高并发内存池 - 开发记录07
高并发内存池 - 开发记录07

📑 目录
- 今日目标
- 巩固页合并理解
- 实现慢增长算法
- 统一对外接口
- 踩坑记录
- 代码统计
- 今日收获
- 遗留问题
- 思考与反思
今日目标
原计划Day7实现慢增长算法和统一接口,加上昨天状态不太好,今天一开始担心自己写不出来。不过想了想,决定先巩固一下昨天的页合并理解,再开始新内容。
计划任务:
- 巩固页合并算法理解
- 实现慢增长算法(NumMoveSize)
- 封装统一对外接口(ConcurrentAlloc/Free)
- 基础性能统计(时间不够,留到明天)
巩固页合并理解
早上的自我检验
今天早上决定先不看代码,凭记忆自己检验一下对昨天内容的理解程度。
Q1: 三层架构职责
回顾了一下各层的职责:
- ThreadCache:管理对象,无锁快速响应,与CentralCache交互
- CentralCache:切分Span成对象,建立映射_pageToSpan便于归还
- PageCache:页合并、页切分、批量申请内存
不过重新思考后发现,CentralCache的映射更准确的说法是:用于对象归还时快速定位Span,不是插入对象到页,而是插入到Span的_freeList。
Q2: 页合并触发流程
B → D → F → C → A → E
(释放对象 → useCount-- → 检查==0 → 归还Span → 检查相邻页 → 合并)
流程记得很清楚,说明昨天理解到位了。
Q3: 为什么要页合并
从"内存碎片"、“利用率”、"复用"等角度思考了一下:
- 不合并 → 外部碎片 → 有内存但用不上
- 合并 → 大块连续内存 → 可以满足大请求
这就是页合并的核心价值。
Q4: 代码填空
这里栽了一个小坑:
// 我写的:
span->_pageId = prevSpan->prevSpan->_pageId; // 错误, 多了一个prevSpan->// 正确的:
span->_pageId = prevSpan->_pageId; //
原因是prevSpan已经是Span指针了,不需要再访问prevSpan->prevSpan。这是访问链表前一个节点的写法,不对。
其他都答对了,特别是停止合并的3个条件:
it == _pageToSpan.end()(前一页不存在)it->second->_isUse == true(前一页正在使用)prevSpan->_n + span->_n > 128(合并后超过128页)
收获
通过这些提问,发现自己对页合并的理解还不错,但有些细节需要注意:
- 指针访问不要多一层(
prevSpan->_pageId而不是prevSpan->prevSpan->_pageId) - CentralCache的映射作用理解更清楚了
巩固这一步很有用,让我对后面的开发更有信心了。
实现慢增长算法
设计思路
当前问题:
// ThreadCache.h 第69行(之前)
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, size, 8);
// ↑
// 固定8个
不管什么对象,都固定申请8个,有问题:
- 8字节对象:8个太少(只64字节),频繁调用CentralCache
- 256KB对象:8个太多(2MB!),浪费内存
目标:
小对象多拿,大对象少拿。
算法设计
思考应该用什么策略,一开始想固定总字节数:
批量数 = 固定字节数 / 对象大小
但这样8字节对象会申请32768个(256KB/8B),太多了!
查阅了一些资料后发现,需要加个上限:
批量数 = min(上限, 固定字节数 / 对象大小)
为什么要上限?
如果批量数太大(比如32768个),CentralCache需要切分很多Span,加锁时间长,影响并发性能。上限512是经验值,平衡了性能和锁竞争。
这样就合理多了!
实现过程
Step 1: NumMoveSize函数
一开始写的代码有个小bug:
// 我写的:
size_t min = min(num, 512); // ❌ 变量名和函数名冲突!
后来发现变量叫min,函数也叫min(),会产生歧义。
而且为了避免依赖<algorithm>头文件,改成用if语句:
static inline size_t NumMoveSize(size_t size) {// 1. 计算:固定字节数/size (MAX_BYTES = 256KB)size_t num = MAX_BYTES / size;// 2. 限制上限512(避免批量过大,锁竞争严重)if (num > 512) {num = 512;}// 3. 至少返回2(避免返回0或1,批量太小)if (num < 2) {num = 2;}return num;
}
验证效果:
8字节对象: 512个 = 4KB ← 合理!
32字节对象: 512个 = 16KB ← 合理!
