小杰-自然语言处理(seven)——transformer系列——自注意力(self-attention)
1.引入
Self - attention(自注意力)是一种注意力机制,其核心在于同一输入序列生成 Q、K、V。通过计算序列内元素间的相关性(Q 与 K 的权重矩阵),对元素(V)加权求和得到新的上下文表示,能捕捉长距离依赖,是 Transformer 的核心组件,广泛应用于 NLP、CV 等领域。
2.1 self-attention矩阵运算过程
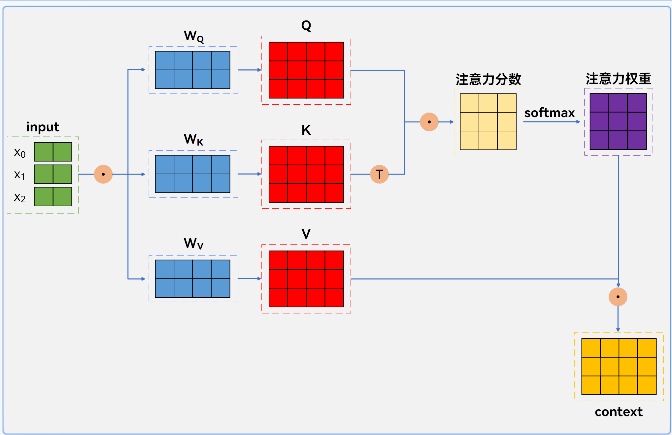
假设输入序列有 3 个词,词向量维度 2(输入矩阵 X 为 3×2)。随机初始化 3 个 2×4 的权重矩阵 W_Q、W_K、W_V,与 X 相乘得到 3×4 的 Q、K、V。
计算 Q 与 K 转置的点乘,得 3×3 注意力分数矩阵,除以![]() (其中
(其中
![]() 缩放后,经 softmax 得到权重矩阵,再与 V 相乘,得到 3×4 的输出矩阵 context,即为 Self-Attention 结果,融合了序列内各元素信息。
缩放后,经 softmax 得到权重矩阵,再与 V 相乘,得到 3×4 的输出矩阵 context,即为 Self-Attention 结果,融合了序列内各元素信息。
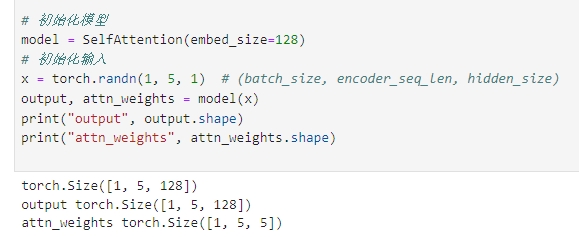
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
#定义Self-Attention 类
class SelfAttention(nn.Module):def __init__(self,input_dim,qkv_dim):"""input_dim: 输入向量维度(如图中每个 x 的维度,假设输入是单个向量拼接,这里设为图中隐含的维度,比如示例里可理解为每个 x 是 2 维,实际按需求调整)qkv_dim: Q、K、V 的维度(对应图中 W_Q、W_K、W_V 输出维度,图中示意生成的 Q/K/V 是更高维,这里设为 4 演示,可按需改)"""super(SelfAttention,self).__init__()# 初始化 Q、K、V 对应的权重矩阵self.W_Q=nn.Linear(input_dim,qkv_dim)self.W_K = nn.Linear(input_dim, qkv_dim)self.W_V = nn.Linear(input_dim, qkv_dim)def forward(self,x):"""x: 输入序列,形状为 [seq_len, input_dim],对应图中 x0、x1、x2 拼接后的输入,这里 seq_len=3(3 个元素),input_dim 是单个元素维度"""Q=self.W_Q(x)# [3, qkv_dim] 对应图中 Q 矩阵,每个 x 映射到 Q 空间K = self.W_K(x)# [3, qkv_dim] 对应图中 K 矩阵,每个 x 映射到 K 空间V = self.W_V(x) # [3, qkv_dim] 对应图中 V 矩阵,每个 x 映射到 V 空间# 2. 计算注意力分数(Q 与 K^T 点乘)scores = torch.matmul(Q, K.transpose(0, 1))# 3. 缩放(可选,图中未体现但实际常用,这里按公式加一下,d_k 取 qkv_dim 开根号)d_k = Q.size(-1) # 获取 K 的维度,即 qkv_dimscores = scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))# 4. 计算注意力权重(softmax 归一化),得到 [3, 3] 权重矩阵,对应图中“注意力权重”attention_weights = F.softmax(scores, dim=-1)# 5. 加权求和得到 context(权重与 V 相乘),结果形状 [3, qkv_dim],对应图中“context”context = torch.matmul(attention_weights, V)return context, attention_weightsif __name__ == '__main__':#模拟输入input_seq=torch.tensor([[1.1, 2.2], # x0[3.4, 4.4], # x1[5.4, 6.4]], # x2dtype=torch.float32)# 初始化 Self - Attention 模块self_attention=SelfAttention(input_dim=2, qkv_dim=4)# 前向传播context, attention_weights = self_attention(input_seq)# 打印结果查看print("Q 矩阵:\n", self_attention.W_Q(input_seq).shape)print("K 矩阵:\n", self_attention.W_K(input_seq).shape)print("V 矩阵:\n", self_attention.W_V(input_seq).shape)print("注意力分数矩阵:\n",torch.matmul(self_attention.W_Q(input_seq), self_attention.W_K(input_seq).transpose(0, 1)).shape)print("注意力权重矩阵:\n", attention_weights.shape)print("最终 context 输出:\n", context.shape)实验结果为: