Datawhale秋训营-“大运河杯”数据开发应用创新大赛
Datawhale秋训营-“大运河杯”数据开发应用创新大赛
一、LLM
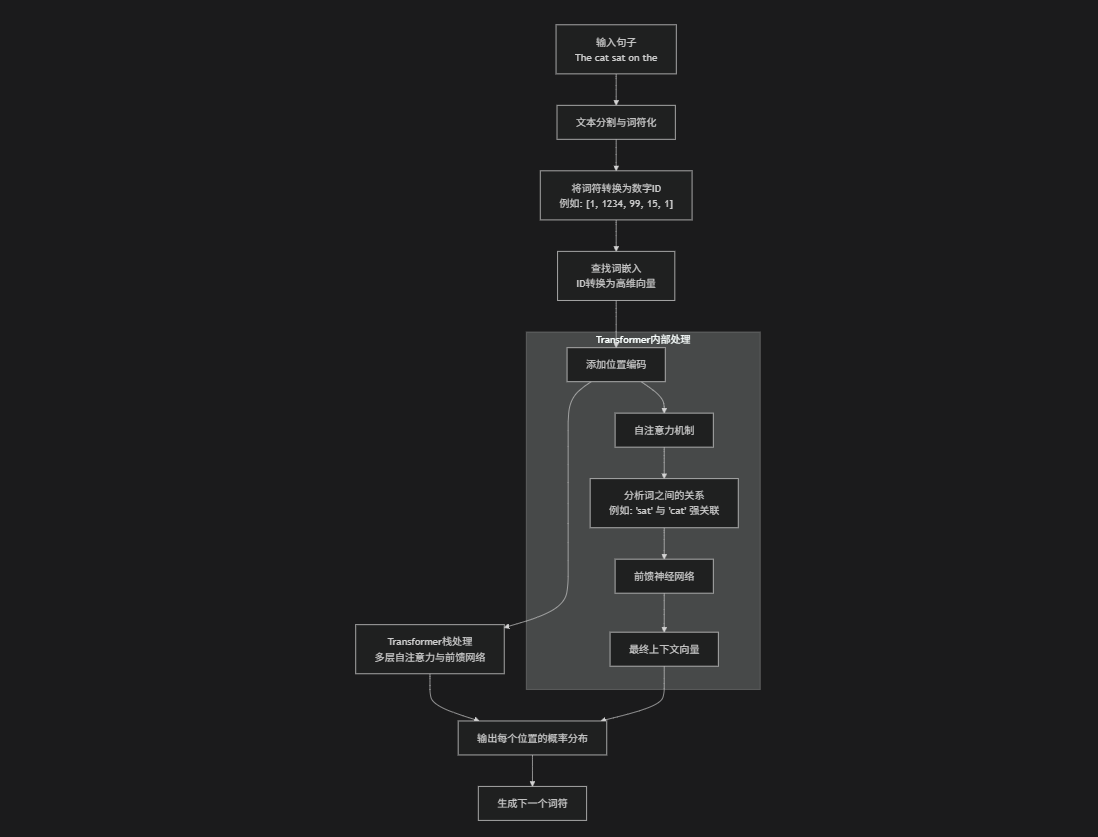
1. 数据预处理和词符化(Tokenization)
步骤描述:LLM 首先将输入文本分解成更小的单元,称为词符(tokens)。词符可以是单词、子词或字符,这取决于所使用的词符化方法(如 Byte-Pair Encoding 或 WordPiece)。例如,单词 "playing" 可能被分解为 "play" 和 "##ing"。
目的:将文本转换为模型可以处理的数字形式。
例子:假设输入句子是 "The cat sat on the"。词符化后可能得到词符序列:["The", "cat", "sat", "on", "the"]。每个词符被映射到一个唯一的 ID。
2. 词嵌入(Word Embedding)
步骤描述:每个词符 ID 被转换为一个高维向量(通常有数百或数千维),称为词嵌入。这些嵌入捕获词的语义和语法信息(例如,相似词有相似向量)。
目的:将离散的词符转换为连续的数值表示,便于模型处理。
例子:词符 "cat" 可能被映射为一个向量 [0.2, -0.5, 0.8, ...],而 "dog" 的向量可能接近它,因为它们在语义上相似。
文本的语义关系可以通过向量关系来体现。 比如经典的“国王 - 男人 + 女人 ≈ 女王”。
3. 位置编码(Positional Encoding)
步骤描述:Transformer 模型本身不处理序列顺序,因此需要添加位置信息。位置编码是一个与词嵌入相同维度的向量,它编码每个词符在序列中的位置。通常使用正弦和余弦函数来生成位置编码。
目的:让模型理解词符的顺序和相对位置。
例子:对于序列 ["The", "cat", "sat", "on", "the"],第一个词符 "The" 获得一个位置编码向量,第二个词符 "cat" 获得另一个,依此类推。这些位置编码被添加到词嵌入中,形成最终的输入向量。
4. Transformer 架构处理
步骤描述:输入向量通过多个 Transformer 块(层)进行处理。每个 Transformer 块包括两个主要组件:
自注意力机制(Self-Attention):计算每个词符与其他所有词符的相关性权重,从而捕捉上下文依赖。例如,在处理 "sat" 时,模型会关注 "cat" 和 "on" 等词。
前馈神经网络(Feed-Forward Network):对每个词符的表示进行非线性变换,增加模型的表达能力。
目的:逐步提取和融合上下文信息,生成每个词符的丰富表示。
例子:对于输入序列 "The cat sat on the",自注意力机制可能发现 "sat" 与 "cat" 强相关(因为猫是坐的主体),而 "on" 与 "the" 相关(表示位置)。
5. 输出层和概率分布
