自由学习记录(111)
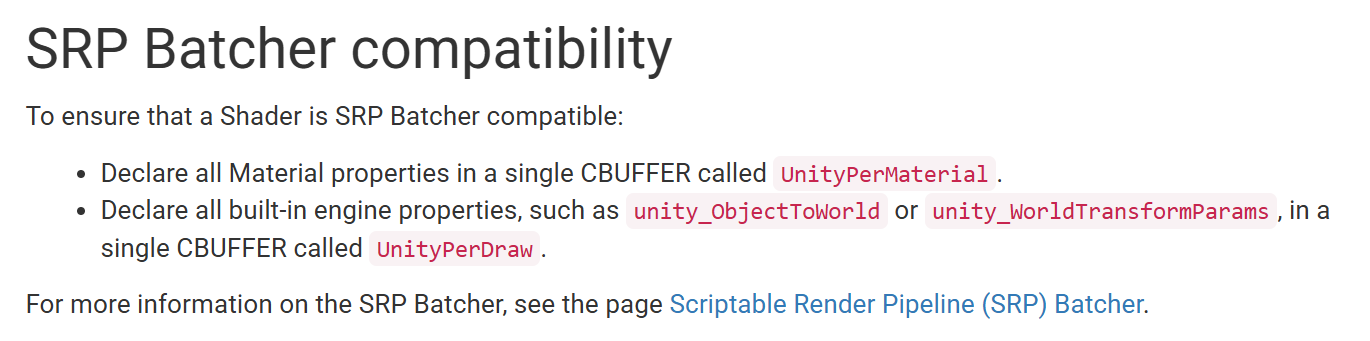
它们不是“函数”,也不是普通的“变量”——是用于 Unity 的 Scriptable Render Pipeline(SRP)中 Shader 常量缓冲区(CBUFFER) 的命名约定。
-
“UnityPerDraw” 是用来存放“每 Draw 调用”必须上传给 GPU 的内置引擎属性(如物体变换矩阵等) 。 Unity Manual+2Keyle's knowledge repository | 宝藏工坊+2
-
“UnityPerMaterial” 是用来存放“每 材质 (Material)”的属性(如漫反射颜色、贴图 _ST 参数等) 。 Unity Manual+2Unity User Manual+2
UnityPerDraw is a constant buffer in Unity's Scriptable Render Pipeline (SRP) Batcher that holds all built-in engine properties, such as unity_ObjectToWorld. For a shader to be compatible with the SRP Batcher and allow it to draw multiple objects in a single pass, it must declare these engine-specific properties within a single UnityPerDraw buffer.
-
Purpose:
The
UnityPerDrawbuffer is crucial for performance optimization. It allows Unity to batch (combine) draw calls for multiple objects, especially those sharing the same material, thereby reducing the overhead of sending data to the GPU for each object. -
Content:
It contains engine-level data that changes for each object being drawn, including transformations like the object-to-world matrix and other shader-related variables.
-
Compatibility:
For a custom shader to be SRP Batcher compatible, it must define this
UnityPerDrawconstant buffer and place all the necessary built-in engine properties inside it. -
Related Buffer:
UnityPerDrawworks in conjunction with another constant buffer calledUnityPerMaterial, which holds all the material-specific properties, like colors and textures.
https://docs.unity3d.com/Packages/com.unity.render-pipelines.universal@10.2/manual/shaders-in-universalrp.html#:~:text=SRP%20Batcher%20compatibility,a%20single%20CBUFFER%20called%20UnityPerDraw%20.
如何在Unity中快速搭建一个3A级别的场景 - 技术专栏 - Unity官方开发者社区
