BELLE-A论文翻译
BELLE: A Bi-Level Multi-Agent Reasoning Framework for Multi-Hop Question Answering
BELLE:一种用于多跳问答的双层级多智能体推理框架
摘要
多跳问答(Multi-hop QA)涉及查找多个相关段落,并逐步进行推理以回答复杂问题。以往基于大语言模型(LLM)的多跳问答研究,往往忽略了问题类型之间的差异,采用统一的建模方法。本文首先对公开的多跳问答基准进行了深入分析,将问题划分为四种类型,并评估了五种前沿方法:Chain-of-Thought(CoT)、单步(Single-step)、迭代步(Iterative-step)、子步(Sub-step)和自适应步(Adaptive-step)。我们发现,不同类型的多跳问题对不同方法的敏感度不同。
为此,我们提出了一种双层级多智能体推理框架(BELLE),通过将每种方法视为一个“操作符”,并根据问题类型动态组合这些操作符来解决多跳问答任务。BELLE的第一层包含多个智能体,通过辩论制定一个可执行的操作符组合计划。在辩论过程中,除了基本的正方、反方和裁判角色外,我们在第二层引入了==“快思考”和“慢思考”智能体==,以监控观点变化是否合理。
大量实验表明,BELLE在多个数据集上显著优于强基线模型。此外,在更复杂的多跳问答任务中,BELLE的模型消耗具有更高的成本效益。
作者团队:
- 张涛林(Taolin Zhang)——合肥工业大学,计算机与信息工程学院
- 李冬阳(Dongyang Li)——上海电力大学
- 陈启洲(Qizhou Chen)——阿里云,华东师范大学
- 王成宇(Chengyu Wang)(通讯作者)——阿里云
- 何晓峰(Xiaofeng He)——华东师范大学
出版期刊与日期:
-
会议名称:The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025)
第63届计算语言学协会年会(ACL 2025) -
会议时间:2025年7月27日 – 8月1日
-
出版页码:第4184–4202页
-
出版社:Association for Computational Linguistics(ACL)
1 引言
近年来,大语言模型(LLMs)已成为现代自然语言处理(NLP)系统的基础架构(Blevins 等,2023;Zhang 等,2024b,a;Chu 等,2024a)。此外,思维链(Chain-of-Thought, CoT)提示技术进一步增强了 LLM 的推理能力(Wei 等,2022;Shaikh 等,2023;Chu 等,2024b)。然而,多跳问答(multi-hop QA)的复杂性常常超出 LLM 的知识边界,导致生成答案中出现事实性错误,即所谓的“幻觉”现象(Khalifa 等,2023;Huang 等,2024;Chu 等,2024a;Shi 等,2024)。
