GPT-1 技术报告
关键词:
GLUE, NLI, Entailment, F1, PC, MC
GPT-1 是一个阶段实验报告, 文章类似博客形式发表,发表时注明该模型还在研发阶段。
原文 《Improving Language Understanding by Generative Pre-Training, 2018》
- link: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
1.概述 (Introduction & Related Work)
Transformer架构优势明显:能处理长程依赖,提高迁移性能,优于LSTM。其有以下两点趋势:
-
数据范式:
- 生成式(generative):预测文本序列,用无标签数据预训练。
- 判别式(discriminative):直接预测标签,需要标注数据,用于微调。
-
双阶段训练:
- 生成式预训练 (Pre-train)+ 判别式微调(Fine-tuning)是NLP任务的有效策略,可充分利用大量无标签文本。
- 任务无关的通用表示可迁移到多种下游任务 (Pre-train),只需最小架构调整即可显著超越专门设计的判别式模型(Fine-tuning)。
2. 方法部分 (Framework)
2.1 损失函数
- 无监督预训练 (Unsupervised pre-training)
- 有监督微调 (Supervised fine-tuning)
- 改进微调 ,在微调时加上语言建模损失,作为辅助目标(auxiliary objective)
- 提高监督模型的泛化能力;
- 加速收敛。
| 阶段 | 目标 | 数据类型 | 核心思想 | 输出 |
|---|---|---|---|---|
| 预训练 | 最大化语言模型似然 (L_1) | 无标签文本 | 学习通用语言表示 | Transformer 解码器权重 |
| 微调 | 最大化监督目标 (L_2) | 带标签任务 | 学习任务特定能力 | 分类或推理预测结果 |
| 联合目标 | (L_3 = L_2 + λ\lambdaλ L_1) | 有标签任务 + 辅助语言建模 | 稳定收敛,防止过拟合 | 改进泛化性能 |
- 常用两类损失函数
| 特性 | Cross-Entropy | F1 Loss |
|---|---|---|
| 优化目标 | 最大化单个样本的正确分类概率 | 最大化整体 Precision-Recall 平衡 |
| 类别不平衡 | 容易偏向多数类 | 对少数类更敏感 |
| 可微性 | 完全可微 | 需要 soft 近似处理 |
| 应用场景 | 大多数分类任务 | 类别严重不平衡,或想直接优化 F1-score 的任务 |
2.2 微调
NLP的下游任务可以归纳为分类任务,即双选/多选题,具体如下:
| 任务 | “下一个逻辑单元” 的含义 |
|---|---|
| 分类任务 | 类别标签(text label 或特殊token) |
| 蕴含/相似性 | 二分类或多分类, 关系标签包括(entailment-contradiction-neutral / similar / dissimilar) |
| 问答 | 正确答案候选 |
| 语言建模 | 下一个词(自然语言token) |
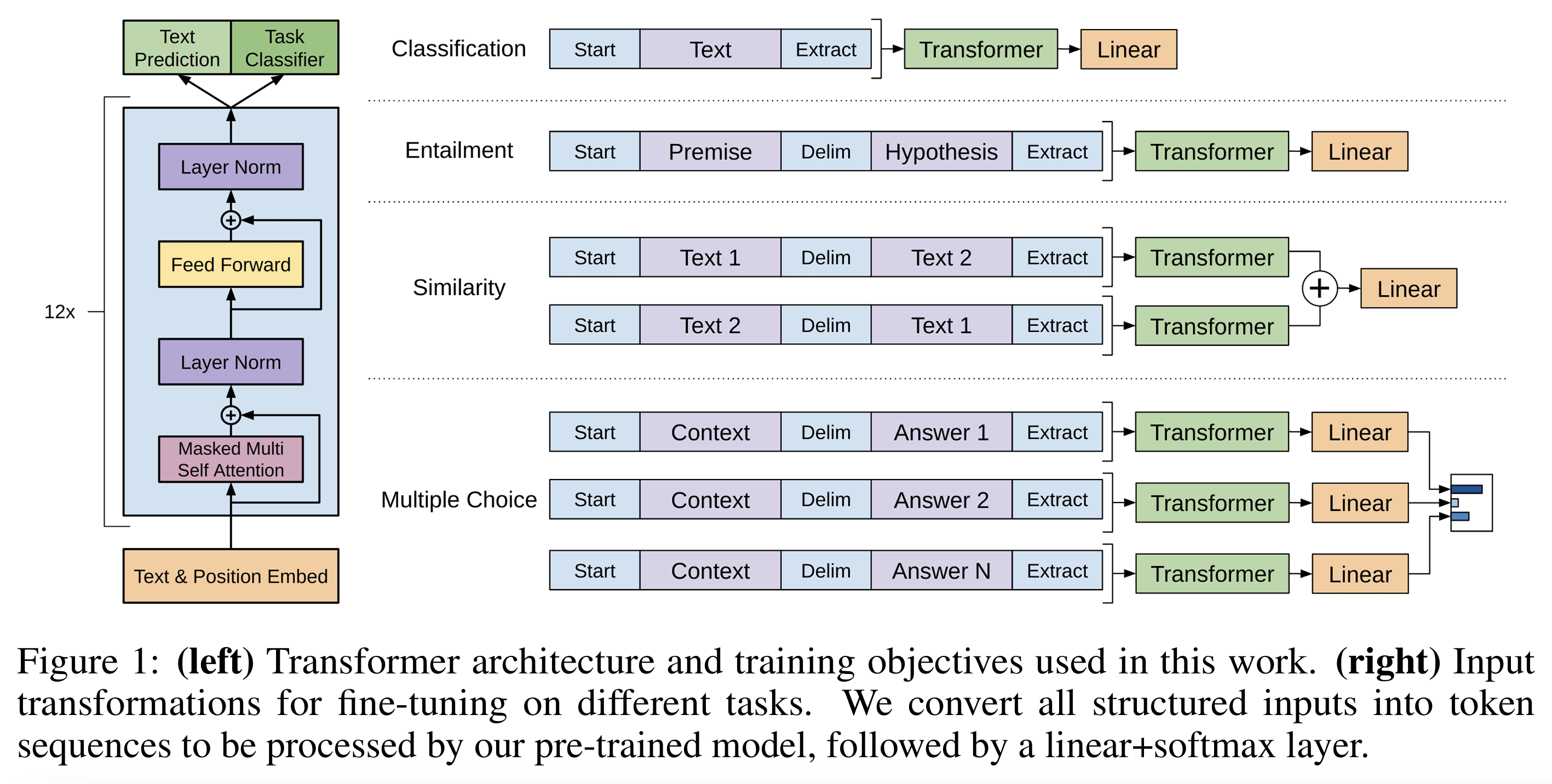
- 输出
| 任务类型 | 输入格式(示例) | 输出内容 | 输出解释 |
|---|---|---|---|
| 1️⃣ 文本分类 (Text Classification) | [<s>, text, </s>] | 类别标签的概率分布 | 模型最后一个 token 的表示 → 线性+softmax → 输出类别概率。 例如情感分类输出 [positive, negative] 两类概率。 |
| 2️⃣ 文本蕴含 (Textual Entailment) | [<s>, 前提(premise), $, 假设(hypothesis), </s>] | 三类概率: entailment (蕴含)/ contradiction(矛盾) / neutral(中立) | 模型输出一个分类概率分布,判断假设是否被前提蕴含。 |
| 3️⃣ 相似度任务 (Sentence Similarity) | 两个输入顺序:[<s>, s1, $, s2, </s>] 与 [<s>, s2, $, s1, </s>] | 相似度得分(实数或类别) | 两个方向的输出 hidden 向量求和,再经线性层 → softmax(或回归值)。 |
| 4️⃣ 问答 / 常识推理 (QA / Commonsense Reasoning) | [<s>, context, question, $, answer_k, </s>] (每个候选答案独立输入) | 候选答案分布 | 模型对每个 [z;q;$;a_k] 输出一个标量得分,经 softmax 得到“正确答案”。 |
- 模型输出结构
如图:
2.3 实验设置部分
-
Unsupervised pre-training
- 数据集:
- 使用 BooksCorpus 数据集:包含 7000+ 未出版书籍,涵盖冒险、奇幻、爱情等多种体裁。
- 特点:文本连续性强,有利于模型学习长程依赖。