为什么用 “generic” 这个词
-
因为该缓冲区并非给某个特殊材质、某个特殊场景单独定制,而是 “所有符合条件的材质共用的结构” —— 所以称为“通用/generic”。
-
这样做能让 SRP Batcher 将多个材质对象用同一 Shader 的数据上传路径合并,从而减少 CPU 开销、减少状态切换。 Unity+1
-
例如文档中:“All built-in engine properties must be declared in a single CBUFFER named ‘UnityPerDraw’. … All Material properties in a single CBUFFER named ‘UnityPerMaterial’. ” Unity Manual+1
这些 CBUFFER 名称体现出“通用结构”:所有对象共用 “UnityPerDraw”,所有材质共用 “UnityPerMaterial”。
-
如果你自己编写或修改 Shader 并希望兼容 SRP Batcher,你必须确保:所有材质属性放在同一个 CBUFFER(如 UnityPerMaterial),并保证不同材质变体该 CBUFFER 的大小/布局一致。 Unity Forum+1
-
否则就会破坏批处理机制,使得绘制流程回退为较慢路径。
-
所以这里的 “generic” 并不意味着 “简陋” 或 “基础”,而是强调 “标准化+可批处理” 的含义。
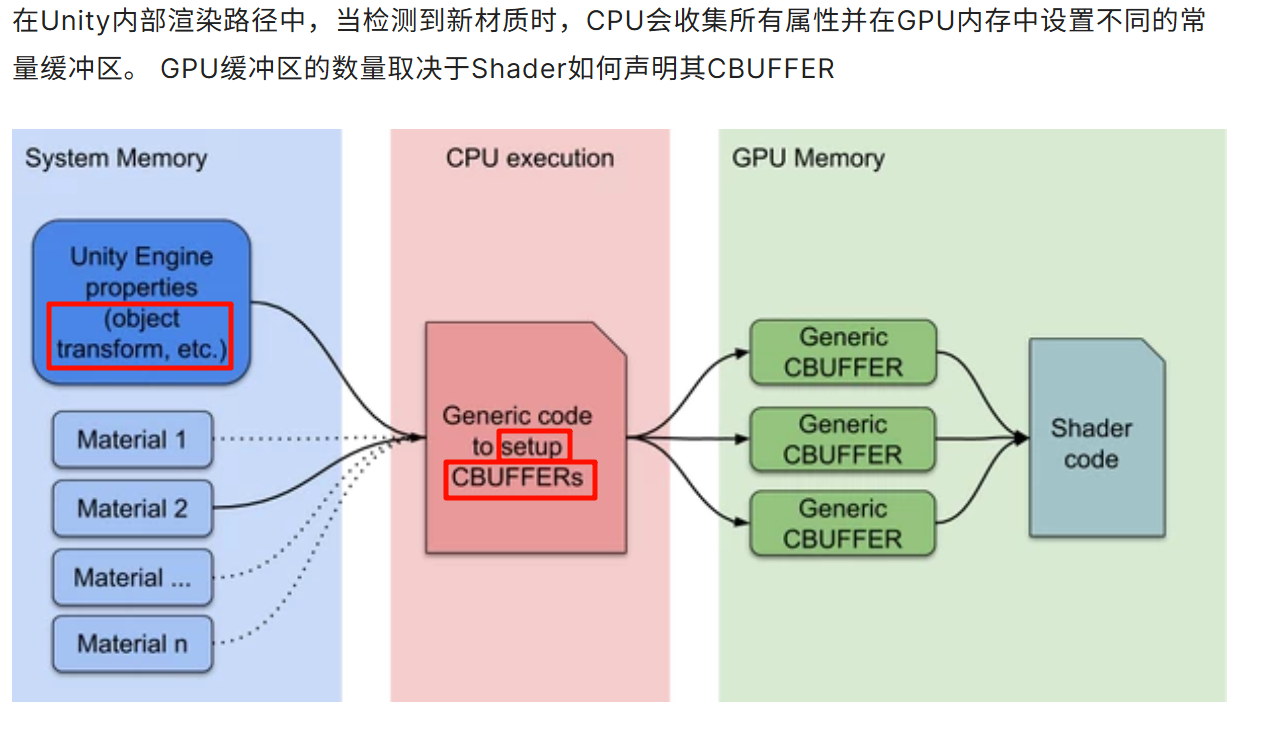
SRP Batcher 流程中,当检测到一个使用某 Shader 的材质(Material)时,CPU 会收集该材质、对象的属性,并将这些属性设置到 GPU 内存中的常量缓冲区 (CBUFFER) 中。 Unity Manual+1
文档指出:
“During the inner render loop, when Unity detects a new Material, the CPU collects all properties and sets up different constant buffers in GPU memory. The number of GPU buffers depends on how the Shader declares its CBUFFERs.” Unity Manual
因此,“generic CBUFFER”一词用来指 “这些被批处理机制(batcher)统一管理的常量缓冲区”——即不是手写专用给一个材质写一个独立的缓冲区,而是靠 shader 中 CBUFFER 定义,被 Unity 批处理系统通用使用。

天才,so high the devil’s taking notes
飞船内饰搭建(一)——SRP Batcher篇 - 技术专栏 - Unity官方开发者社区
“generic CBUFFER” 这里的 “generic” 并不是一个特定的技术术语,而是用来表示“通用的/一般的” 常量缓冲区(constant buffer)——也就是指那些并非专为某一特定材质或对象而写,而是由 Unity 在渲染流程中统一收集并上传的一类缓冲区。
使用SRP技术,我们需要关心并写一些引擎底层代码。我们能原生地集成一些新的范式 - 比如GPU的数据管理(生命权);目标是由大量不同材质、但Shader变体较少的场景下,提升渲染性能。
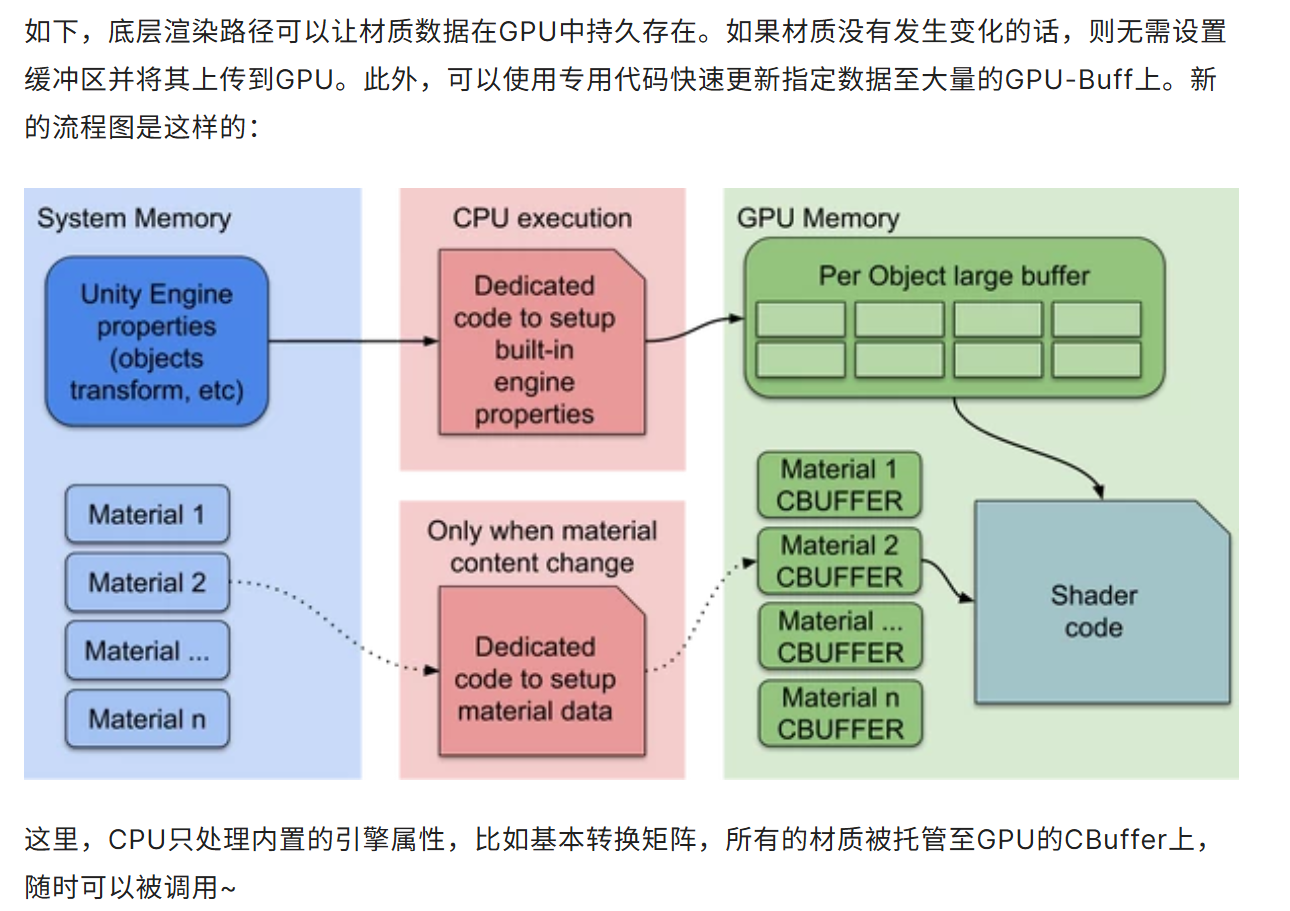
CPU只处理内置的引擎属性,比如基本转换矩阵,所有的材质被托管至GPU的CBuffer上,随时可以被调用~
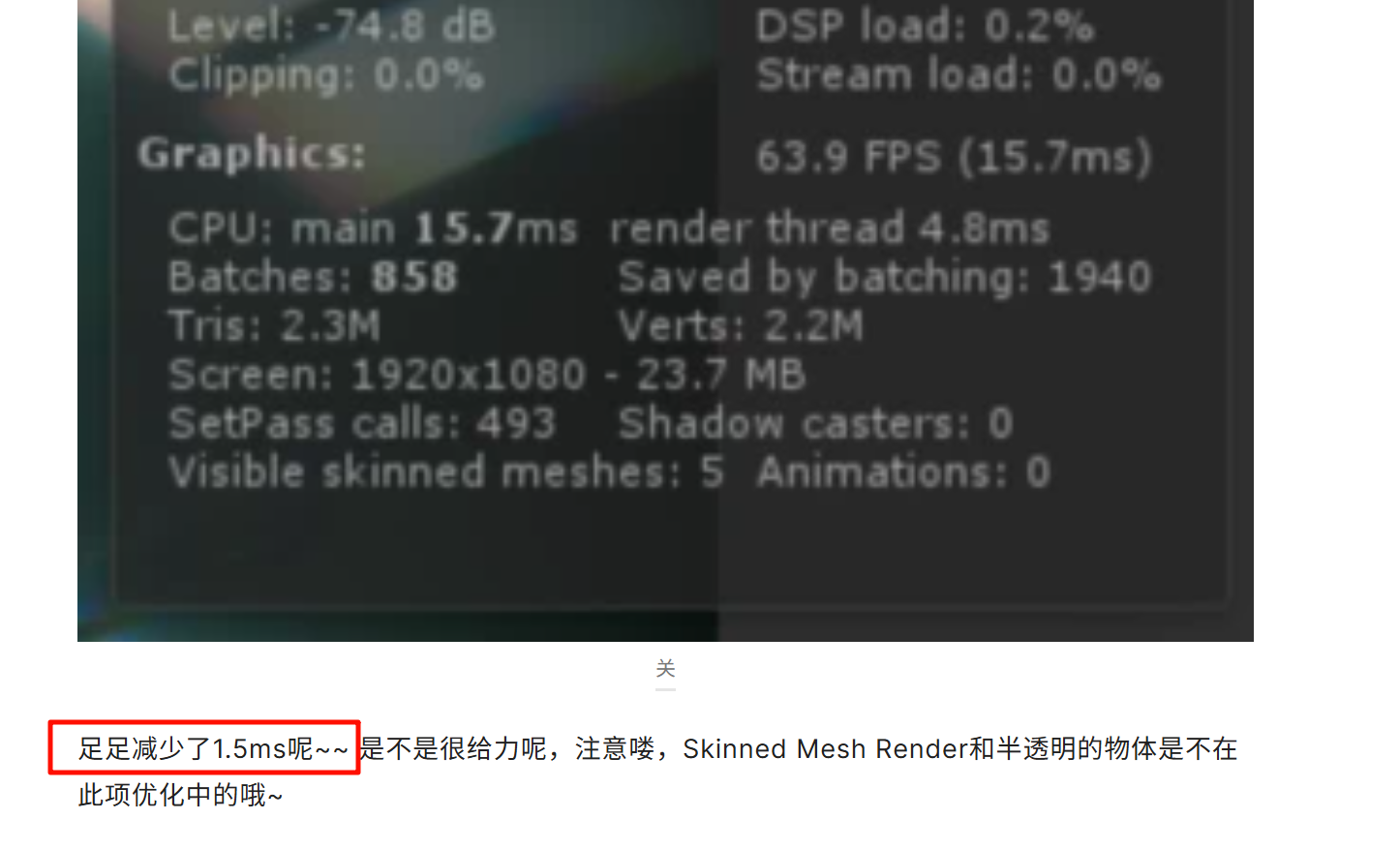
天,惊人1.5ms,
【樱花兔】黑丝小姐姐本人献上Unity 3D游戏场景,画质也太强了吧!_哔哩哔哩_bilibili
看到了世界的荒谬。nothing to say,no right to criticize those who share on the Internet,really learn about that