步骤描述:最后一个 Transformer 块的输出被传递到一个线性层,然后通过 softmax 函数转换为概率分布。这个分布表示在给定上下文的情况下,下一个词符的可能性。
目的:预测下一个词符。
例子:对于上下文 "The cat sat on the",模型可能输出一个概率分布,其中 "mat" 的概率为 0.6,"floor" 的概率为 0.3,其他词概率较低。模型选择概率最高的词符作为预测结果。
6. 训练过程(预训练和微调)
预训练:LLM 首先在大量文本数据(如互联网文本)上进行自监督学习。训练目标是预测下一个词(语言建模任务)。模型通过调整参数(如权重和偏置)来最小化预测误差(使用交叉熵损失)。
微调:预训练后,模型可以在特定任务(如问答或翻译)上进行微调,使用有标签数据进一步调整参数。
例子:在预训练中,模型看到句子 "The cat sat on the mat",并学习预测 "mat" 作为 "The cat sat on the" 的下一个词。通过数十亿个这样的例子,模型学习语言模式。
7. 文本生成(推理阶段)
步骤描述:在生成文本时,模型使用自回归方式,即迭代地预测下一个词符,并将预测的词符添加到输入中,继续预测。为了生成多样化的文本,通常使用采样策略(如贪婪搜索、束搜索或 top-k 采样)。
目的:生成连贯的、上下文相关的文本。
例子:假设我们输入提示 "The cat sat on the",模型预测下一个词为 "mat"。然后,输入变为 "The cat sat on the mat",模型可能预测下一个词为 "and",继续生成 "and fell asleep"。
二、文本嵌入详细步骤
前提:为文本“绘制地图”的技术。这张地图不是普通的二维地图,而是一个高维空间(比如几百甚至几千维)的地图
语义相近的文本,在地图上的位置也相近。 比如“猫”和“狗狗”的距离,会比“猫”和“汽车”的距离近得多。
文本的语义关系可以通过向量关系来体现。 比如经典的“国王 - 男人 + 女人 ≈ 女王”。
步骤1:文本预处理
首先,我们需要将原始的文本数据清理和标准化,为后续处理做准备。
操作:包括转换为小写、去除标点符号、处理特殊字符、分词等。
目的:减少噪音,让模型专注于有意义的词汇。
例子:句子
"The cat sat on the mat, didn't it?"预处理后可能变成:
["the", "cat", "sat", "on", "the", "mat", "did", "not", "it"]
步骤2:词符化
将预处理后的文本分解成模型能够处理的基本单元,称为“词符”。
操作:对于简单情况,词符就是单词。但对于复杂语言或解决未知词汇问题,会使用子词分词法(如BERT用的WordPiece,GPT用的Byte-Pair Encoding)。
目的:建立模型的基础词汇表。
例子:单词
"playing"可能会被分词为["play", "##ing"]两个词符。