128KB对象: 2个 = 256KB ← 合理!
256KB对象: 2个(至少2) ← 保底值
Step 2: 修改ThreadCache调用
// 修改后:
size_t batchNum = SizeClass::NumMoveSize(size);
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, size, batchNum);
位置选择:
思考了一下这个函数应该放在哪里,一开始想放ThreadCache,但后来意识到应该放SizeClass,因为:
- 和RoundUp、Index、NumMovePage是同类函数(都是根据size计算)
- 静态函数,不占用对象内存
- 所有层都能用
这个设计思路让代码逻辑更集中。
效果对比
修改前(固定8个):
- 8字节对象:8个 = 64字节 ← 太少
- 128KB对象:8个 = 1MB ← 太多
修改后(慢增长):
- 8字节对象:512个 = 4KB ← 减少频繁调用
- 128KB对象:2个 = 256KB ← 避免浪费
统一对外接口
为什么需要统一接口?
当前问题:
// 用户使用内存池,需要这样写:
void* ptr = GetTLSThreadCache()->Allocate(32);
GetTLSThreadCache()->Deallocate(ptr, 32);
问题:
- 暴露了内部实现(ThreadCache、TLS机制)
- 接口不友好,用户需要了解内部结构
- 大内存(>256KB)也走内存池,效率低
目标:
// 统一接口,简单易用:
void* ptr = ConcurrentAlloc(32);
ConcurrentFree(ptr, 32);
好处:
- 隐藏内部实现
- 接口简洁,类似malloc/free
- 自动处理大内存
设计决策
大内存策略:
考虑了一下大内存应该怎么处理,最终选择了直接malloc:
- 方案A:走内存池 → 需要128页Span,浪费资源
- 方案B:直接malloc → 高效,不占用内存池
如何区分大小内存?
释放时根据size判断:
if (size > MAX_BYTES) {free(ptr); // 大内存直接free
} else {GetTLSThreadCache()->Deallocate(ptr, size); // 小内存走内存池
}
这个方案比在内存块前记录标记更简单。
实现过程
创建ConcurrentMemoryPool.h:
// 统一分配接口
static inline void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){return malloc(size); // 大内存直接malloc}else{return GetTLSThreadCache()->Allocate(size); // 小内存走内存池}
}// 统一释放接口
static inline void ConcurrentFree(void* ptr, size_t size)
{if (size > MAX_BYTES){free(ptr); // 大内存直接free}else{GetTLSThreadCache()->Deallocate(ptr, size); // 小内存归还内存池}
}
踩坑:
我一开始写的是:
return ThreadCache::GetTLSThreadCache()->Allocate(size); // 错误
编译报错:class "ThreadCache" has no member "GetTLSThreadCache"
原因分析:
仔细查看代码后发现,GetTLSThreadCache()不是ThreadCache的成员函数,而是一个全局函数!查看ThreadCache.h的定义:
// 这是全局函数,不是成员函数
static ThreadCache* GetTLSThreadCache() {if (pTLSThreadCache == nullptr) {pTLSThreadCache = new ThreadCache;}return pTLSThreadCache;
}
修复:
return GetTLSThreadCache()->Allocate(size); // 直接调用全局函数
这个错误让我意识到要区分成员函数和全局函数。
测试验证
写了完整的测试用例:
- 小对象分配(32B/64B/128B)→ 走内存池
- 大对象分配(512KB/1MB)→ 走malloc
- 边界值(256KB vs 256KB+1)→ 正确区分
- 批量分配100个对象 → 正常工作
测试结果:
=== 测试1: 小对象分配(走内存池) ===
分配小对象:32B: 0x19ebb761fe064B: 0x19ebb763fc0128B: 0x19ebb765f80
小对象释放完成=== 测试2: 大对象分配(直接malloc) ===
分配大对象:512KB: 0x19ebb57ee001MB: 0x19ebb86e040
大对象释放完成所有测试完成!
完美!接口工作正常!
踩坑记录
坑1:变量名和函数名冲突
size_t min = min(num, 512); // 变量min和函数min()冲突
修复: 换个变量名,或者直接用if语句。
坑2:成员函数 vs 全局函数
ThreadCache::GetTLSThreadCache() // 错误 GetTLSThreadCache不是成员函数
GetTLSThreadCache() // 是全局函数
教训: 使用函数前要确认它的类型(成员函数还是全局函数)。
坑3:多级指针访问
span->_pageId = prevSpan->prevSpan->_pageId; // 错误 多了一层
span->_pageId = prevSpan->_pageId; // 正确代码
教训: prevSpan已经是Span*了,直接访问即可。
任务4:基础性能统计
设计思路
为什么需要性能统计?
