[linux仓库]打开线程的“房产证”:地址空间规划与分页式管理详解[线程·壹]
🌟 各位看官好,我是egoist2023!
🌍 Linux == Linux is not Unix !
🚀 今天来学习Linux的指令知识,并学会灵活使用这些指令。
👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享更多人哦!

目录
进程和线程
重谈地址空间
分页式存储管理
虚拟地址和页表由来
物理内存管理
页表
页目录结构
二级页表的地址转换
缺页异常
总结
进程和线程
线程是在进程占用资源比较多的情况下诞生的另一种技术:
进程:一个运行起来的执行流,一个加载到内存中的程序 (教材), 进程 = 内核数据结构 + 自己的代码和数据;
线程:进程内部的一个执行流,轻量化;
观点:进程是系统分配资源的基本单位(内核角度,给进程下的定义),线程是CPU调度的基本单位.
重谈地址空间
我们之前一直不敢谈页表是个什么东西,只知道它是一种内核数据结构,可以做虚拟地址到物理地址的转化.在这里,将会对页表这层薄雾进行解惑!!!
页表也是一种内核数据结构,也要在内核中存在,那么也要占据物理内存.
那么这里提出一个疑惑:页表构建的映射关系,是按字节进行映射的吗?
为什么会提出这样的猜想呢?
- 以前学C时,内存被访问的基本单位是字节
- 虚拟地址空间是从全0到全F,每一个地址对应一个字节
那么如果页表是以字节进行映射的呢? --> 在32位环境下,我们知道虚拟地址空间为4GB左右,那么就是4 * 1024 * 1024 * 1024 个字节 --> 而一个字节对应一个地址,即有这么多的地址要进行映射 --> 而虚拟地址和物理地址都是4字节,进而可以推出页表就需要 8 * 4 * 1024 * 1024 * 1024 空间 --> 32 GB --> 这还仅仅是一个进程的页表啊!!! --> 因此可以反向推出不可能是以字节映射的.
那么页表构建的映射关系究竟是如何映射的呢?这里留下疑惑,下文进行揭晓.
分页式存储管理
虚拟地址和页表由来
我们前面说过在没有虚拟内存和分页机制的情况下,每⼀个用户程序在物理内存上所对应的空间必须是连续的.
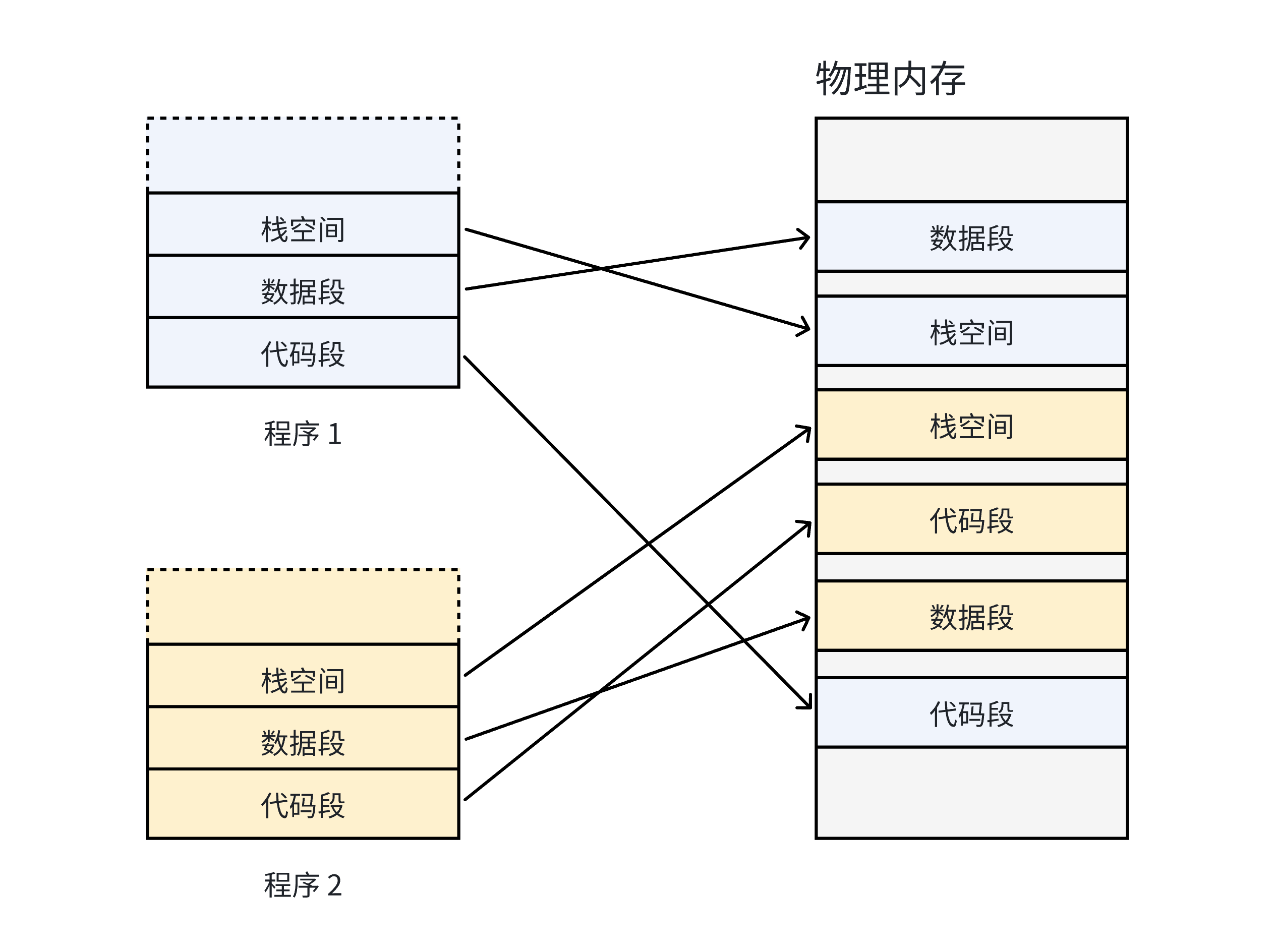
在上图中,因为每⼀个程序的代码、数据⻓度都是不⼀样的,按照这样的映射⽅式,物理内存将会被分割成各种离散的、⼤⼩不同的块。经过⼀段运⾏时间之后,有些程序会退出,那么它们占据的物理内存空间可以被回收,导致这些物理内存都是以很多碎⽚的形式存在。
因此我们希望OS提供给用户的空间必须是连续的,但是物理内存最好不要连续.因此引入了虚拟内存和分页.那么是如何做到物理内存不连续的呢?