若你的材质工作流基于 Mixer + Megascans + Unity:建议 尽快将核心资源(贴图、材质包)备份到本地,以防未来 Bridge 服务被停用或迁移。
在使用 Fab 获取新资源时,检查资源的导出格式是否适合 Mixer + Unity(例如贴图通道命名、单位、材质设置、引擎兼容性)。
考虑将材质制作流程从过度依赖 Mixer 转向更为主动/可控的工具(如 Substance Designer/Shader Graph +手工贴图处理)以降低依赖风险。
对于 Unity,确认你的贴图集(Albedo, Metallic-Roughness, Normal 等)是否按照 Unity 的标准打包,避免资源格式变化导致贴图错误。
在 Bridge/Quixel 原库中获取的 Megascans 资源:如果你已下载使用,仍可在原许可下继续。Epic Developer Community Forums+1
然而,迁移至 Fab 后的新资源或旧资源的更新版本,并不保证与你在 Mixer 中的流程能够无缝工作。例如,文档明确指出:
“At the moment, Fab does not offer one-click export functionality or DCC integrations the way that Quixel Bridge does.” Epic Developer Community Forums
也就是说:虽然 Fab 支持 Unity、Blender 等导出格式,但对于 Mixer 的深度集成(如 Bridge 中“直接一键导入 Mixer”流程)可能受限。
资源格式、贴图通道、材质打包方式可能变化,需你在导入/使用时做额外检查或调整。
Quixel Mixer官方说明:Mixer 将保持对个人和团队 “免费使用” 的许可。support.fab.com+1
但官方也声明:Mixer 未来版本不会有额外功能更新或改进,即它将作为“最终版本”维持。Epic Developer Community Forums+1
同时,资源库从 Quixel Bridge/Megascans 正在迁移到 Fab(由 Epic Games 推出的统一资源平台)中。Quixel+2Epic Games Developers+2
“Megascans 意思是上传自己拍摄的照片给 Mixer,然后 Mixer 会给出可用的直接的材质?”
部分正确但需要澄清:Megascans 是一个扫描资源库(高分辨率真实世界扫描贴图 +模型)由 Quixel 提供。你可以在 Mixer 中使用 Megascans 贴图/资产作为基础。Mixer 本身也允许导入你自己的“Custom Surface”或“Custom Model”作为起点。 docs.quixel.com+1
但不是 “上传自己拍的照片” 就自动生成材质” 的黑箱流程。你仍需要在 Mixer 内做混合、层次控制、遮罩、绘制、设置等。扫描贴图本身也可能来源于专业扫描流程,而不是仅拍照直接用。
“材质以 FBX 的形式存在,对吗?”
不对。材质一般不是以 FBX 文件形式存在。FBX 文件是 3D 模型格式。Mixer 导出时更多的是贴图图集(Texture Maps:如 Albedo, Roughness, Normal, Metalness 等)以及可选 “模型导出” 但其重点在贴图。 docs.quixel.com+1
材质会在目标引擎/DCC (如 Unity/Unreal/Blender) 中与模型以及材质系统一起使用。你在 Mixer 导出的贴图然后配合在 Unity 中用 Shader 或材质球去使用。
Substance Designer 是一个程序化材质创作工具:你可以构建节点网络,从无到有生成纹理(tiling 材质、参数化材质、复杂效果等)。
它更适合需要高度可控、可修改、可定制的材质库建设/材质变体控制。
因此从功能上:Designer 的“自定义深度”比 Mixer 高,而 Mixer 的“操作便利”+“基于扫描贴图”优势更明显。
