web自动化测试-selenium_01_元素定位
文章目录
- 一、id 定位
- 二、name 定位
- 三、class_name 定位
- 四、tag_name 定位
- 五、link_text 定位
- 六、partial_link_text 定位
- 七、XPath 定位
- 1. 基本语法
- 2. 常用定位方式
- 3. 优缺点
- 八、CSS 定位
- 1. 基本语法
- 2. 常用定位方式
- 3. 优缺点
- XPath与CSS定位对比与选择建议
- 示例总结
1.在pycharm终端:
pip install selenium
2.安装浏览器驱动:下载地址:https://googlechromelabs.github.io/chrome-for-testing/
添加浏览器驱动的环境变量
第一个案例:
# 1.导入包
from selenium import webdriver
import time
# 2.创建浏览器驱动对象
driver = webdriver.Chrome()
# 3.打开web页面
driver.get("https://www.baidu.com")
# 4.暂停3秒
time.sleep(3)
# 5.关闭驱动对象
driver.quit()
Selenium 八种定位元素方式:
- id
- name
- class_name
- tag_name
- link_text
- partial_link_text
- XPath
- CSS
一、id 定位
id 定位就是通过元素的 id 属性来定位元素,HTML 规定 id 属性在整个HTML文档中必须是唯一的。
前提:元素有 id 属性。
element = driver.find_element(By.ID,'id')
⭐ 案例
需求:打开注册 A.html 页面,完成以下操作:
- 使用 id 定位,输入用户名:admin
- 使用 id 定位,输入密码:123456
- 3秒后关闭浏览器窗口
# 1.导入包
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep# 2.获取浏览器对象
driver = webdriver.Chrome()# 3.打开url
# 改成实际路径
url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)# 4.查找 用户名元素
username = driver.find_element(By.ID,'userA')# 5.查找 密码元素
password = driver.find_element(By.ID,'passwordA')# 6.用户名输入 admin
# send_keys('内容')
username.send_keys('admin')
# 7.密码输入 123456
password.send_keys('123456')# 8.暂停3秒
sleep(3)# 9.退出浏览器驱动
driver.quit()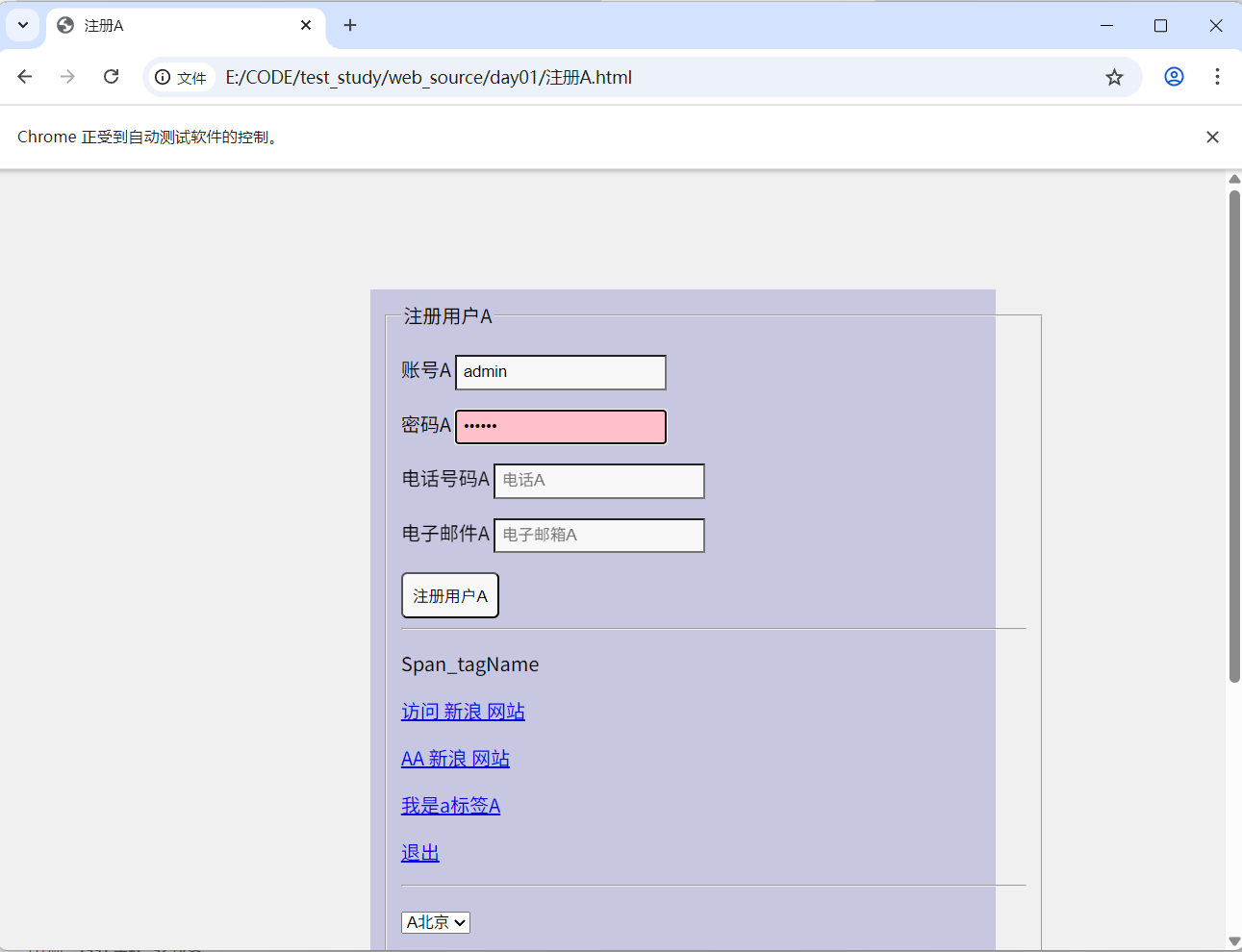
二、name 定位
name 定位就是根据元素 name 属性来定位,HTML 文档中 name 的属性值是可以重复的。
前提:元素有 name 属性。