为Day8/Day9的性能测试做准备,需要能够量化内存池的性能表现:
- 对比malloc vs 内存池的速度差异
- 分析内存使用情况
- 检测内存泄漏
统计哪些指标?
采用迭代策略,先实现最基础的4个指标:
allocCount- 分配次数freeCount- 释放次数currentMemory- 当前内存使用量(字节)peakMemory- 峰值内存使用量(字节)
技术选型:原子变量
std::atomic<size_t> g_allocCount{0}; // 分配次数
std::atomic<size_t> g_freeCount{0}; // 释放次数
std::atomic<size_t> g_currentMemory{0}; // 当前内存
std::atomic<size_t> g_peakMemory{0}; // 峰值内存
为什么用原子变量而不是锁?
| 方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 实现简单 | 会影响性能测试准确性 |
| 原子变量 | 无锁,开销小 | 不支持复杂操作 |
选择原子变量的理由:
- 线程安全,多线程同时
++不会出错 - 无锁,不影响性能测试
- 开销小,适合高频调用
- 对于简单的计数操作足够用
统计位置:统一接口
在ConcurrentAlloc/ConcurrentFree中统计:
- 大小内存都能统计到
- 统一位置,不会遗漏
- 对用户透明
实现过程
步骤1:声明全局统计变量
在ConcurrentMemoryPool.h顶部添加:
#include <atomic>std::atomic<size_t> g_allocCount{0}; // 分配次数
std::atomic<size_t> g_freeCount{0}; // 释放次数
std::atomic<size_t> g_currentMemory{0}; // 当前内存(字节)
std::atomic<size_t> g_peakMemory{0}; // 峰值内存(字节)
步骤2:在ConcurrentAlloc中记录分配
static inline void* ConcurrentAlloc(size_t size)
{// 性能统计:记录分配g_allocCount++;g_currentMemory += size;// 更新峰值内存size_t current = g_currentMemory.load();size_t peak = g_peakMemory.load();if (current > peak) {g_peakMemory.store(current);}// 真正的分配逻辑if (size > MAX_BYTES) {return malloc(size);} else {return GetTLSThreadCache()->Allocate(size);}
}
峰值更新的关键点:
- 使用
load()读取原子变量 - 使用
store()写入原子变量 - 峰值只在分配时更新,释放时不更新
- 峰值记录"历史最高水位",只增不减
步骤3:在ConcurrentFree中记录释放
static inline void ConcurrentFree(void* ptr, size_t size)
{// 性能统计:记录释放g_freeCount++;g_currentMemory -= size;// 注意:不更新peakMemory(峰值不会因释放而减少)// 真正的释放逻辑if (size > MAX_BYTES) {free(ptr);} else {GetTLSThreadCache()->Deallocate(ptr, size);}
}
一个小bug: 最开始把统计代码放在return之后了,导致永远不会执行。调整到return之前就正常了。
测试验证
编写测试文件: test/test_statistics.cpp
测试策略:
- 基本分配/释放 - 验证计数正确性
- 大内存分配 - 验证>256KB也能统计
- 峰值内存 - 验证峰值只增不减
- 混合场景 - 验证小内存+大内存混合
中文乱码问题:
Windows控制台默认编码不是UTF-8,中文显示乱码。解决方案:
#include <windows.h>int main() {SetConsoleOutputCP(65001); // 设置控制台编码为UTF-8// ...测试代码
}
编译测试:
g++ -std=c++11 test/test_statistics.cpp src/CentralCache.cpp src/PageCache.cpp -o test/test_stats.exe
./test/test_stats.exe
测试结果分析:
测试1:基本分配和释放
分配3次后:allocCount=3, currentMemory=112字节(16+32+64), peakMemory=112
释放2次后:freeCount=2, currentMemory=64字节, peakMemory=112(峰值保持)
全部释放后:freeCount=3, currentMemory=0字节, peakMemory=112(峰值保持)
验证:计数准确,峰值正确保持
测试2:大内存分配(300KB)
分配后:allocCount=1, currentMemory=307200字节
释放后:freeCount=1, currentMemory=0字节
验证:大内存(走malloc)也能正确统计
测试3:峰值内存
分配1KB:currentMemory=1024, peakMemory=1024
分配2KB:currentMemory=3072, peakMemory=3072
释放1KB:currentMemory=2048, peakMemory=3072(峰值不变!)