- 对比数据集:1B Word Benchmark(ELMo 使用)大小相近,但其句子打乱,无长程结构。
- 模型性能:在 BooksCorpus 上, token-level perplexity = 18.4。
- 数据集:
-
Model specifications
-
架构:
- 12 层 decoder-only Transformer,带 masked self-attention。
- 隐藏层维度:768,注意力头数:12。
- 前馈网络维度:3072。
-
训练参数:
- 优化器:Adam,最大学习率 2.5e-4。
- 学习率调度:前 2000 步线性升高,之后采用余弦衰减(cosine schedule)。
- 训练周期:100 epochs,每批 64 个随机采样的 512-token 连续序列。
- 正则化:LayerNorm 全局使用,权重初始化 N(0,0.02) 足够。
- Dropout:残差、embedding、attention 均 0.1。
- L2 正则化:非 bias/gain 权重 w=0.01。
- 激活函数:GELU。
-
位置编码:学习位置 embedding(learned),替代 Transformer 原文的 sinusoidal 位置编码。
-
分词与文本预处理:
- 使用 BPE,40,000 merges。
- 使用 ftfy 清洗文本,标准化标点/空格。
- 使用 spaCy tokenizer。
-
Fine-tuning details
- 超参数继承:除非特别说明,否则沿用预训练设置。
- 额外Dropout:在分类头上加0.1的dropout。
- 学习率:6.25×10⁻⁵(比预训练小,防止灾难性遗忘)。
- batch size:32
- 训练轮数:一般3个epoch就收敛。
- 学习率调度:
- 前0.2%的训练步骤warmup;
- 线性下降(linear decay)。
- 损失函数:任务相关(分类通常为cross-entropy)。
-
3. 实验 Experiments
实验涉及多任务类型数据, 具体如表1:

3.1 GLUE
GLUE(General Language Understanding Evaluation)是在 2018 年提出的多任务自然语言理解基准,目的是让模型学习到多任务的通用语言理解能力,并评测模型在多任务上的泛化能力,多任务类型包括:
- 自然语言推理(NLI)
- 句子相似度(Semantic Similarity)
- 文本蕴含(Entailment)
- 情感分类(Sentiment Classification)
- 可接受性判断(Acceptability Judgment)
- 语义等价(Paraphrase Detection)等。
原始 GLUE 论文(2018)中介绍的任务共 9 个主任务(部分任务包含多个子集),如下:
| 类型 | 数据集名称 | 简介 |
|---|---|---|
| 单句分类 | CoLA (Corpus of Linguistic Acceptability) | 判断句子语法是否可接受(binary) |
| SST-2 (Stanford Sentiment Treebank) | 判断影评句子的情感极性(positive / negative) | |
| 句子对分类 | MRPC (Microsoft Research Paraphrase Corpus) | 判断两句是否语义等价(paraphrase) |
| QQP (Quora Question Pairs) | 判断两句 Quora 问题是否意思相同(duplicate) | |
| 自然语言推理 | MNLI (Multi-Genre NLI) | 判断句子对间关系(entailment / contradiction / neutral) |
| QNLI (Question NLI) | 从 SQuAD 改造,用于判定答案句是否蕴含问题(entailment / not-entailment) | |
| RTE (Recognizing Textual Entailment) | 整合 RTE1~RTE5,判断文本是否蕴含假设句 | |
| WNLI (Winograd NLI) | 基于 Winograd Schema,测试代词指代推理能力 | |
| 语义相似度回归 | STS-B (Semantic Textual Similarity Benchmark) | 句对相似度评分(1~5) |
| 自然语言推理多域验证 | MNLI-m / MNLI-mm | 分别代表 matched(同域)与 mismatched(异域)评测集 |
在Hugging Face Datasets中,将MNLI分为两个子集,并增加 AX集 (Analysis Set), 如图:
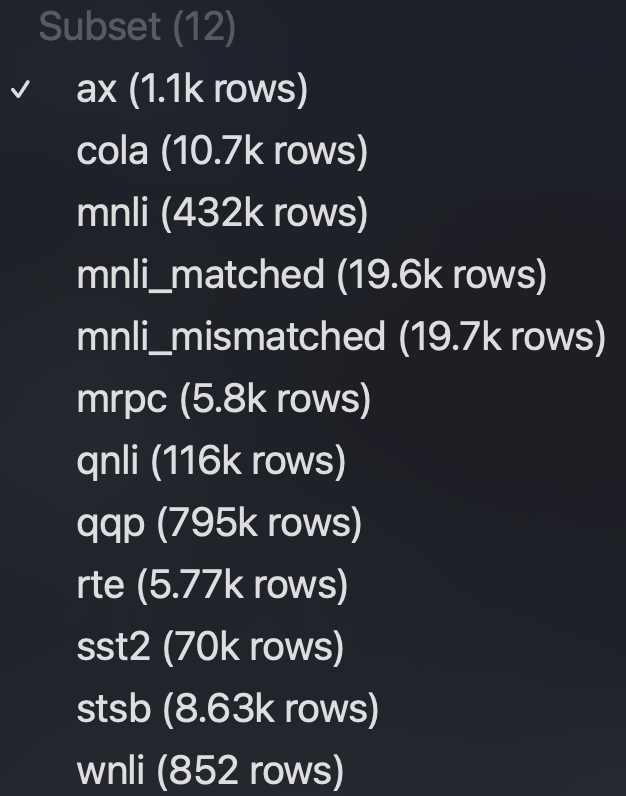
其中AX是一个人工构造的小规模评测集,大约 1100 个样本,由语言学专家人工编写,专门用来诊断模型在不同语言现象上的理解能力。
AX不计入 GLUE 总分(GLUE score),只用于分析模型的语言学行为和推理能力,分数一般在 20–50 之间。
3.1 NLI数据集
定义:给定一对句子 (T, H),判断 T 是否能蕴含 H(T ⇒ H)
-
二分类:如果 T 为真,H 是否也必然为真?