Mixer 是一个贴图/材质制作工具,主要用于将扫描材质 (如 Megascans 的贴图) 或你自定义导入的表面进行混合、遮罩、绘制,生成 PBR 纹理贴图(如 Albedo/Roughness/Metalness/Normal 等)然后导出。 docs.quixel.com+2docs.quixel.com+2
它支持导入你自己的模型(“Custom model”)或扫描资产,然后在 Mixer 内部进行材质/表面层混合与绘制。 docs.quixel.com+1
导出时你主要得到的是 贴图/纹理集合,以及在某情况下可导出模型(但模型导出的并非其核心功能). docs.quixel.com+1
它不太像一个“生成程序化材质节点系统”那样你从零开始设计流程(相比于某些工具),而更多是 “基于已有贴图/扫描材质 +混合” 这种工作流。 GarageFarm
https://www.reddit.com/r/unrealengine/comments/1l0zsdd/whats_the_deal_with_quixel_mixer/
https://www.fab.com/listings/0c9be59a-edd3-4428-b8d7-c21f7b7232fa
1. In Unity, go to: Assets, Import Package, Custom Package
2. Navigate to /Megascans Library/Support/Plugins/Unity/Version/ and open the file called "Megascans_Importer.unitypackage"
樱花兔正在创作我会在这里分享一些我自己制作的案例哦~ | 爱发电
生成流程(高层次)
-
模型构建/雕刻完成后——有一组多边形网格。
-
在 3D 软件里对模型标记“缝” (seams) 或决定如何“切开”模型拓扑,使其可以展开。 GarageFarm+1
-
“展开”(Unwrap):将切开的网格“铺平”成二维的 UV 岛 (UV islands),每个岛对应模型的一部分。 learn.foundry.com+1
-
在 UV 编辑器里整理这些 UV 岛:调整比例、旋转、打包(packing)到贴图空间里,避免拉伸、重叠。 GarageFarm+1
-
将 2D 贴图(漫反射贴图、法线贴图、金属粗糙度贴图等)与 UV 坐标关联,这样渲染引擎知道贴图上每个像素该映射到模型哪个点。 MYND Scan to BIM
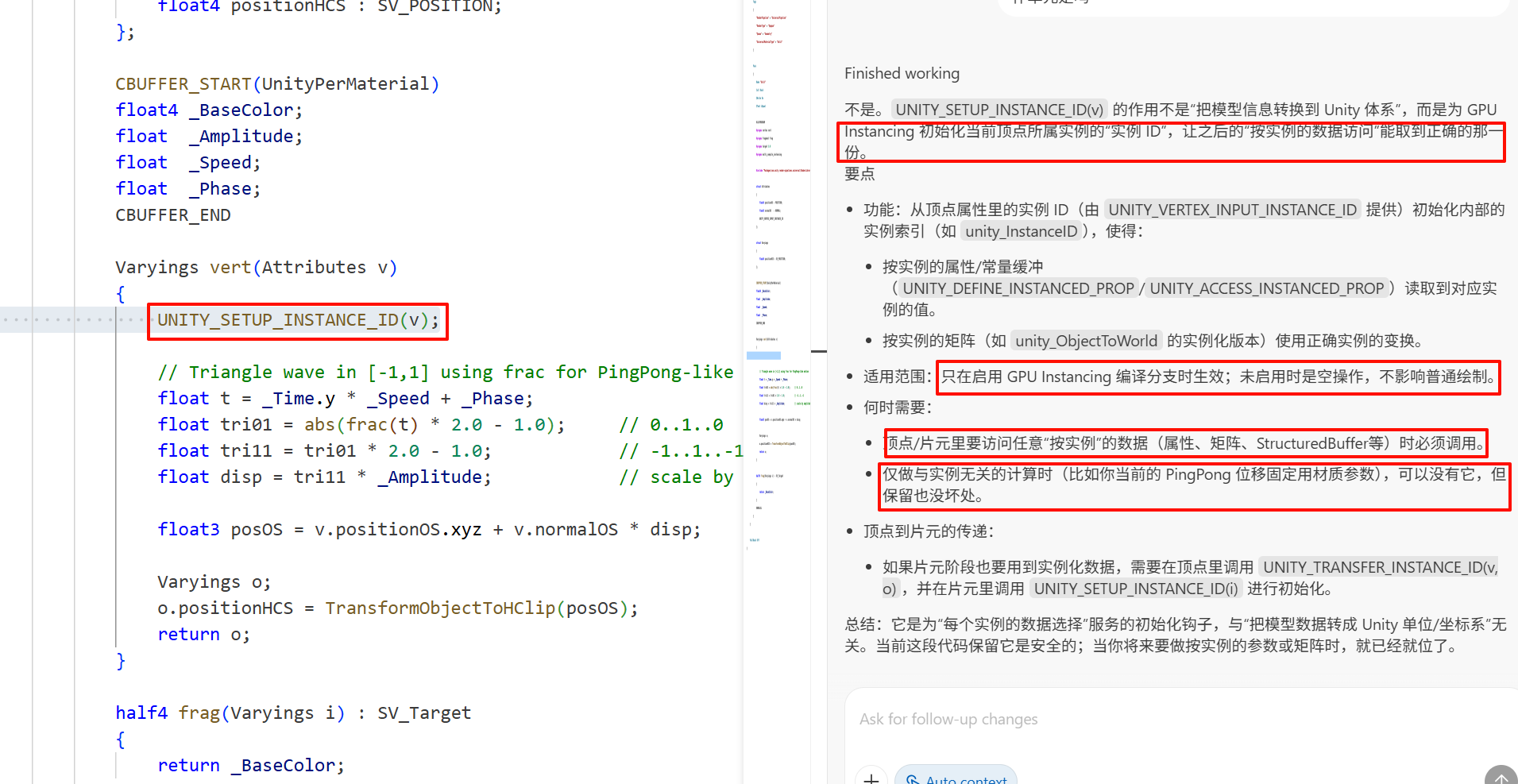
struct Attributes{float4 positionOS : POSITION;float3 normalOS : NORMAL;UNITY_VERTEX_INPUT_INSTANCE_ID};struct Varyings{float4 positionHCS : SV_POSITION;};CBUFFER_START(UnityPerMaterial)float4 _BaseColor;float _Amplitude;float _Speed;float _Phase;CBUFFER_ENDVaryings vert(Attributes v){UNITY_SETUP_INSTANCE_ID(v);// Triangle wave in [-1,1] using frac for PingPong-like motionfloat t = _Time.y * _Speed + _Phase;float tri01 = abs(frac(t) * 2.0 - 1.0); // 0..1..0float tri11 = tri01 * 2.0 - 1.0; // -1..1..-1float disp = tri11 * _Amplitude; // scale by amplitudefloat3 posOS = v.positionOS.xyz + v.normalOS * disp;Varyings o;o.positionHCS = TransformObjectToHClip(posOS);return o;}-