步骤3:将词符映射到ID
模型内部有一个巨大的词汇表,每个词符对应一个唯一的数字ID。
操作:根据上一步的分词结果,将每个词符替换成其在词汇表中的ID。
目的:将文本转换为数字,这是计算机能够理解的方式。
例子:假设词汇表中:
"cat"-> ID 1234"mat"-> ID 5678那么句子
["the", "cat", "sat", "on", "the", "mat"]就变为[1, 1234, 99, 15, 1, 5678](这里的数字是假设的)。
步骤4:查找初始词向量
这是嵌入过程的起点。模型拥有一个“查找表”,其中为词汇表中的每一个ID都分配了一个初始的、密集的向量(即词嵌入)。
操作:根据上一步得到的ID序列,从嵌入矩阵中查找对应的向量。
目的:将离散的ID转换为连续的、有数学意义的向量表示。
例子:ID
1234("cat") 对应的向量可能是一个300维的数组,例如[0.2, -0.5, 0.8, ..., 0.1]。ID5678("mat") 对应的向量可能是[0.3, -0.4, 0.7, ..., 0.2]。
关键点:这些初始向量最初是随机生成的,它们的“意义”是在模型训练过程中逐渐学习到的。
步骤5:从词嵌入到文本嵌入(核心步骤)
这是最核心的一步。我们需要将一系列词向量(代表一个句子或段落)合并成一个单一的、固定长度的文本嵌入向量。有几种主要的方法:
方法A:平均池化
操作:将一个句子中所有词向量的每一个维度进行算术平均。
优点:简单、快速。
缺点:忽略了词序和语法结构。
例子:对于句子
"The cat sat",我们有三个词向量 V_the, V_cat, V_sat。文本嵌入 =
(V_the + V_cat + V_sat) / 3
方法B:使用Transformer模型(如BERT) 这是现代嵌入技术的主流方法。
操作:
将词向量序列输入到Transformer模型中。
模型通过自注意力机制,让每个词都能与句子中的其他所有词进行“交互”,从而根据上下文来调整每个词的表示。例如,“苹果”这个词在“吃苹果”和“苹果手机”中的向量会是不同的。
我们通常取第一个特殊词符
[CLS]对应的输出向量作为整个句子的嵌入。或者,也可以将所有词的输出向量进行平均。
优点:能生成上下文感知的、高质量的嵌入,能捕捉复杂的语义和语法关系。
缺点:计算更复杂。
步骤6:输出与应用
经过以上步骤,我们得到了一个能够代表输入文本语义的、固定维度的浮点数向量。这个向量就是“文本嵌入”。
形态:一个数组,例如
[0.12, -0.45, 0.88, ..., -0.02](维度为384或768等)。应用:这个向量可以用于各种下游任务,如:
语义搜索:比较查询和文档的嵌入向量的相似度。
文本分类:将这个向量输入到一个分类器中。
聚类:将相似的文本向量聚成一类。
Thinking Bubble
当你向Deepseek询问了一个问题,这整个过程到底发生了什么?