-
三分类:若不为真,句子T,H的逻辑是对立关系(contradiction),还是无关系(neutral)
NLI数据集包括
SNLI, MultiNLI, QNLI, RTE, SciTail
基本介绍如下:
| 任务 | 输入类型 | 标签类别 | 数据来源 | 任务重点 |
|---|---|---|---|---|
| SNLI | (premise, hypothesis) | entail / neutral / contra | 图像 caption | 推理语义关系 |
| MNLI | (premise, hypothesis) | entail / neutral / contra | 多领域文本 | 泛化能力 |
| RTE | (premise, hypothesis) | entail / not_entail | 多任务融合小集 | 少样本 |
| QNLI | (question, sentence) | entail / not_entail | Wikipedia QA 转换 | 语义匹配与问答逻辑 |
| SciTail | (sentence1, sentence2) | entail / neutral | 科学考试 QA 转换 | 科学推理 |
3.1.1 RTE
RTE (Recognizing Textual Entailment)是最早系统化定义“语义蕴含”任务的项目(始于 2005 年),由 PASCAL (Pattern Analysis, Statistical Modelling and Computational Learning) Recognizing Textual Entailment Challenge 发起。
RTE是早期 NLI 标准任务,数据少、领域广,无法通过大规模训练记忆,需靠语言理解泛化能力,考验语言理解的泛化能力。
RTE1–RTE5 是自然语言推理任务的演化轨迹:从最初的“句子级语义蕴含” → “跨句推理” → “文档更新检测”。
为后来 SNLI、MNLI、QNLI 等大规模 NLI 数据集奠定了定义、格式与评测标准:
| 届数 | 年份 | 规模 | 来源 | 新特征 | 难度 |
|---|---|---|---|---|---|
| RTE-1 | 2005 | 800 | 新闻、QA、IE | 定义任务 | ⭐ |
| RTE-2 | 2006 | 800 | QA、IE、IR | 增加dev、标准化 | ⭐⭐ |
| RTE-3 | 2007 | 800 | QA、MT、IE | 句子更长、标注更严 | ⭐⭐⭐ |
| RTE-4 | 2008 | 1000 | 新闻、Wiki | 文档级pilot任务 | ⭐⭐⭐⭐ |
| RTE-5 | 2009 | 1200 | 新闻更新检测 | 跨文档更新推理 | ⭐⭐⭐⭐ |
相关版本:
| 子集 | 年份 | 来源 | 样本数 |
|---|---|---|---|
| RTE1–RTE5 | 2005–2009 | 新闻、问答、信息抽取 | 各 800–1600 |
| SICK (RTE-like) | 2014 | 图片描述、句法转换 | 10k |
| GLUE 中 RTE | 合并自 RTE1–RTE5 + SICK + SNLI 小样本 | 2.5k 训练样本 |
GLUE 作者将这些数据统一清洗为一个标准格式(两句 + Entailment / Not Entailment 标签)。
3.1.2 SNLI (Stanford Natural Language Inference Corpus)
SNLI 由斯坦福大学在 2015 年提出,核心目标是创建一个大规模、自然、语义多样的 NLI 数据集。
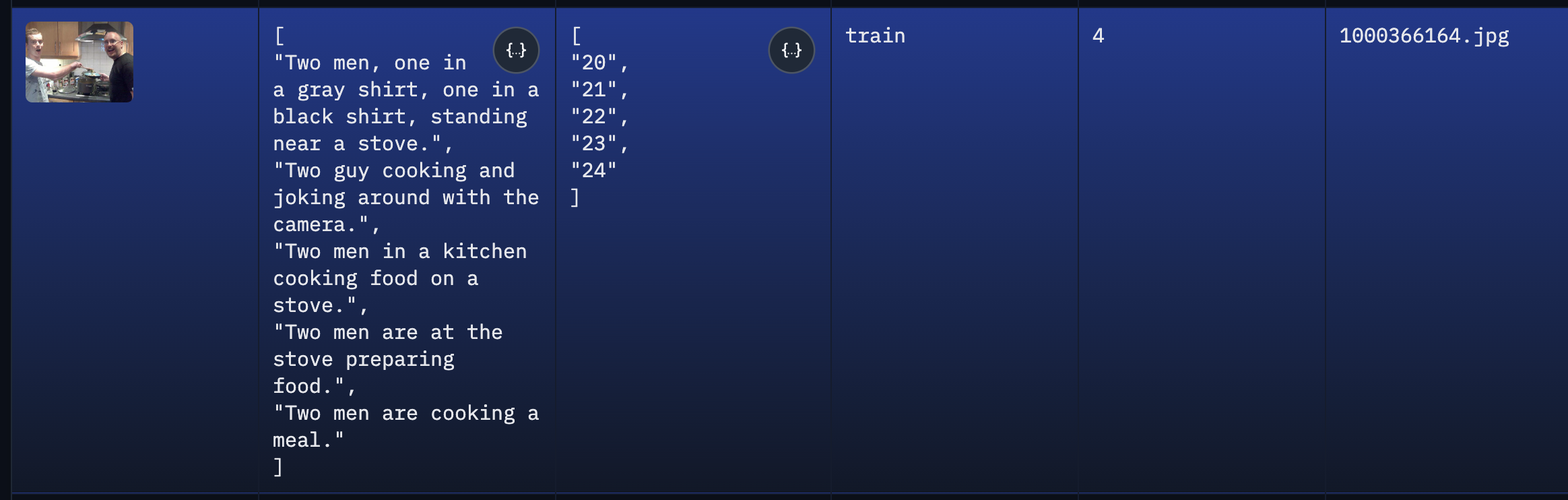
为了让句子语义自然,其选用图像描述数据集 Flickr30k 的文本标题(caption)作为前提句(premise)。
- Flickr30k 数据基础:
| 项目 | 内容 |
|---|---|
| 数据集名称 | Flickr30k |
| 图片数量 | 31,783 张 |
| 每张图片的标题数 | 5 条 captions(由人工撰写) |
| 总标题数(caption 数量) | 约 31,783 × 5 ≈ 158,915 条 |
具体如下:
- SNLI 的样本生成机制
| 步骤 | 内容 |
|---|---|
