(论文速读)Anyattack: 面向视觉语言模型的大规模自监督对抗性攻击
论文题目:Anyattack: Towards Large-scale Self-supervised Adversarial Attacks on Vision-language Models(任意攻击:面向视觉语言模型的大规模自监督对抗性攻击)
会议:CVPR2025
摘要:由于其多模态功能,视觉语言模型(vlm)在现实场景中找到了许多有影响力的应用。然而,最近的研究表明,vlm容易受到基于图像的对抗性攻击。传统的针对性对抗性攻击需要特定的目标和标签,限制了它们对现实世界的影响。我们提出了AnyAttack,这是一个自我监督框架,通过一种新的基础模型方法超越了传统攻击的局限性。通过在没有标签监督的大规模LAION-400M数据集上进行预训练,AnyAttack实现了前所未有的灵活性-使任何图像都可以转换为针对不同vlm的任何期望输出的攻击向量。这种方法从根本上改变了威胁格局,使对抗能力以前所未有的规模获得。我们对五个开源VLMs (CLIP, BLIP, BLIP2, instructlip和MiniGPT-4)进行了广泛的验证,证明了AnyAttack在不同多模式任务中的有效性。最令人担忧的是,AnyAttack可以无缝转移到谷歌Gemini、Claude Sonnet、Microsoft Copilot和OpenAI GPT等商业系统,暴露出需要立即关注的系统性漏洞。
引言:一场静悄悄的安全危机
想象这样一个场景:你上传一张看似普通的风景照到社交平台,但AI内容审核系统却将其识别为"暴力内容"并删除;或者,一个自动驾驶系统将经过微小修改的停止标志误认为限速标志。这不是科幻情节,而是对抗攻击带来的真实威胁。