element = driver.find_element(By.NAME,'name')
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)username = driver.find_element(By.NAME,'userA').send_keys('admin')
password = driver.find_element(By.NAME,'passwordA').send_keys('123456')sleep(3)driver.quit()
三、class_name 定位
class_name 定位就是根据元素 class 属性值来定位元素。
HTML 通过使用 class 来定义元素的样式。
前提:元素有 class 属性。
注意:如果 class 有多个属性值,只能使用其中的一个。
element = driver.find_element(By.CLASS_NAME,'class_name')
⭐ 案例
需求:打开注册A.html页面,完成以下操作:
- 通过 class_name 定位电话号码 A,并输入:
18611111111 - 3秒后关闭浏览器窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)telephone = driver.find_element(By.CLASS_NAME,'telA')telephone.send_keys('18611111111')sleep(3)driver.quit()
四、tag_name 定位
tag_name 定位就是通过标签名来定位。
HTML 本质就是由不同的 tag 组成,每一种标签一般在页面中会存在多个,所以不方便进行精确定位,一般很少使用。
element = driver.find_element(By.TAG_NAME,'tag_name')
如果存在多个相同标签,则返回符合条件的第一个标签。
需求:使用 tag_name 定位方式,使用注册A.html页面,用户名输入 admin
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)username = driver.find_element(By.TAG_NAME,'input')
username.send_keys('admin')sleep(3)driver.quit()
要获取相同标签名的第二个元素,可以使用 find_elements 方法先获取所有符合条件的元素列表,再通过索引获取第二个元素(索引从 0 开始,第二个元素的索引为 1)。
示例代码如下:
# 导入By类
from selenium.webdriver.common.by import By# 获取所有指定标签名的元素(返回列表)
elements = driver.find_elements(By.TAG_NAME, 'tag_name')# 获取第二个元素(索引为1)
if len(elements) >= 2: # 确保列表至少有2个元素,避免索引越界second_element = elements[1]
else:print("没有足够的元素")
说明:
find_elements会返回页面中所有符合标签名的元素,以列表形式存储。- 列表的索引从 0 开始,因此
elements[1]对应第二个元素。 - 使用前建议判断列表长度,避免因元素数量不足导致报错。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)# 获取所有input元素(列表形式)
inputs = driver.find_elements(By.TAG_NAME, 'input')# 第一个input通常是用户名(索引0)
username = inputs[0]
username.send_keys('admin')# 第二个input通常是密码(索引1)
password = inputs[1]
password.send_keys('123456') # 输入密码sleep(3)driver.quit()
五、link_text 定位
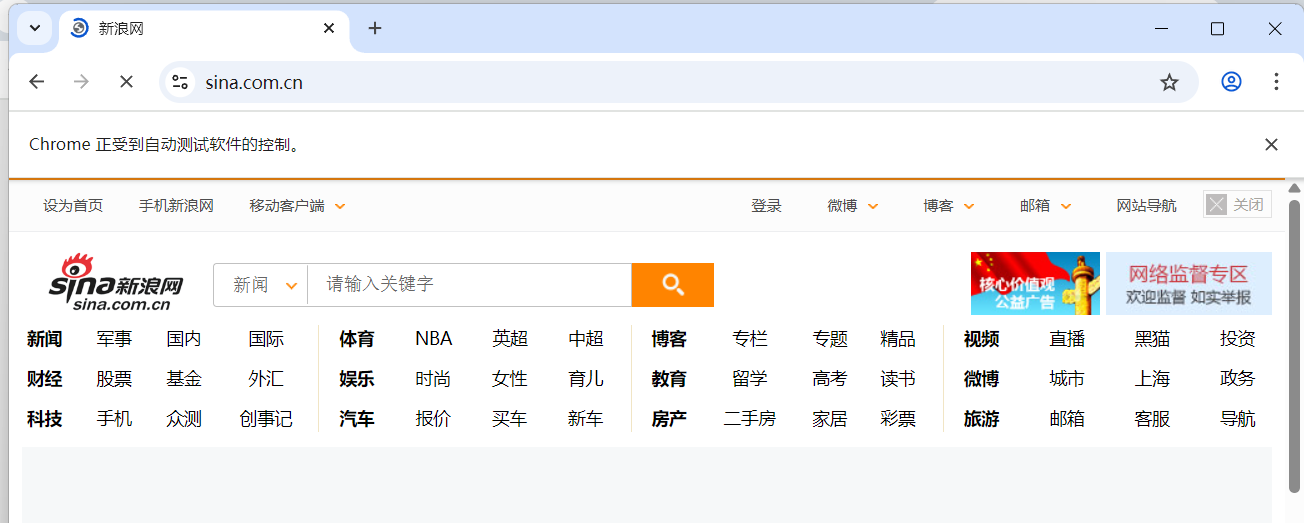
link_text 定位是专门用来定位超链接元素(<a>标签</a>),并且是通过超链接的文本内容来定位元素。
element = driver.find_element(By.LINK_TEXT, 'link_text')
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)driver.find_element(By.LINK_TEXT,'访问 新浪 网站').click()sleep(3)
driver.quit()

六、partial_link_text 定位
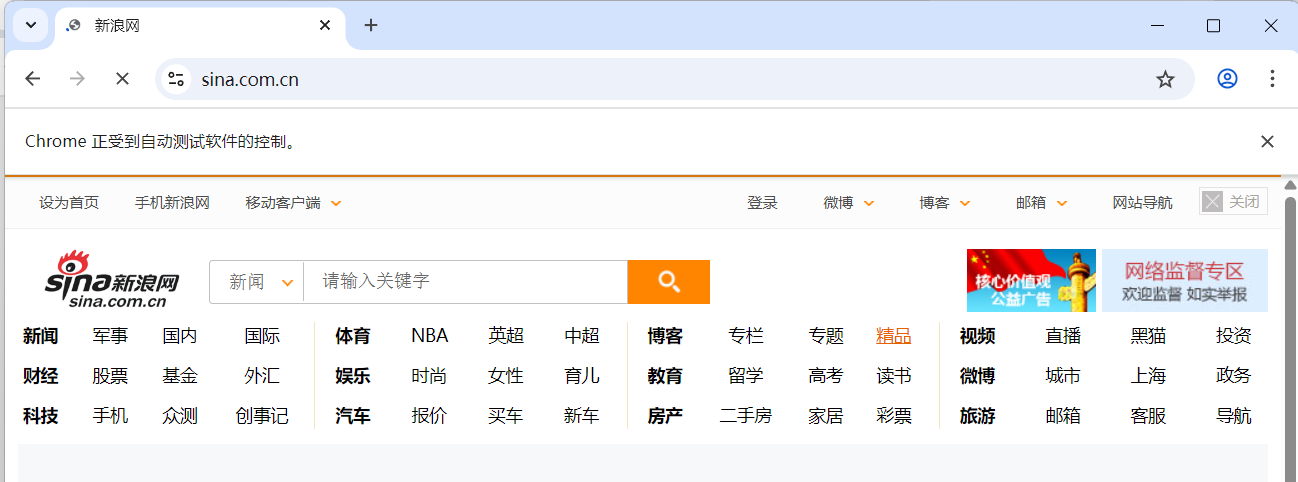
在 Selenium 中,partial_link_text 是一种通过链接文本的部分内容来定位超链接元素(<a> 标签)的方法。它适用于当你知道链接文本的一部分,但不确定完整文本时使用。
find_element(By.PARTIAL_LINK_TEXT, 部分文本)
-
匹配规则:
只要链接的完整文本(<a>标签内的文本内容)中包含你指定的“部分文本”,就会被匹配到。
例如,链接文本为“点击查看示例页面”,使用partial_link_text="示例"可以成功定位。 -
大小写敏感:
匹配过程区分大小写(不同浏览器可能略有差异,建议按实际文本大小写编写)。 -
返回结果:
find_element会返回第一个匹配到的元素。- 若要获取所有匹配的元素,使用
find_elements(返回列表,无匹配时为空列表)。
-
适用元素:
仅用于定位<a>标签的超链接,其他标签(如按钮)不适用。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)driver.find_element(By.PARTIAL_LINK_TEXT,'访问').click()sleep(3)
driver.quit()
七、XPath 定位
XPath 是一种在 XML/HTML 文档中查找元素的语言,通过路径表达式定位元素,支持复杂条件匹配,灵活性极高。
1. 基本语法
- 绝对路径:从根节点(
/html)开始,逐级书写,如:
html/body/div[1]/a(不推荐,页面结构变化易失效)。 - 相对路径:从任意节点开始,以