位移长度如何对应到世界空间
- 当前实现中,disp 的单位是对象空间的“模型单位”。顶点被加在 v.normalOS 方向上,然后整体通过对象到世界矩阵变换。因此:
- 若物体是等比缩放 s:世界空间位移 ≈ s * disp。
- 若非等比缩放:世界空间位移 ≈ length((float3x3)ObjectToWorld * normalOS) * disp,不同方向的缩放会改变位移的世界长度。
- 想让幅度用“世界单位”且不受缩放影响,可在世界空间做位移:
- 将顶点变到世界:pWS = TransformObjectToWorld(v.positionOS.xyz)
- 用归一化世界法线:nWS = TransformObjectToWorldNormal(v.normalOS)
- 位移:pWS += nWS * disp,然后 o.positionHCS = TransformWorldToHClip(pWS)
- 当前实现中,disp 的单位是对象空间的“模型单位”。顶点被加在 v.normalOS 方向上,然后整体通过对象到世界矩阵变换。因此:
-
关于 _Phase
- 你的判断基本正确:它不改变幅度与频率,只决定动画在时间轴上的起点(初始帧的相位)。
- 由于用了 frac(_Time.y * _Speed + _Phase),这里的 _Phase 单位是“周期的份额”(无量纲),例如 0.25 表示从 25% 周期处开始;_Speed 是每秒周期数。
-
在 Blender 中,坐标系为 “右手坐标系统(Right-handed)”,且 Z 轴为“向上”(Up)。Blender Stack Exchange+2Dummies+2
-
在你原图中使用的 Autodesk FBX Review(或其底层所示)可能采用的是 Y 轴为“向上”或其他约定,而非 Blender 的 Z=上。
-
因此,当你在 Blender 导入来自其他软件或查看器的模型时,常会看到模型“躺平”、“旋转 90°”的问题,这就是因为上轴 (Up Axis) 不一致。
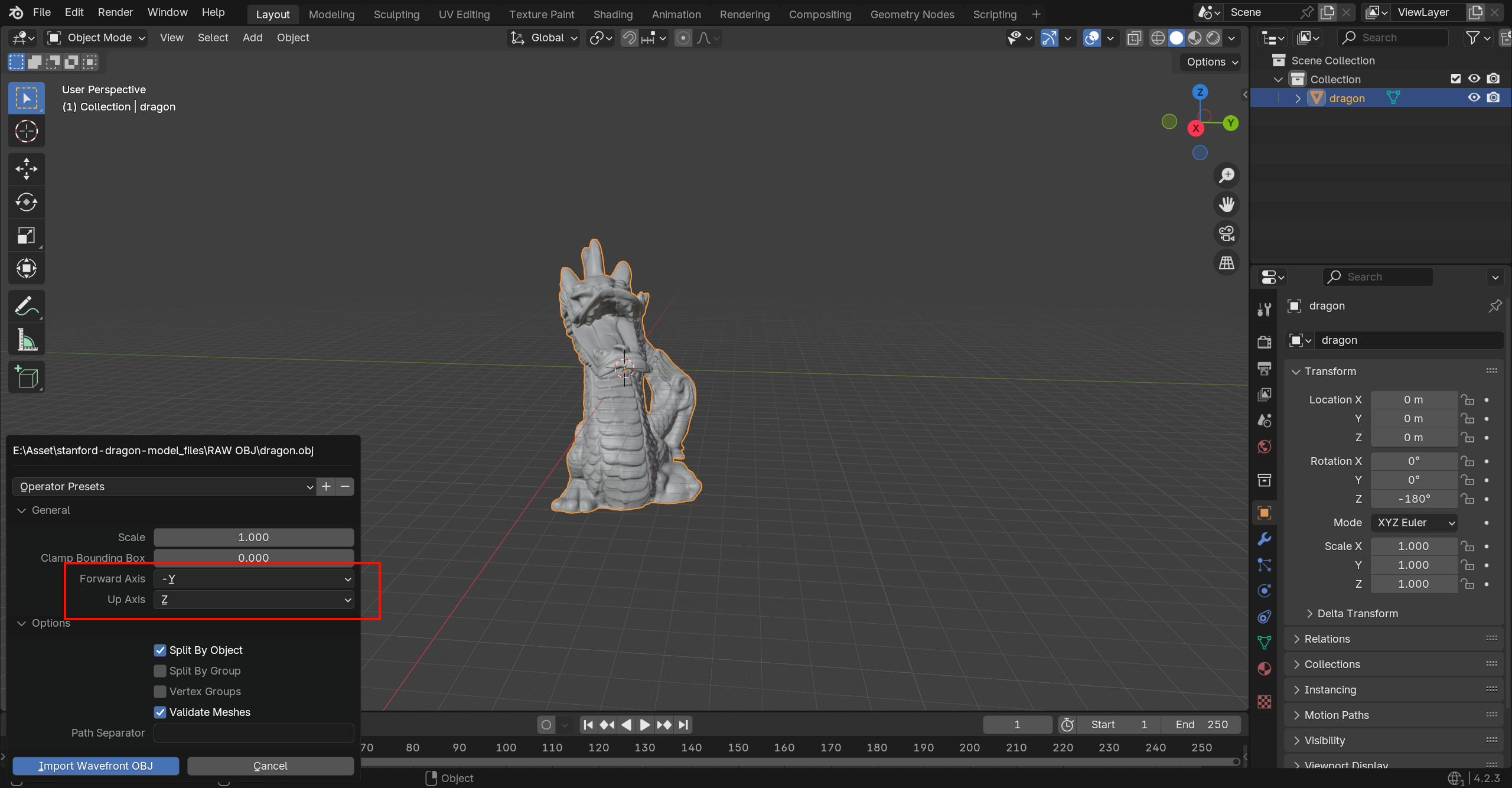
-
OBJ 是一个由 Wavefront Technologies 最初为其 “Advanced Visualizer” 软件开发的 3D 模型几何定义格式。 Wikipedia+2All3DP+2
-
它主要用于存储:顶点位置、纹理坐标 (UV)、顶点法线、面 (Polygon) 等几何结构数据。 Wikipedia+1
-
它不支持动画、骨骼、摄像机、灯光、场景层次结构等复杂数据(或其支持非常有限)在多数应用中。 docs.blender.org
-
通常配合一个
.mtl材质模板库文件使用,以定义材质与贴图。 Blue Marble Geographics+1
在 Blender 的选项中对应解释
当你看到 “Import > Wavefront (.obj)” 这个选项,意味着 Blender 将:
-
读取你选定的
.obj文件(可能还有一个.mtl文件) -
将几何体(顶点、面、法线、UV)导入成 Blender 的 Mesh 对象
-
你可以设置 “Forward Axis”/“Up Axis” 来匹配不同软件的坐标系(因为 OBJ 本身不强制某种坐标系) docs.blender.org
-
“Split By Object”/“Split By Group” 等选项控制是否把 OBJ 文件里定义的对象或组导入为 Blender 中多个对象。
黑边
https://polycount.com/discussion/186513/free-checker-pattern-texture
uv测试图
https://www.printables.com/model/696344-stanford-dragon
跨越时间不变,任何打开的项目都保证可以相通的逻辑,unity自带的版本连接,