| ① | 从 Flickr30k 数据集中选取数10万条图像描述(caption),如: → “A man is playing a guitar on stage.” |
| ② | 将每条caption作为前提句 (premise)。 |
| ③ | 使用众包平台(Amazon Mechanical Turk, AMT)让人工标注者为每个前提句编写三种类型的假设句 (hypothesis): 必然为真(Entailment)— 必然为假(Contradiction)— 真假不定(Neutral) |
| ④ | 收集标注者写出的句子,形成成对的文本样本(premise, hypothesis, label)。 |
每个前提句有 5个标注者标记 3个标签类型,即一个前提句可生成 15 个假设句,共150w句对。经过筛选、验证和清理后,最终得到约 57 万个高质量句对。
3.1.3 MultiNLI(Multi-Genre Natural Language Inference)
MNLI(MultiNLI) 是 SNLI 的扩展版,它包含来自 10 种语体(genres) 的英文文本,例如:
- Fiction(小说)
- Telephone speech(电话语音)
- Government reports(政府文件)
- Slate magazine(新闻评论)
- Travel guides(旅游指南)等。
每个样本都是一个句子对(premise, hypothesis),任务是预测它们的关系:
entailment(蕴含) / contradiction(矛盾) / neutral(中立)。
MNLI包含:MNLI-m(matched) 和 MNLI-mm(mismatched):
| 名称 | 含义 | 举例 | 评估目的 |
|---|---|---|---|
| MNLI-matched (MNLI-m) | 同域测试集(matched):测试数据来自与训练集相同的语体(genre) | 如果模型在“fiction”语体上训练,那么测试样本也来自“fiction”等已见过的域 | 检查模型在熟悉领域中的泛化性能 |
| MNLI-mismatched (MNLI-mm) | 异域测试集(mismatched):测试数据来自与训练集不同的语体 | 模型在“fiction”等上训练,但在“telephone speech”或“government reports”上测试 | 检查模型在**未见领域(out-of-domain)**的泛化能力 |
- 具体结构:
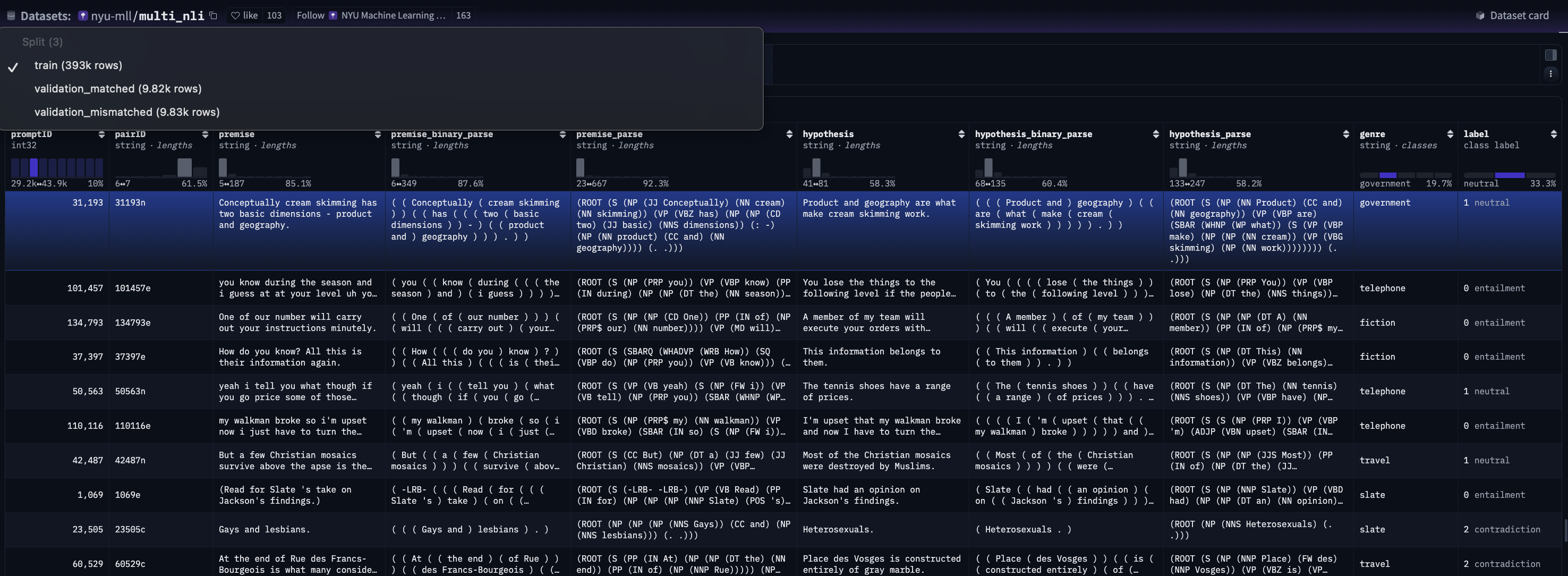
- glue版本:
3.1.4 QNLI (Question NLI)
QNLI 是 GLUE Benchmark(2018) 的核心八个子任务之一。由问答任务(SQuAD)改造成的自然语言推理(NLI)任务。
基本信息:
| 项目 | 内容 |
|---|---|
| 全名 | Question-answering Natural Language Inference (QNLI) |
| 来源 | 由 SQuAD v1.1 (Stanford Question Answering Dataset) 改造而来 |
| 任务类型 | 二分类 (Binary classification) |
| 输入形式 | (question, sentence) 对 |
| 输出标签 | “entailment” / “not entailment”(是否能回答问题) |
| 评测指标 | Accuracy |
| 所属类别 | 自然语言推理(NLI)类任务 |
| GLUE 任务编号 | 通常排第 7 位 |
- SQuAD v1.1
一个抽取式问答任务:
- 输入:一个文章段落 + 一个问题
- 输出:从文章中抽取出一个片段作为答案
例如:
Paragraph: “The Eiffel Tower is located in Paris.”
Question: “Where is the Eiffel Tower located?”
Answer: “in Paris.”
- 转换方式
| 原 SQuAD 元素 | QNLI 对应形式 |
|---|---|
| Question | Premise / Sentence 1 |
| Context Sentence | Hypothesis / Sentence 2 |