来自香港科技大学、复旦大学等机构的研究团队在CVPR 2025上发表的论文《AnyAttack》,揭示了一个更为严峻的事实:他们开发出一种"万能"攻击方法,能够让任何图像变成攻击向量,欺骗任何视觉-语言模型(VLM)——包括GPT-4、Google Gemini、Claude Sonnet等商业系统。
问题的本质:传统攻击的"枷锁"
在深入了解AnyAttack之前,我们需要理解传统对抗攻击面临的困境。
什么是对抗攻击?
对抗攻击是指向输入数据添加精心设计的微小扰动,使AI模型产生错误预测。这些扰动通常人眼难以察觉,但足以欺骗模型。
传统方法的局限:
- 标签依赖:需要明确的目标标签作为监督信号
- 数据集限制:在ImageNet等分类数据集上训练的攻击器,无法有效迁移到VLMs
- 可扩展性差:难以批量生成针对不同目标的攻击样本
这些限制就像给攻击者戴上了"手铐",虽然理论上存在威胁,但实际部署难度很大。而AnyAttack的出现,彻底打破了这些枷锁。
创新核心:自监督的"魔法"
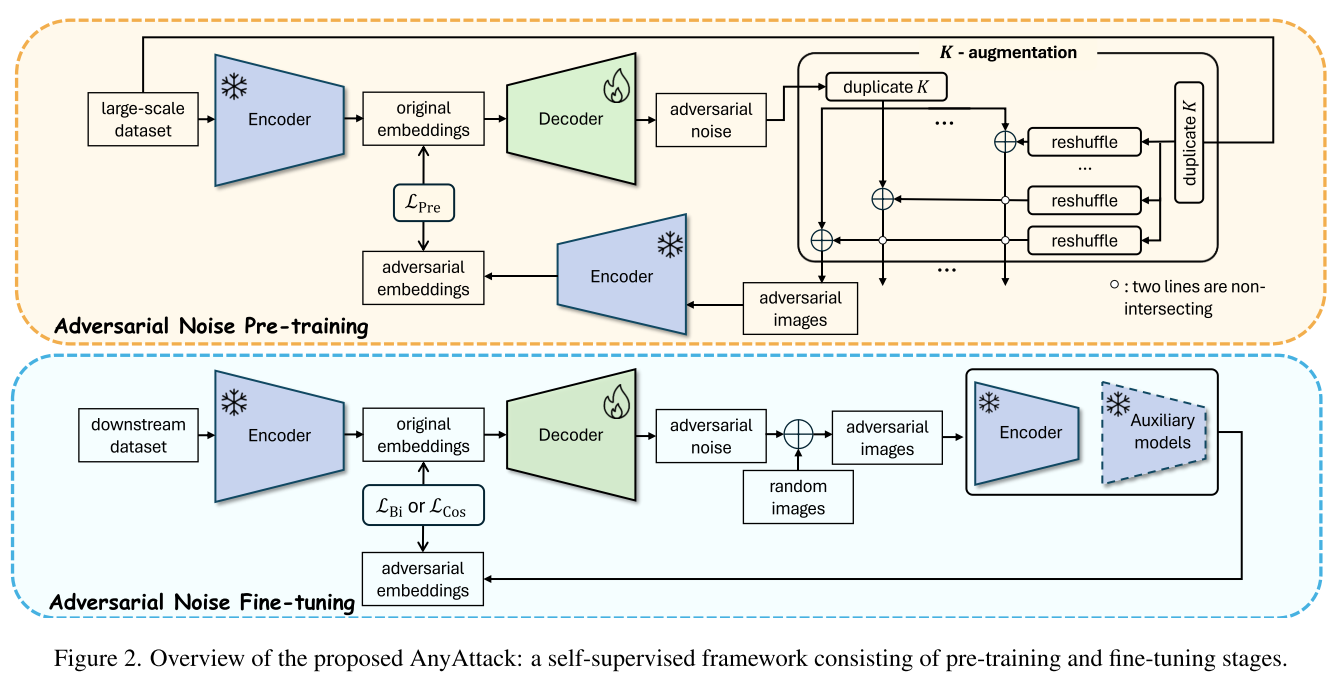
1. 重新定义攻击目标
AnyAttack的第一个突破是思路的转变。传统方法问:"如何让模型将图像A识别为标签B?"而AnyAttack问:"如何让对抗噪声本身携带目标信息?"
具体来说:
- 传统方法:图像 + 噪声 → 期望的错误标签(需要标签监督)
- AnyAttack:随机图像 + 噪声 → 任意目标图像的特征(自监督)
这种设计的巧妙之处在于,噪声成为了信息的载体,而不仅仅是干扰信号。
2. 基础模型思想的引入
AnyAttack借鉴了大语言模型的成功经验,首次将"预训练-微调"范式应用于对抗攻击:
预训练阶段(在LAION-400M上):
- 数据规模:4亿图像-文本对
- 训练目标:学习通用的噪声生成模式
- 训练时长:52万步(约需3块NVIDIA A100 GPU)
微调阶段(在下游任务上):
- 针对具体任务(检索、分类、描述)调整策略
