OUC AI Lab 第四章:即插即用的注意力机制
1、论⽂阅读与视频学习
1.4 SENet & CBAM
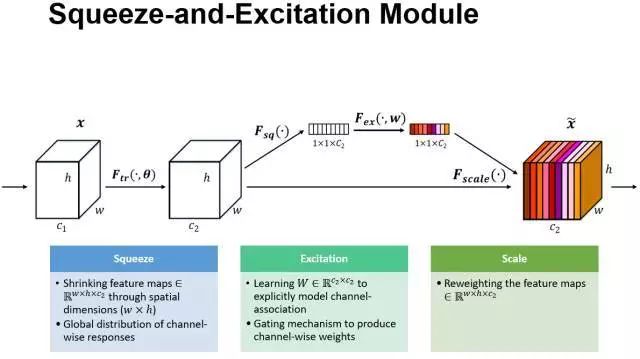
SE模块是一个非常简单的模块,在c1到c2是传统的网络层,之后,特征图会经过三个步骤。
首先是 Squeeze 操作,也就是将每一个chnnel压缩成了一个实数,在这里使用全局池化进行操作,长度就是channel的长度,其次就是对这个张量进行处理。
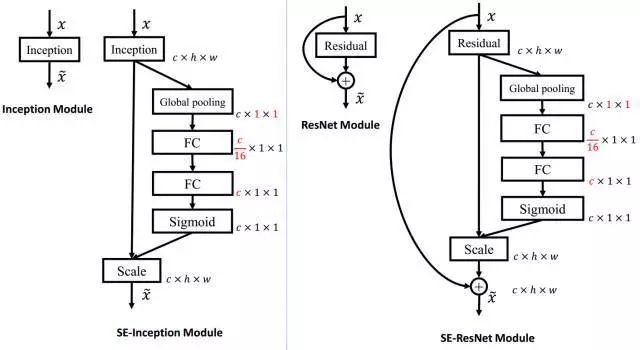
处理的方式也很简单,经过两层全连接层,先降维后升维到channel长度,再经过一层sigmold层即可。
最后就是将得到的这个向量乘到之前的那个特征图上去。
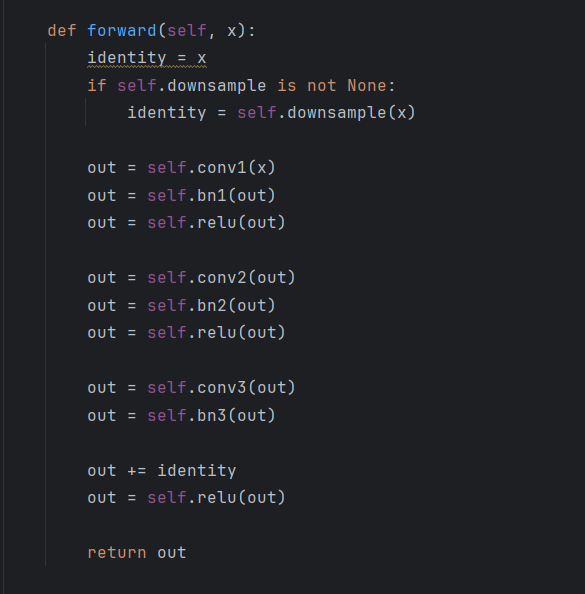
想要把SE模块添加到resnet中去也很简单,上面是传统的resnet的一个模块,只需要在out += 之前添加下面的模块即可

其中经过平均池化的数据的形状为[1,outchannel,1,1]
所以这里的fc实际上是conv2d

相乘也更方便。
2、代码作业
网络部分:
class_num = 16
class HybridSN(nn.Module):def __init__(self):super(HybridSN, self).__init__()self.conv1 = nn.Conv3d(1,8,kernel_size=(7,3,3))self.conv2 = nn.Conv3d(8,16,kernel_size=(5,3,3))self.conv3 = nn.Conv3d(16,32,kernel_size=(3,3,3))self.conv4 = nn.Conv2d(576,64,3)self.fc1 = nn.Linear(18496,256)self.dropout1 = nn.Dropout(0.4)self.fc2 = nn.Linear(256,128)self.dropout2 = nn.Dropout(0.4)self.clas = nn.Linear(128,class_num)def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.relu(x)x = self.conv3(x)x = F.relu(x)x = x.reshape(x.size(0),-1,x.size(3),x.size(4))x = F.relu(self.conv4(x))x = x.reshape(x.size(0),-1)x = F.relu(self.dropout1(self.fc1(x)))x = F.relu(self.dropout2(self.fc2(x)))x = self.clas(x)return x
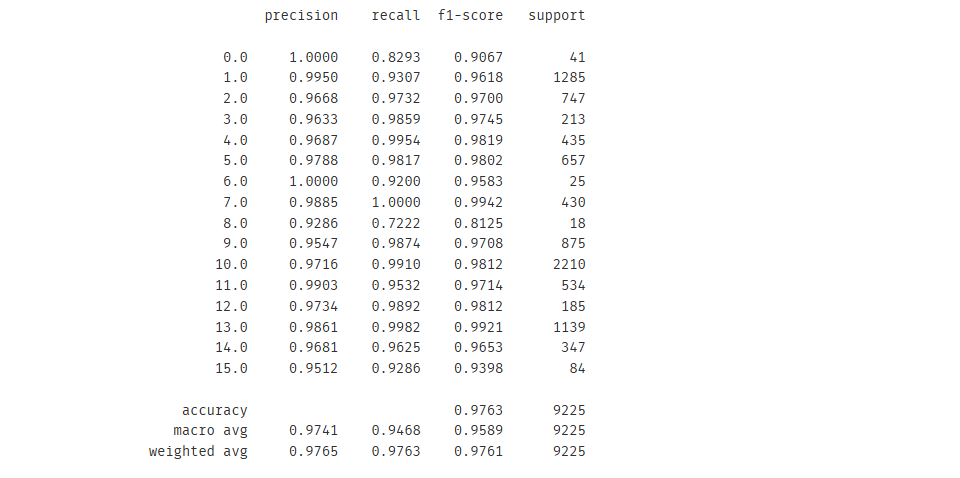
结果:
3D卷积核2D卷积还是有一定的区别的。
首先面对channel为1的2D卷积,一个卷积核就只对这一个通道的数据做卷积,每次得到一个值,从左到右从上到下依次卷积就得到了一张feature map;
然后是2D卷积中的多通道卷积,例如输入的channel=n,那么就有n个卷积核分别对n个channel的相同位置一起做上面的卷积,然后再相加得到一个值。
最后是3D卷积,这里实际上在channel=n时依然只有一个卷积核,不过这个卷积核是三维的,有自己长宽高,相应对应着每次卷几个通道的几个长几个宽,也有三个步长,分别对应着在channel上移动几个channel,在长上移动多少,宽上移动多少。
3、思考题
● 训练HybridSN,然后多测试⼏次,会发现每次分类的结果都不⼀样,请思考为什么?
我看了一些同学写的博客,很多博客一眼AI,纯答非所问。我认为这里主要是因为没有规范调用model.eval()函数,这个函数的作用很重要,就是进行测试时让dropout层不起作用,还可以让BN层对测试数据使用训练数据的均值和方差,这些都是非常重要的。
● 如果想要进⼀步提升⾼光谱图像的分类性能,可以如何改进?
在这里相当于只用到了卷积的操作,也许可以添加上之前学习的注意力机制和残差的操作
● depth-wise conv 和 分组卷积有什么区别与联系?
分组卷积是将channel分组,将分组后的每组channel分别卷积,当分组数量减小为1的时候,分组卷积就退化为了DW
● SENet 的注意⼒是不是可以加在空间位置上?
SENet的注意力是对每个channel求出一个权重,换句话说我认为只要有channel就可以使用SENet