| 是否包含正确答案? | NLI 标签(entailment / not entailment) |
如果该句子中包含回答问题所需的信息 → “entailment”;否则 → “not entailment”。
- 数据量
| 数据集 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| QNLI | ≈ 105K | ≈ 5.4K | ≈ 5.4K |
- HF的格式
3.1.5 SciTail
SciTail 是由 AI2 的科学问答数据集(Science Question Answering Dataset) 用脚本自动构造的。
-
构造过程
- 从 science QA 数据集 中选取问题及正确答案;
- 将 question + correct answer 组合成 hypothesis;
- 从包含该问题的相关文档(或支持证据)中选取句子作为 premise;
- 若 premise 能支持 hypothesis → entailment;若不能 → neutral(注意:没有 contradiction 标签)。
-
数据特征
| 特征 | 说明 |
|---|---|
| 科学领域特化 | 全部语料来源于 science QA,测试知识推理 |
| 由 QA → NLI 转换 | 与 QNLI 类似,都是“句对化问答”任务 |
| 标签为二分类(entail / neutral) | 没有 contradiction,语义判定更细腻 |
| 考察常识+科学知识 | 需要模型具有一定 factual & commonsense reasoning 能力 |
- 数据规模
| 集合 | 样本数 |
|---|---|
| 训练集 | ≈ 23K |
| 验证集 | ≈ 1.3K |
| 测试集 | ≈ 2.1K |
- 数据样例
3.2 NLI任务评测
各数据集评测结果:
| 数据集 | 来源领域 | 特点 | 模型提升幅度 |
|---|---|---|---|
| SNLI | 图像标题 | 语义简单但结构规范 | +0.6% |
| MNLI (MultiNLI) | 多领域 | 演讲/小说/新闻/政府报告等覆盖广、难度高 | +1.5% |
| QNLI (Question NLI) | Wikipedia | 由问答任务转化为NLI | +5.8% |
| SciTail | 科学考试 | 科学知识推理 | +5% |
| RTE | 新闻报道 | 传统小规模RTE任务,未使用多任务训练 | 56%(低于对比模型61.7%) |
准确率结果如表2:
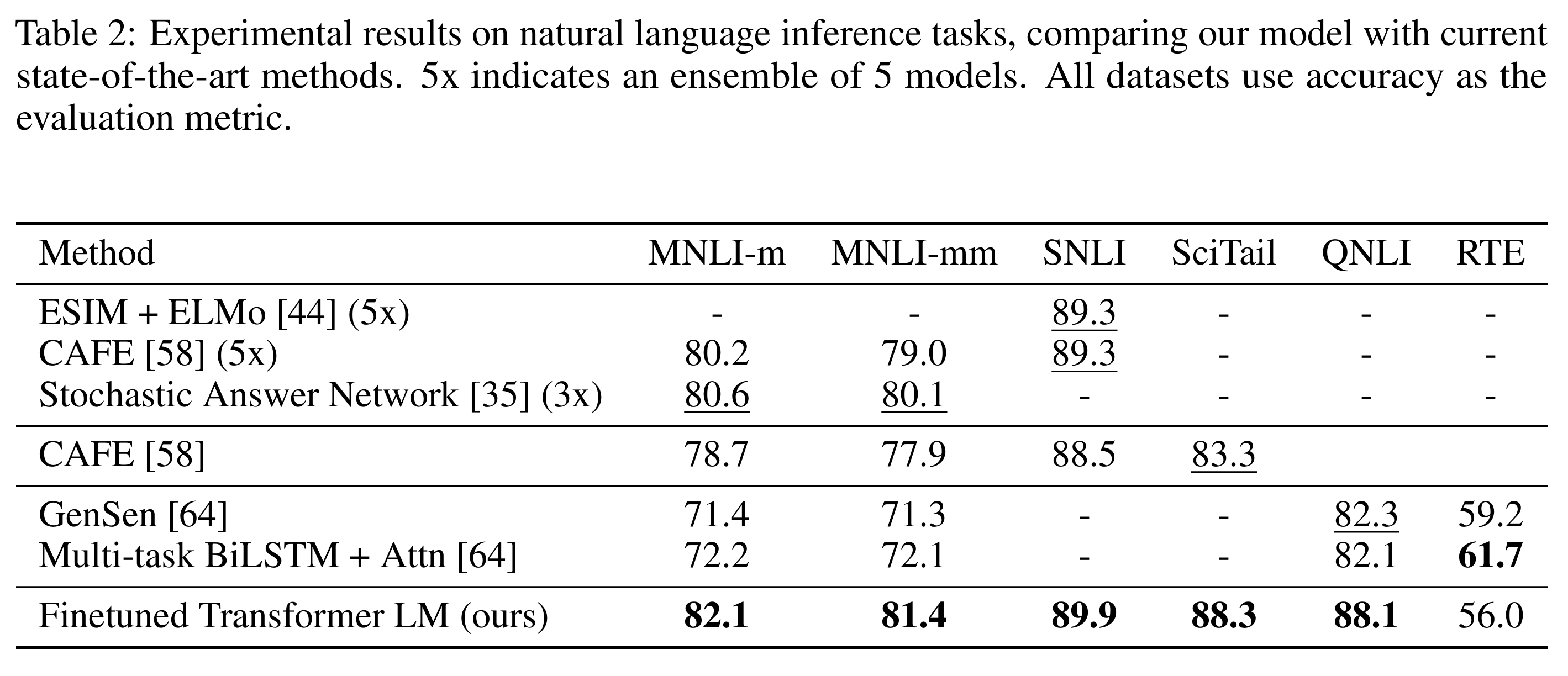
其中MNLI-m/mm 分别为 matched / mismatched(同域/异域)评估集
4. QA-知识问答
问答与常识推理(Question Answering & Commonsense Reasoning)包括Story Cloze, RACE。
测试模型的多句理解能力、长文本阅读理解能力与常识逻辑推理。
4.1 Story Cloze
常识推理 (commonsense reasoning) 的经典 benchmark。
每个样本是一个 四句开头 + 两个候选结尾,选择一个更合理结尾(二选一)。
模型需要理解叙事逻辑 + 人类常识 + 情感合理性。示例:
Context (前四句)
1. John went to the kitchen.
2. He saw a big cake on the table.
3. He was very hungry.
4. He picked up a knife.Two possible endings:
* (A) He cut the cake and had a slice. ✅
* (B) He washed the knife and put it away. ❌
4.2 RACE
RACE (Reading Comprehension Dataset from Exams),中国中高考英语题。
涉及长文本理解、多句推理、词汇消歧义与推测人物意图。
模型不仅要“找句子”,还要能“理解整篇文章结构与上下文逻辑”。
| 项目 | 内容 |
|---|---|
| 来源论文 | Lai et al., “RACE: Large-scale ReAding Comprehension Dataset From Examinations” EMNLP 2017 |