在文献中,基于 LLM 的多跳问答方法大致可分为两类:
(1)闭卷推理(Closed-book Reasoning):该方法依赖 LLM 对多跳问题的理解能力,通过在生成过程中进行概率采样来得到答案。例如,CoT 方法通过逐步提示 LLM 来生成推理过程。考虑到复杂的多跳推理路径,一些研究(Dua 等,2022;Zhou 等,2023)将其分解为子问题并逐步求解,另一些研究(Yao 等,2023;Chu 等,2024a;Menon 等,2024)则将推理过程建模为在概率推理树上进行广度优先(BFS)或深度优先(DFS)搜索。然而,正如 Borgeaud 等(2022)所指出的,LLM 所学的知识往往不足以回答复杂问题,因此需要外部数据支持。
(2)检索增强推理(Retrieval-augmented Reasoning):早期工作采用单步检索,但常常难以收集回答多跳问题所需的全部知识,导致知识遗漏(Lazaridou 等,2022;Borgeaud 等,2022;Izacard 等,2023)。一些方法通过迭代式检索,将前一轮的输出与子问题拼接,逐步获取更多信息(Press 等,2023;Shao 等,2023;Jiang 等,2024)。如图1所示,无论面对何种多跳问题,检索方法都直接召回外部知识并结合输入进行回答。尽管自适应方法(Jeong 等,2024)引入了分类器来判断问题复杂度,但仍采用固定流程处理所有问题类型,这不仅增加了计算负担,也限制了其在需要高推理速度的场景中的应用(Mavi 等,2024;Zhuang 等,2024)。
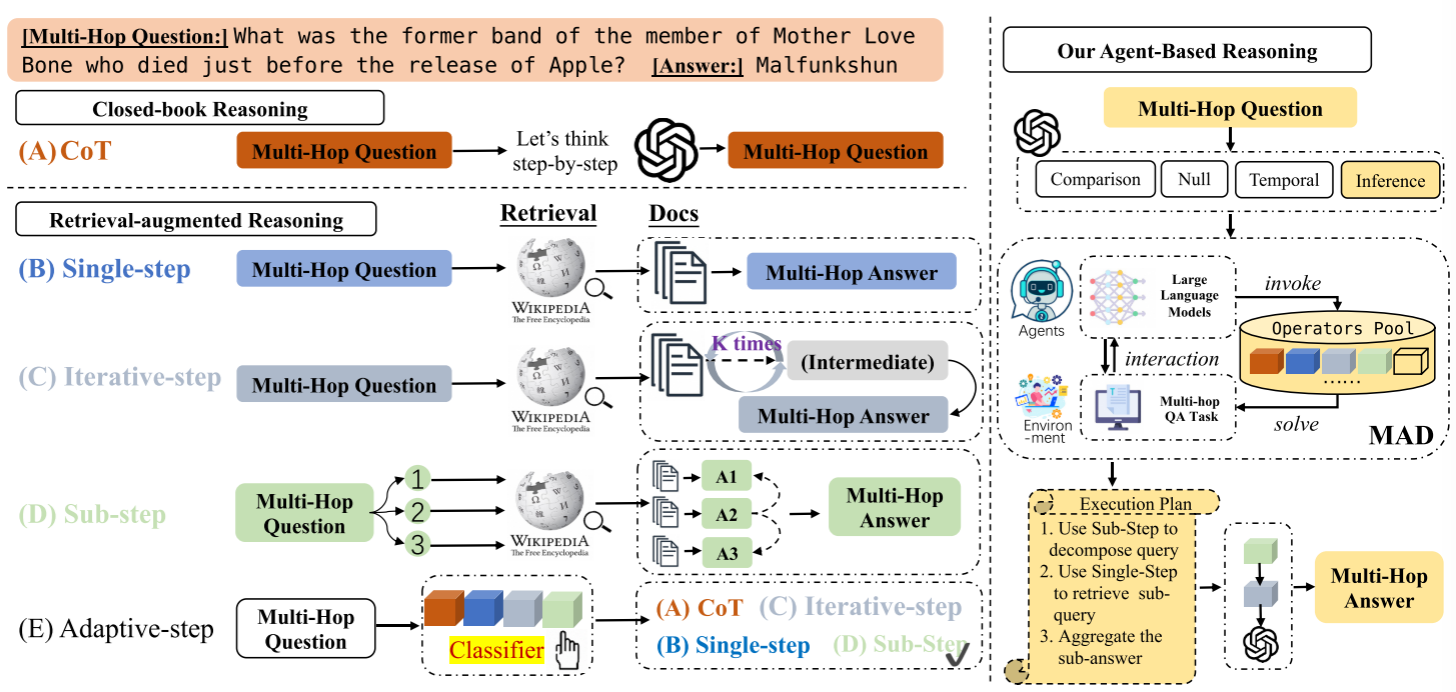
图 1:多跳问答方法对比。(1)闭卷推理不考虑引入外部知识;(2)检索增强推理采用端到端的固定方案处理所有多跳问题;(3)我们的智能体推理框架则针对问题类型动态生成执行计划,组合合适的多跳操作符。
Adaptive-step(自适应步骤法): “先分类,再匹配方法”,即通过分类器判断问题类型,再自适应选择合适的推理策略(而非用固定方法解决所有问题)。而传统多跳 QA 方法(如 Single-step 单步检索、Iterative-step 迭代检索)存在 “一刀切” 问题:无论问题简单 / 复杂,都用同一套流程,导致简单问题浪费算力、复杂问题推理不足。Adaptive-step 的核心是 “按需分配策略”:先通过分类器识别问题类型,再为不同类型匹配最优推理方法,平衡性能与效率。