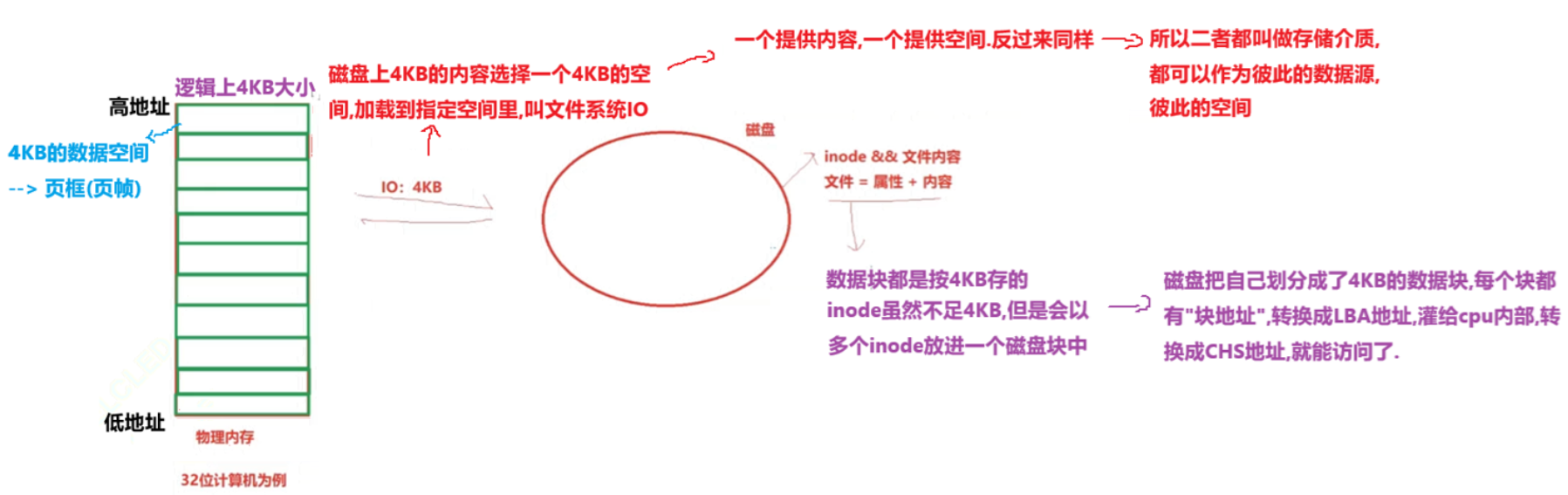
在32位机器下,我们把物理内存划分成一块块的4KB大小的数据空间,而一个4KB大小的数据空间称之为页框(页帧),每个页框包含一个物理页(page),一个页的大小等于页框的大小;
- 页框是一个存储区域;
- 页是一个数据块,可以存放在任何页框或磁盘中.
而一个磁盘中无论是可执行程序、未打开的文件都属于文件,而文件 = 属性 + 内容,我们前面学过"块"这个概念,并且知道数据块都是以4KB为单位进行存储,那么inode结构体(属性)呢?虽然不足4KB,但是可以把多个inode结构体放进一个磁盘块啊! --> 因此,磁盘把自己划分成了4KB的数据块,每个块都有"块地址",转换成LBA地址,灌给cpu内部,转换成CHS地址,就能访问了.
思想是将虚拟内存下的逻辑地址空间分为若干页,将物理内存空间分为若干页框,通过⻚表便能把连续的虚拟内存,映射到若⼲个不连续的物理内存⻚。这样就解决了使⽤连续的物理内存造成的碎⽚问题。
既然物理内存和磁盘划分都是以4KB为单位了,那么我们是否可以理解成将磁盘上4KB的内容选择一个4KB的空间,加载到指定空间里呢?这不就叫做文件系统IO吗!!! --> 进一步理解,一个提供内容,一个提供空间,反过来也是可以成立的 --> 所以我们把二者都叫做存储介质啊!都可以作为彼此的数据元,彼此的空间!
物理内存管理
如何理解物理内存划分成4KB页框呢?
假设一个物理内存有4GB的空间,按照一个页框大小为4KB进行划分的话,就会被划分成4 * 1024 * 1024 / 4 = 1048576个页框啊 ! 那么这些页框中的物理页有的可能正在被使用,有的是空的,有的是被锁定的,有的正在被释放.既然这样,OS要不要管理这一块块的4KB空间呢?肯定要的,该如何管理呢?
先描述,再组织!
既然需要描述,就需要有描述这4KB物理页空间的结构体:内核用struct page表示系统中的每个物理页,并使用大量联合体union来节省内存,便于维护page结构.