| 数据来源 | 中国初高中英语考试题(middle & high school, 12 to 18 岁) |
| 任务类型 | Multi-choice reading comprehension(4选1,阅读理解) |
| 规模 | 约 27,933 篇文章,97,687 个问题,约 280,000 个选项 |
| 评测指标 | Accuracy(正确选项选择率) |
- 三个子集
| 子集 | 名称 | 来源 | 难度 | 文章数 / 问题数 | 主要特点 |
|---|---|---|---|---|---|
| RACE-m | Middle school subset | 初中英语考试 | ⭐⭐(中等) | ~6,409 篇 / 25,421 问题 | 句子短、选项易辨别、推理浅显 |
| RACE-h | High school subset | 高中英语考试 | ⭐⭐⭐⭐(困难) | ~21,524 篇 / 72,266 问题 | 篇章长、题目更抽象、涉及推理与隐含信息 |
| RACE | 合集 (RACE-m + RACE-h) | 全体 | 混合 | 27,933 篇 / 97,687 问题 | 综合性评测 |
4.3 测试性能
-
结果
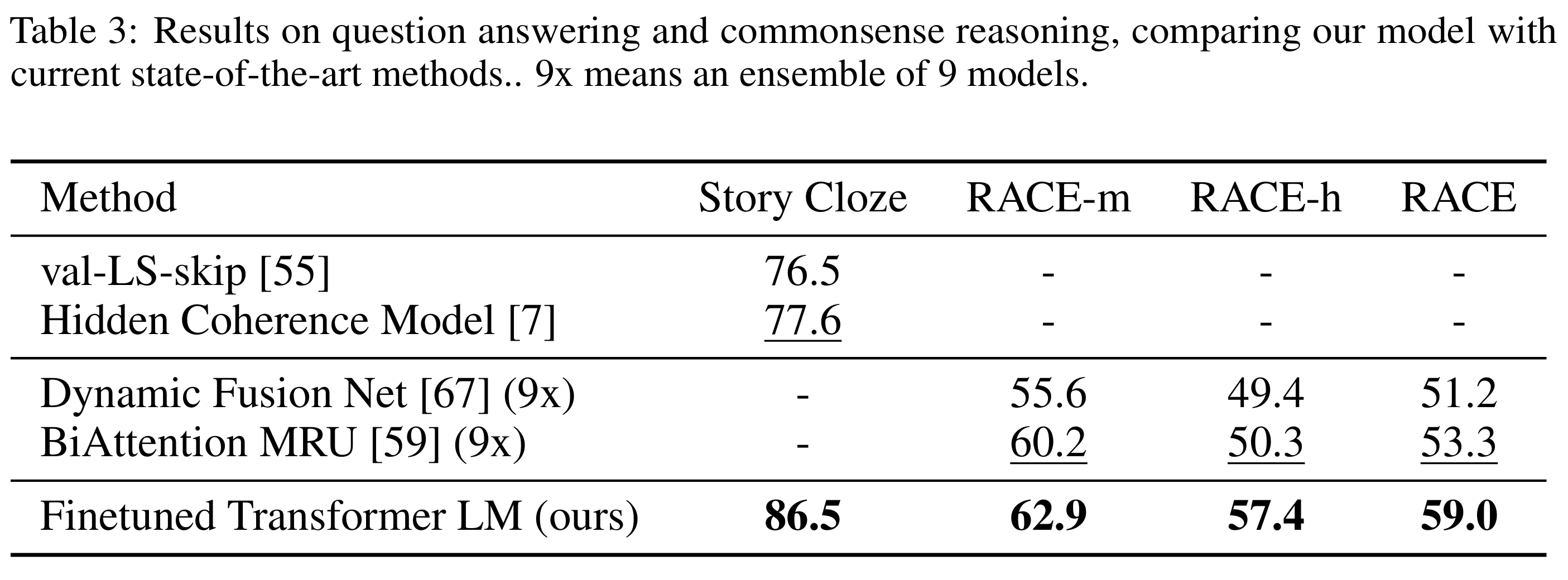
- Story Cloze:86.5%,比前最佳(77.6%)提升 +8.9%
- RACE-m:62.9%,RACE-h:57.4%,整体 RACE:59.0%,总体提升+5%以上
-
结论
- GPT-1 的 Transformer LM 经过下游任务微调(fine-tuning)后,显著优于此前基于 RNN 与融合网络的模型。
- 在两个任务中都表现出强跨句推理与长程依赖建模能力。
具体结果如表3所示:
5. 分类&语义相似-数据集
- 分类: CoLA, SST2
- Semantic Similarity: MRPC, STSB, QQP
- 综合GLUE
- 数据集分类
| 任务类型 | 数据集 | 核心能力 | 输出类型 |
|---|---|---|---|
| 分类 | CoLA | 语法理解 | MC |
| 分类 | SST-2 | 情感分析 | Accuracy |
| 语义相似性 | MRPC | 句子重写判定 | F1 / Acc |
| 语义相似性 | STS-B | 语义相似度评分 | Pearson / Spearman Correlation |
| 语义相似性 | QQP | 问题重复判定 | F1 / Acc |
| 综合 | GLUE | 多任务迁移能力 | 各子任务指标综合 |
- 评价指标
| 数据集 | 样本分布 | 使用指标 |
|---|---|---|
| SST-2 | 平衡 | Accuracy 足够 |
| MRPC | 正例少,负例多 | F1 更能衡量模型识别少数类能力 |
| QQP | 正例少,负例多 | 同上 |
| CoLA | 二分类但不平衡 | 使用 Matthew’s Correlation (MC) 更适合语法可接受性判断 |
| STS-B | 连续评分 | 用 Pearson / Spearman 衡量线性和秩相关性 |
-
离散标签
- Acc: 样本分类平衡
- F1 : 侧重评估模型对正类的分类表现
- MC: 样本不平衡时替代Acc,需要衡量正负分类的一致性
-
连续性输出(回归问题)
- Pearson Correlation: 两个连续变量的线性相关程度, 衡量“数值精确匹配度”
- Spearman Correlation: 两个变量的秩(rank)相关性, 衡量“排序一致性”
5.1 分类数据集 (Classification)
5.1.1 CoLA (Corpus of Linguistic Acceptability)
| 项目 | 内容 |
|---|---|
| 类型 | 二分类 (binary classification) |
| 任务 | 判断句子是否符合英语语法(grammatical vs ungrammatical) |
| 数据来源 | 来自语言学论文和语料库,由专家标注 |
| 样本量 | 8,551 训练样本 / 1,043 验证 / 1,064 测试 |
| 评测指标 | Matthew’s Correlation (MC) |
| 难点 | 语法感知任务,模型需捕捉深层语言结构和句法规则 |