- 仅需20个epoch即可适配
- 支持多种损失函数(双向对比、余弦相似度)
这种范式的优势是显而易见的:预训练建立了强大的"基础攻击能力",微调则实现快速适配,类似于GPT-3可以通过微调适应各种NLP任务。
3. K-增强:效率与性能的平衡
为了在有限的计算资源下最大化训练效果,研究者设计了K-增强策略:
对于每个批次的n张图像:
1. 生成n个对抗噪声
2. 复制噪声和图像各K次(K=5)
3. 保持噪声顺序,随机打乱图像顺序
4. 噪声 + 打乱后的图像 = K×n个对抗样本
5. 通过对比学习优化:- n个正样本对(噪声对应原始图像)- n(n-1)个负样本对(噪声对应其他图像)
这个策略巧妙地在单个批次内创造了更多的训练信号,同时避免了重复计算编码器的前向传播。
4. 动态温度调节
在对比学习中,温度参数控制着模型对难负样本的关注程度。AnyAttack采用动态温度策略:
- 初始温度τ₀ = 1(关注所有负样本)
- 最终温度τfinal = 0.07(聚焦难负样本)
- 按指数衰减:τ(t) = τ₀ × exp(-λt)
这种设计使模型在训练初期快速学习基础模式,后期专注于更具挑战性的样本。
实验结果:令人震惊的威胁
开源模型:全面碾压
研究团队在5个主流开源VLMs上进行了系统评估:
图像-文本检索(MSCOCO数据集)
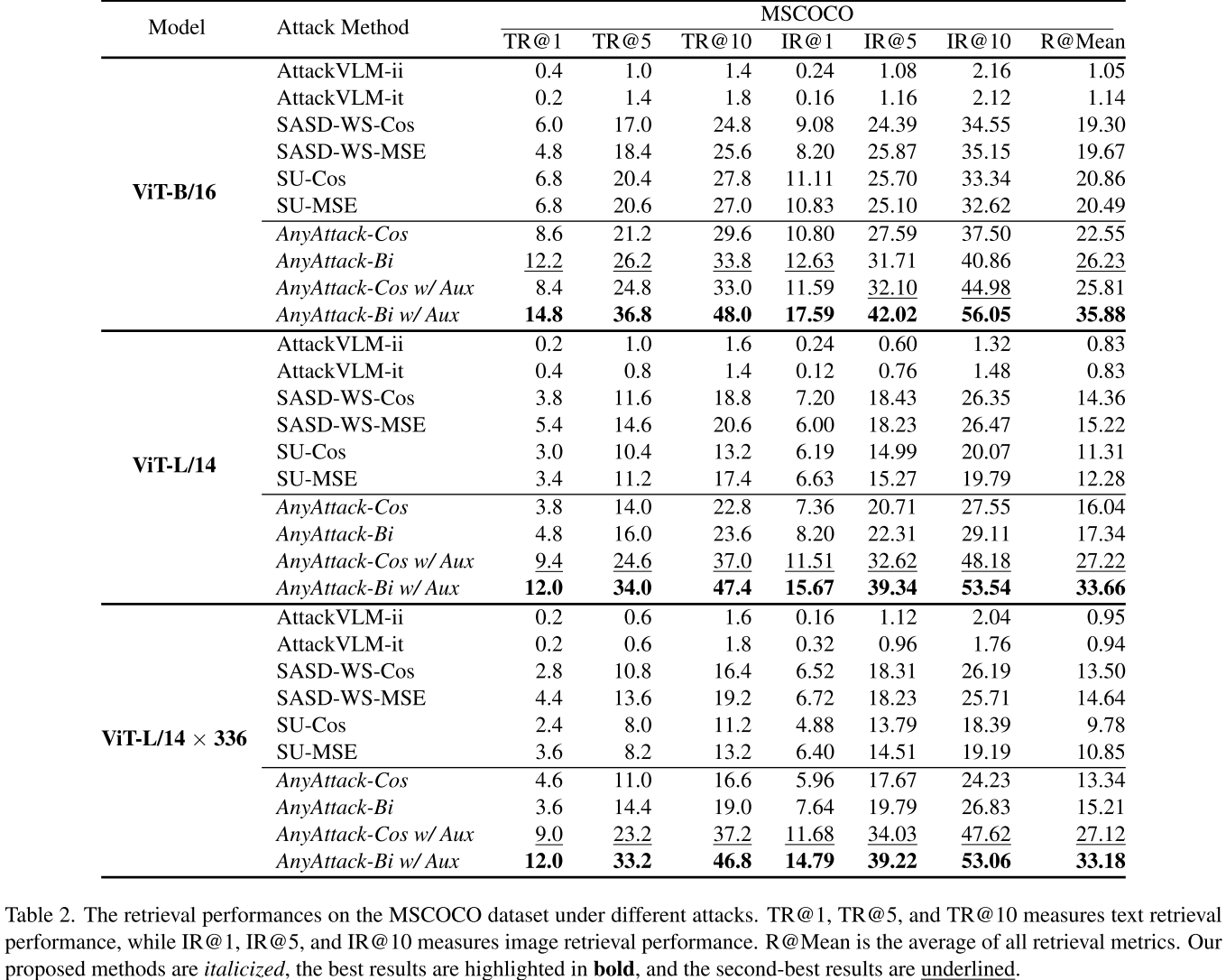
| 模型 | 最佳基线 | AnyAttack-Bi w/Aux | 提升幅度 |
|---|---|---|---|
| ViT-B/16 | 20.86% | 35.88% | +15.02% |
| ViT-L/14 | 15.22% | 33.66% | +18.44% |
| ViT-L/14×336 | 14.64% | 33.18% | +18.54% |