验证:峰值是"历史最高水位",不会因释放而减少
测试4:混合场景
分配16字节+128字节+300KB:allocCount=3
全部释放后:freeCount=3, currentMemory=0
验证:小内存+大内存混合统计正常
关键验证点:
- allocCount和freeCount能正确统计
- currentMemory随分配/释放正确变化
- peakMemory记录峰值且不会减少
- 大内存(>256KB)也能正确统计
测试截图: (见博客素材/day7_性能测试*.png)
实现心得
1. 原子变量的理解
std::atomic提供线程安全的操作:
- 简单操作可以直接用运算符:
g_allocCount++ - 复杂操作需要显式调用:
g_peakMemory.load()、g_peakMemory.store() - 虽然每个操作是原子的,但"读-比较-写"的组合不是原子的,在统计场景下可以接受小误差
2. 峰值统计的巧妙之处
峰值不会因为释放而减少,这是设计的关键:
- 记录的是"历史最高水位"
- 用于评估程序最大内存需求
- 只在分配时检查和更新
3. 统计位置的选择
把统计放在ConcurrentAlloc/ConcurrentFree而不是三层内部:
- 大内存直接走malloc,也能统计到
- 避免在各层重复统计
- 统计的是"用户视角"的分配
4. Windows中文显示问题
SetConsoleOutputCP(65001)设置UTF-8编码,这是Windows平台特有的问题,Linux/Mac不需要。
代码统计
今日新增代码
Common.h(慢增长算法):
- NumMoveSize函数:+18行
ThreadCache.h(调用慢增长):
- 修改FetchFromCentralCache:+1行
ConcurrentMemoryPool.h(统一接口):
- 新建文件:+39行
ConcurrentMemoryPool.h(性能统计):
- 新增4个原子变量:+4行
- 修改ConcurrentAlloc/Free:+15行
test_concurrent_api.cpp(测试):
- 新建测试文件:+108行
test_statistics.cpp(性能统计测试):
- 新建测试文件:+156行
总计: +322行(不含测试约+77行)
当前代码总量
Common.h: 278行
ThreadCache.h: 109行
CentralCache.h/cpp: 43 + 134行
PageCache.h/cpp: 24 + 170行
ConcurrentMemoryPool.h: 62行(含性能统计)
测试代码: 264行(两个测试文件)
-------------------------
总计: 1084行
Git提交记录
# 提交1:慢增长算法
git commit -m "feat: 实现慢增长算法优化批量申请策略"2 files changed, 23 insertions(+)# 提交2:统一接口
git commit -m "feat: 实现统一对外接口ConcurrentAlloc/Free"2 files changed, 139 insertions(+)# 提交3:性能统计
git commit -m "feat: 实现基础性能统计功能"2 files changed, 178 insertions(+)# 推送到GitHub
git push→ github.com:Guojin06/HighConcurrencyMemoryPool.git
今日收获
技术收获
1. 慢增长算法理解
不是"慢慢增长",而是有上限控制的批量策略:
- 小对象多拿(512个)→ 减少调用次数
- 大对象少拿(2个)→ 避免浪费
- 上限512 → 平衡性能和锁竞争
2. 接口设计思想
统一接口的好处:
- 隐藏实现细节
- 降低使用门槛
- 自动处理边界情况(大内存直接malloc)
类似标准库的设计理念:简单易用,功能强大。
3. 函数放置位置的考量
NumMoveSize放在SizeClass而不是ThreadCache,因为:
- 和其他计算函数(RoundUp、Index)是同类
- 静态函数,逻辑集中
- 所有层都能复用
这种设计思维很重要。
4. 原子变量的应用
std::atomic是C++11的强大工具:
- 提供线程安全的操作,无需显式加锁
- 简单操作(++/–)可以直接用运算符
- 复杂操作(读-比较-写)需要用load()/store()
- 适合高频调用的统计场景
相比互斥锁的优势:
- 无锁,性能更好
- 不会影响性能测试的准确性
- 适合简单的计数操作
5. 统计设计的思考
峰值内存的设计很巧妙:
- 只增不减,记录"历史最高水位"
- 用于评估程序的最大内存需求
