当夸克遇上大模型:中国 AI 产品的“第二阶段”来临了
10 月 23 日,阿里旗下夸克 App 悄然上线了一个新入口——「对话助手」。
一时间,朋友圈、知乎、B 站都在讨论:
“夸克要变成中国的 ChatGPT 吗?”
这其实是一个更大的问题的开始:
当搜索产品与大模型融合时,会发生什么?
一、夸克不是加了个AI,而是换了个“大脑”
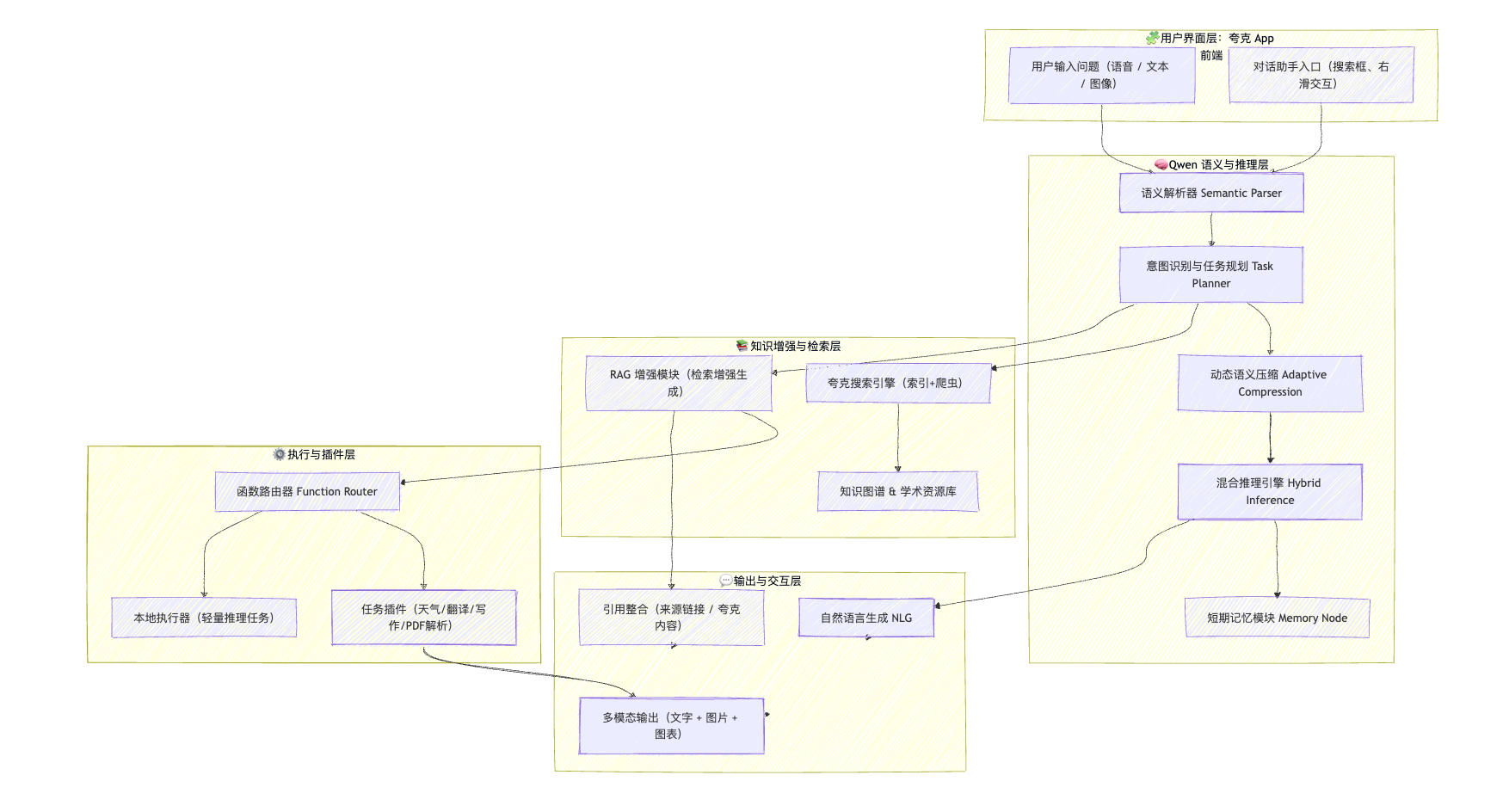
打开新版夸克 App,你会发现搜索框变了:
原来的输入提示从“搜索你想要的内容”,变成了“问我任何问题”。
这不是一句口号,而是一个信号——
夸克正在从“索引世界”走向“理解世界”。
搜索是信息的入口,AI 是理解的引擎。
夸克把两者融合,实质上是在为阿里的大模型 Qwen 找到一个“真实场景的容器”。
二、从“检索”到“生成”:夸克完成了语义闭环
在传统搜索中,逻辑是这样的:
用户输入关键词 → 系统检索网页 → 排序返回链接。
而在夸克的新架构里,逻辑变成了:
用户输入语义 → Qwen 模型理解意图 → 搜索 + 生成融合输出。
换句话说,夸克已经从「信息查找器」变成了一个「语义执行系统」。
它理解你的问题,调用不同的模块来解决它,而不是单纯返回网页。
这套机制可以用一个图形化思维来理解👇
flowchart TD
A[用户问题] --> B[语义解析 (Qwen)]
B --> C1[知识检索 (夸克索引)]
B --> C2[内容生成 (大模型回答)]
B --> C3[任务执行 (插件/API 调用)]
C1 --> D[语义融合层]
C2 --> D
C3 --> D
D --> E[结果输出:文字 / 链接 / 图表 / 动作]
这正是大模型产品化的核心方向:
从“语言交互”走向“任务执行”。
三、为什么是夸克,而不是钉钉、淘宝或天猫精灵?
