Qwen3 Embedding论文解读
论文标题:Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
论文地址:https://arxiv.org/abs/2506.05176
论文发布时间:2025 年 6 月 5 日
Abstract
论文推出了 Qwen3 Embedding 系列模型。该系列基于 Qwen3 基础模型构建,使用多阶段训练流程将大规模无监督预训练与高质量数据集上有监督微调相结合。
在训练过程中,Qwen3 大语言模型不仅作为骨干模型,还在跨多个领域和语言合成高质量、丰富且多样的训练数据方面发挥关键作用,从而对训练流程起到增强效果。
Qwen3 Embedding 系列提供多种规模(0.6B、4B、8B)的模型,适用于嵌入和重排序任务,能够满足不同的部署场景,用户可根据需求在效率和效果之间进行优化。
Introduction
在使用 LLM 作为 Embedder 之前,一般使用 Encoder-only 架构的模型来作为嵌入模型,如 BERT。目前已经有很多基于 LLM 的嵌入模型新范式提出,如:
-
在嵌入模型的训练过程中,结合指令类型、领域和语言等方面的差异化任务,在下游任务中取得了更好的性能。
-
在重排序模型的训练中,通过基于用户提示的零样本方法以及结合有监督微调的方法,都实现了性能的提升。
本文推出了 Qwen3 Embedding 系列模型,这些模型构建于 Qwen3 基础模型之上。
-
为了训练嵌入模型,采用了多阶段训练流程,包括大规模无监督预训练,随后在高质量数据集上进行有监督微调,还通过融合不同的模型 checkpoint 来增强模型的稳健性和泛化能力。
-
Qwen3 指令模型能够高效合成大规模、高质量、多语言且多任务的文本相关性数据集。这些合成数据用于初始的无监督训练阶段,而一小部分高质量的小规模数据则被选用于第二阶段的有监督训练。
-
对于重排序模型,以类似的方式采用两阶段训练方案,包括高质量的有监督微调与模型融合阶段。基于不同规模的 Qwen3 骨干模型(包括 0.6B、4B 和 8B),最终训练出了三个文本嵌入模型和三个文本重排序模型。
值得注意的一点是,Qwen3 Embedding 系列嵌入模型支持灵活维度表示。
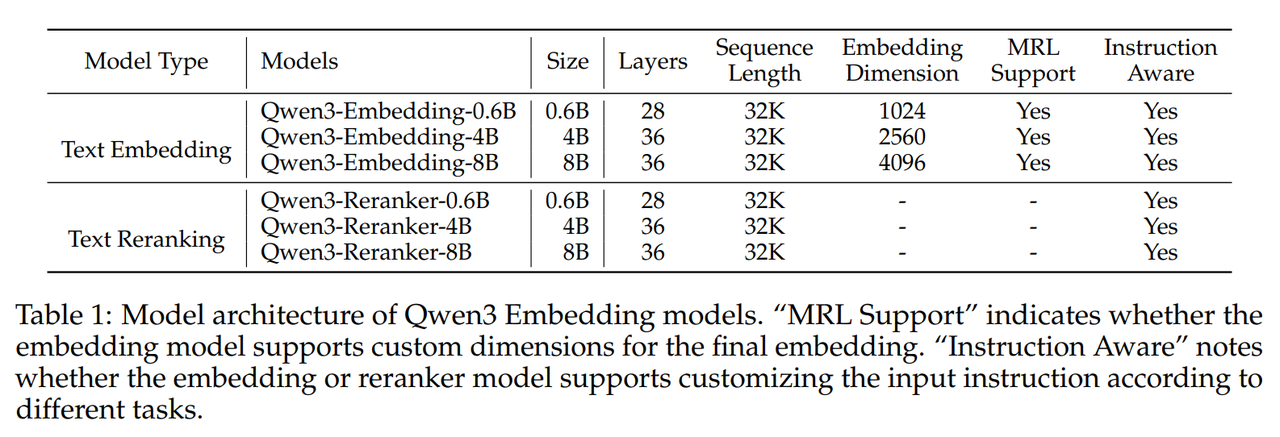
Model Architecture
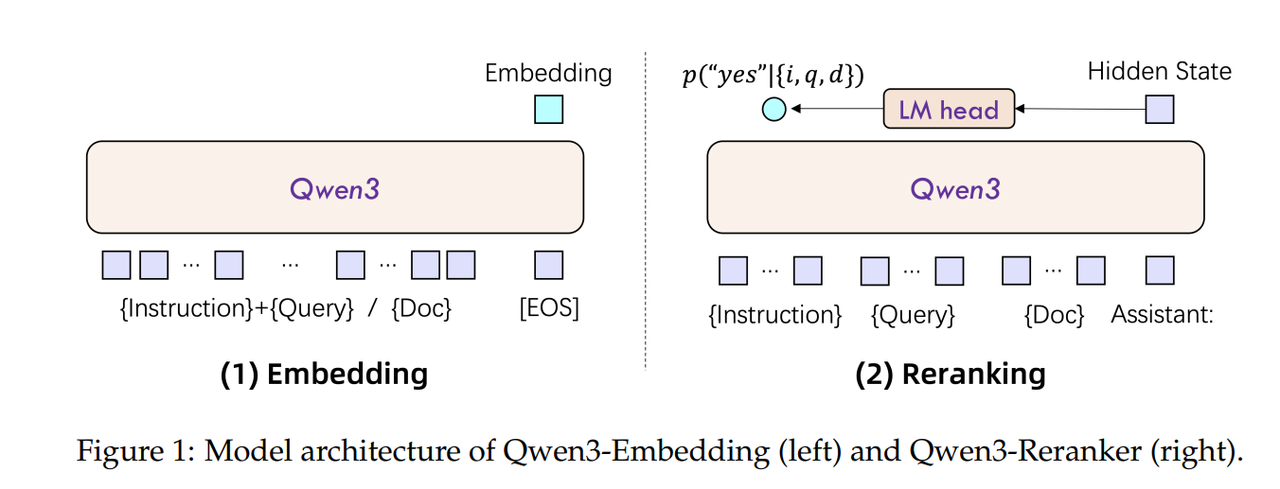
Qwen3 Embedder 和 Reranker 模型的架构为
decoder-only,Embedder的输出为最后一个隐藏层的last token位置向量,Reranker的输出是分类后"yes"位置的概率。设计上和FlagEmbedding社区的Embedder-llm一致。
给定一个查询 q 和若干文档 d,嵌入和重排序模型会基于指令 I 所定义的相似性标准来评估它们的相关性。训练数据被组织为 {Ii,qi,di+,di,1−,⋯ ,di,n−}\{I_{i}, q_{i}, d_{i}^{+}, d_{i, 1}^{-}, \cdots, d_{i, n}^{-}\}{Ii,qi,di+,di,1−,⋯,di,n−}。
