PPIO上线DeepSeek-OCR模型
刚刚,PPIO 上线 DeepSeeek 最新发布的 DeepSeek-OCR 模型,这是一个专为高效视觉-文本压缩概念验证而设计的视觉文本模型。
现在,你可以到 PPIO 官网在线体验 DeepSeek-OCR,或将模型 API 接入 Cherry Studio 等第三方 AI 应用或你自己的 AI 工作流中。
在线体验地址:
https://ppio.com/llm/deepseek-deepseek-ocr
开发者文档:
https://ppio.com/docs/model/llm
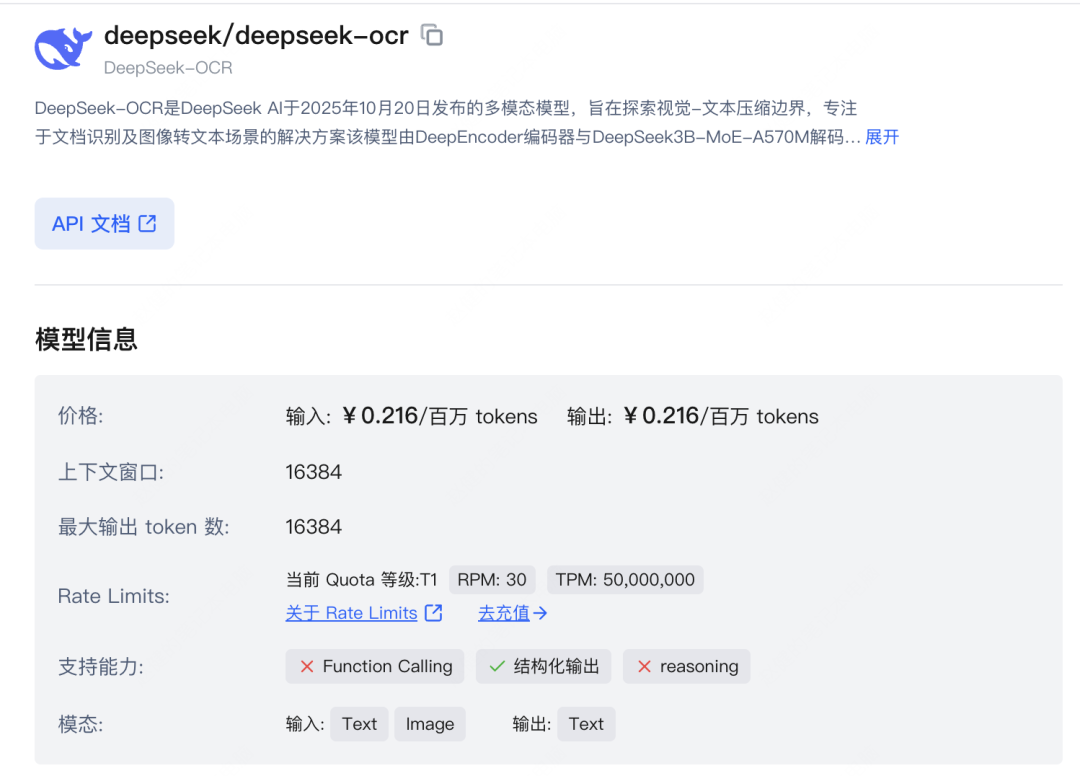
模型基础信息:
模型创新点
DeepSeek-OCR 模型的创新点是什么?