- 只在分配时更新,释放时不更新
这种"单向更新"的设计思路在很多场景都能用到。
工程思维
1. 迭代开发的价值
慢增长算法一开始我想写得很完美,后来发现:
- 先用简单策略跑通(固定字节数/size)
- 再加限制条件(上限512、下限2)
- 测试验证后再优化
这种思路效率很高。
2. 测试驱动开发
每个功能实现后立即测试:
- 慢增长算法:验证各种size的批量数
- 统一接口:测试小对象、大对象、边界值
发现问题立即修复,不积累技术债。
3. 错误信息的价值
编译报错has no member "GetTLSThreadCache",让我发现了函数类型理解错误。错误信息不是坏事,是学习的机会。
遗留问题
TODO标记
性能统计 已完成
Day8剩余任务:
// 1. 扩展性能指标(可选)
// - syscallCount - 系统调用次数
// - spanSplitCount - Span切分次数
// - spanMergeCount - Span合并次数
//
// 2. 计算指标(基于现有数据)
// - 内存利用率 = currentMemory / peakMemory
// - 碎片率分析
//
// 3. 性能基准测试
// - malloc vs 内存池对比测试
// - 多线程并发测试
今天原计划完成3-4个任务,实际完成了4个(超预期),提前完成了Day8的部分内容。
优化想法
1. 慢增长算法可能的优化:
当前是固定策略,后续可以考虑动态调整:
- 记录每个size的实际使用频率
- 频繁使用的size增加批量数
- 不常用的size减少批量数
这是性能优化阶段的工作。
2. 统一接口可能的扩展:
// 可以添加:
void* ConcurrentRealloc(void* ptr, size_t oldSize, size_t newSize);
size_t ConcurrentGetSize(void* ptr);
这些功能不是必须的,看后续需求。
思考与反思
时间分配
今天总用时约3.5小时:
- 巩固页合并:30分钟
- 慢增长算法:30分钟
- 统一接口:1小时(包括测试)
- 性能统计:1.5小时(包括测试和调试乱码问题)
感觉时间分配比较合理,巩固那30分钟很值得,让我对后面的开发更有信心。性能统计部分花时间较多,主要在测试设计和中文乱码调试上。
学习方法
提问式巩固很有效:
早上采用凭记忆回答问题的方式,不看代码,这种方式:
- 检验真实理解程度
- 发现知识盲区
- 加深记忆
比直接看代码效果好多了。
理解比速度重要:
今天完成了4个任务(原计划3-4个),而且每个都理解透彻了:
- 知道为什么这么设计
- 知道可能的坑在哪里
- 知道优化的方向
原本性能统计计划留到Day8,但今天状态不错就继续做了。这种"顺着状态走"的节奏挺好。
状态管理
昨天状态不好,今天早上还有点担心。但通过巩固页合并理解,找回了信心。
教训: 状态不好时,降低难度,从巩固旧知识开始,而不是强上新内容。
进度评估
对比13天规划:
- 完成 Day1-6:三层架构完成
- 完成 Day7:慢增长算法、统一接口、基础性能统计完成(Day8部分内容提前)
- ⏳ Day8:性能benchmark测试
- ⏳ Day9:多线程测试
- ⏳ Day10-11:性能优化
目前进度: 超预期!原计划Day7完成3个任务,实际完成4个任务,Day8的基础性能统计提前完成。
明天计划
Day8任务(调整后):
-
性能benchmark测试(2-3小时)
- 对比测试:malloc vs 内存池
- 单线程小内存分配测试
- 测量分配/释放速度
- 分析统计数据
-
多线程并发测试准备(1小时)
- 设计多线程测试场景
- 实现基础的多线程测试框架
预计用时:3-4小时
可能合并Day8和Day9部分内容,因为Day7提前完成了Day8的统计功能。
一些感悟
今天最大的感受是巩固理解的重要性。
昨天学了页合并算法,虽然代码写出来了,但心里还是有点虚。今天早上通过提问检验,发现自己理解得还不错,这让我很有信心。
还有一个体会是接口设计的思想。ConcurrentAlloc/Free这两个函数虽然只有30多行,但封装了内部复杂度,让用户使用起来很简单。这就是抽象的力量。
慢增长算法看起来简单,但设计思路很巧妙:
- 用除法计算基础批量数
- 用上限防止过大
- 用下限保证批量效果
这种多层保护的设计模式,在很多地方都能用到。
关于原子变量的理解:
今天实现性能统计时,对std::atomic有了更深的理解。它不是万能的,只适合简单的操作。对于"读-比较-写"这种复合操作,虽然每一步是原子的,但整体不是。不过在统计场景下,这种小误差可以接受。
这让我意识到:没有完美的方案,只有适合场景的方案。
明天开始性能测试,终于可以看到内存池相比malloc到底快多少了!很期待!