其中, qiq_{i}qi表示一条查询, di+d_{i}^{+}di+表示一条正样本, di,1−,⋯ ,di,n−d_{i, 1}^{-}, \cdots, d_{i, n}^{-}di,1−,⋯,di,n−表示若干条负样本。
实际上,数据集里一个 query 会有多个正样本和多个负样本。这里论文说的其实是 batch 内采样策略,我们通常称之为
In-batch negatives,这样采样有个好处:天然适合 对比学习(contrastive learning) 或 in-batch negatives 策略。假设 batch=8,计算出来的相似度矩阵为 8*8,正样本只在对角线出现,其他位置都是负样本,天然具有 label 信息,非常利于 InfoNCE 损失函数矩阵计算。
注意,infoNCE 损失,不是 pointwise 和 pairwise 损失。pointwise 是二分类问题(BCE 损失)标签是 0 或 1;pairwise 是 pair 之间损失最小化问题,每次只比较一对正负,只存在相对顺序。
嵌入模型 使用具有因果注意力的大语言模型,在输入序列的末尾添加一个[EOS]标记。最终嵌入为[EOS]标记对应的最后一层的隐藏状态。为确保嵌入在下游任务中遵循指令,将指令和查询拼接成一个单一的输入上下文,同时在使用大语言模型处理之前保持文档不变。查询的输入格式如下:
{Instruction} {Query}<|endoftext|>
重排序模型 为了更准确地评估文本相似度,在单一语境中使用大语言模型进行逐点重排序。与嵌入模型类似,为了具备遵循指令的能力,在输入语境中包含了指令。使用大语言模型聊天模板,并将相似度评估任务构建为二分类问题。大语言模型的输入遵循以下所示的模板:
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the
Instruct provided. Note that the answer can only be "yes" or "no".<|im_end|>
<|im_start|>user
<Instruct>: {Instruction}
<Query>: {Query}
<Document>: {Document}<|im_end|>
<|im_start|>assistant
<think>\n\n</think>\n\n
Qwen3 Reranker 模型的相似度分数计算方法为,"yes"标记的概率比"yes"和"no"标记的概率和:
score(q,d)=eP(yes∣I,q,d)eP(yes∣I,q,d)+eP(no∣I,q,d)score(q, d)=\frac{e^{P(yes | I, q, d)}}{e^{P(yes | I, q, d)}+e^{P(no | I, q, d)}}score(q,d)=eP(yes∣I,q,d)+eP(no∣I,q,d)eP(yes∣I,q,d)
Models Training
Training Objective
对于嵌入模型,采用了基于 InfoNCE 框架的改进对比损失。给定一批包含 N 个训练实例的数据,该损失定义为:
Lembedding=−1N∑iNloge(s(qi,di+)/τ)Zi,(1)L_{embedding }=-\frac{1}{N} \sum_{i}^{N} log \frac{e^{\left(s\left(q_{i}, d_{i}^{+}\right) / \tau\right)}}{Z_{i}}, (1)Lembedding=−N1∑iNlogZie(s(qi,di+)/τ),(1)
其中, s(⋅,⋅)s(\cdot, \cdot)s(⋅,⋅)是一个相似度函数(使用余弦相似度),τ是温度参数, ZiZ_{i}Zi是归一化因子,用于聚合正对与各种负对的相似度分数:
Zi=e(s(qi,di+)/τ)+∑kKmike(s(qi,di,k−)/τ)+∑j≠imije(s(qi,qj)/τ)+∑j≠imije(s(di+,dj)/τ)+∑j≠imije(s(qi,dj)/τ)Z_{i}=e^{\left(s\left(q_{i}, d_{i}^{+}\right) / \tau\right)}+\sum_{k}^{K} m_{i k} e^{\left(s\left(q_{i}, d_{i, k}^{-}\right) / \tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(q_{i}, q_{j}\right) / \tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(d_{i}^{+}, d_{j}\right) / \tau\right)}+\sum_{j \neq i} m_{i j} e^{\left(s\left(q_{i}, d_{j}\right) / \tau\right)}Zi=e(s(qi,di+)/τ)+∑kKmike(s(qi,di,k−)/τ)+∑j=imije(s(qi,qj)/τ)+∑j=imije(s(di+,dj)/τ)+∑j=imije(s(qi,dj)/τ)
其中,ZiZ_{i}Zi的 5 项相似度分别表示:
-
qiq_{i}qi与其对应的一条正样本di+d_{i}^{+}di+
-
qiq_{i}qi与其 K 个困难负样本di,k′−d_{i, k'}^{-}di,k′−
-
qiq_{i}qi与若干个其他批次内查询qjq_{j}qj
-
qiq_{i}qi对应的正样本di+d_{i}^{+}di+与若干个其他批次内文档djd_{j}dj
-
qiq_{i}qi与若干个其他批次内文档djd_{j}dj
掩码因子mijm_{ij}mij旨在减轻假阴性的影响,其定义为:
mij={0if sij>s(qi,di+)+0.1 or dj=di+,1otherwise.m_{ij} = \begin{cases} 0 & \text{if } s_{ij} > s(q_i, d_i^{+}) + 0.1 \text{ or } d_j = d_i^{+}, \\ 1 & \text{otherwise}. \end{cases}mij={01if sij>s(qi,di+)+0.1 or dj=di+,otherwise.