首先,是LLM语言大模型的构建,先将数以亿计的文本数据输入,这些文本数据被转化为一个个token,每一个token对应一个ID,每一个ID映射出一个高维向量,在这个高维的向量空间里,离得越近证明相似度越高,所有的token的词嵌入被存在一个“地图”序列里,但是为了好找相应ID对应的向量,使用位置编码与该向量一一对应,这时所有输入的句子就变成了一个个高维向量的向量组,被输入Transformer架构,然后看每一个向量组中前后token的相似度,最后所有的token对于其他的token都会对应一个相似度,最后通过softmax概率函数来预测下一个词的概率,再重复更多的操作,完成预训练。最后用户输入一段文字可以进行推理,自迭代形成丰富的文本。
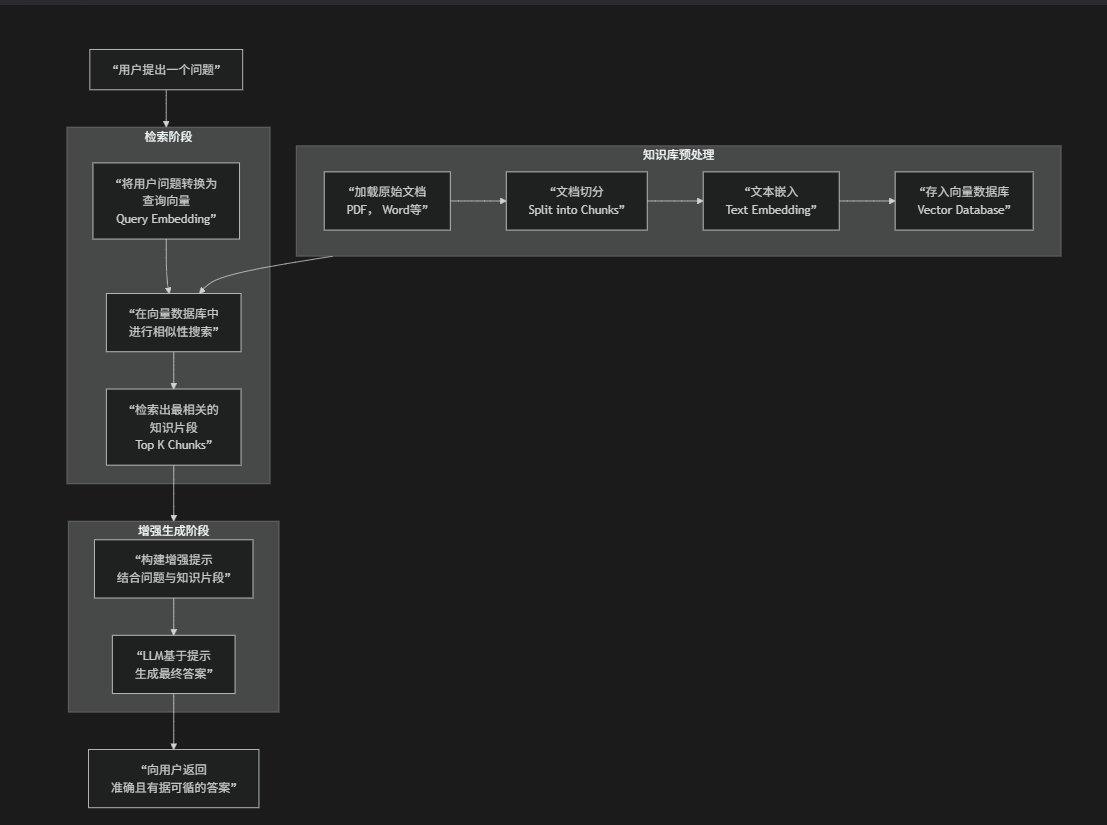
三、检索增强生成 Retrieval-Augmented Generation, RAG
传统LLM:像“闭卷考试”,模型只能依赖其训练时记忆在参数中的知识。
RAG系统:像“开卷考试”,在回答问题前,先去“参考书”(外部知识库)里查找相关资料,然后结合资料和自己的知识(LLM的能力)来组织答案。
四、向量数据库
传统数据库:像是一个按书名或作者精确查找的图书管理员。如果你问“有《三体》这本书吗?”,他可以快速告诉你。
向量数据库:像是一个能理解书籍“内容”和“思想”的超级管理员。如果你问“有没有关于‘人性在极端环境下挣扎’的小说?”,他不仅能理解这个抽象概念,还能从所有书籍中找出主题最相关的几本给你。
1. 核心概念:什么是向量?
