前端实现大文件上传全流程详解
在日常开发中,大文件上传是个绕不开的坎——动辄几百 MB 甚至 GB 级的文件,直接上传不仅容易超时,还会让用户体验大打折扣。最近我用 Vue+Express 实现了一套完整的大文件上传方案,支持分片上传、断点续传、秒传和手动中断,今天就带大家从头到尾盘清楚其中的技术细节。
一、先看效果:我们要实现什么?
先上核心功能清单,确保大家明确目标,知道我们要解决哪些实际问题:
- 「大文件分片上传」:将文件切成固定大小的小片段分批上传,避免单次请求超时
- 「秒传」:服务器已存在完整文件时,直接返回成功,无需重复上传
- 「断点续传」:刷新页面或上传中断后,仅上传未完成的分片,无需从头开始
- 「并发控制」:限制同时上传的分片数量,避免请求过多导致浏览器/ 服务器崩溃
- 「手动中断」:支持用户随时停止上传,且中断后已传分片不丢失
最终交互很简洁:一个文件选择框 + 上传中的中断按钮,但背后是一整套覆盖「上传前 - 上传中 - 上传后」的完整逻辑。
二、全流程拆解:从选文件到合并
我们先从宏观视角梳理整个流程,再拆分成前端和后端的具体实现。整个过程可总结为「5 步走」,每一步都有明确的目标和技术要点:
用户选择文件 → 前端分片+算哈希 → 校验文件状态(秒传/断点续传) → 并发上传分片 → 后端合并分片
第一步:用户选择文件(前端触发)
这是流程的起点,通过原生 input type=“file” 获取用户选择的文件,在 onchange 事件中触发后续逻辑。
<template> <div class="upload-container"> <h2>大文件上传演示</h2> <input @change="handleUpload" type="file" class="file-input" /> <!-- 上传中才显示中断按钮 -> <button @click="abortUpload" v-if="isUploading" class="abort-btn"> 中断上传 </button> </div>
</template>
<script setup>import { ref } from "vue";
// 上传状态管理
const isUploading = ref(false); // 是否正在上传
const abortControllers = ref([]); // 存储所有请求的中断控制器
const handleUpload = async (e) => {
const file = e.target.files[0];
// 获取用户选择的单个文件
if (!file) return; // 未选文件则退出// 后续核心逻辑:分片、算哈希、校验... // (下文逐步展开)
};
</script>
<style scoped>.upload-container { margin: 20px; }.file-input { margin-right: 10px; }.abort-btn { padding: 4px 8px; background: #ff4444; color: white; border: none; border-radius: 4px; }</style>
第二步:前端分片 + 计算文件哈希
大文件直接上传会触发超时,因此必须先「拆小」;而哈希值是实现「秒传」和「断点续传」的核心 —— 它是文件的唯一标识,用于告诉服务器 “这是哪个文件”。
2.1 文件分片:把大文件切成小片段
用浏览器原生 API File.slice() 按固定大小(这里设为 1MB)切割文件,得到多个 Blob 对象(即「分片」)。运行:
// 分片大小:1MB(可根据需求调整,如5MB/10MB)
const CHUNK_SIZE = 1024 * 1024;
/** * 生成文件分片数组 * @param {File} file - 用户选择的原始文件 * @returns {Blob[]} 分片数组 */
const createChunks = (file) => { let cur = 0; // 当前切割位置
let chunks = []; while (cur < file.size) {
// 从当前位置切割到「当前位置+分片大小」,最后一片可能不足1MB
const blob = file.slice(cur, cur + CHUNK_SIZE);
chunks.push(blob); cur += CHUNK_SIZE; } return chunks;
};
// 示例:3.5MB 的文件会生成 4 个分片(1MB+1MB+1MB+0.5MB)
2.2 计算文件哈希:生成唯一标识
用 spark-md5 库计算文件哈希,但有个关键优化:「不读取整个文件」,而是抽样读取部分片段(首尾分片全量 + 中间分片抽样),既能保证哈希唯一性,又能大幅提升大文件的计算速度。
先安装依赖:
npm install spark-md5 --save
再实现哈希计算逻辑:
import sparkMD5 from "spark-md5";
/*** 计算文件哈希值(抽样优化) *
@param {Blob[]} chunks - 分片数组 *
@returns {Promise<string>} 文件哈希值
*/
const calHash = (chunks) => { return new Promise((resolve) =>
{ const spark = new sparkMD5.ArrayBuffer(); // 初始化MD5计算器
const fileReader = new FileReader(); // 用于读取Blob内容
const targets = []; // 存放抽样的片段(用于计算哈希)// 抽样策略:首尾分片全量,中间分片取3个2字节片段(共6字节)
chunks.forEach((chunk, index) => { if (index === 0 || index === chunks.length - 1) { // 首尾分片:全量加入抽样
targets.push(chunk); } else { // 中间分片:取前2字节、中间2字节、后2字节
targets.push(chunk.slice(0, 2));
targets.push(chunk.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2)); targets.push(chunk.slice(CHUNK_SIZE - 2, CHUNK_SIZE)); }
