深度学习SE,CBAM,ECA,SimAM模块汇总之SE
常规卷积操作会对输入各个通道做卷积,然后对个通道的卷积结果进行求和,这种操作将卷积学习到的空间特征和通道特征混合在一起;而 SE 模块就是为了抽离这种混杂,让模型直接学习通道特征
一、什么是SE模块?
SE模块全称"Squeeze-and-Excitation"(压缩-激励)模块,是深度学习中的一种注意力机制,最早由Momenta公司(现并入商汤科技)在2017年提出。它的核心思想是让网络学会"关注"哪些通道(channel)的特征更重要。
想象一下你在看一幅画时,眼睛会不自觉地聚焦在重要的部分上,SE模块就是让神经网络具备这种"选择性注意"的能力。
二、SE模块的结构
SE模块非常简单但非常有效,主要由三个步骤组成:
- Squeeze(压缩):把全局空间信息压缩到一个通道描述符中
- Excitation(激励):学习通道间的依赖关系
- Scale(缩放):对原始特征图进行通道权重调整
用伪代码表示就是:
def SE_Module(input):# Squeeze: 全局平均池化squeeze = GlobalAvgPool2D(input)# Excitation: 两个全连接层形成瓶颈结构excitation = FC(relu(FC(squeeze)))# Scale: 对原始输入进行通道加权output = input * excitationreturn output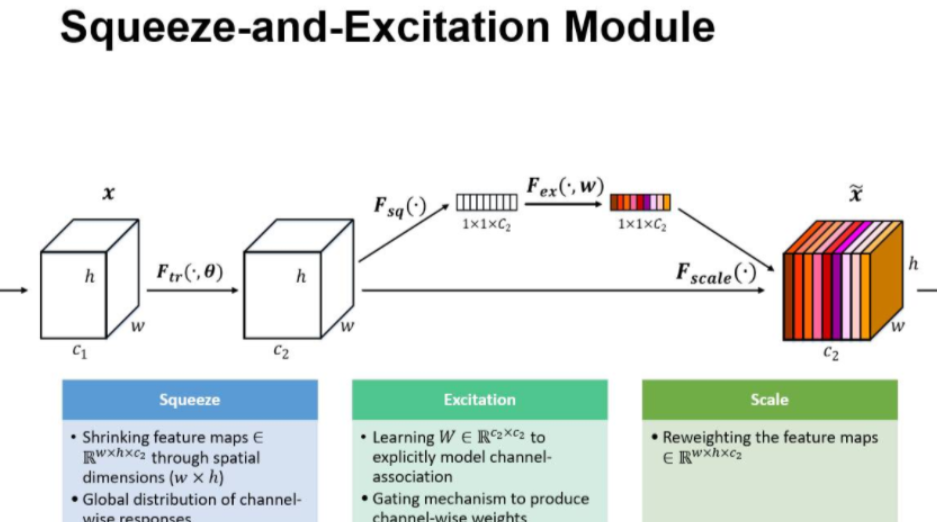
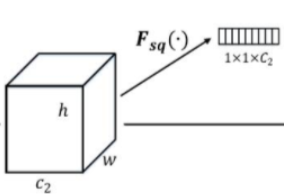
1. 压缩(squeeze )
由于卷积只是在局部空间内进行操作(没有全局感受野),很难获得做够的信息来提取 channel 之间的关系特征。 为了提取 channel 之间的关系,首先要将每个 channel 上的空间特征编码(压缩)为一个全局特征(可以理解为对每个 channel 的特征信息的进行融合),采用全局平局池化来实现,输出维度为1x1xC
2. 激励(Excitation)
通过bp获取通道权重
得到Squeeze的1x1xC全局特征后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。
3. Scale
最后是scale操作,在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
SE实现注意力机制原因:
SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合;
假设输入图像H×W×C,通过global pooling+FC层,拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。在去噪任务中,将每个噪声点赋予权重,自动去除低权重的噪声点,保留高权重噪声点,提高网络运行时间,减少参数计算。这也就是SE模块具有attention机制的原因