积较大,因库代码被完整复制到可执行文件中。
所以,链接过程中会涉及到对.o中外部符号进行地址重定位。
一个ELF可执行程序,在没有加载到内存的时候,就已经有地址了!Linux系统编译形成可执行程序的时候,需要对代码和数据进行编址。当代CPU和计算机和操作系统,在对ELF编址的时候采用的做法都是平坦模式进行的,我们仍可以看作是段起始地址+偏移量的方式,只不过段起始地址是0。
这种从全零到全F的线性编址得到的地址起始就是我们之前讲的虚拟地址。在磁盘中的可执行文件,它的地址是以逻辑地址的方式表示的,而在内存中,它是以虚拟地址的方式表示的。尽管在磁盘中是逻辑地址,在内存中是虚拟地址,但是他们都是从全0到全F的。
当我们把可执行程序加载到内存中时,我们的程序内部就建立起了物理地址到虚拟地址的映射关系。这个映射关系被记录在页表之中。cpu可以根据存储在EIP中的程序地址入口(即ELF Header中的entry point address)去访问物理地址。需要注意的是,这个程序地址入口存储的地址是程序在内存中的虚拟地址。当cpu拿到虚拟地址之后,在根据页表得到物理地址再进行访问。当CPU需要将虚拟地址转换为物理地址时,会从CR3寄存器获取页表基址开始查找。
CR3 寄存器为 MMU 提供了页表的起始地址。在 x86 分页机制中,虚拟地址到物理地址的转换需要多级页表(如页目录和页表)。CR3 存储的是页目录的物理地址,MMU 使用 CR3 的值作为起点,逐级查找页表项,最终完成地址转换。转换完成后,cpu和内存又通过系统总线连接起来,进行数据的传输。
好了,今天的内容就分享到这,我们下期再见!