});// 读取抽样片段并计算哈希 fileReader.readAsArrayBuffer(new Blob(targets)); fileReader.onload = (e) => { spark.append(e.target.result); // 累加数据 resolve(spark.end()); // 生成最终哈希值(如:"a1b2c3d4e5") }; }); };
「为什么抽样?」
如果是 1GB 的文件,全量读取计算哈希可能需要几秒甚至十几秒;抽样后仅读取几十字节,耗时可压缩到几百毫秒,用户几乎无感知。
第三步:校验文件状态(前后端配合)
拿到文件哈希后,前端需要先向后端发「校验请求」,判断两个关键信息:
1.服务器是否已存在完整文件?(决定是否秒传)
2.服务器是否有部分已上传的分片?(决定断点续传时要补传哪些分片)
3.1 前端发起校验请求
const fileHash = ref(""); // 文件哈希值
const fileName = ref(""); // 原始文件名(用于取后缀)
/** * 向服务器校验文件状态 * @returns {Promise<Object>} 校验结果(shouldUpload: 是否需要上传, existChunks: 已上传分片列表) */
const verify = async () => { const res = await fetch("http://localhost:3000/verify",
{
method: "POST",
headers: { "content-type": "application/json" },
body: JSON.stringify({fileHash: fileHash.value, fileName: fileName.value,}),
});
return res.json();};
// 在handleUpload中调用校验
const handleUpload = async (e) => {
const file = e.target.files[0];
if (!file) return;
fileName.value = file.name;
const chunks = createChunks(file);
fileHash.value = await calHash(chunks); // 计算哈希
// 发起校验
const verifyRes = await verify();
if (!verifyRes.data.shouldUpload) {
// 服务器已存在完整文件 → 秒传成功
alert("秒传成功!文件已存在"); return;
}
// 需上传:进入分片上传环节(下文展开)
await uploadChunks(chunks, verifyRes.data.existChunks);
};
3.2 后端处理校验逻辑
后端需要检查「完整文件」和「已上传分片」的存在性,返回给前端决策依据。先初始化后端项目并安装依赖: # 1. 初始化 npm init -y
# 2. 安装依赖
npm install express cors multiparty fs-extra path --save
再实现 /verify 接口:
const express = require("express");
const path = require("path");
const fse = require("fs-extra"); // 文件操作工具(比原生fs更易用)
const cors = require("cors");
const bodyParser = require("body-parser");
const app = express();app.use(cors()); // 解决跨域app.use(bodyParser.json());
// 解析JSON请求体
// 上传根目录(所有分片和完整文件都存在这里)
const UPLOAD_DIR = path.resolve(__dirname, "uploads");
// 确保上传目录存在
fse.ensureDirSync(UPLOAD_DIR);
/** * 提取文件名后缀(如:"test.pdf" → ".pdf") * @param {string} fileName - 原始文件名 * @returns {string} 文件后缀 */
const extractExt = (fileName) => {
return fileName.slice(fileName.lastIndexOf("."));
};
// 校验接口:/verify
app.post("/verify", async (req, res) => {
const { fileHash, fileName } = req.body;
// 完整文件路径 = 上传目录 + 文件哈希 + 原文件后缀(确保文件名唯一)
const completeFilePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`);// 1. 检查完整文件是否存在 → 秒传逻辑 if (fse.existsSync(completeFilePath)) { return res.json({ status: true, data: { shouldUpload: false } // 无需上传 }); }// 2. 检查已上传的分片 → 断点续传逻辑 const chunkDir = path.resolve(UPLOAD_DIR, fileHash); // 分片临时目录(用文件哈希命名) const existChunks = fse.existsSync(chunkDir) ? await fse.readdir(chunkDir) // 已上传的分片列表(如:["a1b2-0", "a1b2-1"]) : [];res.json({ status: true, data: { shouldUpload: true, // 需要上传 existChunks: existChunks // 已上传的分片标识,供前端过滤 } });});
// 启动服务器
app.listen(3000, () => { console.log("服务器运行在 http://localhost:3000");
});
第四步:并发上传分片(前端核心)
这是前端最复杂的环节,需要解决三个关键问题:
1.过滤已上传的分片(只传缺失的)
2.控制并发请求数(避免请求爆炸)
3.支持手动中断上传(用户可随时停止)
4.1 过滤已上传的分片
