大模型微调完整步骤( LLama-Factory)
一、LLaMA-Factory 安装部署
在安装之前,首先需要有一个linux服务器,并在这个服务器上完成搭建,否则在后续配置和安装时可能会出现非常多的兼容性问题。如果本地是windows机器,推荐使用windows自带的hyper-v虚拟化出来一个linux环境。
LLaMA-Factory 的 Github地址:https://github.com/hiyouga/LLaMA-Factory
- 克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git- 切换到项⽬⽬录
cd LLaMA-Factory- 修改配置,将 conda 虚拟环境安装到数据盘(这⼀步也可不做)
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/conda/envs
conda config --add envs_dirs /root/autodl-tmp/conda/envs- 创建 conda 虚拟环境(⼀定要 3.10 的 python 版本,不然和 LLaMA-Factory 不兼容)
conda create -n llama-factory python=3.10- 激活虚拟环境
conda activate llama-factory- 在虚拟环境中安装 LLaMA Factory 相关依赖,注意:如报错 bash: pip: command not found ,先执⾏ conda install pip 即可
pip install -e ".[torch,metrics]"- 检验是否安装成功
llamafactory-cli version二、启动 LLama-Factory 的可视化微调界⾯ (由 Gradio 驱动)
直接运行下面的命令:
llamafactory-cli webui2.1配置端口转发
如果使用了虚拟机、Docker或者购买云服务器,还需要配置端⼝转发,其中云服务器还需要开通防火墙端口。
在本地电脑的终端(cmd / powershell / terminal等)中执⾏代理命令,其中
root@123.125.240.150 和 42151 分别是实例中SSH指令的访问地址与端⼝,请找到⾃⼰实
例的ssh指令做相应替换。 7860:127.0.0.1:7860 是指代理实例内 7860 端⼝到本地的 7860
端⼝
ssh -CNg -L 7860:127.0.0.1:7860 root@123.125.240.150 -p 421512.2从 HuggingFace 上下载基座模型
HuggingFace 是⼀个集中管理和共享预训练模型的平台 https://huggingface.co;
- 创建⽂件夹统⼀存放所有基座模型
mkdir Hugging-Face- 修改 HuggingFace 的镜像源
export HF_ENDPOINT=https://hf-mirror.com- 修改模型下载的默认位置
export HF_HOME=/root/autodl-tmp/Hugging-Face- 注意:这种配置⽅式只在当前 shell 会话中有效,如果你希望这个环境变量在每次启动终端时都⽣效,可以将其添加到你的⽤户配置⽂件中(修改 ~/.bashrc 或 ~/.zshrc )
- 检查环境变量是否⽣效
echo $HF_ENDPOINT
echo $HF_HOME- 安装 HuggingFace 官⽅下载⼯具
pip install -U huggingface_hub- 执⾏下载命令
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-DistillQwen-1.5B- 如果直接本机下载了模型压缩包,如何放到你的服务器上?——在 AutoDL 上打开JupyterLab 直接上传,或者下载软件通过 SFTP 协议传送
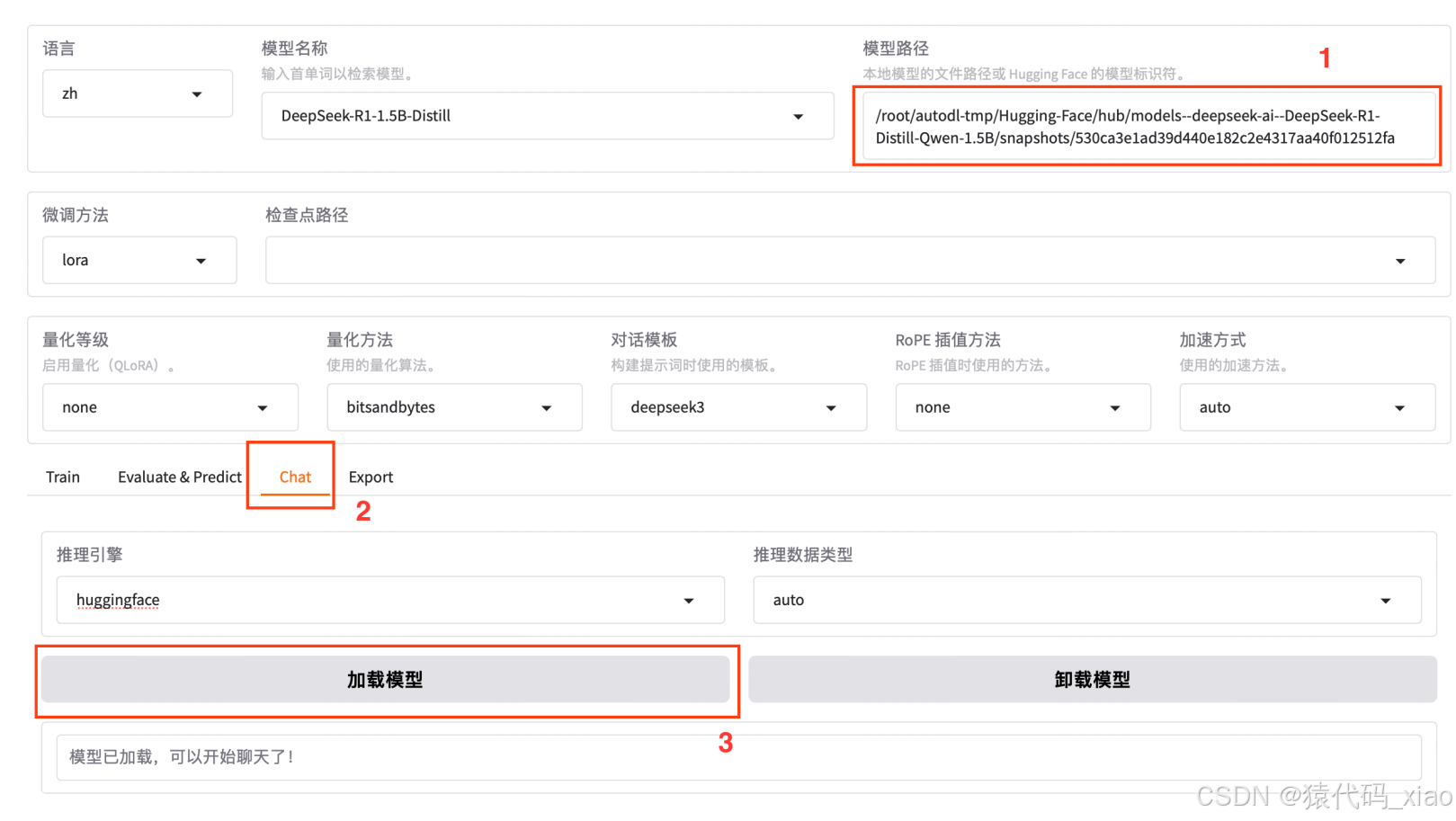
三、可视化⻚⾯上加载模型测试,检验是否加载成功
注意:这⾥的路径是模型⽂件夹内部的模型特定快照的唯⼀哈希值,⽽不是整个模型⽂件夹