https://assetstore.unity.com/lists/list-121004
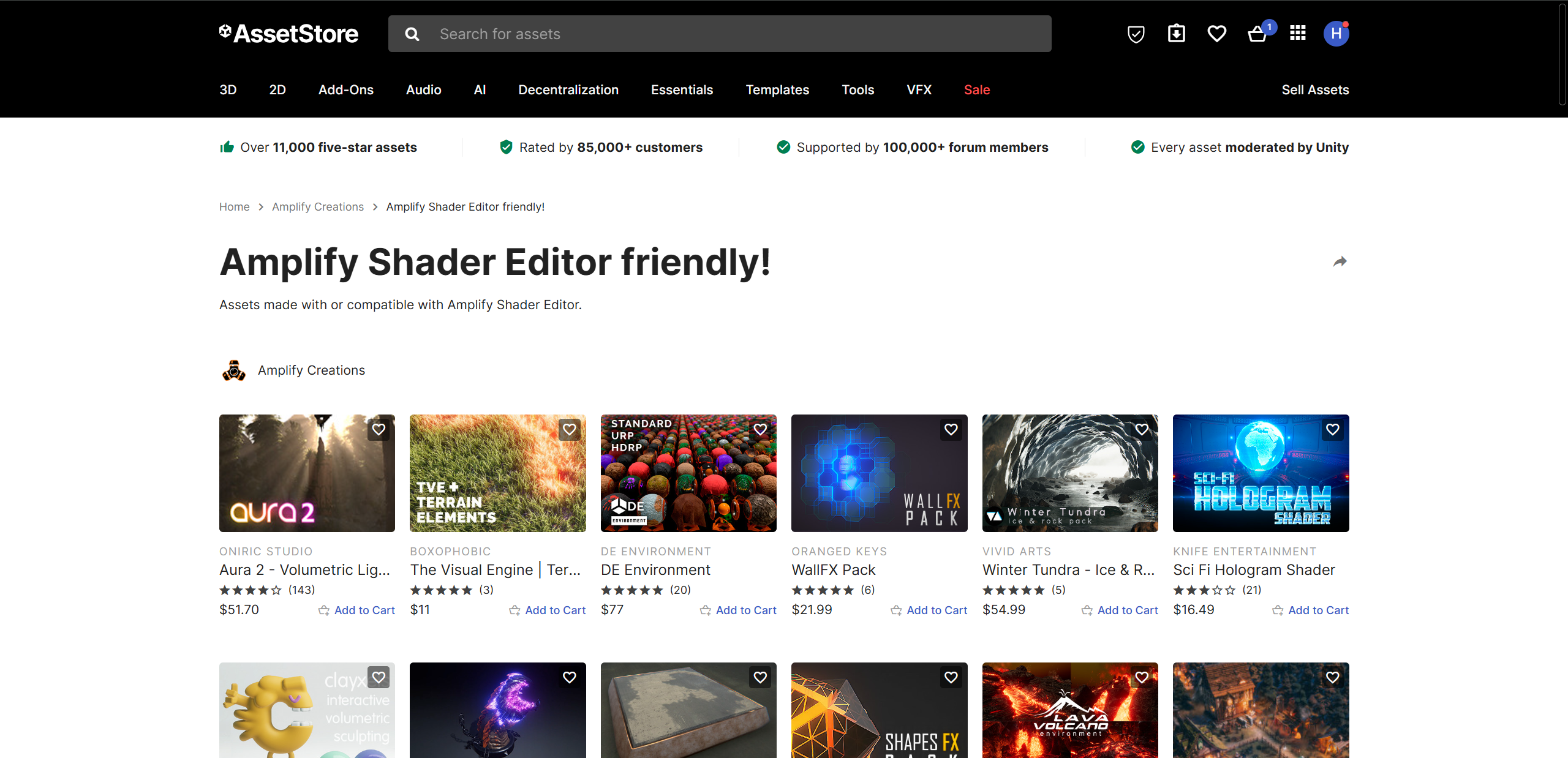
https://www.zhihu.com/question/475771378
https://zhuanlan.zhihu.com/p/518073527
https://www.reddit.com/r/Unity3D/comments/f51zem/ase_vs_unity_shader_graph_is_amplify_shader/
magicacloth2,这个组件,使用的官方教程,ase,和shadergraph,看了ase发现和shadergraph挺像的,但是用shadergraph的时候使用的,preview没有ase里面显示的那么明确,这种感觉ase反而更让人有安全感,,,
https://docs.unity3d.com/2021.3/Documentation/Manual/pack-exp.html
从 Unity 2021.1 起,“Preview”状态被淘汰,包的状态要么是 “Experimental”,要么是 “Pre-release”。
https://www.youtube.com/watch?v=4AMrlo7wha8




https://www.youtube.com/watch?v=dPJYg8kTZjM
specular workflow need higher memory
https://assetstore.unity.com/packages/tools/visual-scripting/amplify-shader-editor-68570?srsltid=AfmBOoq3CoF3xQ38tPwOW3iyYrvfLUPoGiW__tYxefYq6xFvIsfcyNWC&utm_source=chatgpt.com
如果你提到的是 Amplify Shader Editor(ASE),下面是简介 + 优缺点 +适用情境。
✅ 简介
-
它是一个节点式着色器编辑器,集成在 Unity 中,用于“拖节点”生成着色器。 amplify.pt+2wiki.amplify.pt+2
-
支持 Built-in 渲染管线 + URP + HDRP。 Unity Asset Store+1
-
提供完整源码、可扩展节点 API、模板系统、Shader 函数 (Shader Functions) 等。 amplify.pt+1
⚠️ 优缺点
优点
-
比内置的 Shader Graph 更早且更成熟,对于有复杂自定义着色需求的项目来说更灵活。 reddit.com+1
-
支持扩展自定义节点、模板,适合团队制作规范化着色器系统。
缺点
-
成本(购买费)+维护可能比免费工具多。
-
如果项目只需要简单着色器、或严格使用 URP/HDRP、或团队已经熟悉 Shader Graph,则可能“过度”了。正如某社区讨论所言:
“Start with Shader Graph, learn it well … in the extreme case you will need something that is not part of SG, it is perfectly fine to pick up Amplify later.” Real Time VFX
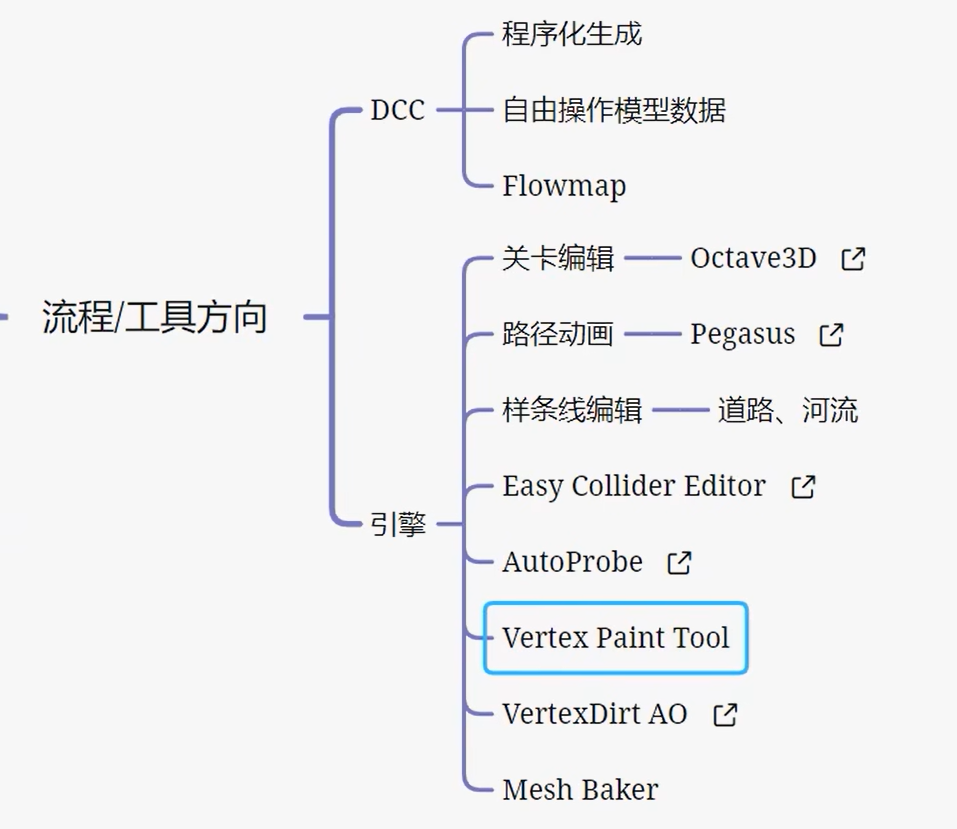
【教程】技术美术进阶计划(节选)_哔哩哔哩_bilibili
https://www.youtube.com/shorts/_mxEvF_Tl6c
一个沙子,unity里怎么做,做一盆沙子,手伸到里面可以捞出来沙子,然后会从手上流式,需要什么,沙子,基本重力,单独沙子的计算,每个沙子的单独计算,每个沙子的单独计算这真的做的到吗,为什么听上去感觉很不可行呢,还是说不可行的部分才是需要自己动脑子的?世面上常见的做法是什么,有需要去模仿吗,我自己做的效果会差多少?