当前大语言模型(LLM)在处理长文本内容时面临显著的计算挑战——计算量随序列长度呈二次方增长。
DeepSeek 探索了一种潜在解决方案:利用视觉模态作为文本信息的高效压缩媒介。
一张包含文档文本的图像可以用远少于等效数字文本的 token 数表示丰富信息,这表明通过视觉 token 进行“光学压缩”有望实现更高的压缩率。
DeepSeek 从“以 LLM 为中心”的视角重新审视视觉-语言模型(VLM),关注视觉编码器如何提升 LLM 处理文本信息的效率,而非仅关注人类擅长的传统 VQA 任务。
OCR 任务作为连接视觉与语言的中间模态,为这种“视觉-文本压缩”范式提供了理想试验场:它在视觉与文本表示之间建立了天然的压缩-解压缩映射,并可提供量化评估指标。
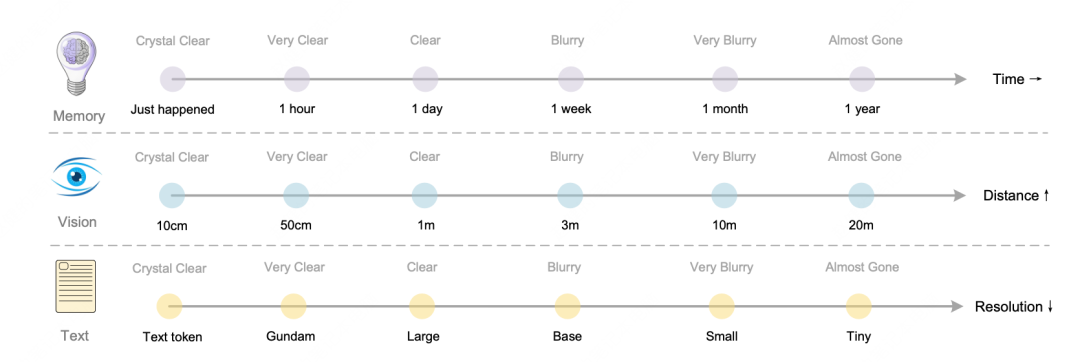
遗忘机制是人类记忆最基本的特点之一。
“上下文光学压缩”方法可以模拟这一机制:先把前几轮历史文本渲染成图像,完成初步压缩;随后对更久远的图像逐级缩小分辨率,实现多层压缩——token 数量逐步减少,文字也愈发模糊,从而完成“文本遗忘”。
DeepSeek-OCR 就是一个专为高效视觉-文本压缩概念验证而设计的 VLM。
DeepSeek-OCR 由两个组件构成:DeepEncoder 和解码器 DeepSeek3B-MoE-A570M。
DeepEncoder 作为核心引擎,在高分辨率输入下保持低激活,同时实现高压缩率,确保视觉 token 数量可控。
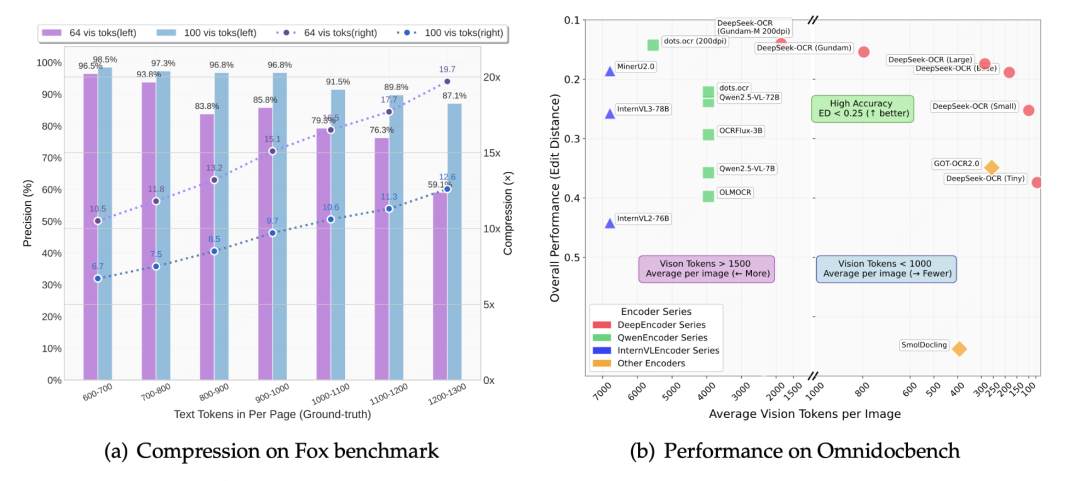
实验表明,当文本 token 数量不超过视觉 token 10 倍(即压缩率 < 10×)时,模型可实现 97% 的 OCR 解码精度;即使在 20× 压缩率下,OCR 精度仍保持在约 60%。
这为历史长上下文压缩和 LLM 记忆遗忘机制等研究方向带来广阔前景。
此外,DeepSeek-OCR 具备极高实用价值:
在 OmniDocBench 上,它仅用 100 个视觉 token 就超过 GOT-OCR2.0(256 tokens/页),并以不足 800 个视觉 token 的表现优于 MinerU2.0(平均每页 6000+ tokens)。
在生产环境中,单张 A100-40G 每天可为 LLM/VLM 生成 20 万页以上训练数据。
一些官方示例:



总结来说,DeepSeek-OCR 模型首次定量验证 “视觉 token 可替代文本 token” 的上下文光学压缩潜力,为 LLM 长上下文、记忆遗忘机制、多模态高效训练提供了新思路,同时其本身已是工业级高精度 OCR 数据生成器,具备大规模预训练数据生产能力。
当然,仅靠 OCR 任务尚不足以全面验证真正的“上下文光学压缩”效果。接下来,DeepSeek 表示还将开展“数字-光学文本交错预训练”、“大海捞针”测试等更深入的实验与评估。
如何体验DeepSeek-OCR?