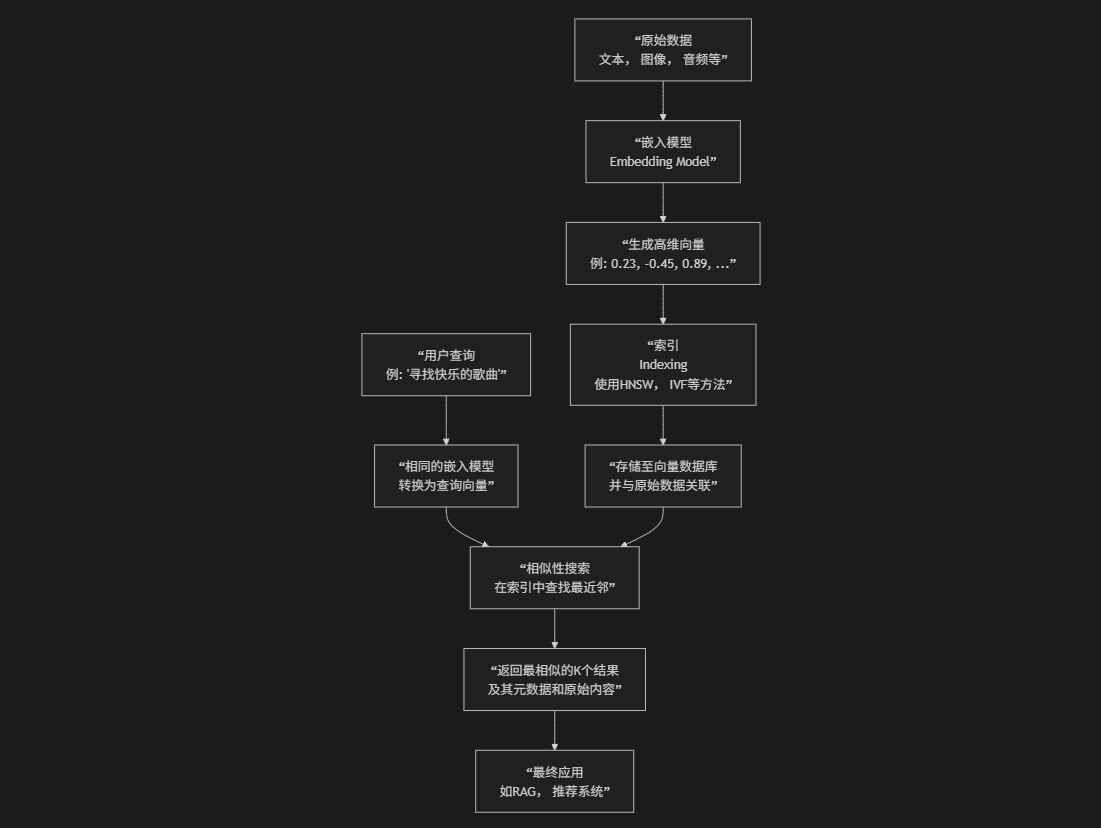
向量:简单来说,它是一个有序的数字列表,在数学和物理中代表一个具有大小和方向的量。
向量嵌入:在AI中,我们通过嵌入模型将文本、图像、音频等数据转换为高维向量(通常是几百到几千维)。这个向量就像是该数据在“语义空间”中的坐标和DNA,捕获了其深层特征。
例子:
单词“国王”可能被表示为向量
[0.9, -0.2, 0.3, ...]单词“皇后”的向量
[0.85, -0.25, 0.35, ...]会与“国王”的向量非常接近。单词“苹果”的向量
[0.1, 0.8, -0.1, ...]则会离它们较远。
2. 数据入库:从原始数据到向量
步骤描述:这是准备阶段,将需要被搜索的数据“向量化”并存入数据库。
a. 数据加载:收集原始数据,如产品描述、用户资料、文档段落、图片等。
b. 生成嵌入:使用嵌入模型(如OpenAI的
text-embedding-3)将每条数据转换为一个高维向量。c. 创建索引:这是向量数据库的核心技术。它不会进行简单的线性扫描,而是会构建一种特殊的数据结构(索引),以便在后缀进行极快速的搜索。常见的索引算法有HNSW(分层导航小世界)和IVF(倒排文件)。
d. 存储向量和元数据:将向量、索引以及对应的原始数据(或其引用)和元数据(如创建时间、作者、类别等)一起存储起来。
例子:一个音乐流媒体公司想要构建一个“歌曲推荐系统”。
他们将1000万首歌曲的“歌词”、“流派”、“音律特征”作为原始数据。
使用模型为每首歌曲生成一个384维的向量。例如:
歌曲《Happy》的向量:
[0.8, -0.1, 0.5, ...]歌曲《Don‘t Worry, Be Happy》的向量:
[0.78, -0.12, 0.48, ...]歌曲《Sad Song》的向量:
[0.1, 0.9, -0.6, ...]
系统为这1000万个向量构建HNSW索引。
将向量、歌曲ID、歌手、发行年份等元数据存入向量数据库。
3. 查询过程:相似性搜索
步骤描述:当用户发起查询时,数据库如何找到最相关的结果。
a. 查询向量化:将用户的查询输入(如搜索词、一张图片)使用同一个嵌入模型转换为一个查询向量。
b. 执行相似性搜索:向量数据库在之前构建的索引中,寻找与“查询向量”最相似的K个向量(例如,前10个)。
c. 排名与返回:根据相似度分数对结果进行排序,并返回最相关的条目。
相似度度量方法:
余弦相似度:最常用,衡量的是向量之间的角度,忽略其大小。非常适用于文本嵌入。
欧几里得距离:衡量向量之间的直线距离。距离越短,越相似。
点积:衡量向量的方向和幅度。
五、LlamaIndex 框架
1、SimpleDirectoryReader:文档加载能手
SimpleDirectoryReader 是 LlamaIndex 中一个非常实用的数据加载组件,它的主要任务就是从指定目录读取多种格式的文件。
核心功能:支持从本地目录或远程文件系统(如 S3 存储桶)加载多种格式的文件。它能自动根据文件扩展名选择相应的读取器,简化了数据准备过程。
支持的文件类型:默认支持
.txt、.pdf、.docx、.pptx、.jpg、.png等多种格式。使用示例:
python
