【优先级队列(堆)】3.前 K 个⾼频单词 (medium)
优先级队列(堆)
- 3.前 K 个⾼频单词 (medium)
- 题⽬描述:
- 解法(堆):
- 算法思路:
- 算法代码:
3.前 K 个⾼频单词 (medium)
题⽬链接:692. 前 K 个⾼频单词
题⽬描述:
给定⼀个单词列表 words 和⼀个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由⾼到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
⽰例 1:
输⼊:
words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出:
[“i”, “love”]
解析:
“i” 和 “love” 为出现次数最多的两个单词,均为 2 次。
注意,按字⺟顺序 “i” 在 “love” 之前。
⽰例 2:
输⼊:
[“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出:
[“the”, “is”, “sunny”, “day”]
解析:
“the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。
注意:
1 <= words.length <= 500
1 <= words[i] <= 10
words[i] 由⼩写英⽂字⺟组成。
k 的取值范围是 [1, 不同 words[i] 的数量]
进阶:尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
解法(堆):
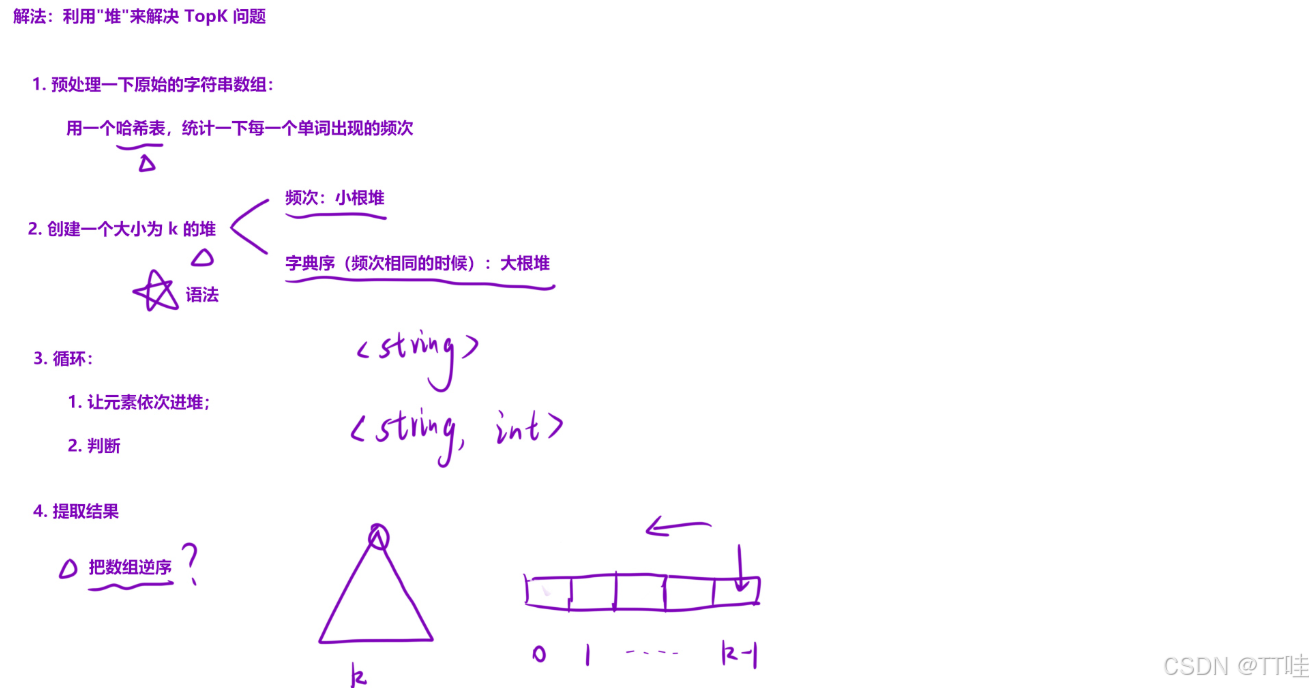
算法思路:
• 稍微处理⼀下原数组:
a. 我们需要知道每⼀个单词出现的频次,因此可以先使⽤哈希表,统计出每⼀个单词出现的频次;
b. 然后在哈希表中,选出前 k ⼤的单词(为什么不在原数组中选呢?因为原数组中存在重复的单词,哈希表⾥⾯没有重复单词,并且还有每⼀个单词出现的频次)
• 如何使⽤堆,拿出前 k ⼤元素:
a. 先定义⼀个⾃定义排序,我们需要的是前 k ⼤,因此需要⼀个⼩根堆。但是当两个字符串的频次相同的时候,我们需要的是字典序较⼩的,此时是⼀个⼤根堆的属性,在定义⽐较器的时候需要注意!
▪ 当两个字符串出现的频次不同的时候:需要的是基于频次⽐较的⼩根堆
▪ 当两个字符串出现的频次相同的时候:需要的是基于字典序⽐较的⼤根堆
b. 定义好⽐较器之后,依次将哈希表中的字符串插⼊到堆中,维持堆中的元素不超过 k 个;
c. 遍历完整个哈希表后,堆中的剩余元素就是前 k ⼤的元素
算法代码:
class Solution
{public List<String> topKFrequent(String[] words, int k) {// 1. 统计⼀下每⼀个单词出现的频次Map<String, Integer> hash = new HashMap<>();for(String s : words){hash.put(s, hash.getOrDefault(s, 0) + 1);}// 2. 创建⼀个⼤⼩为 k 的堆PriorityQueue<Pair<String, Integer>> heap = new PriorityQueue<>((a, b) ->{if(a.getValue().equals(b.getValue())) // 频次相同的时候,字典序按照⼤根堆的⽅式排列{return b.getKey().compareTo(a.getKey());}return a.getValue() - b.getValue();});// 3. TopK 的主逻辑for(Map.Entry<String, Integer> e : hash.entrySet()){heap.offer(new Pair<>(e.getKey(), e.getValue()));if(heap.size() > k){heap.poll();}}// 4. 提取结果List<String> ret = new ArrayList<>();while(!heap.isEmpty()){ret.add(heap.poll().getKey());}// 逆序数组Collections.reverse(ret);return ret;}
}