其中 sijs_{i j}sij是qiq_{i}qi、djd_{j}dj或qi,qjq_{i},q_{j}qi,qj的相应分数。
公式理解
- 温度。
温度越小,分布越尖锐,正样本与负样本的相似度经过 softmax 后差值越大。温度越大,分布越平滑,所有样本相似度接近。
- 掩码因子mijm_{ij}mij,防止误伤。
条件 1: sij>s(qi,di+)+0.1s_{ij} > s(q_i, d_i^+) + 0.1sij>s(qi,di+)+0.1
如果某个“负样本”与查询的相似度比正样本还高 0.1 以上,那么它很可能不是真正的负样本(可能是漏标的正样本或语义等价项)。
条件 2: dj=di+d_j = d_i^+dj=di+
如果两个样本共享同一个正文档(例如数据重复或一对多),那么 djd_jdj实际上是正样本,不能当作负样本。
- 4 个负样本计算项
第二项:困难样本作为负样本,掩码因子mijm_{ij}mij通过条件 1 来控制这些困难样本是否参与损失计算。
第三项:其他查询作为负样本,这一项假设了其他查询不应与当前查询高度相似,掩码因子mijm_{ij}mij通过条件 1 和 2 来过滤假阴性。
第四项:正文档与其他文档的相似度,这一项假设了正样本与其他批次内样本都是不相似的,掩码因子mijm_{ij}mij防止误伤。
第五项:批次内其他文档作为负样本,标准的 in-batch negative。
对于重排序模型,采用优化的有监督微调(SFT)损失定义为:
Lreranking=−logp(l∣P(q,d)),(2)L_{reranking }=-log p(l | \mathcal{P}(q, d)), (2)Lreranking=−logp(l∣P(q,d)),(2)
其中, p(⋅∣∗)p(\cdot | *)p(⋅∣∗)表示 LLM 的概率。对于正样本文档,标签 l 为“yes”;对于负样本文档,标签 l 为“no”。该损失函数使模型为正确的标签分配更高的概率,从而提升排序性能。
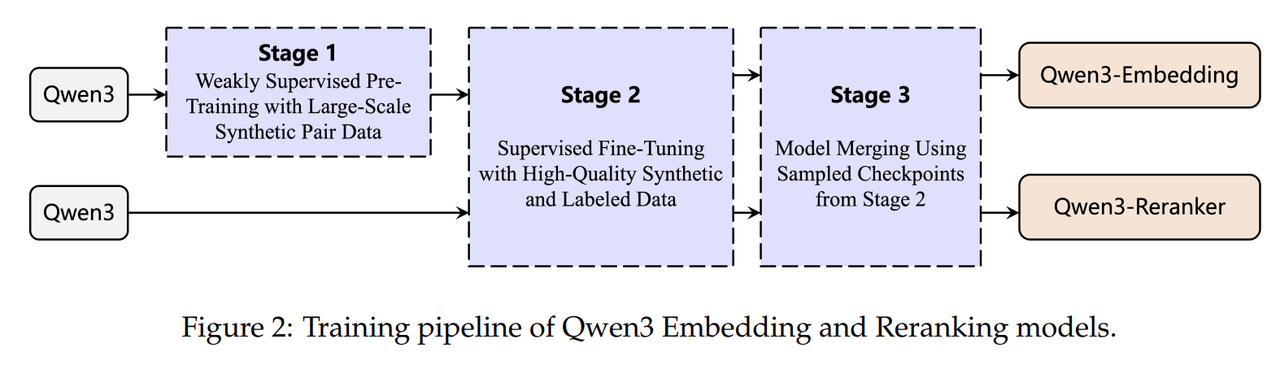
Multi-stage Training
多阶段训练方法是训练文本嵌入模型的常用做法。该策略通常先在包含噪声的大规模半监督数据上进行初始训练,然后使用规模更小、质量更高的监督数据集进行微调。嵌入模型的两个训练阶段均采用式 1 中定义的优化目标,而重排序模型的训练则采用式 2 中定义的损失函数作为优化目标。
在现有的多阶段训练框架基础上,Qwen3 Embedding 系列引入了以下关键创新:
-
大规模合成数据驱动的弱监督训练:与以往的研究(例如 GTE、E5、BGE 模型)不同,这些研究的弱监督训练数据主要来自问答论坛或学术论文等开源社区,论文提出利用基础模型的文本理解和生成能力来直接合成配对数据。这种方法允许在合成提示中任意定义所需配对数据的各个维度,如任务、语言、长度和难度。与从开放域来源收集数据相比,基础模型驱动的数据合成具有更强的可控性,能够精确管理生成数据的质量和多样性,特别是在低资源场景和语言中。
-
高质量合成数据在有监督微调中的应用:由于 Qwen3 基础模型的卓越性能,其生成的合成数据质量极高。因此,在有监督训练的第二阶段,有选择地纳入这些高质量合成数据,进一步提升了模型的整体性能和泛化能力。
-
模型融合:在完成有监督微调后,应用一种基于球面线性插值(slerp)的模型融合技术。该技术包括融合在微调过程中保存的多个模型检查点,旨在提高模型在各种数据分布中的鲁棒性和泛化性能。
重排序模型的训练过程不包含第一阶段的弱监督训练阶段。
嵌入模型的目标是学习通用的语义表示空间,这一任务对数据的广度和多样性要求很高,因此适合先在大规模(即使含噪声)弱监督数据上进行预训练;重排序模型的目标是在给定一个查询(query)和一组候选文档后,对这些候选进行精细化的相关性打分和排序,更关注细粒度的语义匹配和判别能力,对训练数据的质量、标注精度和任务对齐度要求极高,而对数据规模的依赖相对较低。
重排序模型,需要将 query 和 document 拼接后输入模型进行联合编码,输出相关性分数。这类模型的训练严重依赖高质量的标注对(如人工标注的相关/不相关标签),弱监督数据中的噪声会显著损害其判别性能。
Synthetic Dataset