struct page {unsigned long flags; /* Atomic flags, some possibly* updated asynchronously */atomic_t _count; /* Usage count, see below. */atomic_t _mapcount; /* Count of ptes mapped in mms,* to show when page is mapped* & limit reverse map searches.*/union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};
#if NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUSspinlock_t ptl;
#endif};pgoff_t index; /* Our offset within mapping. */struct list_head lru; /* Pageout list, eg. active_list* protected by zone->lru_lock !*//** On machines where all RAM is mapped into kernel address space,* we can simply calculate the virtual address. On machines with* highmem some memory is mapped into kernel virtual memory* dynamically, so we need a place to store that address.* Note that this field could be 16 bits on x86 ... ;)** Architectures with slow multiplication can define* WANT_PAGE_VIRTUAL in asm/page.h*/
#if defined(WANT_PAGE_VIRTUAL)void *virtual; /* Kernel virtual address (NULL ifnot kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};其中有几个比较重要的参数需要关注:
flags:用来存放页的状态,是一个位图。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag的每⼀位单独表示一种状态,所以它⾄少可以同时表示出32种不同的状态。这些标志定义在<linux/page-flags.h>中。其中⼀些⽐特位非常重要,如PG_locked⽤于指定页是否锁定,PG_uptodate⽤于表示页的数据已经从块设备读取并且没有出现错误。
#define L_PTE_PRESENT (1 << 0)
#define L_PTE_FILE (1 << 1) /* only when !PRESENT */
#define L_PTE_YOUNG (1 << 1)
#define L_PTE_BUFFERABLE (1 << 2) /* matches PTE */
#define L_PTE_CACHEABLE (1 << 3) /* matches PTE */
#define L_PTE_USER (1 << 4)
#define L_PTE_WRITE (1 << 5)
#define L_PTE_EXEC (1 << 6)
#define L_PTE_DIRTY (1 << 7)
#define L_PTE_COHERENT (1 << 9) /* I/O coherent (xsc3) */
#define L_PTE_SHARED (1 << 10) /* shared between CPUs (v6) */
#define L_PTE_ASID (1 << 11) /* non-global (use ASID, v6) */_count:引用计数;
_mapcount:表示在⻚表中有多少项指向该页,也就是这⼀⻚被引用了多少次。当计数值变为-1时,就说明当前内核并没有引⽤这一页,于是在新的分配中就可以使⽤它。
mappint:表明配置,跟文件有关,通过radix_tree_node 指向一个个的 struct page 结构,
struct page {union {struct {unsigned long private; /* Mapping-private opaque data:* usually used for buffer_heads* if PagePrivate set; used for* swp_entry_t if PageSwapCache;* indicates order in the buddy* system if PG_buddy is set.*/struct address_space *mapping; /* If low bit clear, points to* inode address_space, or NULL.* If page mapped as anonymous* memory, low bit is set, and* it points to anon_vma object:* see PAGE_MAPPING_ANON below.*/};};struct address_space {struct inode *host; /* owner: inode, block_device */struct radix_tree_root page_tree; /* radix tree of all pages */
} __attribute__((aligned(sizeof(long))));struct radix_tree_root {unsigned int height; /* 基数树的高度(层数) */gfp_t gfp_mask; /* 内存分配时使用的标志(如GFP_KERNEL) */struct radix_tree_node __rcu *rnode; /* 指向基数树的根节点(struct radix_tree_node) */
};struct radix_tree_node {unsigned int count;void *slots[RADIX_TREE_MAP_SIZE]; // struct page[]unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
};
mapping跟文件有关,好像很熟悉啊?我们知道一个文件是存在文件缓冲区的啊?会不会是拿着struct file 对应的指针指向对应的page就可以了!!!
virtural:是页的虚拟地址。通常情况下,它就是⻚在虚拟内存中的地址。有些内存(即所谓的⾼端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的时候,必须动态地映射这些页。
lru:最近最少使用,淘汰对应的页面.
对于系统中的每个物理页都要分配一个struct page这样的结构体,而在32位机器下大概有1048576个,而每个struct page结构体大概占40个字节的内存,那么就有40 * 1048576 ≈ 40 MB,相对系统4GB而言,仅用40MB的内存就能维护这么多物理页,开销并不算大.
那为什么页的大小不能太大又不能太小呢?
页的大小对于内存利⽤和系统开销来说⾮常重要,页太大,页页必然会剩余较⼤不能利⽤的空间(页内碎⽚)。页太⼩,虽然可以减⼩⻚内碎⽚的大小,但是页太多,会使得⻚表太⻓⽽占⽤内存,同时系统频繁地进⾏⻚转化,加重系统开销。因此,页的大小应该适中,通常为 512B - 8KB ,windows系统的页框大小为4KB。
描述的问题解决了,那么该如何进行组织呢?
既然我们已经知晓了page结构体,在OS内定义一个全局的数组 struct page pages[1048576] --> 对整个物理内存的管理就转换成了对数组的增删查改.只要OS在加载开机的时候,这个全局数组的每个page就天然有下标了.
因此物理内存的每一块4KB的空间,都可以使用数组下标来进行表述,如物理内存从下到上进行表示:
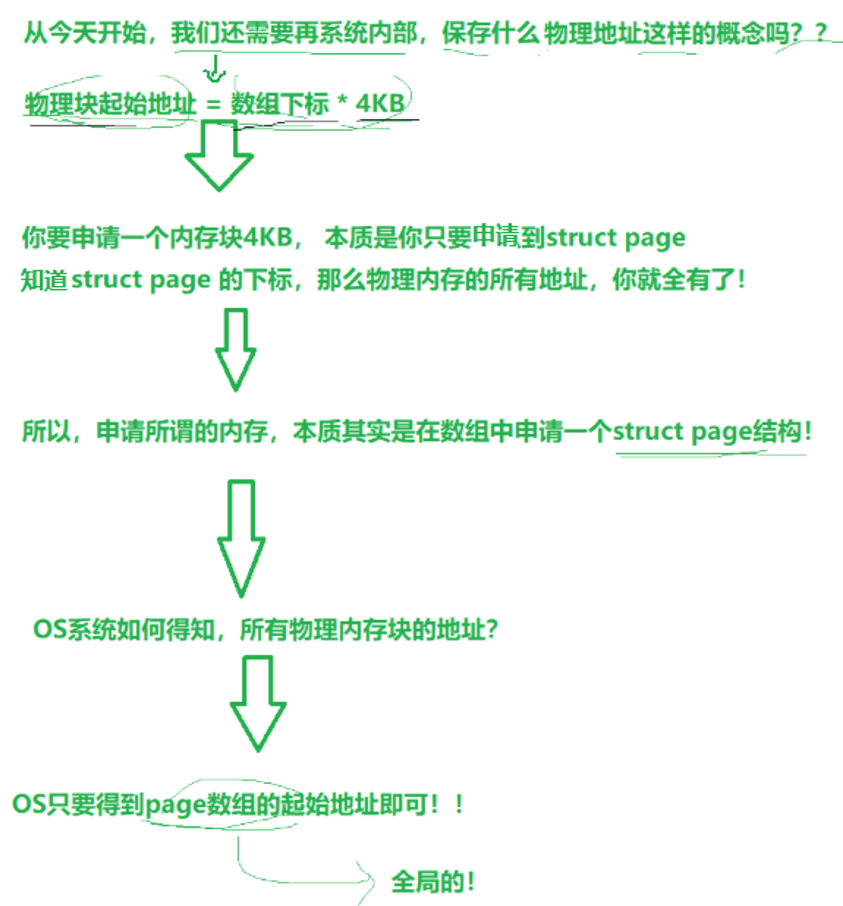
- 0下标对应的page --> 第一个物理内存块(4KB)
- 1下标对应的page --> 第二个物理内存块(4KB)
- 2下标对应的page --> 第三个物理内存块(4KB)
- ...
页表
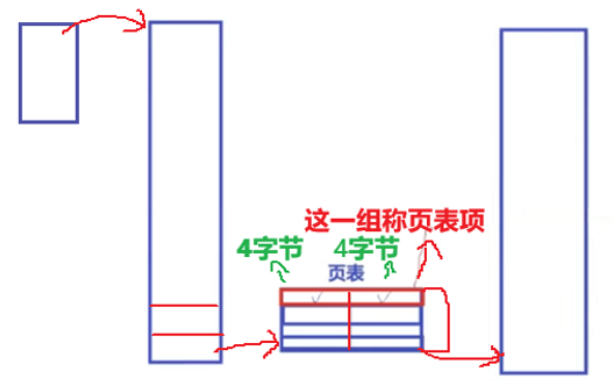
在 32 位系统中,虚拟内存的最⼤空间是 4GB ,这是每⼀个用户程序都拥有的虚拟内存空间。既然需要让 4GB 的虚拟内存全部可⽤,那么⻚表中就需要能够表⽰这所有的 4GB 空间,那么就⼀共需要 4GB/4KB = 1048576 个表项。
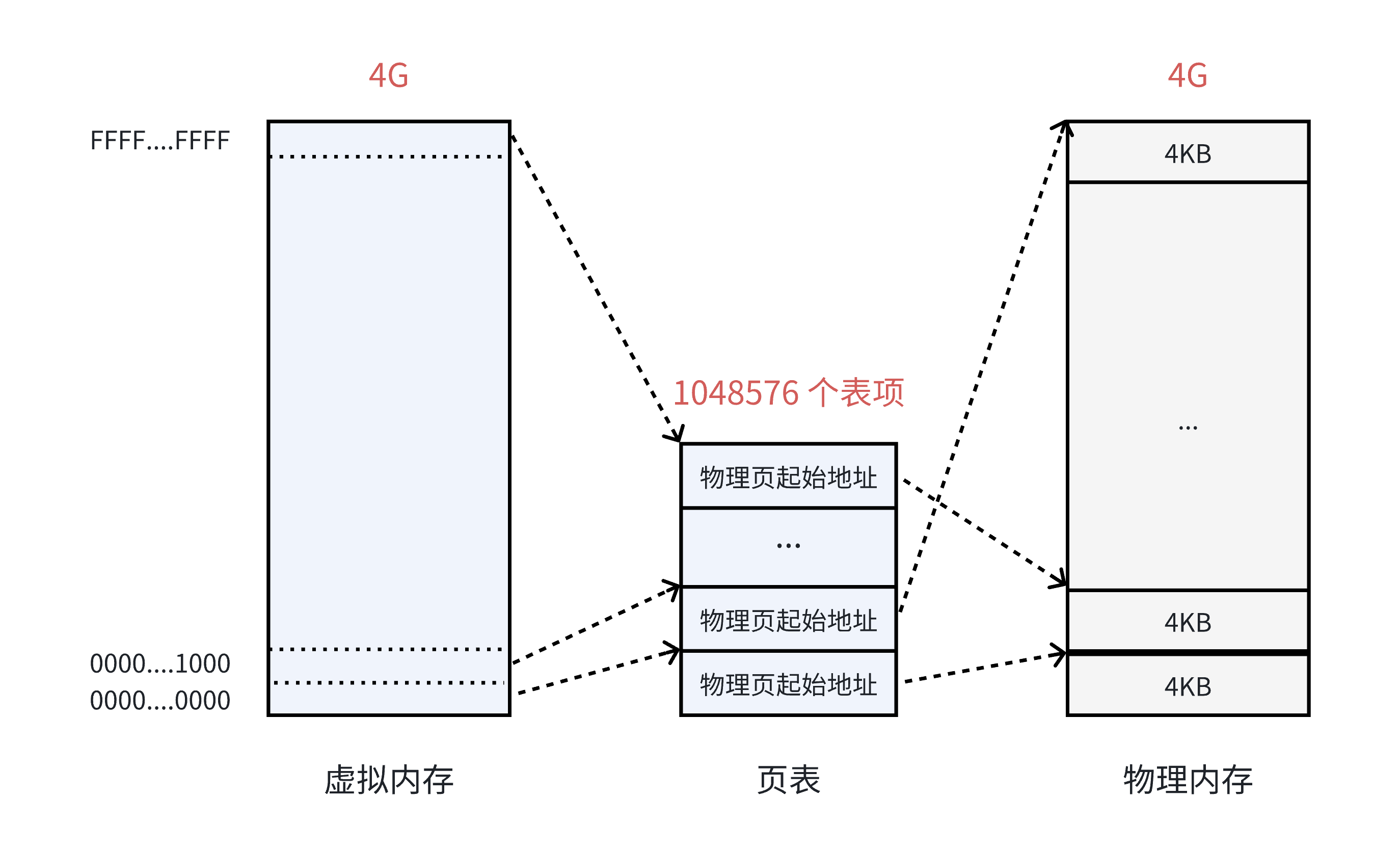
虚拟内存看上去被虚线“分割”成⼀个个单元,其实并不是真的分割,虚拟内存仍然是连续的。这个虚线的单元仅仅表⽰它与⻚表中每⼀个表项的映射关系,并最终映射到相同⼤⼩的⼀个物理内存⻚上。
在 32 位系统中,地址的长度是 4 个字节,那么页表中的每⼀个表项就是占⽤ 4 个字节。所以⻚表占据的总空间大小就是: 1048576 * 4 = 4MB 的⼤⼩。也就是说页表自己本身,就要占用 4MB / 4KB = 1024 个物理页。虽然相比前面一个页表需要占用32GB大小,这个的牺牲算小了些,但还是存在一些问题:
- 回想⼀下,当初为什么使⽤页表,就是要将进程划分为⼀个个⻚可以不⽤连续的存放在物理内中,但是此时⻚表就需要1024个连续的⻚框,似乎和当时的⽬标有点背道而驰了......