| 研究意义 | 测量模型的语法敏感性和语言规则理解能力 |
5.1.2 SST-2 (Stanford Sentiment Treebank 2)
| 项目 | 内容 |
|---|---|
| 类型 | 二分类 (binary classification) |
| 任务 | 句子级情感分类(正面/负面) |
| 数据来源 | IMDb 影评语料 |
| 样本量 | 67,349 训练 / 872 验证 / 1,821 测试 |
| 评测指标 | Accuracy |
| 难点 | 情感表达通常依赖于上下文、否定词、词序,甚至讽刺 |
| 研究意义 | 测量模型对情感理解的能力,是典型文本分类任务 |
5.2 语义相似性任务 (Semantic Similarity)
5.2.1 MRPC (Microsoft Research Paraphrase Corpus)
| 项目 | 内容 |
|---|---|
| 类型 | 二分类 (paraphrase / not paraphrase) |
| 任务 | 判断两句话是否在语义上等价 |
| 数据来源 | 新闻文本对,Microsoft Research 提供 |
| 样本量 | 3,668 训练 / 408 验证 / 1,725 测试 |
| 评测指标 | F1-score / Accuracy |
| 难点 | 需要理解同义改写、否定、语序变化和语义消歧 |
| 研究意义 | 测量模型的语义理解和句子级推理能力 |
5.2.2 STS-B (Semantic Textual Similarity Benchmark)
| 项目 | 内容 |
|---|---|
| 类型 | 回归 (0–5 分的相似度评分) |
| 任务 | 预测两句子语义相似度(连续值) |
| 数据来源 | 来自新闻、论坛、Wikipedia、图片描述等多种语料 |
| 样本量 | 5,749 训练 / 1,500 验证 / 1,379 测试 |
| 评测指标 | Pearson / Spearman correlation |
| 难点 | 精细的语义判断,区分部分重叠、逻辑相反或上下文不同的句子 |
| 研究意义 | 测量模型的语义相似度理解能力,用于下游检索、QA 等任务 |
5.2.3 QQP (Quora Question Pairs)
| 项目 | 内容 |
|---|---|
| 类型 | 二分类 (duplicate / not duplicate) |
| 任务 | 判断两个 Quora 问题是否语义重复 |
| 数据来源 | Quora 网站公开数据 |
| 样本量 | 364,000 训练 / 40,000 验证 / 390,000 测试 |
| 评测指标 | F1-score / Accuracy |
| 难点 | 问题可能用不同方式表达同一个意思,需理解同义替换和长短句 |
| 研究意义 | 测量模型问句语义匹配能力,对 FAQ、问答系统很重要 |
5.3 性能评测
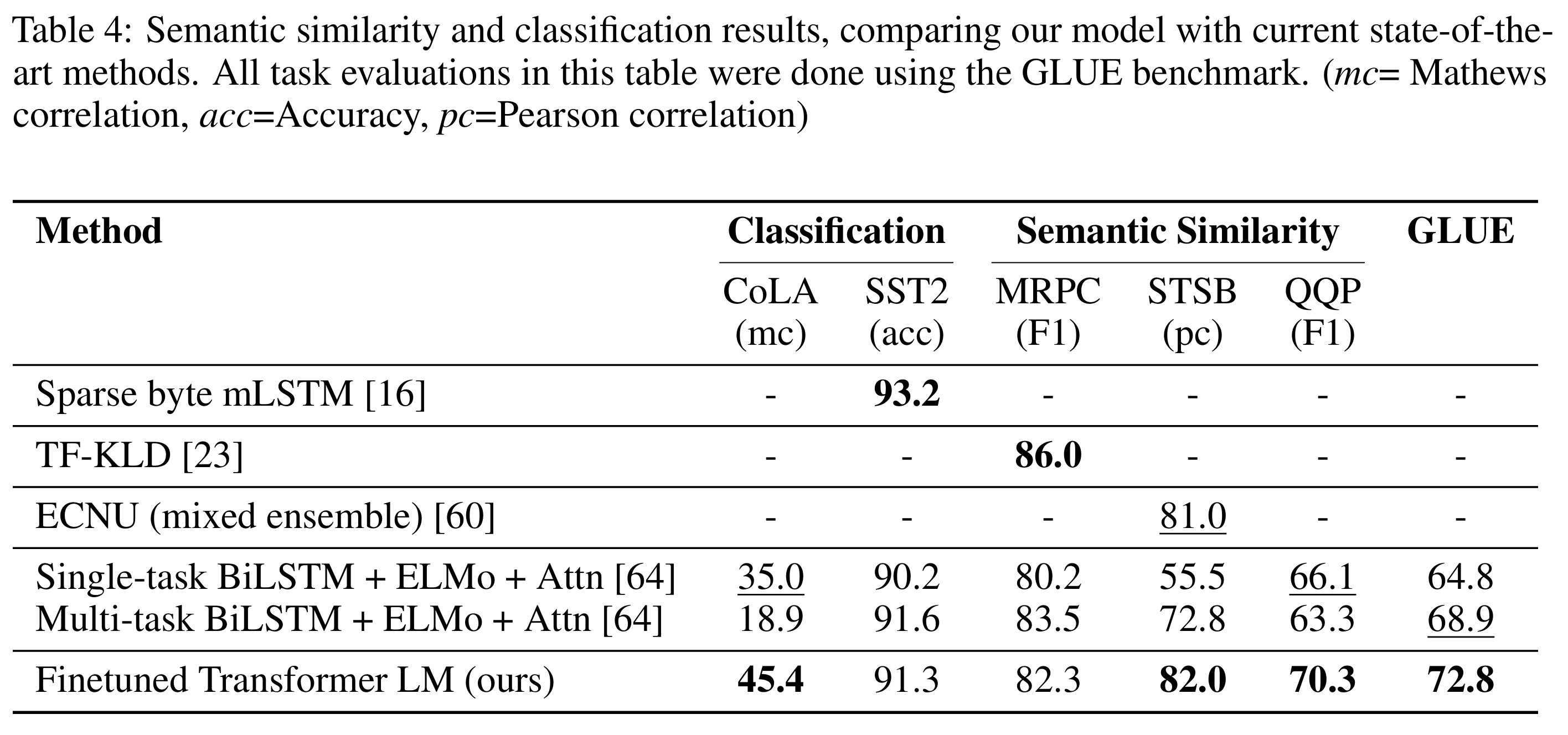
- 分类任务
- CoLA:提升巨大(+10.4),说明模型对语法可接受性学习能力强,能够捕捉内在语言规律。
- SST-2:91.3% 与前最佳接近,说明模型在标准情感分类任务上也有良好性能。
- 相似性匹配
- MRPC:提升显著(≈9.5% F1),说明模型在 小规模句子重写/同义句匹配上能力很强。
- STS-B:提升 1 个点 Pearson,表明模型能够 更精准地预测连续语义相似度。
- QQP:F1 提升 1.4%,说明在大规模重复问题匹配上也有稳定改进。
- GLUE
- 从小数据集(STS-B, 5.7k)到大数据集(SNLI, 550k)均表现稳定(SOTA)
具体如图:
6. 性能分析
这一部分主要讨论 两个核心问题:
- Transfer Learning(层转移的影响):预训练模型的不同层参与微调,对下游任务影响
- Zero-shot 性能:不依赖监督微调,直接用预训练语言模型解决任务的能力(vs LSTM)
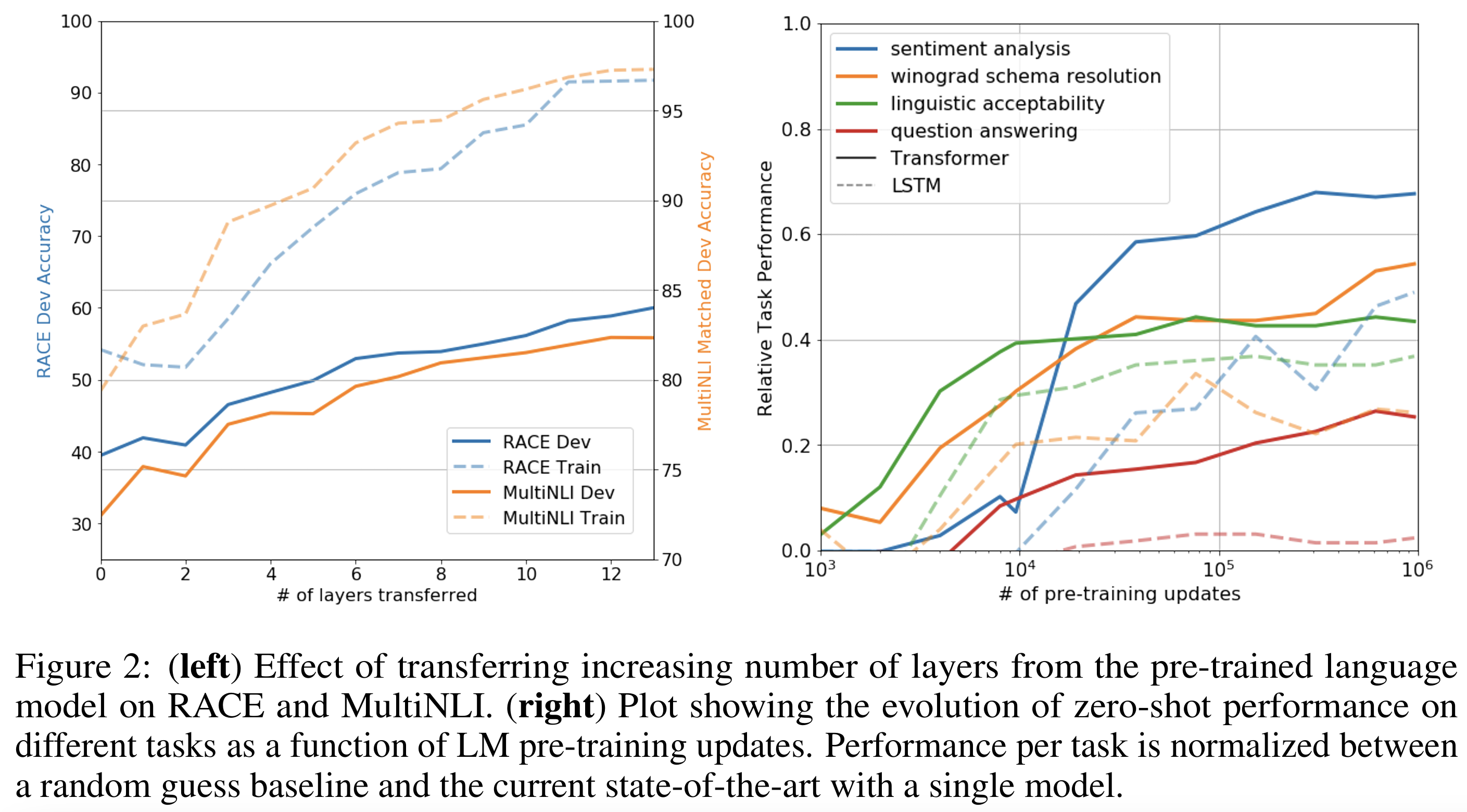
6.1 层转移(Figure 2 left)
- 实验思路:
- 将不同数量的 transformer 层从无监督预训练模型迁移到 下游监督任务
- 评估迁移层数对 MultiNLI(NLI任务) 和 RACE(问答任务) 的性能影响
- 观察结果:
- 只迁移 embedding 层 → 性能已有明显提升
- 增加 transformer 层迁移 → 性能逐层提升
- MultiNLI 全部层迁移 → 性能提升约 9%
- 结论
- 每一层 transformer 都包含有用的表示能力,对下游任务都有贡献
- 预训练模型层越多,迁移效果越明显
- 图示通常是 x轴:迁移层数,y轴:任务性能
- 线条向上趋势 → 层数增加性能提升
直观理解:预训练模型的深层表示越丰富,对下游理解任务的帮助越大。
6.2 Zero-shot 性能(Figure 2 right)
- 实验目标:为什么预训练 transformer 有效,即不依赖下游微调时的能力,设计一系列启发式解法(heuristics):
- CoLA:使用平均 token log-probability 预测句子语法是否正确
- SST-2:在句子末尾添加 token very 并限制输出为 positive/negative,用概率高的词预测
- RACE:选择生成概率最高的答案
- DPRD (Winograd):用两种可能的指代替换句子,选择 log-probability 高的选项
- 观察结果
- 零样本性能随预训练进程稳定增长
- Transformer 比 LSTM 波动小 → 表明 Transformer 的结构 inductive bias 有利于迁移
- 结论:预训练语言模型学到了广泛的、任务相关的能力,即使没有微调也能解决多种任务
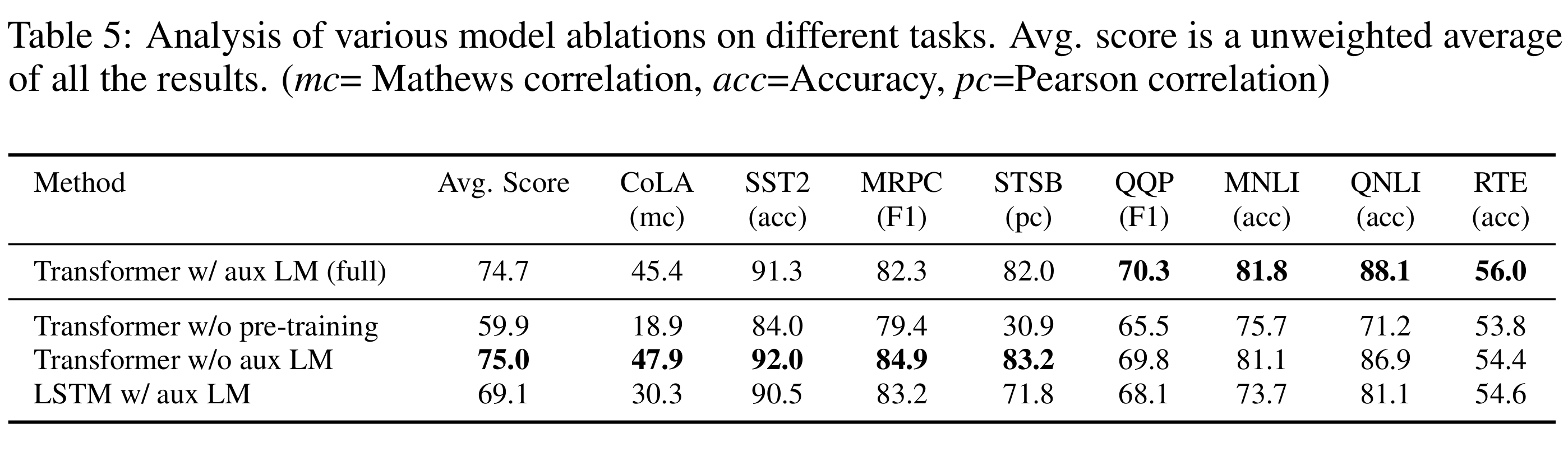
6.3 三个消融实验 (Ablation studies)
- 去掉语言建模损失(微调时,除分类交叉熵、F1损失外,加入预测下一个 token 的交叉熵)
- 替换 Transformer 为 LSTM(单层 2048 单元)
- 去掉预训练(直接在下游任务上训练 Transformer)
- 目的:量化各个设计选择对 下游任务表现 的影响
(1) 去掉 语言建模损失(auxiliary LM objective)
- 实验:Transformer 进行微调时不使用辅助 LM 目标
- 观察:
- 对 NLI(MNLI, QNLI, RTE)和 QQP 有提升大数据集受益
| 数据集 | 数据规模 | 影响 aux LM |
|---|---|---|
| MNLI | 大 (~392k) | 显著受益 |
| QQP | 大 (~363k) | 显著受益 |
| QNLI | 中 (~104k) | 有一定受益 |
| RTE | 小 (~2.5k) | 干扰 |
* 对中小规模数据集无用,甚至性能下降:* CoLA: ~8.5k train* SST-2: ~67k train* MRPC: ~3.7k train* STS-B: ~5.7k train
- 结论:
- 辅助 LM 目标帮助模型在大规模数据任务中捕捉更多上下文信息
(2) Transformer vs LSTM
- 实验:把 Transformer 替换为单层 2048 单元 LSTM,其他训练框架保持一致
- 观察:
- 平均得分下降 5.6
- LSTM 仅在 MRPC 上略好
- 结论:
- Transformer 的结构(多层自注意力)更适合捕捉长程依赖和复杂语义关系
- LSTM 在句子对小规模语义匹配任务(MRPC)表现稍好,适合数据量小且任务短文本
(3) 去掉预训练(直接训练 Transformer)
- 实验:不使用大规模无监督预训练,直接在下游任务上训练 Transformer
- 观察:
- 平均得分下降 14.8%,几乎在所有任务上性能下降
- 结论:
- 预训练模型在大规模语料学习到的语义、句法和世界知识对下游任务迁移至关重要,是性能提升的核心原因。
上述结果如表5:
总结
Transformer结构 + 预训练 + auxiliary LM 是LLM多任务性能最优组合
Ref
- https://huggingface.co/datasets/nlphuji/flickr30k/viewer/TEST/test?row=4
- https://huggingface.co/datasets/nyu-mll/multi_nli/viewer/default/train?row=0
- https://huggingface.co/datasets/nyu-mll/glue/viewer/qnli?views%5B%5D=qnli_train