i had enough, then i get into escort work---
-
硬件变:各代 SM 的 Core/LDST/SFU 数量、寄存器/共享内存大小、缓存层次、是否有 Tensor Core/RT Core 都在变。Fermi 首次提供 64KB 片上可配置 L1/Shared,早期没有统一数据 L1。NVIDIA+1
-
编程模型基本稳定:线程→warp(32)→block→grid 的模型和 kernel 启动方式保持一致;差异以 Compute Capability 暴露,代码可按能力分支。NVIDIA Docs+1
-
PTX 抽象:NV 的 PTX 是虚拟 ISA,跨代稳定,再由驱动 JIT 到各代硬件指令,最大限度屏蔽微架构差异。NVIDIA Docs+1
【实践策略】
-
以 Compute Capability 为开关做特性检测(运行时或
__CUDA_ARCH__编译时)。NVIDIA Docs -
面向 PTX/高层 API 编码,避免依赖特定代的 SASS。NVIDIA Docs
-
编译时用
-arch/-code生成合适的目标集,保留兼容 PTX。NVIDIA Docs
-
LD/ST:把线程的读写请求发往片上 L1/Shared 或片外全局内存,执行合并、对齐、返回写回等内存事务。数量影响每周期可发出的内存指令吞吐。NVIDIA+1
-
SFU:执行 sin/cos/rsqrt/exp 等超越函数和插值类指令,减轻 CUDA Cores 负担。NVIDIA
【没有它】
-
无 LD/ST:每次访存需由标量 ALU 逐步拼装事务,访存带宽暴跌,warp 长期阻塞。
-
无 SFU:超越函数退化为多条通用指令,延迟显著上升,着色和科学计算都变慢。
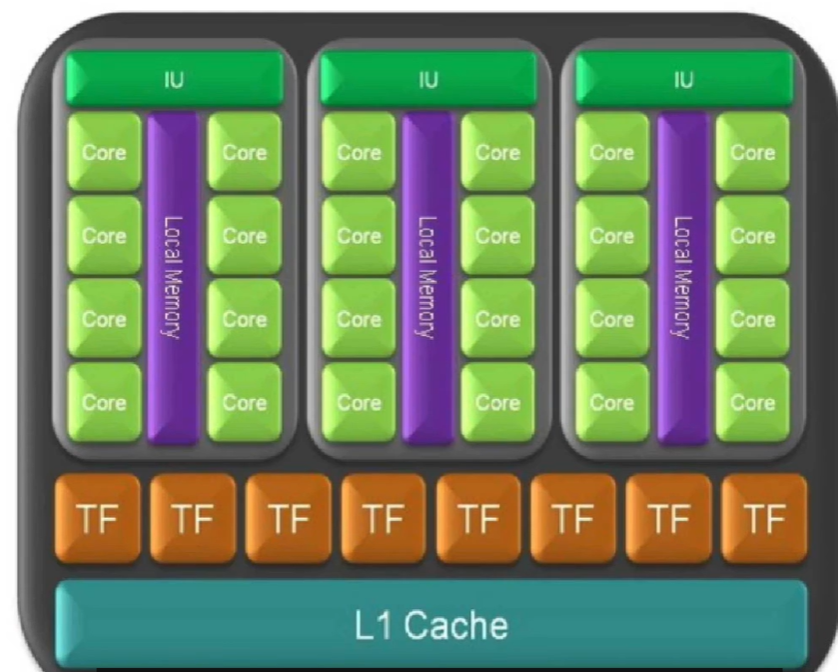
完全是乱讲、、

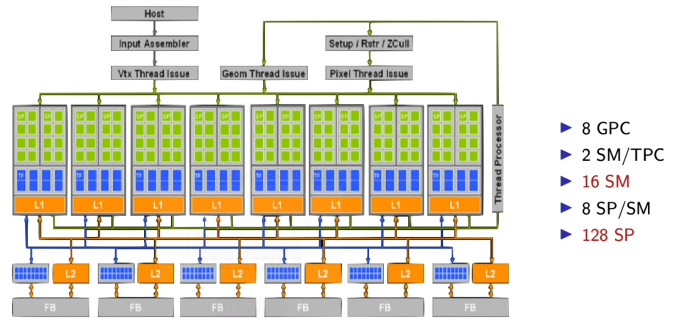
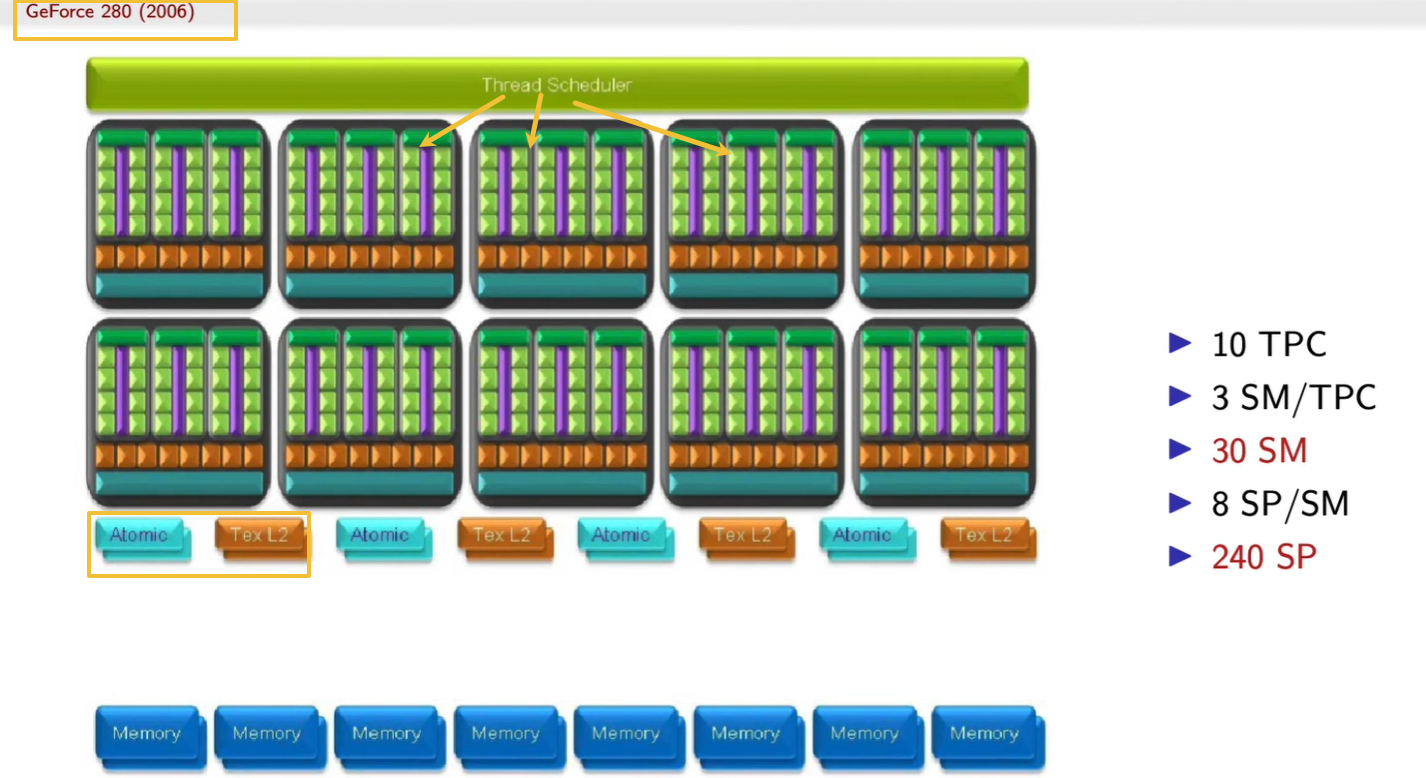
为什么要用 3 个 SM 组成 1 个 TPC?保证每个 TPC 能独立处理一组线程块,有独立的缓存与纹理通道;这样多个 TPC 可完全并行运行,如果所有 SM 都共用全局资源,线程分配会互相抢占,带宽饱和、效率骤降。
为什么这代(GeForce 280, 2006)比上一张 Tesla 架构图多了那么多格子?上一代是 8 GPC × 16 SM × 128 SP
这一代是 10 TPC × 30 SM × 240 SP
→ 并行核心数直接翻倍。
→ 并且引入了 更独立的线程调度器,可以同时处理更多 kernel。
黄色方框里 Atomic / Tex L2 / Memory 是什么层级?Atomic:负责跨线程同步与原子操作(保证加法/计数等不会冲突)。Tex L2:纹理数据的二级缓存。SP → SM → TPC → Tex L2 / Atomic → Memory
CPU → Thread Scheduler → TPC → SM → SP