阿里有很多接入 Qwen 的产品,但夸克是唯一一个真正 “纯 AI First” 的场景。
原因有三:
场景天然轻量:
用户在夸克上的行为天然短、频、可数据化——这对大模型训练极其友好。
每一次提问,都是一条新的语义样本。知识生态天然丰富:
拥有论文、教材、百科、网页等知识源,是模型知识增强(RAG)的理想土壤。品牌形象中立:
夸克不像钉钉有企业属性,也不像淘宝有商业倾向。
它更像中国版的「Google Assistant」,适合做通用语义实验。
因此,“夸克对话助手”不是一个孤立的功能,而是阿里在验证一件事:
如何把大模型做成一个“无感产品”。
四、Qwen 在夸克中的角色:不是插件,是中枢
很多人以为夸克只是在接口层“调用了 Qwen”,
但从架构角度看,它更像是让 Qwen 成为系统的语义中枢。
Qwen 在其中承担三个关键任务:
语义解析:理解用户意图(Intent Parsing);
任务路由:判断需要搜索、生成还是执行;
多模态融合:将文字、网页、图片、表格等数据进行语义对齐。
这与 OpenAI 的「Function Calling + Memory」体系极其相似,
但夸克的实现方式更贴近国内的实际场景——它把“搜索”和“执行”放在了同一框架中。
比如,当你输入:
“帮我生成一篇关于新能源车的论文摘要”
夸克的执行逻辑可能是这样的:
Step 1: Qwen 解析任务 → 论文主题识别
Step 2: 夸克检索数据库 → 抽取高质量资料
Step 3: 模型生成摘要 → 语言润色 + 引用来源
Step 4: 输出带参考的内容
整个链路完成于数秒内,这就是典型的 检索增强生成(RAG) + 语义执行融合(Semantic Fusion)。
五、从体验角度看:夸克更像是“中国的 Perplexity AI”
如果说豆包是中国的 ChatGPT,
那么夸克更像是中国的 Perplexity AI + Google SGE 的混合体。
它的回答通常带有:
引用来源(来自夸克检索);
结构化生成(模型生成摘要);
可点击交互(延伸阅读)。
这让它拥有两种体验层的优势:
| 维度 | ChatGPT | 夸克 |
|---|---|---|
| 信息准确性 | 依赖模型记忆 | 结合实时搜索 |
| 回答速度 | 快,但偏生成 | 稍慢,但更可靠 |
| 可验证性 | 难以追溯 | 提供引用来源 |
| 使用场景 | 通用问答 | 学习、资料、论文、知识增强 |
这意味着夸克不打算“和 ChatGPT 拼”,
它要走一条更稳、更“有知识密度”的路径。
六、技术亮点:语义压缩与混合推理的落地验证
根据内部推测与性能表现,夸克的“对话助手”采用了 Qwen 系列的闭源变体,
包含两个关键特性:
Adaptive Compression(自适应语义压缩)
将长对话上下文压缩为低维语义向量,降低 token 成本并保持上下文一致。Hybrid Inference(混合推理)
根据任务复杂度动态选择模型规模:简单问答 → 小模型本地推理;
复杂生成 → 云端大模型推理。
这种架构在技术层面非常先进,
既保证了速度,也保证了效果,是国产模型工程化的关键一跃。
七、夸克的真正价值:做中国的“AI 操作层”
如果我们把手机操作系统看作“硬件管理层”,
把微信、抖音看作“社交/内容层”,
那么夸克想做的,其实是 “语义操作层”。
也就是说:
用户不再用 App,而是通过语言直接操控一切。
这正是智能体(Agent)的核心概念。
夸克在做的,就是让这套机制首先跑通在最熟悉的入口——搜索框。
八、行业启示:大模型的第二阶段是“场景驱动”
2023 年是模型之年,大家都在比参数、比榜单。
2024 年是能力之年,RAG、Tool、Agent 成为关键词。
而 2025 年,已经进入了 “场景驱动”之年。
这意味着:
模型不再是主角;
用户体验成为新的竞争焦点;
谁能让模型真正“进入生活”,谁就赢。
夸克的出现,不是技术突破,而是产品定义的突破。
它证明了一件事:
大模型并不神秘,它可以无声地藏在一个搜索框里。
🧭 结语:AI,不止是回答问题,而是理解世界
夸克对话助手的诞生,像是一个信号。
它让我们看到中国 AI 产品正在从“展示模型”走向“融入生活”。
当某一天,
你不再打开 ChatGPT、Kimi、文心,而是随手点开夸克就能解决问题,
那时的大模型,才算真正“落地”。
📍作者点评:
夸克的这一步,不是模仿 ChatGPT,而是补齐中国 AI 的“认知层”。
它让我们看到:未来的搜索框,不只是输入框,而是通往世界的语义接口。