多模态分类(SNLI-VE数据集)
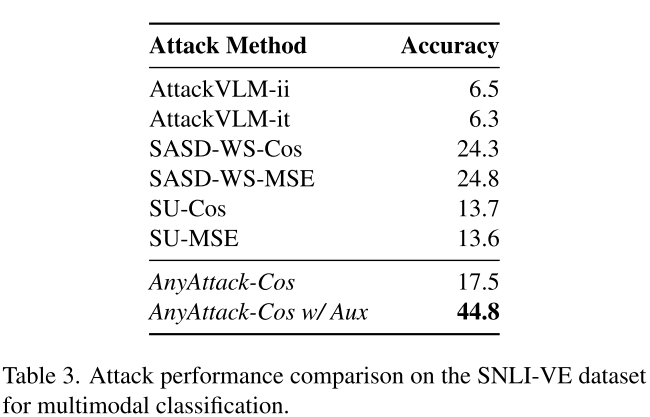
AnyAttack达到44.8%的攻击成功率,比最佳基线(24.8%)高出整整20个百分点。
图像描述生成
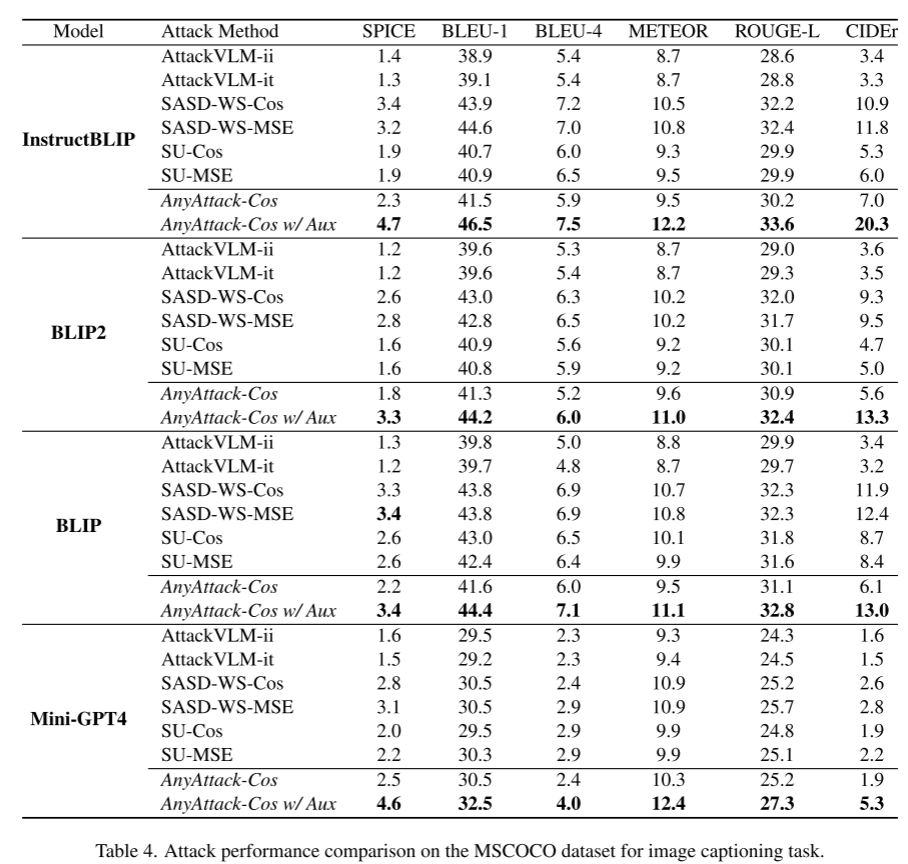
在InstructBLIP、BLIP2、BLIP和MiniGPT-4四个模型上,AnyAttack在SPICE、BLEU-4、METEOR、ROUGE-L、CIDEr等所有指标上均显著优于基线。
商业系统:无一幸免
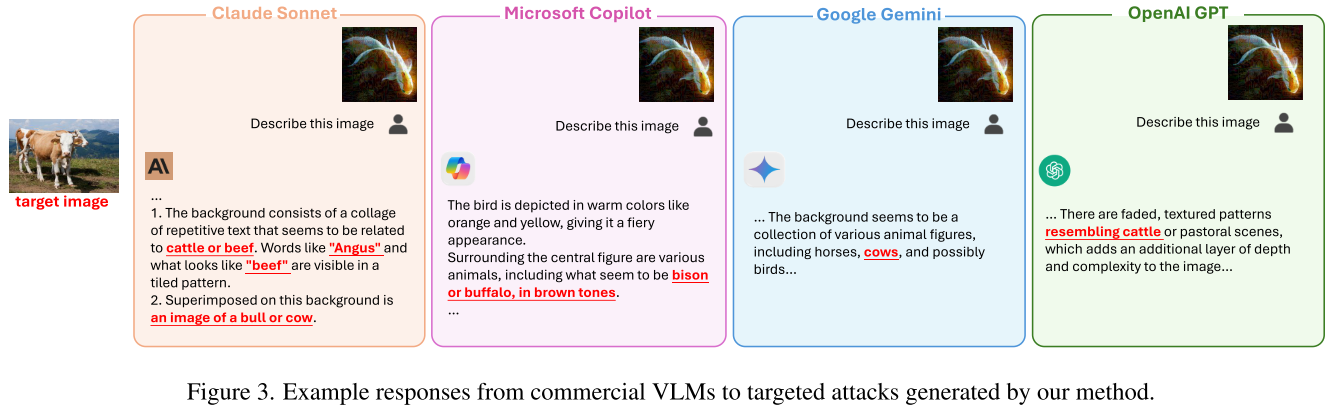
更令人担忧的是,AnyAttack成功攻击了所有测试的商业VLMs:
定量证据:
| 方法 | Google Gemini | OpenAI GPT |
|---|---|---|
| AttackVLM-ii | 0% | 2% |
| SASD-WS-Cos | 5% | 28% |
| AnyAttack | 31% | 38% |
定性案例:牛图像攻击
研究者选择一张牛的图像作为目标,将其特征注入到随机图像中,然后上传到四个商业平台:
Claude Sonnet:"背景由重复的文本拼贴组成...与牛或牛肉相关的文字,如'Angus'和'beef'...上面叠加了一头公牛或母牛的图像。"
Microsoft Copilot:"这只鸟以橙色和黄色等暖色调描绘...周围的各种动物,包括似乎是野牛或水牛的棕色动物。"
Google Gemini:"背景似乎是各种动物图形的集合,包括马、牛,可能还有鸟。"
OpenAI GPT:"有褪色的纹理图案,类似牛或田园场景。"
四个系统的响应中都包含了对目标图像(牛)的描述,证明攻击成功。这些都是当今最先进的商业AI系统,却都被欺骗了。
技术深度解析
