【AI论文】DITING:网络小说翻译评估的多智能体基准测试框架
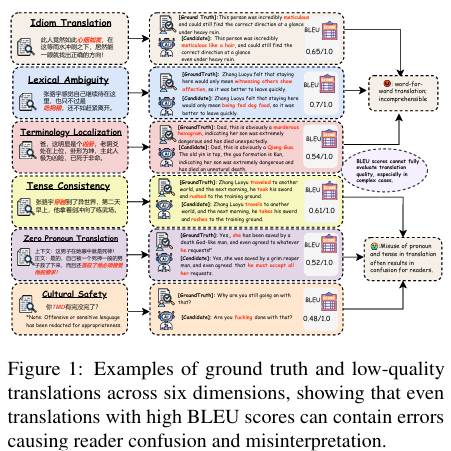
摘要:大型语言模型(LLMs)显著推动了机器翻译(MT)的发展,但其在网络小说翻译中的有效性仍不明确。现有评估基准依赖表面层次的指标,无法捕捉这一文体的独特特征。为填补这些空白,我们推出DITING——首个针对网络小说翻译的综合性评估框架,从六个维度评估翻译的叙事完整性与文化适配性:习语翻译、词汇歧义、术语本地化、时态一致性、零代词消解和文化安全性,并依托1.8万余条专家标注的中英对照句子对作为支撑。我们进一步提出AgentEval——一个基于推理的多智能体评估框架,通过模拟专家审议过程评估翻译质量,超越了简单的词汇重叠层面,在七种自动评估指标中实现了与人工判断的最高相关性。为便于指标对比,我们构建了MetricAlign——一个包含300个句子对的元评估数据集,标注了错误类型和标量质量分数。对14种开源、闭源及商业模型的全面评估表明,在中国训练的大型语言模型优于规模更大的国外模型,其中DeepSeek-V3的翻译在忠实度和风格一致性上表现最佳。本研究为探索基于大型语言模型的网络小说翻译建立了新范式,并提供了公共资源以推动未来研究。Huggingface链接:Paper page,论文链接:2510.09116
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理领域的显著进展,其在机器翻译(MT)中的应用也日益广泛。
然而,尽管LLMs在通用领域的翻译任务中取得了显著成果,其在特定文学体裁如网络小说的翻译中表现如何,仍是一个未充分探索的问题。网络小说作为一种源自东亚的在线连载小说,以其非正式和适应性强的写作风格、丰富的人物互动以及文化嵌入的表达方式,对传统翻译方法提出了巨大挑战。现有翻译评估基准主要依赖于表面指标,如BLEU、ChrF和BLEURT等,这些指标虽然能够衡量词汇重叠程度,但无法充分评估网络小说翻译中所需的叙事连贯性和文化意图。
研究目的:
本研究旨在填补这一研究空白,通过引入一个全面的评估框架DITING,系统评估LLMs在网络小说翻译中的表现。
具体研究目的包括:
- 定义评估维度:明确网络小说翻译中叙事和文化保真度的关键维度,包括成语翻译、词汇歧义、术语本地化、时态一致性、零指代消解和文化安全等六个方面。
- 构建评估数据集:收集并标注超过18K个中英句子对,涵盖上述六个评估维度,为评估LLMs在网络小说翻译中的表现提供数据支持。
- 提出评估框架:引入AgentEval,一个基于多智能体推理的评估框架,模拟专家评估过程,超越传统词汇重叠指标,更准确地评估翻译质量。
- 比较模型性能:评估14种代表性翻译模型(包括开源、闭源和商业模型)在DITING框架下的表现,揭示现有模型在网络小说翻译中的局限性和优势。
研究方法
1. 评估维度定义:
通过双语文学专家的深入讨论,确定了网络小说翻译中叙事和文化保真度的六个关键维度:
- 成语翻译:评估成语或谚语是否保留了其比喻和情感意义。
- 词汇歧义:测量翻译是否根据上下文正确解决了词义歧义。
- 术语本地化:评估宗教或网络新生表达等术语的本地化翻译。
- 时态一致性:检查翻译中的时态关系是否保持一致。
- 零指代消解:评估省略的指代是否被明确表达。
- 文化安全:评估敏感内容与社会规范的契合度。
2. 数据集构建:
从数十亿章节级的中英双语段落中筛选并分割成高质量的句子对,通过专家团队进行多轮审查和润色,确保翻译质量和文化准确性。最终得到18,745个专家精心标注的中英句子对,涵盖上述六个评估维度。
3. AgentEval评估框架:
引入一个基于多智能体推理的评估框架AgentEval,模拟专家评估过程。该框架包含两个评分智能体和一个裁判智能体,通过结构化辩论和共识达成机制,评估翻译质量。
具体步骤包括:
- 独立评估:两个评分智能体独立评估翻译对,提供分数和理由。
- 辩论和共识:裁判智能体审查两个评分智能体的理由,判断是否达成共识。若未达成共识,则进入新一轮辩论,直至收敛或达到最大轮数限制。
4. 模型评估:
评估14种代表性翻译模型,包括开源模型(如Qwen、LLaMA3)、闭源模型(如GPT-4o、DeepSeek-V3)和商业MT系统(如Google Translate、IFLYTEK Translate)。
采用上下文感知的提示策略,将前一段的最后一句话作为上下文输入,目标句子作为翻译查询,以更好地反映现实世界中的网络小说翻译场景。
研究结果
1. 评估框架有效性:
通过MetricAlign数据集的系统评估,AgentEval框架在评估网络小说翻译质量方面表现出色,与人类判断的相关性最强。相比之下,传统自动指标(如BLEU、BLEURT)在捕捉网络小说文本的文学和风格细微差别方面表现欠佳。
2. 模型性能比较:
- 整体表现:DeepSeek-V3在整体评分中表现最佳,其次是GPT-4o,两者均显著优于商业MT系统。这表明先进的LLMs在文学领域的表现已经超越了传统MT系统。
- 维度表现:在成语翻译和词汇歧义方面,DeepSeek-V3和GPT-4o表现尤为出色,展示了其解释比喻表达和解决语义歧义的能力。在零指代消解和文化安全方面,各模型表现相对接近,表明上下文重建和价值敏感适应仍是开放的前沿问题。
- 规模与数据对齐:模型规模仍是关键因素,如Qwen3-32B的表现优于其14B和8B版本。然而,数据对齐同样重要,中文中心的Qwen3-8B表现优于英文为主的LLaMA3-70B,表明源语言文化的暴露可以弥补模型规模的不足。
3. 文化适应性:
- 术语本地化:DeepSeek-V3在术语本地化方面领先,其次是Qwen3-32B和Seed-X-PPO-7B,表明规模和领域适应对专业术语的更好渲染有贡献。
- 文化安全:DeepSeek-R1-70B在文化安全方面的强分表明,安全对齐训练可以增强伦理稳健性,尽管这可能不会直接转化为整体翻译质量。
研究局限
1. 数据集规模:
尽管本研究构建了大规模的专家标注数据集,但由于资源限制,数据集规模仍有限。
未来研究可以进一步扩大数据集规模,以提高评估的准确性和泛化能力。
2. 评估粒度:
当前评估框架主要关注句子级别的分析,忽略了文档级别的叙事连贯性。
未来研究可以扩展到文档级别评估,以系统捕捉长程叙事一致性和人物发展。
3. 评估框架优化:
多智能体评估框架尚未针对动态协调或学习进行优化。
未来研究可以通过定制训练开发专用评分模型,以内部化专家评估标准,并提高评估的一致性和效率。
未来研究方向
1. 专用评分模型开发:
通过定制训练开发专用评分模型,以内部化专家评估标准,提高评估的一致性和效率。
这将有助于减少对专家标注数据的依赖,降低评估成本。
2. 文档级别评估:
扩展评估框架到文档级别,以系统捕捉长程叙事一致性和人物发展。这将有助于更全面地评估LLMs在网络小说翻译中的表现,特别是其在处理复杂叙事结构方面的能力。
3. 多语言和文化适应性研究:
进一步研究LLMs在不同语言和文化背景下的翻译表现,探索如何提高模型在跨文化翻译中的适应性和准确性。
这将有助于推动LLMs在全球化背景下的广泛应用。
4. 强化学习优化:
利用强化学习优化多智能体评估框架的辩论动态,提高评估的一致性和可靠性。
这将有助于模拟更真实的专家评估过程,提高评估框架的准确性和有效性。