//开头,如:
//div[@class="container"]/a(推荐,更稳定)。
2. 常用定位方式
| 场景 | 表达式示例 | 说明 |
|---|---|---|
| 通过标签名 | //tagname | 匹配所有 tagname 标签(如 //a) |
| 通过属性 | //tagname[@属性名="属性值"] | 如 //input[@id="username"] |
| 通过部分属性值 | //tagname[contains(@属性名, "部分值")] | 包含://a[contains(@href, "login")] |
//tagname[starts-with(@属性名, "开头值")] | 开头://img[starts-with(@src, "logo")] | |
| 通过文本内容 | //tagname[text()="完整文本"] | 精确匹配文本,如 //button[text()="登录"] |
| 通过部分文本 | //tagname[contains(text(), "部分文本")] | 如 //p[contains(text(), "欢迎")] |
| 索引定位(从1开始) | //tagname[index] | 如 //li[2](第二个li标签) |
| 多条件组合 | //tagname[@a="x" and @b="y"] | 同时满足多个属性条件 |
| 父节点/子节点/兄弟节点 | //div[@id="box"]/parent::*(父节点) | parent::* 表示父节点,child::* 子节点,following-sibling::* 后续兄弟 |
3. 优缺点
- 优点:支持文本定位、复杂条件组合、层级关系灵活,几乎能定位所有元素。
- 缺点:语法相对复杂,定位速度略慢于 CSS。
⭐ 绝对定位
# 相对路径://*[@id="userA"]
# 绝对路径:/html/body/form/div/fieldset/p[1]/inputfrom selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)try:driver.find_element(By.XPATH,'/html/body/form/div/fieldset/p[1]/input').send_keys('admin')sleep(2)finally:driver.quit()
⭐ 相对定位:
# 相对路径://*[@id="userA"]
# 绝对路径:/html/body/form/div/fieldset/p[1]/inputfrom selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepdriver = webdriver.Chrome()url = r"E:\CODE\test_study\web_source\day01\注册A.html"
driver.get(url)try:driver.find_element(By.XPATH,'//*[@id="userA"]').send_keys('admin')sleep(2)finally:driver.quit()

八、CSS 定位