from llama_index.core import SimpleDirectoryReader # 从本地目录加载所有支持的文件 documents = SimpleDirectoryReader(input_dir="./data").load_data() # 递归加载子目录文件[citation:4] documents = SimpleDirectoryReader(input_dir="./data", recursive=True).load_data() # 加载特定类型的文件[citation:4] documents = SimpleDirectoryReader(input_dir="./data", required_exts=[".pdf"]).load_data() # 从远程文件系统(如S3)加载文件[citation:7] # 需要预先安装 s3fs 库 from s3fs import S3FileSystem s3_fs = S3FileSystem(anon=False, endpoint_url=endpoint_url) documents = SimpleDirectoryReader(input_dir="llama-index-test-bucket", fs=s3_fs).load_data()
进阶技巧:
并行处理:加载大量文件时,使用
num_workers参数进行并行加载可以显著提升速度。python
documents = reader.load_data(num_workers=4)
自定义读取器:你可以通过
file_extractor参数为特定文件类型自定义读取逻辑。例如,强制将 Markdown 文件作为完整文档读取,避免按行分割:python
from llama_index.readers.file.flat.base import FlatReader file_extractor = {'.md': FlatReader()} reader = SimpleDirectoryReader("./data", file_extractor=file_extractor)
2、VectorStoreIndex:向量索引构建器
VectorStoreIndex 是 LlamaIndex 中用于处理文档的核心组件,它将加载的文档转换为向量索引,为后续的语义搜索和检索增强生成(RAG)打下基础。
核心功能:
VectorStoreIndex会自动完成文本分块、向量化(通过嵌入模型)和索引构建,最终形成一个可高效检索的向量索引。使用示例:
python
from llama_index.core import VectorStoreIndex # 从 SimpleDirectoryReader 加载的文档直接创建索引 index = VectorStoreIndex.from_documents(documents) # 你也可以从已有的向量存储(如 IBM Db2 Vector Store)创建索引[citation:2] # 这需要先安装并配置好相应的集成包
幕后流程:
文本分块:将文档分割成较小的文本片段(节点)。
生成嵌入向量:使用指定的嵌入模型为每个文本片段生成向量表示。
构建索引:将这些向量存储在向量数据库中(例如,内存型、Chroma、Faiss,或者像 IBM Db2 这样的企业级数据库),并建立索引以便快速进行相似性搜索。
3、QueryEngine:智能问答引擎
QueryEngine 是执行端到端问答任务的接口。你向它提问,它通过查询索引并调用LLM来返回答案。
核心功能:
QueryEngine接收自然语言查询,通过检索相关上下文信息并结合LLM生成答案。使用示例:
python
# 从创建好的索引创建查询引擎
query_engine = index.as_query_engine()