项目地址: https://github.com/Guojin06/HighConcurrencyMemoryPool
Day7完成进度:
- 巩固页合并理解
- 实现慢增长算法
- 统一对外接口
- 基础性能统计(✨提前完成)
- 性能benchmark测试(Day8)
- 多线程测试(Day8-9)
总代码量: 845 → 1084行(+239行,含测试264行,核心代码+77行)
GitHub提交: 3次提交,已推送
📊 Day7-8过渡:性能Benchmark测试
一、什么是Benchmark测试?
Benchmark(基准测试) 是一种性能测试方法,通过对比测试来评估系统性能:
- 目的: 对比内存池与系统
malloc/free的性能差异 - 核心指标: 耗时(毫秒)、分配次数、峰值内存
- 测试方法: 相同场景下,分别测试两种方案,计算性能提升倍数
二、测试代码实现
1. 计时原理
使用C++11的<chrono>库实现高精度计时:
// 记录开始时间
auto start = std::chrono::high_resolution_clock::now();// 执行测试代码...// 记录结束时间
auto end = std::chrono::high_resolution_clock::now();// 计算时间差(毫秒)
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
关键点:
high_resolution_clock:高精度时钟(纳秒级)duration_cast<milliseconds>:将时间差转换为毫秒.count():获取数值
2. 测试框架设计
// 测试malloc性能
long long BenchmarkMalloc(size_t size, size_t rounds, const char* testName) {auto start = std::chrono::high_resolution_clock::now();// 核心:立即分配立即释放for (size_t i = 0; i < rounds; i++) {void* p = malloc(size);free(p);}auto end = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();return duration;
}// 测试内存池性能
long long BenchmarkMemoryPool(size_t size, size_t rounds, const char* testName) {// 重置统计数据g_allocCount.store(0);g_freeCount.store(0);g_currentMemory.store(0);g_peakMemory.store(0);auto start = std::chrono::high_resolution_clock::now();for (size_t i = 0; i < rounds; i++) {void* p = ConcurrentAlloc(size);ConcurrentFree(p, size);}auto end = std::chrono::high_resolution_clock::now();auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();return duration;
}// 性能对比
void ComparePerformance(size_t size, size_t rounds, const char* testName) {long long mallocTime = BenchmarkMalloc(size, rounds, testName);long long mempoolTime = BenchmarkMemoryPool(size, rounds, testName);// 计算性能提升倍数double speedup = (double)mallocTime / mempoolTime;if (speedup > 1.0) {cout << "内存池更快 " << (speedup - 1.0) * 100 << "%" << endl;} else {cout << "malloc更快 " << (1.0 / speedup - 1.0) * 100 << "%" << endl;}
}
3. 测试场景设计
// 场景1:小对象高频分配(内存池的强项)
ComparePerformance(16, 1000000, "小对象高频分配(16字节 x 100万次)");// 场景2:中等对象