DeepSeek-OCR 是一个架构比较特殊的模型,因此在 PPIO 目前只适用于识别图片以及预设提示词。
-
“<|grounding|>Convert the document to markdown”是指把文档转换成标准 Markdown 文本。
-
“<|grounding|>OCR this image”是指将文档识别成可编辑文本。
-
“Free OCR”是指把图里所有文字按行/块顺序吐出来,不保留表格、标题层级等格式。
-
“Parse the figure”是针对文档中出现的图表或图片进行分析。
-
“Describe this image in detail”要求模型详细描述图像内容,包括视觉元素、场景、关系、情感、构图等。
-
“Locate <|ref|>xxxx<|/ref|> in the image”指执行一个图像中的目标定位任务。
比如,上传 Qwen3-Next 的封面图并让其识别文字:

上传一张 1024 MBTI “代码人格”图片,让其描述图像内容:

DeepSeek-OCR 目前只能回复英文,其翻译如下:
左上角:
- PPIO 的 Logo,由两个圆点组成,看起来像一双眼睛。
画面上方两侧:
- 右侧:一个蓝色的云朵状小人,抬手朝向观众的脸部方向。
- 最右边缘:三列垂直排列的彩色小圆点,颜色包括黑色、红色、黄色、浅蓝色、深紫色、橙色、粉色、灰色、青绿色、棕黄色、白色等,可能因分辨率限制还有其他颜色难以辨认。
中央角色下方:
- 一组中文文字,大致可译为:
“我们用代码写下欢乐的笑声;我们不仅仅是在编程。”
其下方进一步说明编程内容:
- “在代码中,我们使用数字。”
- “编码的过程离不开数字。”
画面底部中心:
- 再次出现中文文字:
“在代码中。”
“我们使用数字。”
“编码的过程涉及数字。”
整体布局表明,这是一个以数字序列进行编码练习的协作项目,氛围轻松愉快,中央角色周围的设计元素充满童趣。这可能是一种面向儿童编程启蒙的教育内容,通过视觉化的方式讲解计算机科学基础概念。
除了在 PPIO 官网进行体验,你也可以将 Model API 接入第三方应用或自己的AI工作流进行体验。开发者文档:https://ppio.com/docs/model/llm
关于PPIO
PPIO 是中国领先的独立分布式云计算服务商,由 PPTV 创始人、前蓝驰创投投资合伙人姚欣和前 PPTV 首席架构师王闻宇于2018年联合创立,致力于为人工智能、智能体、实时音视频处理、具身智能等新一代场景,提供极致⾼性价⽐、超弹性、低延迟的⼀站式智算、模型及边缘计算服务。
根据 CIC (China lnsights Consultancy) 的资料,按2024年收入计,PPIO 是中国最大的独立边缘云公司,运营着中国最大的算力网络。按日均 tokens 消耗量计,在中国独立 AI 云公司中位列前二名。
PPIO 新用户点击阅读原文填写邀请码【24CGOJ】注册并认证可得 15 元代金券,企业用户认证可得 200 元代金券。
如果你有大模型 API、Sandbox、GPU 云等专属需求,可扫码联系我们👇。