- 此外,根据局部性原理可知,很多时候进程在⼀段时间内只需要访问某⼏个⻚就可以正常运行了。因此也没有必要⼀次让所有的物理⻚都常驻内存。
解决需要⼤容量页表的最好⽅法是:把页表看成普通的⽂件,对它进⾏离散分配,即对页表再分页,由此形成多级⻚表的思想。
为了解决这个问题,可以把这个单⼀页表拆分成 1024 个体积更小的映射表。如下图所示。这样⼀来,1024(每个表中的表项个数) * 1024(表的个数) = 1048576,仍然可以覆盖 4GB 的物理内存空间。
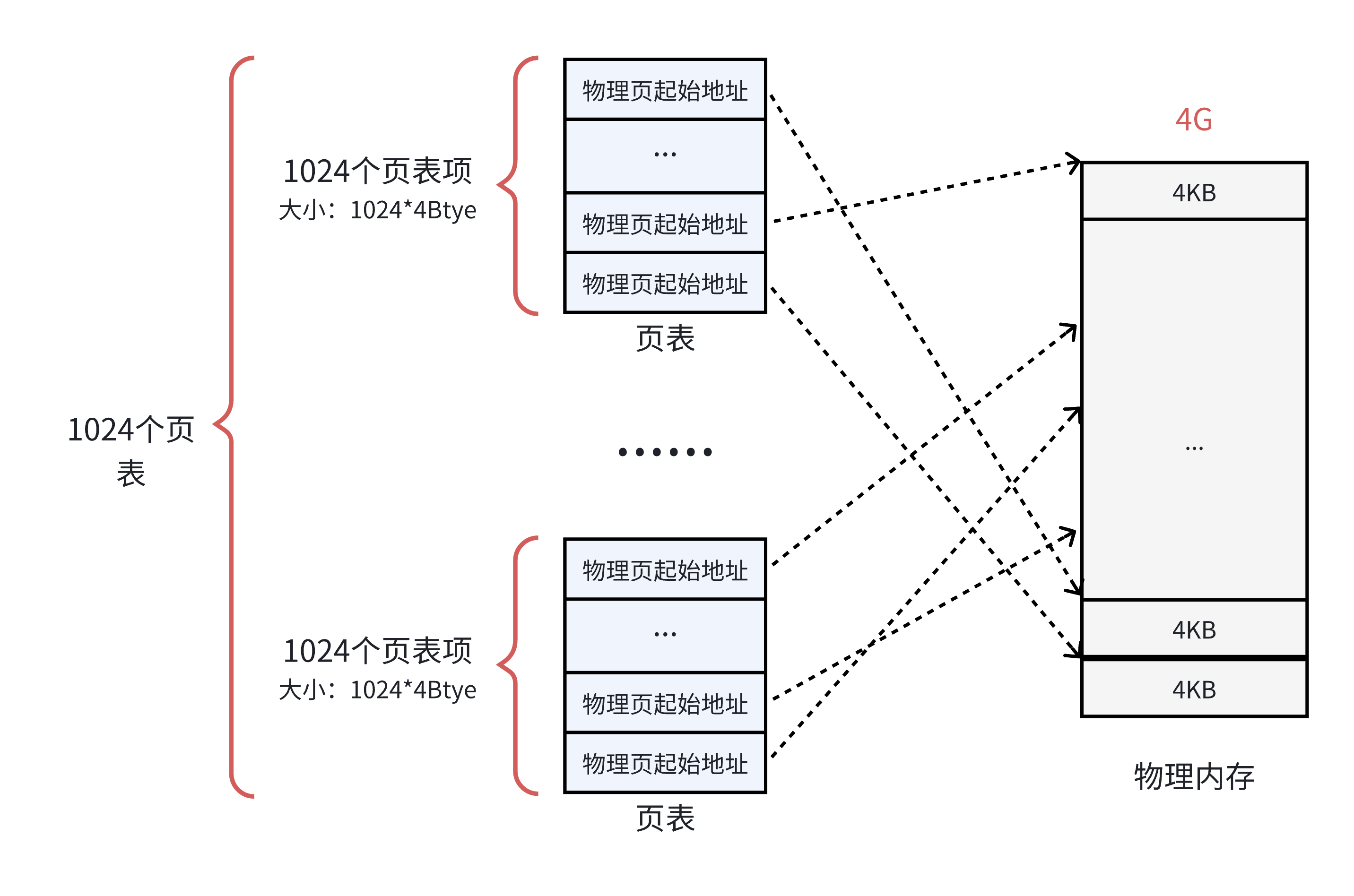
这⾥的每⼀个表,就是真正的⻚表,所以⼀共有 1024 个⻚表。⼀个⻚表⾃⾝占⽤ 4 * 1024 = 4KB ,那么1024 个⻚表⼀共就占⽤了 4MB 的物理内存空间,和之前没差别啊?
从总数上看是这样,但是⼀个应⽤程序是不可能完全使⽤全部的 4GB 空间的,也许只要几十个⻚表就可以了。例如:⼀个用户程序的代码段、数据段、栈段,⼀共就需要 10 MB 的空间,那么使⽤ 3 个页表就足够了.(一个指向一个4KB的物理页,即一个页框,那么一个页表有1024个页表项,一共能覆盖4MB的物理内存;那么10MB的程序向上对齐取整之后就是12MB,所以说只需要3个页表.)