根据后端返回的 existChunks(已上传分片标识列表),过滤掉不需要重新上传的分片,只生成待上传的 FormData。
/** * 上传分片(核心函数) * @param {Blob[]} chunks - 所有分片数组 * @param {string[]} existChunks - 已上传的分片标识列表 */
const uploadChunks = async (chunks, existChunks) => {
isUploading.value = true; abortControllers.value = [];
// 清空历史中断控制器
// 1. 生成所有分片的基础信息(文件哈希、分片标识、分片数据)
const chunkInfoList = chunks.map((chunk, index) => ({ fileHash: fileHash.value, chunkHash: `${fileHash.value}-${index}`,
// 分片标识:文件哈希-序号(确保唯一)
chunk: chunk }));// 2. 过滤已上传的分片 → 只保留待上传的 const formDatas = chunkInfoList .filter(item => !existChunks.includes(item.chunkHash)) .map(item => { const formData = new FormData(); formData.append("filehash", item.fileHash); formData.append("chunkhash", item.chunkHash); formData.append("chunk", item.chunk); // 分片二进制数据 return formData; });if (formDatas.length === 0) { // 所有分片已上传 → 直接请求合并 mergeRequest(); return; }// 3. 并发上传分片(下文展开) await uploadWithConcurrencyControl(formDatas);};
4.2 控制并发请求数
用「请求池 + Promise.race」限制同时上传的分片数量(这里设为 6 个),避免请求过多导致浏览器 / 服务器压力过大。
/** * 带并发控制的分片上传 * @param {FormData[]} formDatas - 待上传的FormData列表 */
const uploadWithConcurrencyControl = async (formDatas) => { const MAX_CONCURRENT = 6;
// 最大并发数(可根据需求调整)
let currentIndex = 0; // 当前待上传的分片索引
const taskPool = []; // 存储当前正在执行的请求(请求池)while (currentIndex < formDatas.length) { // 为每个请求创建独立的中断控制器(AbortController) const controller = new AbortController(); const { signal } = controller; abortControllers.value.push(controller); // 存入控制器列表// 发起分片上传请求 const task = fetch("http://localhost:3000/upload", { method: "POST", body: formDatas[currentIndex], signal: signal // 绑定中断信号 }) .then(res => { // 请求完成后,从请求池和控制器列表中移除 taskPool.splice(taskPool.indexOf(task), 1); abortControllers.value = abortControllers.value.filter(c => c !== controller); return res; }) .catch(err => { // 捕获错误:区分「用户中断」和「其他错误」 if (err.name !== "AbortError") { console.error("分片上传失败:", err); // 可在这里加「错误重试」逻辑(如重试3次) } // 无论何种错误,都清理状态 taskPool.splice(taskPool.indexOf(task), 1); abortControllers.value = abortControllers.value.filter(c => c !== controller); });taskPool.push(task);// 当请求池满了,等待最快完成的一个请求再继续(释放并发名额) if (taskPool.length === MAX_CONCURRENT) { await Promise.race(taskPool); }currentIndex++; }// 等待所有剩余请求完成 await Promise.all(taskPool); // 所有分片上传完成 → 请求合并 mergeRequest();};
4.3 手动中断上传
用 AbortController 中断所有正在进行的请求,并清理状态,确保中断后下次上传能正常恢复。
/** * 中断上传(用户触发) */
const abortUpload = () => { if (!isUploading.value) return;// 1. 中断所有正在进行的请求 abortControllers.value.forEach(controller => { controller.abort(); // 调用中断方法,触发请求的AbortError });// 2. 清理状态 abortControllers.value = []; isUploading.value = false;// 3. 通知用户 alert("上传已中断,下次可继续上传");};
第五步:后端接收分片并合并
所有分片上传完成后,前端需要通知后端「合并分片」,后端按分片序号排序,用「流(Stream)」拼接成完整文件(避免内存溢出)。
5.1 后端接收分片(/upload 接口)
用 multiparty 解析前端发送的 FormData,将分片保存到临时目录(以文件哈希命名)。
// 后端:/upload 接口(接收分片)
const multiparty = require("multiparty");
app.post("/upload", (req, res) => {