黄色箭头指的 Thread Scheduler 与每个模块(TPC、SM)是什么关系?Thread Scheduler 是整个 GPU 的顶层调度器。没有它时,所有线程必须由 CPU 逐一调度,GPU 就无法做到并行管理。
它负责把 CPU 发来的 kernel(线程块) 分配给下面的 SM。
在这张图里,它把任务按块(block)分配到 10 个 TPC 的 30 个 SM 上。
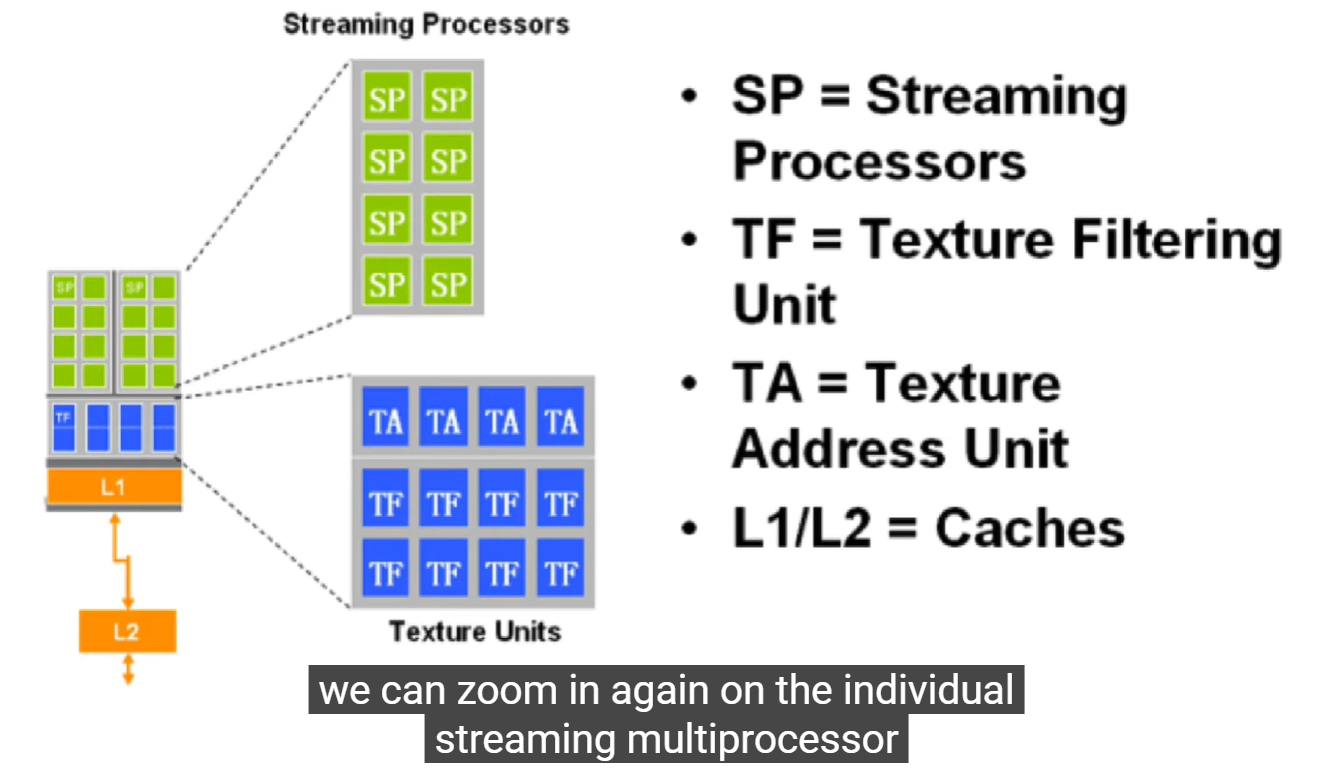
为什么 TF、TA 在 L1 上面?
它们位于缓存之上是因为先计算地址、采样、过滤,再从缓存或显存取数据。
→ 顺序是:
坐标计算(TA) → 纹理过滤(TF) → 数据命中 L1/L2 → 输出到 SP。
L1/L2 为什么叫缓存?它们和 CPU 的缓存一样吗?
-
L1:每个 SM/TPC 局部的高速缓存,保存刚刚使用或即将重用的数据。
-
L2:所有 SM 共享的全局缓存。
-
TA (Texture Address Unit):负责从纹理坐标算出显存中具体的取样位置(像素对应哪块内存)。
-
TF (Texture Filtering Unit):从多个像素样本中做插值、混合、过滤(如双线性、三线性、各向异性)。
这些操作虽然“看不见”,但渲染每一帧都必须依赖。
→ 没有它们,SP 每次取样都要自己计算坐标、权重、插值,速度会慢几十倍。
突然感觉好多废话,
每个 Thread Processor 实际对应一个 GPC,
而 GPC 内又包含多个 SM、SP。
→ 说明 GPU 调度不是“全局队列”,而是分布式的。
→ 各 GPC 独立运行自己的一部分任务,
在底层通过 L2 网络汇聚结果。
Setup / Raster / ZCull 表示光栅化管线;
Thread Processor 模块则可执行通用计算(CUDA Kernel)。
→ Tesla 架构首次实现 渲染任务与通用计算共享底层硬件。
L1 与 L2 的分层结构体现“近计算”原则
-
每个 GPC 内部独立的 L1 缓存(局部性高、速度快)
-
全局共享的 L2 缓存(跨模块通信)
-
最底层的 FB (Frame Buffer) → 外部显存(DRAM)
→ 形成三级数据通路:
寄存器 / Shared Memory → L1 → L2 → DRAM
这正是 CUDA 编程中强调的 Memory Hierarchy。
顶部模块 Vtx / Geom / Pixel Thread Issue 表示三种线程分配路径:
-
顶点线程
-
几何线程
-
像素线程
这些路径都通向下方的 Thread Processor 集群(即 GPC 阵列)。
→ 意味着渲染与计算任务共用同一执行管线,只是入口不同。
→ GPU 的多任务能力就是从这种统一调度模型演化来的。
-
8 GPC (Graphics Processing Cluster)
-
每个 TPC 含 2 个 SM (Streaming Multiprocessor)
-
每个 SM 含 8 个 SP (Streaming Processor)
→ 共计 128 个 SP。
这就是早期 Tesla 架构的典型布局:
8×2×8 = 128 并行核心。
这种乘法式结构是 GPU 的标志性特征——并行层次的几何级扩张。