CSS(层叠样式表)定位通过元素的样式属性或层级关系定位,语法简洁,定位速度快,是实际项目中推荐的方式。
1. 基本语法
- 通过标签名:
tagname(如a匹配所有<a>标签)。 - 通过ID:
#id值(如#username匹配id="username"的元素)。 - 通过class:
.class值(如.btn匹配class="btn"的元素,多class用.class1.class2)。
2. 常用定位方式
| 场景 | 表达式示例 | 说明 |
|---|---|---|
| 通过属性 | tagname[属性名="属性值"] | 如 input[name="password"] |
| 部分属性值(包含) | tagname[属性名*="部分值"] | 如 a[href*="register"] |
| 部分属性值(开头) | tagname[属性名^="开头值"] | 如 img[src^="banner"] |
| 部分属性值(结尾) | tagname[属性名$="结尾值"] | 如 a[href$=".html"] |
| 层级关系(直接子元素) | 父元素 > 子元素 | 如 div.container > ul > li |
| 层级关系(后代元素) | 祖先元素 后代元素 | 如 .nav a(匹配class为nav内的所有a标签) |
| 索引定位(从1开始) | tagname:nth-child(n) | 如 li:nth-child(3)(父元素下第3个li) |
| 第一个/最后一个子元素 | tagname:first-child / :last-child | 如 tr:first-child |
3. 优缺点
- 优点:语法简洁,定位速度快,支持大多数场景,是Selenium推荐的定位方式。
- 缺点:不支持直接通过文本内容定位(需结合其他属性),复杂层级条件不如XPath灵活。
XPath与CSS定位对比与选择建议
| 场景 | 优先选择 | 原因 |
|---|---|---|
| 简单ID/Class/属性定位 | CSS | 语法更简洁,速度更快 |
| 文本内容定位 | XPath | CSS不支持直接文本匹配 |
| 复杂条件组合(多属性) | XPath | 支持 and/or 逻辑,更灵活 |
| 层级关系(如兄弟节点) | XPath | 处理层级关系更直观 |
| 性能优先 | CSS | 浏览器对CSS解析效率更高 |
示例总结
| 需求 | XPath 表达式 | CSS 表达式 |
|---|---|---|
| 定位id为"login"的按钮 | //button[@id="login"] | button#login |
| 定位class含"active"的a标签 | //a[contains(@class, "active")] | a[class*="active"] |
| 定位文本为"首页"的链接 | //a[text()="首页"] | 无直接支持(需间接通过其他属性) |
| 定位第2个li子元素 | //ul/li[2] | ul li:nth-child(2) |
提示:实际使用中,建议优先用CSS,复杂场景(如文本定位)再用XPath,同时避免过度依赖绝对路径,尽量通过稳定的属性(如id、独特class)定位。