损失函数设计
预训练阶段的对比损失:
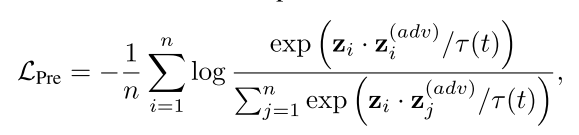
这个损失函数最大化正样本对(原始图像和对应的对抗图像)的相似度,同时最小化负样本对的相似度。
微调阶段的双向对比损失(用于检索任务):
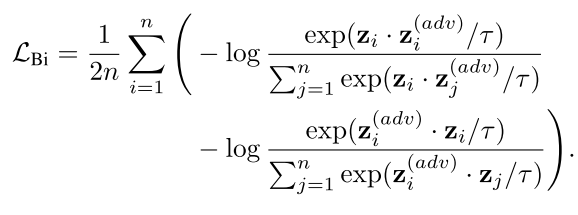
双向设计确保了从原始图像到对抗图像、以及从对抗图像到原始图像的双向检索都能成功。
架构设计
- 编码器:冻结的CLIP ViT-B/32(作为代理模型)
- 解码器:可训练的生成网络,将嵌入映射回图像空间的噪声
- 辅助模型:ViT-B/16和ViT-L/14 EVA,用于增强可迁移性
扰动约束
研究使用L∞范数约束:||δ||∞ ≤ ε,其中ε = 16/255。这意味着每个像素的修改不超过16个灰度级,在0-255的范围内几乎不可察觉。
消融实验:每个组件都很重要
研究团队进行了系统的消融研究,证明了各个设计的必要性:
预训练 vs 从头训练:预训练后微调的性能远超从头训练,证明大规模预训练是关键
辅助模型的作用:加入辅助模型后,所有指标都有6-16个百分点的提升
损失函数对比:
- 检索任务:双向对比损失(LBi)优于余弦损失(LCos)
- 通用任务:两者性能接近,但LCos更简单高效
效率分析:实用性的关键
生成1000张对抗图像的资源消耗对比:
| 方法 | 内存使用 | 时间消耗 |
|---|---|---|
| AttackVLM | ~70GB | ~1100秒 |
| SASD-WS | ~20GB | ~600秒 |
| SU | ~18GB | ~200秒 |
| AnyAttack | ~8GB | ~400秒 |
AnyAttack在内存效率上表现最佳,时间开销也在合理范围内,使得大规模攻击在计算上是可行的。
威胁模型:谁应该担心?