通过使用 Qwen332B 模型生成了涵盖检索、平行文本挖掘、分类和语义文本相似度(STS)等类别的多样化文本对。
总共创建了约 1.5 亿对多任务弱监督训练数据。
生成数据采用了两阶段流程:
(1)配置阶段
在配置阶段,使用大模型来确定合成查询的 “问题类型”“难度” 和 “角色”,选择与给定文档最相关的前五个。所使用的模板如下:
Given a **Passage** and **Character**, select the appropriate option from three fields: Character, Question_Type, Difficulty, and return the output
in JSON format.
First, select the Character who are likely to be interested in the Passage
possible question based on the Passage, the Character, and the
from the candidates. Then select the Question_Type that the Character →
might ask about the Passage; Finally, choose the Difficulty of the →
→
Question_Type. →
Character: Given by input **Character**
Question_Type: - keywords: ...
- acquire_knowledge: ...
- summary: ...
- yes_or_no: ...
- background: ...
Difficulty: - high_school: ...
- university: ... - phd: ...
Here are some examples <Example1> <Example2> <Example3>
Now, generate the **output** based on the **Passage** and **Character** from user, the **Passage** will be in {language} language and the **Character** will be in English.
Ensure to generate only the JSON output with content in English.
**Passage**: {passage} **Character**: {character}
(2)查询生成阶段
在查询生成阶段,使用第一阶段选择的配置来指导查询的生成。此外,明确指定了生成查询的预期长度和语言。所使用的模板如下:
Given a **Character**, **Passage**, and **Requirement**, generate a query from the **Character**'s perspective that satisfies the **Requirement** and can be used to retrieve the **Passage**. Please return the result in JSON format.Here is an example: <example>
Now, generate the **output** based on the **Character**, **Passage** and language, the **Character** and **Requirement** will be in English. **Requirement** from user, the **Passage** will be in {corpus_language}
Ensure to generate only the JSON output, with the key in English and the value
in {queries_language} language.