# 提出你的问题
response = query_engine.query("LlamaIndex是什么?")
print(response)工作流程:
检索:将查询转换为向量,在索引中执行相似性搜索,找到最相关的文本片段。
增强:将查询和检索到的相关文本片段组合成增强的提示。
生成:将增强后的提示发送给LLM,生成最终答案。
特定类型的查询引擎:LlamaIndex 还提供了针对特定类型数据(如结构化表格数据)的专用查询引擎,例如
PandasQueryEngine。
这是自己本地构建的项目问答助手
import os
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.core.memory import ChatMemoryBuffer
# 配置大模型 - 选择其中一种
def setup_llm():try:# 优先尝试使用 Ollama(本地,免费)from llama_index.llms.ollama import Ollamaprint("使用 Ollama 本地模型...")return Ollama(model="llama3", request_timeout=120.0)except ImportError:try:# 备选:使用 OpenAIfrom llama_index.llms.openai import OpenAIos.environ["OPENAI_API_KEY"] = "sk-qzcznawhoeflffhfrcyozgnaudbfytycpjucmwjgjjqtjcuf" # 请替换为您的API密钥print("使用 OpenAI 模型...")return OpenAI(model="gpt-3.5-turbo", temperature=0.1)except ImportError:print("请安装至少一种LLM集成包:")print("pip install llama-index-llms-ollama 或 pip install llama-index-llms-openai")exit(1)
# 配置设置
Settings.llm = setup_llm()
# 1. 加载数据
try:documents = SimpleDirectoryReader("./datas").load_data()print(f"成功加载 {len(documents)} 个文档")
except Exception as e:print(f"文档加载失败: {e}")exit(1)
# 2. 构建索引
print("正在构建索引...")
index = VectorStoreIndex.from_documents(documents)
# 3. 创建查询引擎
query_engine = index.as_query_engine()
# 交互式问答
print("\n=== 项目助手已就绪 ===")
print("输入 '退出' 结束对话\n")
while True:question = input("请输入您的问题: ").strip()
if question.lower() in ['退出', 'quit', 'exit']:break
if not question:continue
try:response = query_engine.query(question)print(f"\n助手: {response}\n")except Exception as e:print(f"出错: {e}")