const form = new multiparty.Form(); // 解析FormData的工具// 解析请求(fields:普通字段,files:文件字段) form.parse(req, async (err, fields, files) => { if (err) { console.error("分片解析失败:", err); return res.status(400).json({ status: false, message: "分片上传失败" }); }// 提取字段 const fileHash = fields["filehash"][0]; // 文件哈希 const chunkHash = fields["chunkhash"][0]; // 分片标识 const chunkFile = files["chunk"][0]; // 分片临时文件(multiparty生成的临时文件)// 分片临时目录(如:uploads/a1b2c3) const chunkDir = path.resolve(UPLOAD_DIR, fileHash); // 确保临时目录存在 await fse.ensureDir(chunkDir);// 目标路径:将分片从临时位置移动到临时目录 const targetChunkPath = path.resolve(chunkDir, chunkHash); await fse.move(chunkFile.path, targetChunkPath);// 响应前端:分片上传成功 res.json({ status: true, message: "分片上传成功" }); });});
5.2 后端合并分片(/merge 接口)
合并的核心是「按序号排序分片」+「用流拼接」,边读边写,避免一次性加载大文件到内存。
// 前端:请求合并分片的函数
const mergeRequest = async () => { await fetch("http://localhost:3000/merge", { method: "POST", headers: { "content-type": "application/json" }, body: JSON.stringify({ fileHash: fileHash.value, fileName: fileName.value, size: CHUNK_SIZE // 分片大小(用于计算写入位置)
}),
});// 合并完成后的清理 isUploading.value = false; alert("文件上传完成!");};
// 后端:/merge 接口(合并分片)
app.post("/merge", async (req, res) => { const { fileHash, fileName, size: CHUNK_SIZE } = req.body; // 完整文件路径(上传目录 + 文件哈希 + 后缀)
const completeFilePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`);
// 分片临时目录
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);// 检查分片目录是否存在(防止恶意请求) if (!fse.existsSync(chunkDir)) { return res.status(400).json({ status: false, message: "分片目录不存在" }); }// 1. 读取所有分片并按序号排序 const chunkPaths = await fse.readdir(chunkDir); chunkPaths.sort((a, b) => { // 从分片标识中提取序号(如:"a1b2-0" → 0) return parseInt(a.split("-")[1]) - parseInt(b.split("-")[1]); });// 2. 用流拼接分片(边读边写,低内存占用) const mergePromises = chunkPaths.map((chunkName, index) => { return new Promise((resolve) => { const chunkPath = path.resolve(chunkDir, chunkName); const readStream = fse.createReadStream(chunkPath); // 分片读流 const writeStream = fse.createWriteStream(completeFilePath, { start: index * CHUNK_SIZE, // 写入起始位置(精确到字节) end: (index + 1) * CHUNK_SIZE // 写入结束位置 });// 分片读取完成后:删除分片文件 + resolve readStream.on("end", async () => { await fse.unlink(chunkPath);// 删除单个分片 resolve(); });// 管道流:将分片内容写入完整文件 readStream.pipe(writeStream); }); });// 3. 等待所有分片合并完成 await Promise.all(mergePromises); // 4. 删除分片临时目录(合并完成后清理) await fse.remove(chunkDir);// 响应前端:合并成功 res.json({ status: true, message: "文件合并成功" });});
「为什么用流?」
如果直接用 fs.readFile 读取所有分片内容再拼接,1GB 的文件会占用 1GB 内存,可能导致服务器内存溢出;而流操作(createReadStream/createWriteStream)是边读边写,内存占用始终很低(仅几 KB/MB)。
三、核心难点与解决方案总结
大文件上传的核心痛点已在方案中解决,这里整理成表格,方便大家快速回顾:
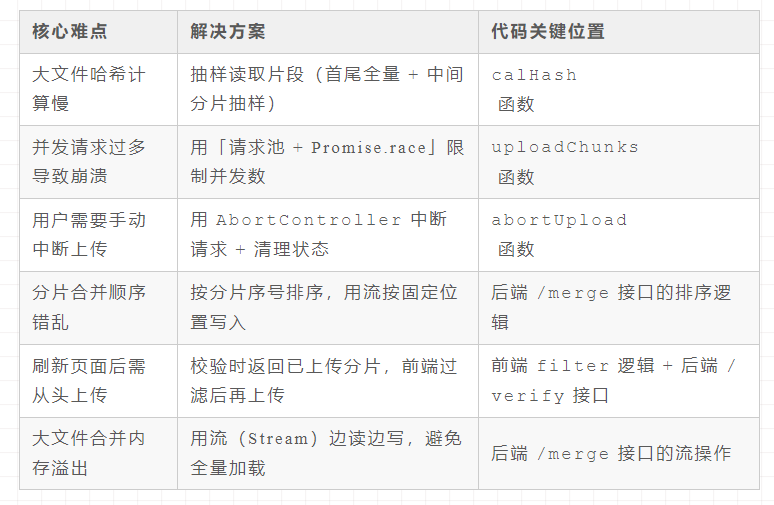
四、最后
大文件上传看似复杂,拆解后其实是「分片→校验→上传→合并」四个核心步骤,每个步骤解决一个具体问题。这套方案用 Vue+Express 实现,代码简洁易懂,可直接作为项目基础版本,再根据实际需求扩展优化。实际开发中,还需要结合业务场景补充异常处理(如文件大小限制、格式校验)、日志监控(上传失败告警)等功能。如果大家在实践中遇到问题,欢迎在评论区交流。