2026版基于python大数据的电影分析可视化系统
博主介绍:高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
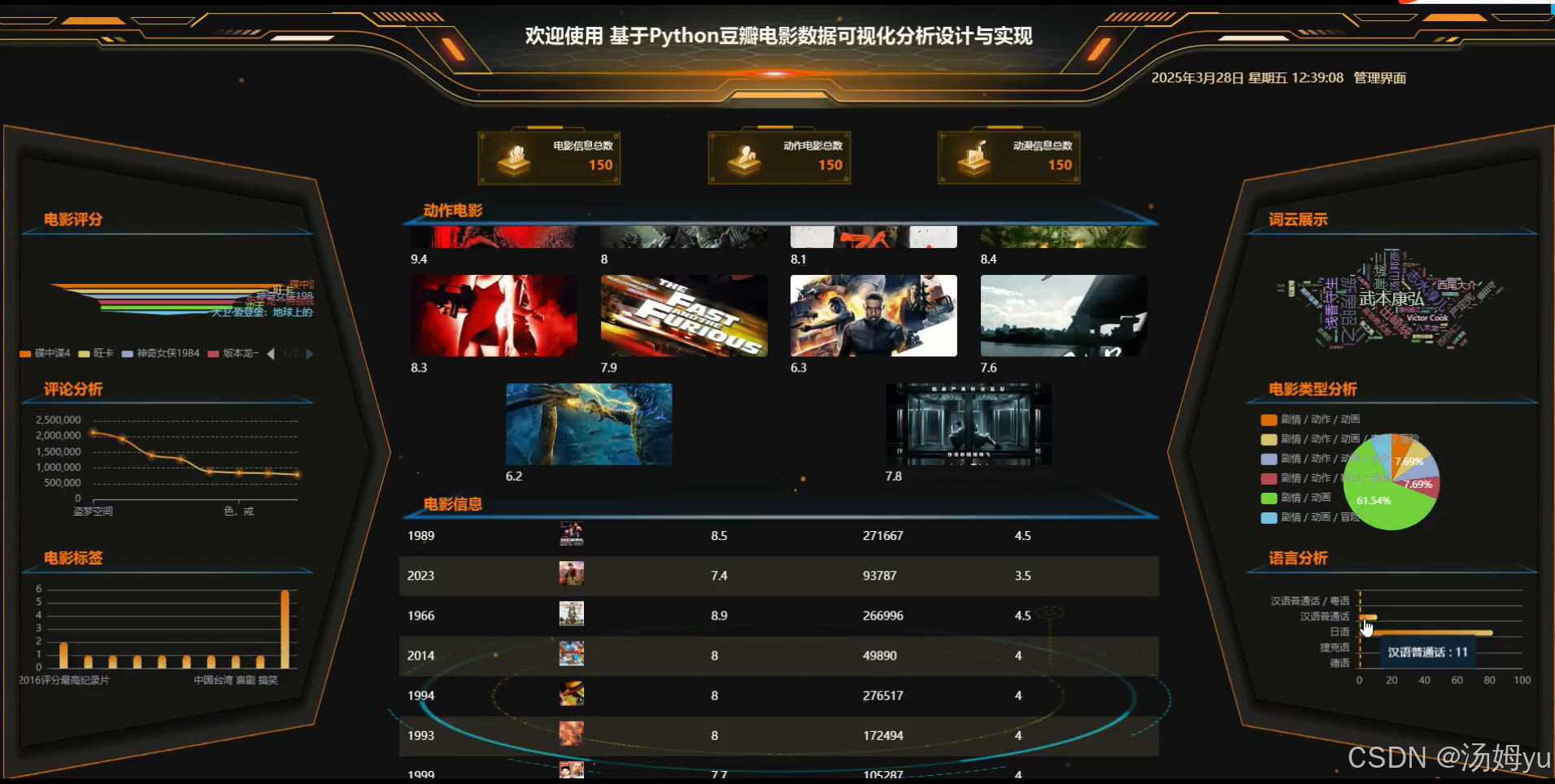
技术:python+mysql+vue+djiango
1、研究背景
在信息爆炸的当下,互联网中蕴藏着海量数据,电影领域亦不例外。豆瓣作为国内极具影响力的电影分享与评论平台,积累了丰富且多元的电影数据,涵盖电影基本信息、用户评分、评论以及各类标签等。这些数据宛如一座宝藏,蕴含着用户行为模式、电影市场走向、大众审美偏好等有价值的信息。然而,原始数据往往繁杂无序,如同未经雕琢的璞玉,难以直接发挥其作用
2、研究意义
本研究以豆瓣电影数据为应用对象,借助Python强大的编程能力,旨在搭建一套高效的数据可视化分析体系。一方面,通过Python爬虫技术,精准且全面地采集豆瓣电影相关数据,解决数据获取难题;另一方面,利用数据处理技术,对采集到的数据去粗取精、去伪存真,为后续分析筑牢根基。最后,运用数据可视化技术,将复杂抽象的数据转化为直观易懂的图表、图形等可视化形式。如此一来,无论是电影爱好者探寻优质影片,还是电影行业从业者制定创作、发行、营销策略,亦或是学术研究者开展相关理论探究,都能从这套分析体系中获取有力的数据支撑,切实解决在电影数据利用过程中数据挖掘难、分析难、理解难的问题
3、研究现状
在国外,电影数据分析与可视化研究起步较早且成果丰硕。众多学者借助Python等编程语言,结合机器学习、深度学习算法对电影数据展开深度挖掘。在数据采集上,运用先进爬虫技术,高效获取全球各大电影平台数据,突破地域限制。在可视化呈现方面,利用D3.js等前沿工具,打造出交互性强、视觉效果震撼的可视化作品,生动展现电影数据背后的复杂关系,如电影票房走势与多种影响因素间的动态关联。
