Redis的有序集合的底层实现
在Redis的五大核心数据类型中,有序集合(Sorted Set,简称ZSet)凭借“元素有序且可按分数排序”的特性,成为实现排行榜、延迟队列、范围统计等场景的利器。比如电商平台的“销量排行榜”、直播平台的“礼物贡献榜”,都能通过ZSet的ZREVRANGE、ZSCORE等命令轻松实现。
但你是否好奇:同样是ZSet,存储10个元素和10万个元素时,Redis的底层实现是否一致?答案是否定的。为了兼顾内存效率和操作性能,Redis为ZSet设计了“双编码”架构——小数据量用ziplist(压缩列表)紧凑存储,大数据量用skiplist(跳表)+dict(哈希表)协同保障性能。本文将从底层结构、转换规则、性能对比到实践建议,全方位拆解ZSet的实现逻辑,揭秘其“小数据省内存、大数据高性能”的底层密码。
一、核心问题:为何ZSet需要两种编码方式?
ZSet的核心诉求有两个:按分数有序排列(支持范围查询)和快速获取单个元素分数(支持单点查询)。若仅用一种编码方式,会陷入“内存”与“性能”的两难:
- 仅用ziplist:内存紧凑,但范围查询和单点查询都需遍历整个列表,时间复杂度O(n),数据量增大后性能急剧下降;
- 仅用skiplist+dict:性能优异,但跳表的索引和哈希表的结构会带来大量内存开销,存储少量数据时性价比极低。
因此,Redis采用“动态编码切换”策略:根据元素数量和长度自动选择编码方式,既保证小数据场景的内存效率,又兼顾大数据场景的高性能。
二、ziplist编码:小数据场景的“内存王者”
当ZSet的元素数量少、成员长度短时,Redis会优先使用ziplist编码。ziplist是Redis专为“小数据紧凑存储”设计的连续内存结构,并非传统链表,能最大限度节省内存。
2.1 底层结构:连续内存的有序排列
ziplist 是一块连续的内存空间,按以下格式存储数据:

每个 entry 存储一个成员(member)和分数(score),格式为:
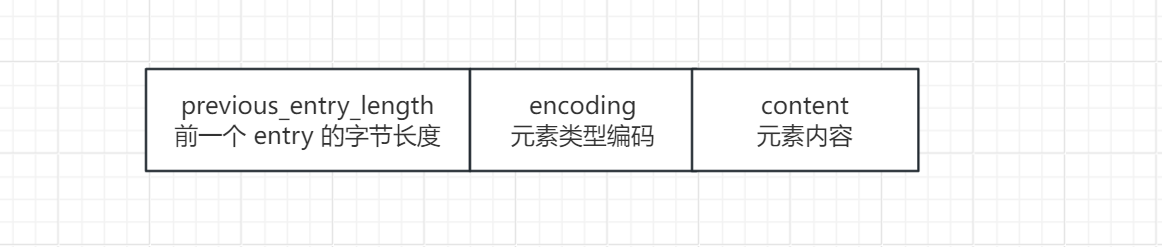
其中score 以 double 类型存储,member 以字符串形式存储。所有 entry 按 score 从小到大排列,score 相同时按 member 字典序排列。
每个entry的结构包含“长度信息+编码类型+实际数据”三部分,无需像链表那样用指针连接节点,彻底消除了指针开销。例如存储ZSet ZADD rank 80 "张三" 90 "李四"时,ziplist的内存布局如下(简化):
[表头信息] → [分数80] → [成员"张三"] → [分数90] → [成员"李四"] → [表尾标记]
2.2 核心优势:极致的内存利用率
ziplist编码的核心竞争力在于“内存紧凑”,具体体现在两点:
- 无冗余开销:连续内存存储,无指针、索引等冗余结构,内存利用率远超跳表+dict组合。实测显示,存储100个短元素的ZSet,ziplist的内存占用仅为跳表+dict的1/5~1/3;
- 缓存友好:连续的内存布局能提升CPU缓存命中率,读取数据时可一次性将多个元素加载到缓存中,小数据量下的读取性能甚至优于跳表。
2.3 致命缺陷:性能随数据量增长而退化
ziplist的连续内存结构也是一把双刃剑,带来了无法回避的性能缺陷,尤其在数据量较大或频繁修改时:
- 查询性能差:无论是范围查询(如
ZRANGE)还是单点查询(如ZSCORE),都需从ziplist头部开始遍历,时间复杂度为O(n)。当元素数量超过100个时,查询延迟会明显增加; - 插入/删除效率低:由于内存连续,插入或删除元素时需移动后续所有数据以维持有序性,时间复杂度同样为O(n)。例如在1000个元素的中间位置插入一个元素,需移动后续999个元素,耗时显著。
2.4 触发条件与适用场景
Redis通过两个配置参数控制ziplist编码的触发(默认值适用于大多数场景,可根据业务调整):
zset-max-ziplist-entries:ZSet的元素数量≤128个;zset-max-ziplist-value:每个成员的字符串长度≤64字节。
适用场景:小数据集、低修改频率的有序场景,例如:
- 小型班级的成绩排名:
ZADD class_rank 95 "小明" 92 "小红" ...(元素数≤50,成员为姓名短字符串); - 小型活动的投票榜单:
ZADD vote_rank 120 "选手A" 105 "选手B" ...(投票期间修改频率低,元素数少)。
三、skiplist+dict编码:大数据场景的“性能王者”
当ZSet的元素数量过多或成员长度过长时,ziplist的性能缺陷会被无限放大。此时Redis会自动切换为“skiplist+dict”的组合编码,通过两种结构的协同,同时满足“有序排列”和“快速查询”的核心诉求。
3.1 整体架构:跳表与哈希表的分工协作
ZSet的组合编码核心是“分工明确、优势互补”:跳表负责维护元素的有序性以支持范围查询,哈希表负责建立“成员→分数”的映射以支持单点查询。其底层结构定义如下(基于Redis源码简化):
// ZSet的核心结构:跳表+哈希表
typedef struct zset {dict *dict; // 哈希表:存储 member → score 的映射,支持O(1)单点查询zskiplist *zsl; // 跳表:按 score 排序存储 (member, score),支持范围查询
} zset;这种架构的优势在于:两种结构共享元素数据(并非复制),既避免了数据冗余,又同时具备跳表和哈希表的高性能特性。例如执行ZSCORE rank "张三"时,直接通过哈希表查询,耗时O(1);执行ZREVRANGE rank 0 9(获取Top10)时,通过跳表快速定位范围,耗时O(log n + 10)。
3.2 跳表:有序性与范围查询的核心
跳表(Skiplist)是一种“基于概率的有序数据结构”,通过建立多层索引,将链表的查询性能从O(n)提升到O(log n),同时支持高效的插入和删除操作。Redis的跳表设计堪称经典,我们从结构、层数生成、核心操作三方面解析。
3.2.1 跳表的核心结构
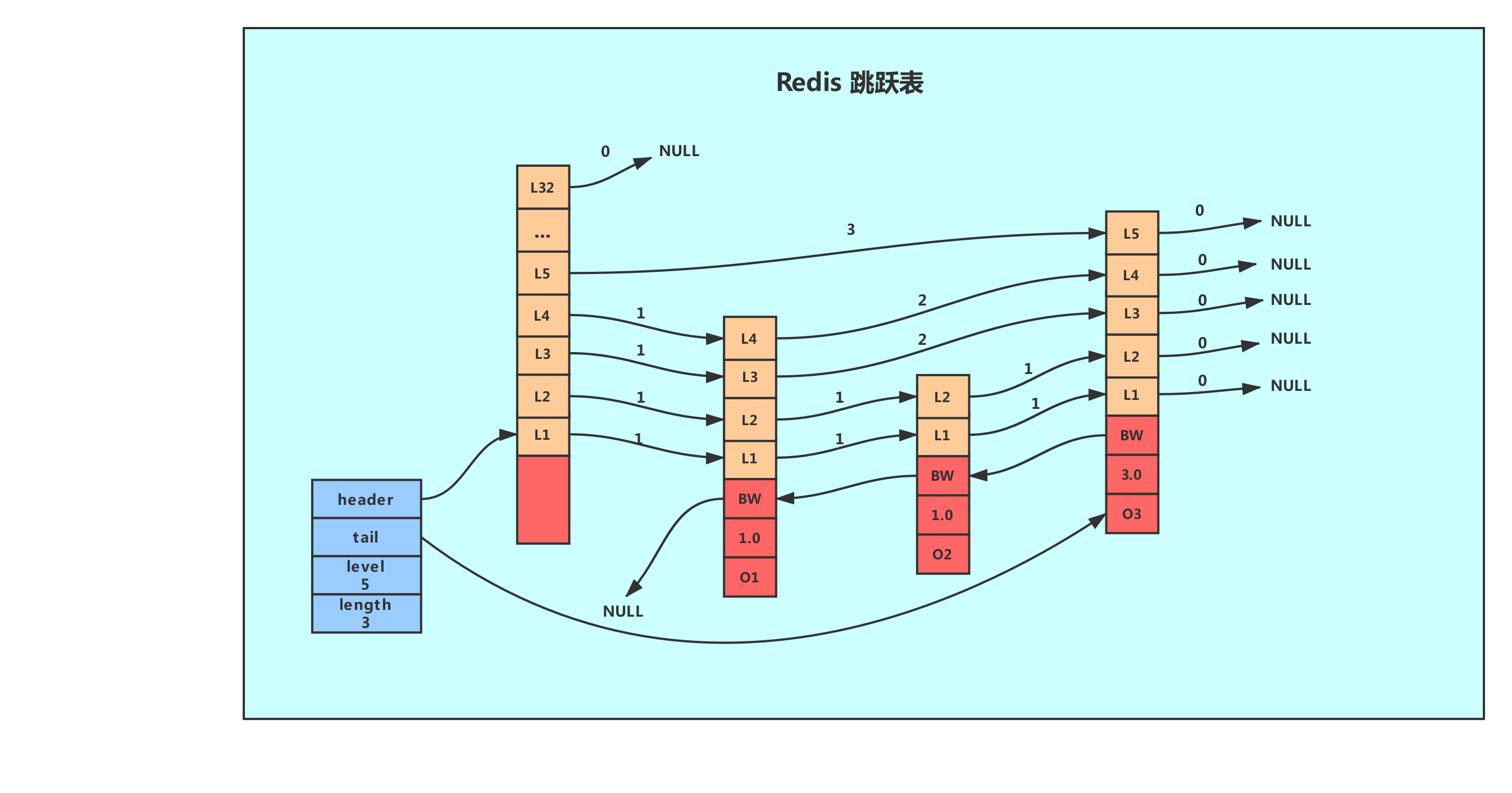
Redis的跳表由zskiplist(跳表整体控制)和zskiplistNode(跳表节点)组成,结构定义如下(简化):
// 跳表节点结构
typedef struct zskiplistNode {sds ele; // 成员(字符串)double score; // 分数(排序依据)struct zskiplistNode *backward; // 后退指针(实现双向遍历)struct zskiplistLevel { // 多层索引struct zskiplistNode *forward; // 前进指针unsigned long span; // 跨度(当前节点到下一跳节点的元素个数,用于计算排名)} level[]; // 柔性数组,存储不同层级的索引
} zskiplistNode;// 跳表整体控制结构
typedef struct zskiplist {struct zskiplistNode *header, *tail; // 表头、表尾节点unsigned long length; // 元素总数int level; // 跳表的最大层数
} zskiplist;关键设计细节:
- 多层索引:每个节点有多个层级的索引,高层索引用于快速定位范围,低层索引用于精确查找;
- 跨度(span):前进指针对应的跨度值,可快速计算节点的排名(如
ZRANK命令),无需遍历计数; - 后退指针:实现从表尾到表头的反向遍历,方便范围查询(如
ZREVRANGE)。
3.2.2 层数的随机生成:跳表性能的关键
跳表的性能依赖于“索引层级的合理分布”——高层索引节点稀疏,低层索引节点密集,类似二分查找的逻辑。Redis通过zslRandomLevel函数随机生成节点层数,保证索引分布的合理性:
#define ZSKIPLIST_MAXLEVEL 64 // 跳表最大层数(足够支撑2^64个元素)
#define ZSKIPLIST_P 0.25 // 层数增加的概率(25%)int zslRandomLevel(void) {int level = 1; // 基础层数为1// 随机数小于25%时,层数加1(最多到64层)while ((random() & 0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}这一设计的巧妙之处在于:
- 每层索引的节点数量约为下一层的1/4(因增加层数的概率为25%),保证了查询时的“二分”效率;
- 最大层数限制为64层,即使元素达到2^64个,也能通过64次比较完成查询,性能稳定。
3.2.3 跳表的核心操作:查询与插入
查询操作(如获取排名第k的元素):从最高层索引开始,通过前进指针快速跨越无效节点,逐步下探到低层索引,最终定位到目标节点,时间复杂度O(log n)。
插入操作:先通过查询逻辑找到插入位置,再创建新节点并随机生成层数,最后更新各层索引的前进指针和跨度值,时间复杂度O(log n)。
3.3 哈希表:单点查询的“加速器”
ZSet中的哈希表与之前Hash类型的哈希表结构完全一致,核心作用是建立“成员→分数”的映射,支持O(1)时间复杂度的单点操作,例如:
ZSCORE rank "张三":直接通过哈希表的key(“张三”)获取value(分数),耗时O(1);ZINCRBY rank 5 "张三":先通过哈希表找到“张三”的分数并更新,再同步更新跳表中的分数和排序,保证数据一致性。
需要注意的是,哈希表和跳表中的成员数据是共享的,并非独立存储,因此不会产生数据冗余。
3.4 触发条件与适用场景
当满足以下任一条件时,Redis会自动将ZSet的编码从ziplist转为skiplist+dict:
- ZSet的元素数量超过
zset-max-ziplist-entries(默认128); - 任意一个成员的字符串长度超过
zset-max-ziplist-value(默认64字节)。
适用场景:大数据集、高频修改或复杂查询的有序场景,例如:
- 全平台商品销量排行榜:
ZADD sales_rank 1000 "商品A" 800 "商品B" ...(元素数过万,需频繁更新销量并查询Top10); - 用户积分排行榜:
ZADD user_score 5000 "用户1001" 4500 "用户1002" ...(元素数过十万,需支持积分实时更新和范围查询)。
四、编码转换与核心对比
4.1 编码转换规则
Redis的ZSet编码转换是“单向不可逆”的:
- ziplist → skiplist+dict:当元素数量或成员长度超过阈值时,自动触发转换,转换过程是创建新的跳表和哈希表,将ziplist中的元素逐个迁移过去;
- skiplist+dict → ziplist:一旦转为组合编码,即使后续删除元素使数据量降至阈值以下,也不会自动转回ziplist(需手动删除ZSet后重新创建才能触发ziplist编码)。
4.2 两种编码核心对比
为了更清晰地展示两种编码的差异,我们从核心特性、性能、适用场景等维度进行对比:
特性 | ziplist(压缩列表) | skiplist+dict(跳表+哈希表) |
内存占用 | 低(连续紧凑,无冗余开销) | 高(跳表索引+哈希表结构) |
单点查询性能 | O(n)(遍历查找) | O(1)(哈希表直接查询) |
范围查询性能 | O(n)(遍历筛选) | O(log n + m)(跳表定位+取m个元素) |
插入/删除性能 | O(n)(需移动数据) | O(log n)(跳表操作+哈希表同步) |
适用场景 | 小数据集、低修改频率 | 大数据集、高频修改或复杂查询 |
五、总结
Redis ZSet的两种编码实现,是“因地制宜”优化思想的又一经典体现——ziplist以“紧凑存储”为核心,解决小数据场景的内存浪费问题;skiplist+dict以“协同高效”为核心,解决大数据场景的性能瓶颈问题。两者的动态切换,让ZSet在不同场景下都能实现内存与性能的最佳平衡。