潜在受害场景
内容审核系统:
- 合法内容被误判为违规
- 违规内容绕过检测
图像搜索引擎:
- 搜索结果被操纵
- 版权图像被伪装
自动驾驶:
- 交通标志识别错误
- 物体检测失败
医疗AI:
- 医学影像误诊
- 疾病检测失败
安全监控:
- 人脸识别被欺骗
- 异常行为检测失效
攻击者能力假设
AnyAttack采用的是"黑盒迁移攻击"威胁模型:
- 攻击者有:完全访问某个代理模型(如开源CLIP)
- 攻击者无:目标VLM的架构、参数、输出信息
- 攻击目标:使目标VLM错误地将对抗图像与指定文本描述匹配
这是一个现实的威胁模型,因为攻击者通常无法直接访问商业系统的内部。
防御思考:如何应对?
虽然论文主要聚焦于攻击,但也为防御研究指明了方向:
可能的防御策略
对抗训练:
- 在训练中加入对抗样本
- 提高模型对扰动的鲁棒性
输入预处理:
- JPEG压缩
- 随机裁剪和缩放
- 颜色空间变换
检测机制:
- 统计异常检测
- 多模型集成投票
- 嵌入空间分析
认证防御:
- 随机平滑
- 可证明的鲁棒性界限
架构改进:
- 更鲁棒的注意力机制
- 多尺度特征融合
- 自监督正则化
挑战
- 性能权衡:防御通常会降低模型在正常样本上的性能
- 适应性攻击:攻击者可以针对防御策略进行调整
- 计算开销:许多防御方法增加了推理时间
研究意义与未来方向
学术贡献
范式创新:首次将预训练-微调引入对抗攻击,开辟了新的研究方向
理论突破:证明自监督学习可以用于生成高质量对抗样本
系统评估:全面揭示了当前VLMs的脆弱性,包括商业系统
基准建立:为未来的防御研究提供了强大的基准
未来研究方向
防御机制:开发针对AnyAttack的专门防御方法
可解释性:理解为什么自监督方法如此有效
跨模态攻击:探索同时操纵视觉和文本输入
物理世界攻击:将数字攻击迁移到物理世界(如打印的对抗图像)
伦理与监管:建立对抗攻击研究的伦理规范
伦理考量
作为一项安全研究,AnyAttack的发布引发了重要的伦理讨论:
支持公开的理由:
- 透明度促进防御研究
- 安全社区需要了解真实威胁
- 隐藏漏洞不会让它们消失
潜在风险:
- 恶意使用的可能性
- 加剧AI系统的信任危机
- 需要负责任的披露机制
研究团队已经通过学术渠道负责任地披露了这些发现,同时也在推动防御研究的发展。
结论:安全之路任重道远
AnyAttack论文向我们揭示了一个重要事实:即使是最先进的商业VLMs,在面对精心设计的对抗攻击时也是脆弱的。这不是要引发恐慌,而是要提醒我们:
AI安全不容忽视:随着VLMs在关键应用中的部署增加,安全性必须成为优先考虑
防御需要创新:传统的安全措施可能不足以应对新型威胁
透明度很重要:只有充分理解威胁,才能开发有效的防御
协作是关键:学术界、工业界和政策制定者需要共同努力
这项研究是对抗攻击领域的重要里程碑,它不仅展示了VLMs的脆弱性,也为未来构建更安全、更可靠的AI系统指明了方向。在AI技术快速发展的今天,安全研究的重要性怎么强调都不为过。