**Character**
{character}
**Passage** {passage}
**Requirment**
- Type: {type}; - Difficulty: {difficulty};
- Length: the length of the generated sentences should be {length} words;
- Languange: the language in which the results are generated should be {language} language;
实验表明,使用这些合成数据训练的嵌入模型在下游评估中表现优异,尤其在 MTEB 多语言基准测试中超过了许多先前的有监督模型。这促使对合成数据进行筛选,以找出高质量的样本对,用于第二阶段的有监督训练。
采用简单的余弦相似度计算来选择数据对,从随机抽样的数据中保留余弦相似度大于 0.7 的样本对。最终,选出了约 1200 万对高质量的有监督训练数据对用于进一步训练。
Evaluation
Embedding 模型在 MTEB 多语言、中英文、代码榜单上 SOTA。
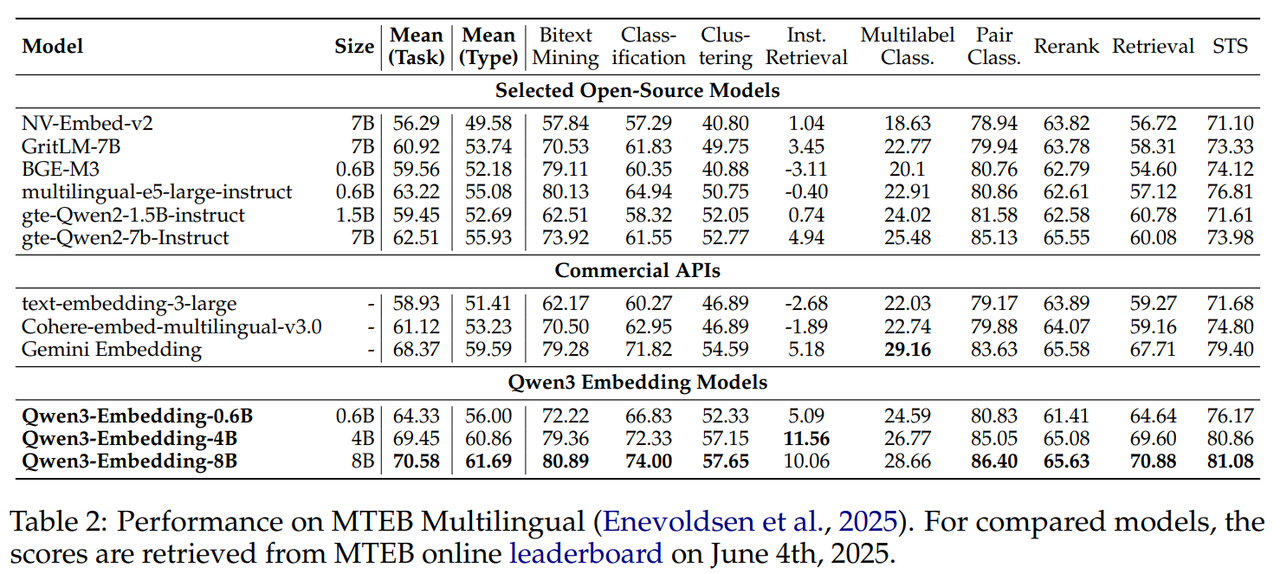
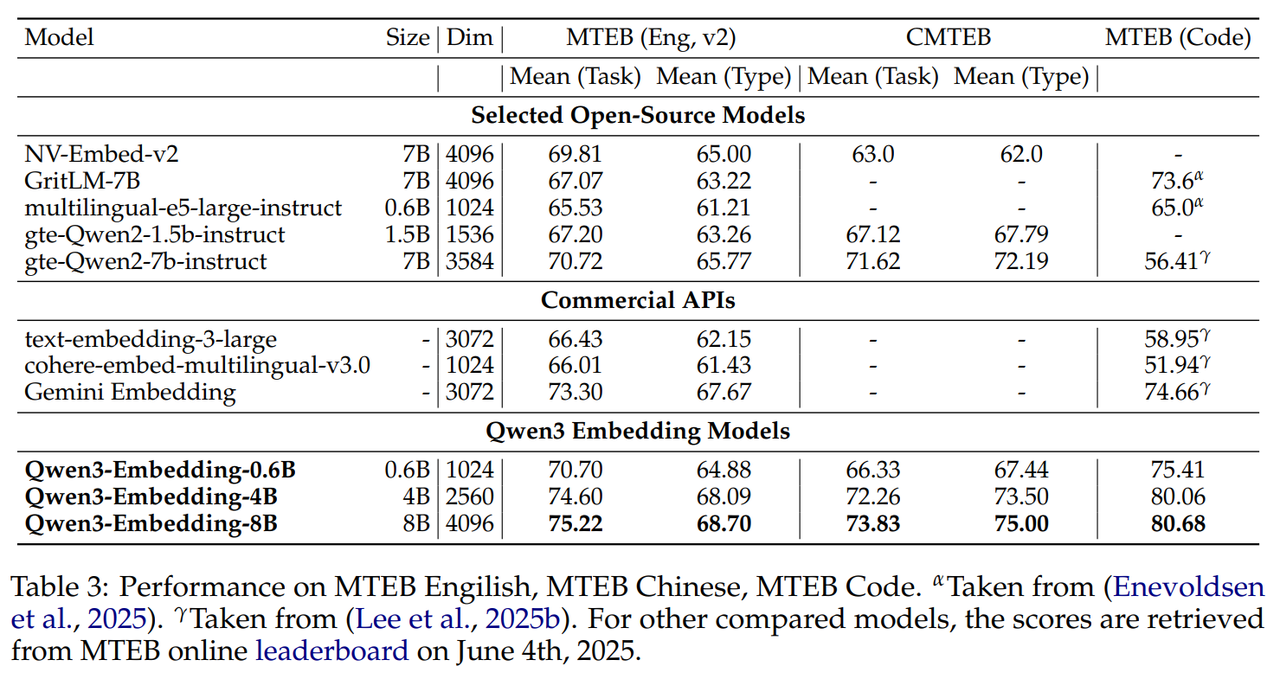
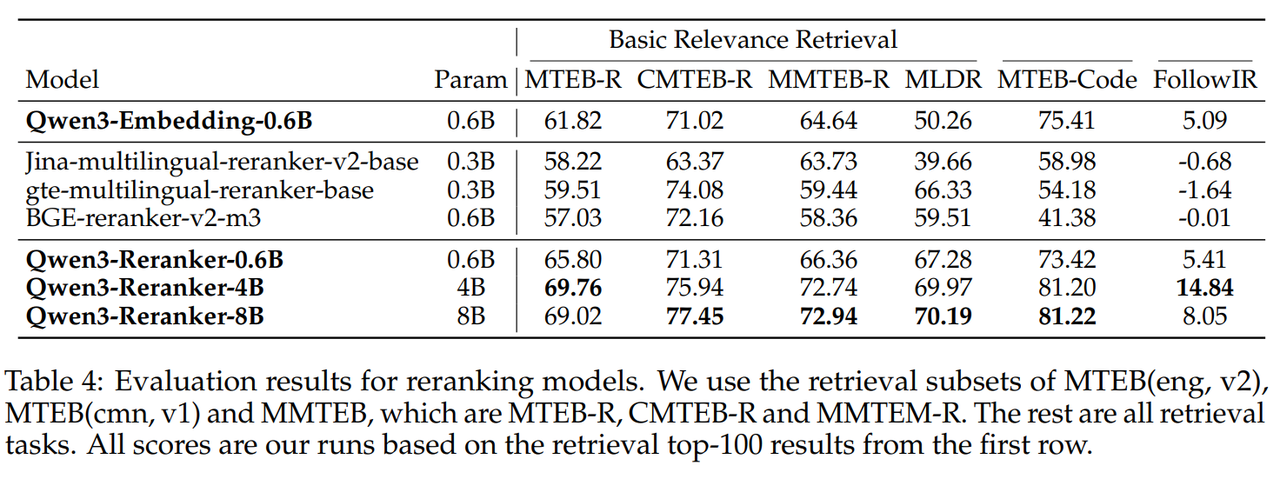
Reranker 模型效果也 SOTA。
Embedding 模型消融实验如下,