页目录结构
既然每一个页框被一个页表中的一个表项来指向了,那么谁来管理这1024个页表呢?管理页表的表称之为页目录表,从而形成二级页表!!!如下所示:
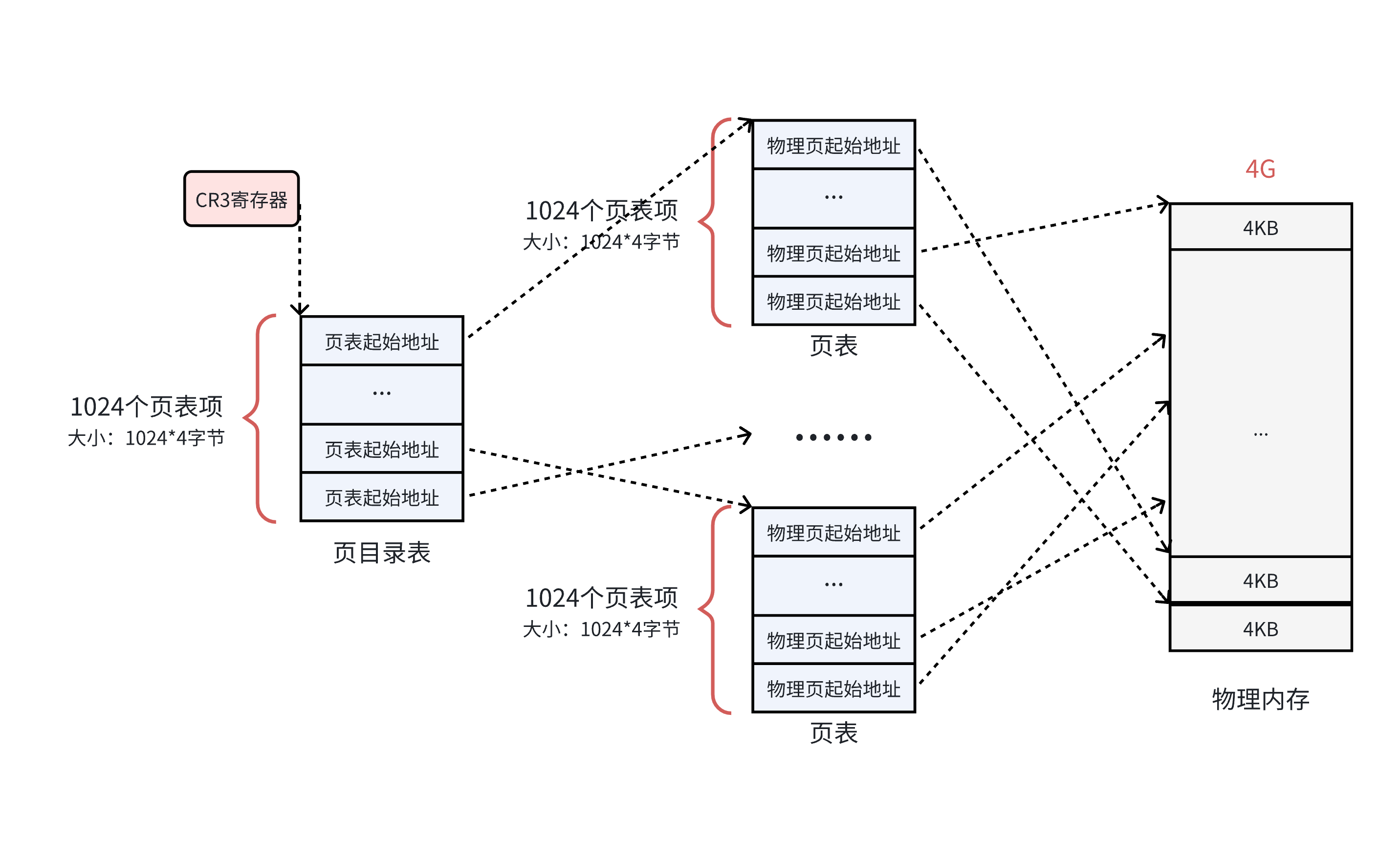
- 页目录的物理地址被 CR3 寄存器 指向,这个寄存器中,保存了当前正在执行任务的页目录地址。
- 一个页目录表的大小 4 * 1024 = 4KB
所以操作系统在加载⽤⼾程序的时候,不仅仅需要为程序内容来分配物理内存,还需要为⽤来保存程序的页目录和⻚表分配物理内存.
二级页表的地址转换
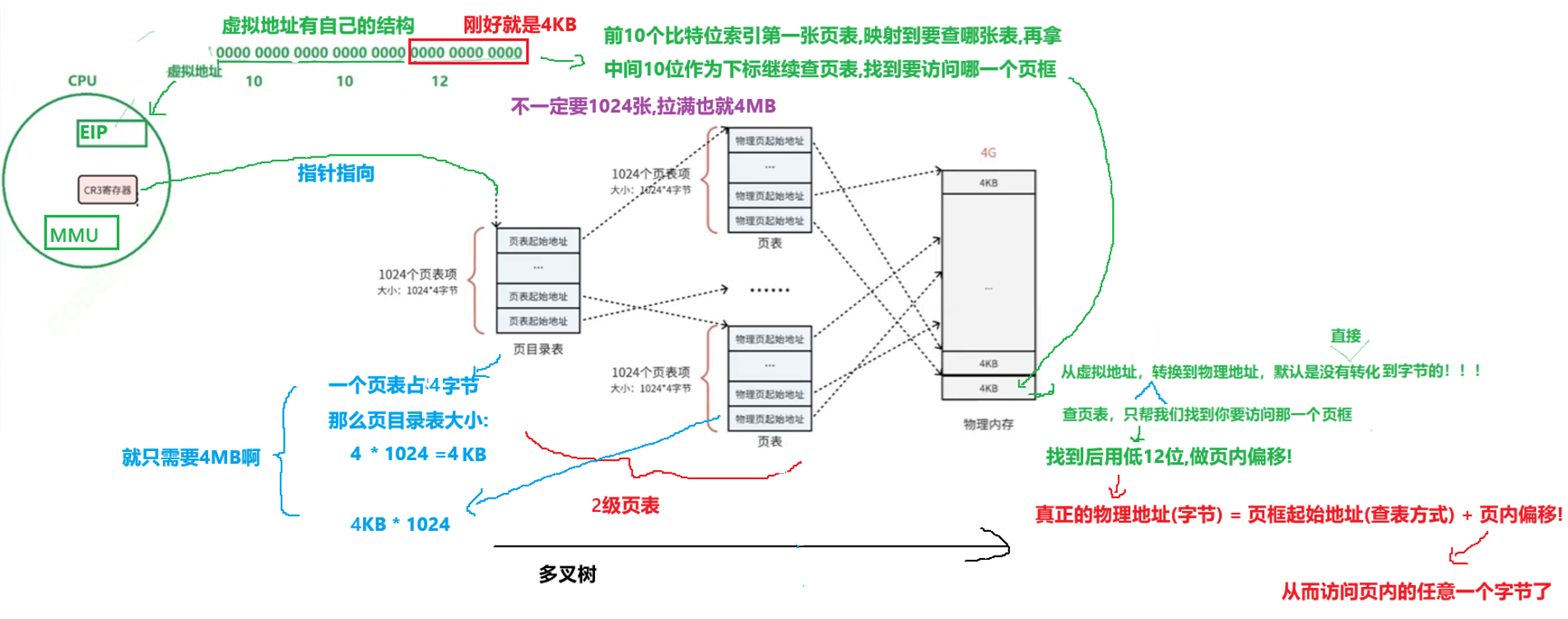
在上述图中,虚拟地址是如何转换得到物理地址的呢?
在32位机器下,CR3寄存器读取页目录起始地址,将虚拟地址中的前10个比特位进行索引找到页目录表的对应位置,而这个位置会指向对应的页表,既然知道了是哪一个页表,就需要知道是物理地址的哪一个页框,接着会用中间10位作为下标知道要访问哪一个页框.找到页框后,这个页框是4KB的啊!!!默认是没有直接转化到字节的!因此用低12位做页内偏移,从而做到虚拟地址到物理地址的映射!!!