ComparePerformance(1024, 100000, "中等对象(1KB x 10万次)");// 场景3:大对象(验证直接走malloc)
ComparePerformance(300 * 1024, 10000, "大对象(300KB x 1万次)");
三、测试结果与分析
场景1:小对象高频分配(16字节 x 100万次)

| 指标 | malloc | 内存池 | 性能提升 |
|---|---|---|---|
| 耗时 | 365ms | 149ms | 2.45x |
| 结论 | - | - | 内存池快144% |
分析:
- 符合设计预期:小对象高频分配是内存池的设计目标
- 优势明显:避免频繁系统调用,ThreadCache无锁快速响应
- 验证成功:内存池在目标场景下性能提升显著
场景2:中等对象(1KB x 10万次)
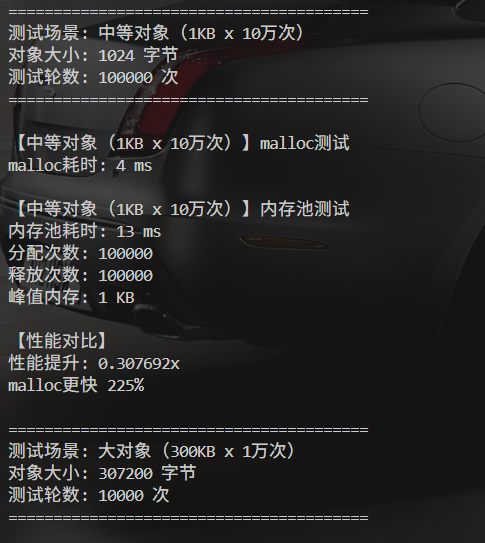
| 指标 | malloc | 内存池 | 性能提升 |
|---|---|---|---|
| 耗时 | 4ms | 13ms | 0.31x |
| 结论 | - | - | malloc快225% |
分析:
- ⚠️ 意外结果:中等对象反而比malloc慢
- 🔍 可能原因:
- 立即释放导致频繁加锁(CentralCache锁)
- 1KB对象可能频繁触发批量申请/返还
- malloc对中等对象有专门优化
- 📝 优化方向:
- 调整慢增长算法参数
- 增加ThreadCache缓存上限
- 优化CentralCache锁粒度
场景3:大对象(300KB x 1万次)

| 指标 | malloc | 内存池 | 性能提升 |
|---|---|---|---|
| 耗时 | 2ms | 2ms | 1.0x |
| 结论 | - | - | ➖ 性能相当 |
分析:
- 符合设计:大对象(>256KB)直接走malloc
- 验证逻辑:ConcurrentAlloc对大对象的处理符合预期
- 无额外开销:统计功能对性能影响可忽略
四、关键技术点总结
1. 为什么采用"立即释放"模式?
for (size_t i = 0; i < rounds; i++) {void* p = malloc(size); // 分配free(p); // 立即释放
}
原因:
- 测试纯开销:只测量分配/释放的性能,不考虑内存使用
- 模拟高频场景:如临时对象的创建销毁
- 避免内存累积:防止系统内存不足影响测试
2. 性能提升计算公式
speedup = malloc耗时 / 内存池耗时// 示例:
// malloc: 365ms,内存池: 149ms
// speedup = 365 / 149 = 2.45x
// 提升 = (2.45 - 1.0) × 100% = 145%
3. 统计数据的价值
cout << "分配次数: " << g_allocCount.load() << endl;
cout << "释放次数: " << g_freeCount.load() << endl;
cout << "峰值内存: " << g_peakMemory.load() / 1024 << " KB" << endl;
- 验证正确性:分配次数 = 释放次数 = 测试轮数
- 观察内存使用:峰值内存反映单次分配大小(立即释放模式下)
- 发现异常:如果数据异常可快速定位问题
五、测试截图汇总
测试过程中的关键截图:
-
统计功能验证:
day7_性能测试1结果.png:基础分配释放day7_性能测试2结果.png:大内存测试day_7性能测试3结果.png:峰值内存day7_性能测试4结果.png:混合场景
-
Benchmark对比:
day_7高并发内存池性能测试场景1小对象高频分配.png:小对象优势day7_性能测试中等对象对比malloc.png:中等对象待优化day7_性能测试大对象对比malloc.png:大对象直接malloc
六、收获与思考
1. Benchmark测试的意义
- 量化性能:用数据说话,而不是主观感觉
- 发现问题:中等对象性能问题在测试中暴露
- 指导优化:明确优化方向和优先级
2. 性能不是绝对的
测试结果告诉我:没有银弹。内存池在小对象场景优势明显,但中等对象反而慢。带来一些思考:
- 要针对具体场景选择合适的方案
- 要持续优化而不是一劳永逸
3. 下一步优化方向
- 分析中等对象慢的根本原因(Day9)
- 调整慢增长算法参数
- 增加多线程并发测试(Day8)
- 优化CentralCache锁粒度
Day7-8过渡完成进度:
- Benchmark测试框架
- 3个测试场景
- 性能数据分析
- 多线程并发测试(Day8)
- 性能优化(Day9)
新增代码量: 约100行(test_benchmark.cpp)