国内相关研究近年来发展迅猛。研究者聚焦国内主流电影平台,如豆瓣,针对本土用户观影习惯、文化偏好等特点进行数据挖掘与分析。通过Python结合大数据处理框架,对海量评论数据进行情感分析,精准把握国内观众对电影的情感倾向。在可视化技术应用上,将Echarts等开源可视化库与国内用户使用习惯相结合,开发出简洁直观、符合国人审美的数据展示界面。
4、研究技术
4.1Python爬虫技术
Python爬虫技术的主要功能是模拟浏览器行为,自动从网页中提取所需数据。无论是静态网页还是动态加载网页,都能借助相应库实现数据抓取。在电影数据采集场景下,可针对豆瓣电影页面,精准获取电影名称、评分、评论等信息。其主要优势在于Python语言简洁易上手,拥有丰富的爬虫库,如Requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML和XML文档,极大降低开发难度与时间成本,能高效完成大规模数据采集任务。
4.2数据处理技术
数据处理技术旨在对采集到的原始数据进行清洗、转换和整合,使其符合分析要求。通过Pandas库可轻松实现数据去重、缺失值处理、数据类型转换等操作。在电影数据处理中,能清理掉重复电影条目、补充缺失评分,将不同格式的日期统一规范。其优势在于处理速度快、功能全面,对复杂数据结构兼容性强,可有效提高数据质量,为后续数据分析筑牢基础,确保分析结果的准确性与可靠性。
4.3数据可视化技术
数据可视化技术将抽象数据转化为直观的图表、图形等可视化形式,便于用户理解与分析。Matplotlib库能绘制折线图、柱状图、散点图等基础图表,Seaborn库基于Matplotlib进行了更高级的封装,使图表更美观。在电影数据分析场景中,可通过柱状图对比不同类型电影数量,用折线图展现电影评分随年份变化趋势。其优势在于直观呈现数据特征与趋势,降低理解数据难度,帮助用户快速洞察数据背后隐藏的信息,辅助决策制定。
5、系统实现