真正的物理地址(字节) = 页框起始地址(查表方式) + 页内偏移!
从而访问页内的任意一个字节了
以上其实就是MMU(一种硬件电路)的工作流程,进行内存管理,地址转换只是承接的业务之一.
到这⾥其实还有个问题,MMU要先进⾏两次⻚表查询确定物理地址,在确认了权限等问题后,MMU再将这个物理地址发送到总线,内存收到之后开始读取对应地址的数据并返回。那么当⻚表变为N级时,就变成了N次检索+1次读写。可⻅,⻚表级数越多查询的步骤越多,对于CPU来说等待时间越⻓,效率越低。
单级⻚表对连续内存要求⾼,于是引⼊了多级⻚表,但是多级⻚表也是⼀把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。
接下来我们来谈谈上图中所涉及到的细节部分:
- cr3保存当前进程页表的基地址,即页目录表的起始物理地址
- 虚拟地址的划分,这个过程编译器用参与吗?不关心!,编译器只要做编址就ok
- 高20位相同的地址,一定是连续存放在一个页框的! ELF->0~FF...相同属性的代码或者数据,在一个4kb块里面,即在一个4KB数据空间里
- 当虚拟地址通过二级页表映射到页框后,如何得到page结构体呢?因为物理块起始地址 = 数组下标 * 4KB , 那么数组下标 = 页框号 / 4KB.
- 进程首次加载磁盘块的时候,OS做什么?内存管理,申请内存->申请page->index-> 页框的物理地址 ->填充页表
- 如果我们访问的是,一个int ? 一个结构体 ? 一个数组呢 ? 一个类变量呢 ? -->所有变量都只有一个地址! --> 开辟空间的最小字节的地址(虚拟) --> 页表转换的时候,只能拿到第一个字节的地址啊 ! 所以语言中存在一个叫做"类型"的概念 !(即起始地址 + 偏移量(类型))
- 如何重新理解写时拷贝?缺页中断?申请和管理物理内存,都是以4KB为单位进行的!因此写时拷贝是把4KB空间全拷一份,而不是只拷贝要改变的变量.
- 可是我们也有个疑惑,我记得new,mallock这种申请,想申请多少字节就申请多少啊!不是说以4KB为单位进行的吗?
- 底层一定要调用系统调用,brk,mmap
- 调用系统调用是有成本的 !
- C、C++自己在语言层,会有自己的内存管理机制,类似STL中的空间配置器!语言层上我们可以随意申请,但是语言会以4KB为单位进行申请,把你需要的n字节给你,剩下的由语言进行管理
既然说多级页表试一把双刃剑,减少存储空间的同时降低了查询效率.那么有没有提升效率的办法呢?
计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。 MMU 引⼊了新武器,江湖⼈称快表的 TLB (其实,就是缓存)
当 CPU 给 MMU 传新虚拟地址之后, MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到总线给内存,⻬活。但 TLB 容量⽐较⼩,难免发⽣ Cache Miss ,这时候 MMU 还有保底的⽼武器 ⻚表,在⻚表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录⼀下刷新缓存。
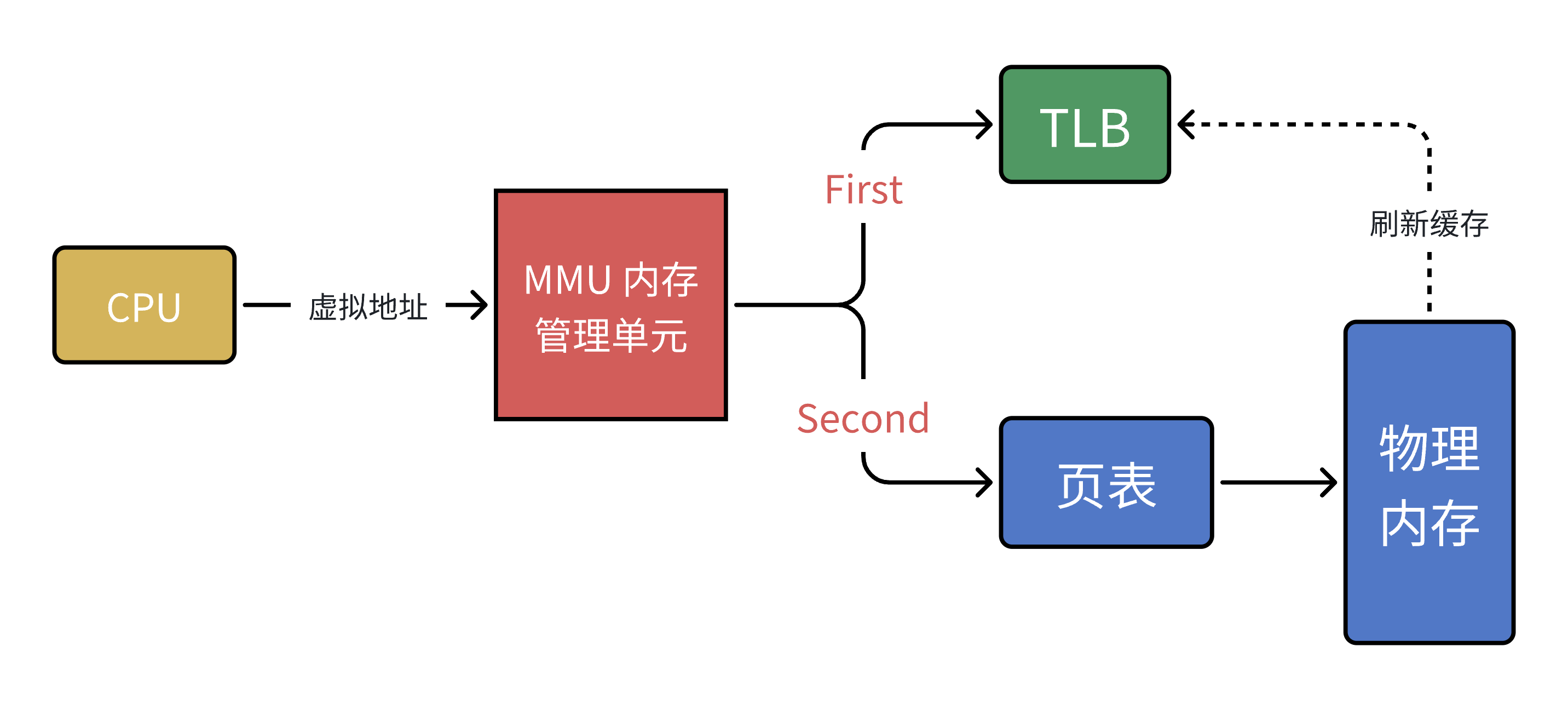
缺页异常
设想,CPU 给 MMU 的虚拟地址,在 TLB 和⻚表都没有找到对应的物理页,该怎么办呢?其实这就是缺⻚异常 Page Fault ,它是⼀个由硬件中断触发的可以由软件逻辑纠正的错误。
假如⽬标内存⻚在物理内存中没有对应的物理⻚或者存在但⽆对应权限,CPU 就⽆法获取数据,这种情况下CPU就会报告⼀个缺⻚错误。
由于 CPU 没有数据就⽆法进⾏计算,CPU罢⼯了用户进程也就出现了缺⻚中断,进程会从用户态切换到内核态,并将缺⻚中断交给内核的 Page Fault Handler 处理。
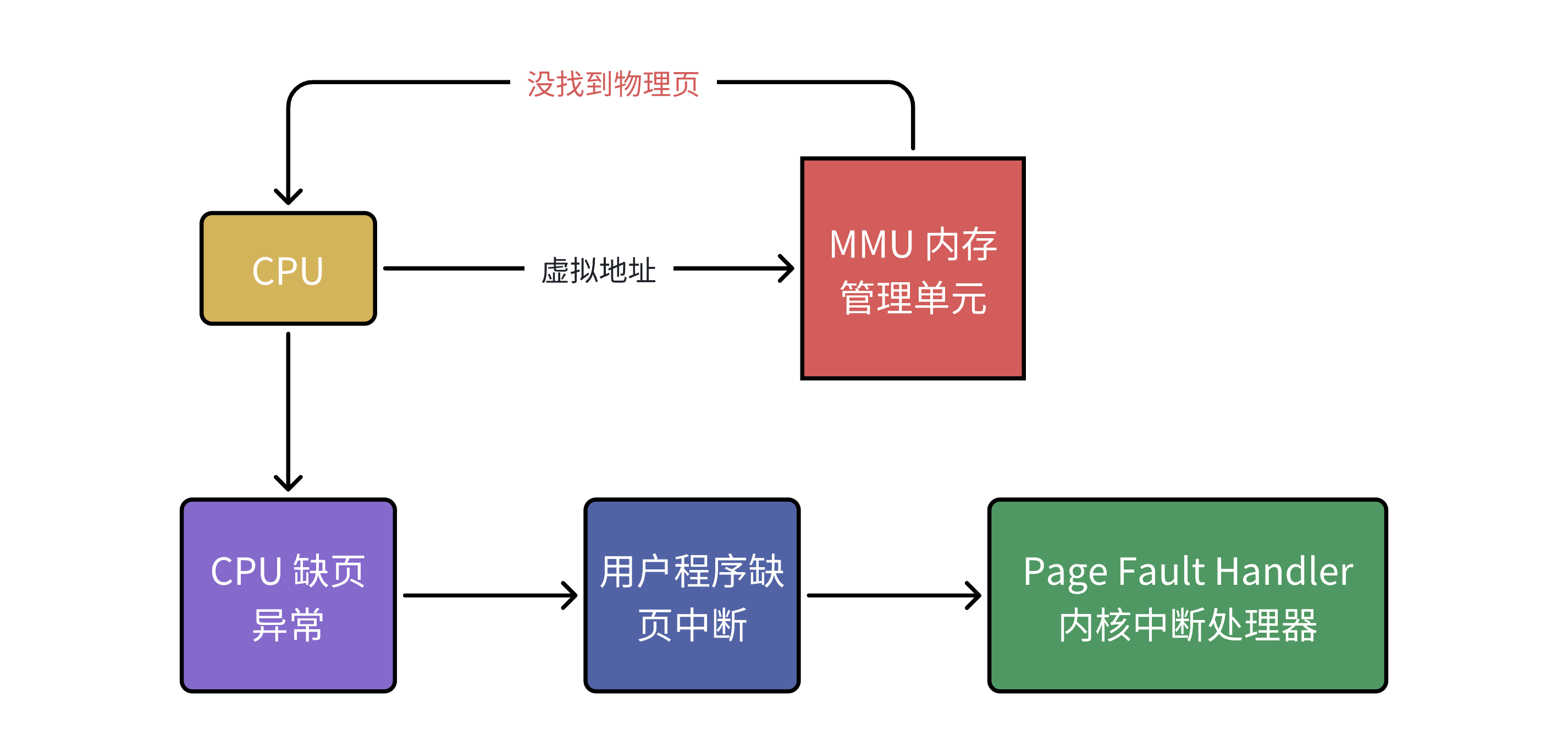
缺⻚中断会交给 PageFaultHandler 处理,其根据缺⻚中断的不同类型会进⾏不同的处理:
- Hard Page Fault 也被称为 Major Page Fault ,翻译为硬缺⻚错误/主要缺⻚错误,这时物理内存中没有对应的物理⻚,需要CPU打开磁盘设备读取到物理内存中,再让MMU建⽴虚拟地址和物理地址的映射。
- Soft Page Fault 也被称为 Minor Page Fault ,翻译为软缺⻚错误/次要缺⻚错误,这时物理内存中是存在对应物理⻚的,只不过可能是其他进程调⼊的,发出缺⻚异常的进程不知道⽽已,此时MMU只需要建⽴映射即可,⽆需从磁盘读取写⼊内存,⼀般出现在多进程共享内存区域。
- Invalid Page Fault 翻译为⽆效缺⻚错误,⽐如进程访问的内存地址越界访问,⼜⽐如对空指针解引⽤内核就会报 segment fault 错误中断进程直接挂掉。
总结
本文深入探讨了Linux系统中进程、线程与内存管理的核心机制。首先解析了进程与线程的区别,指出进程是资源分配单位,线程是CPU调度单位。重点剖析了分页式存储管理原理,包括:
- 虚拟地址空间通过页表映射到物理内存的4KB页框,解决内存碎片问题;
- 采用二级页表结构(页目录+页表)优化空间占用;
- 引入TLB快表加速地址转换,通过缺页中断处理机制应对页缺失情况。 文章还详细介绍了物理内存管理的数据结构设计,包括struct page的组织方式,以及写时拷贝、内存分配等底层实现原理。这些机制共同构成了Linux高效内存管理的技术基础。