whisper 模型处理音频办法与启示
文章目录
- 一、核心目标:先解决“音频长度不一致”问题
- 1.1 音频预处理:标准化输入长度的3个关键步骤
- 二、梅尔频谱图:从“原始音频”到“模型可理解特征”的关键转换
- 2.1 梅尔频谱图的提取参数与计算逻辑
- 2.2 梅尔频谱图的最终形状(30秒音频为例)
- 三、特征归一化:确保输入分布一致性
- 四、CNN处理:梅尔频谱图的“局部特征提取与下采样”
- 4.1 CNN Stem的具体结构
- 4.2 CNN处理后的特征形状变化(以Large模型为例)
- 五、整体流程总结:从音频到模型输入的完整链路
- 关键设计的核心原因
- 1. 输入:梅尔频谱图的格式
- 2. 音频编码器中的一维卷积层
- 3. 卷积层的前向计算流程
- 4. 一维卷积的核心作用
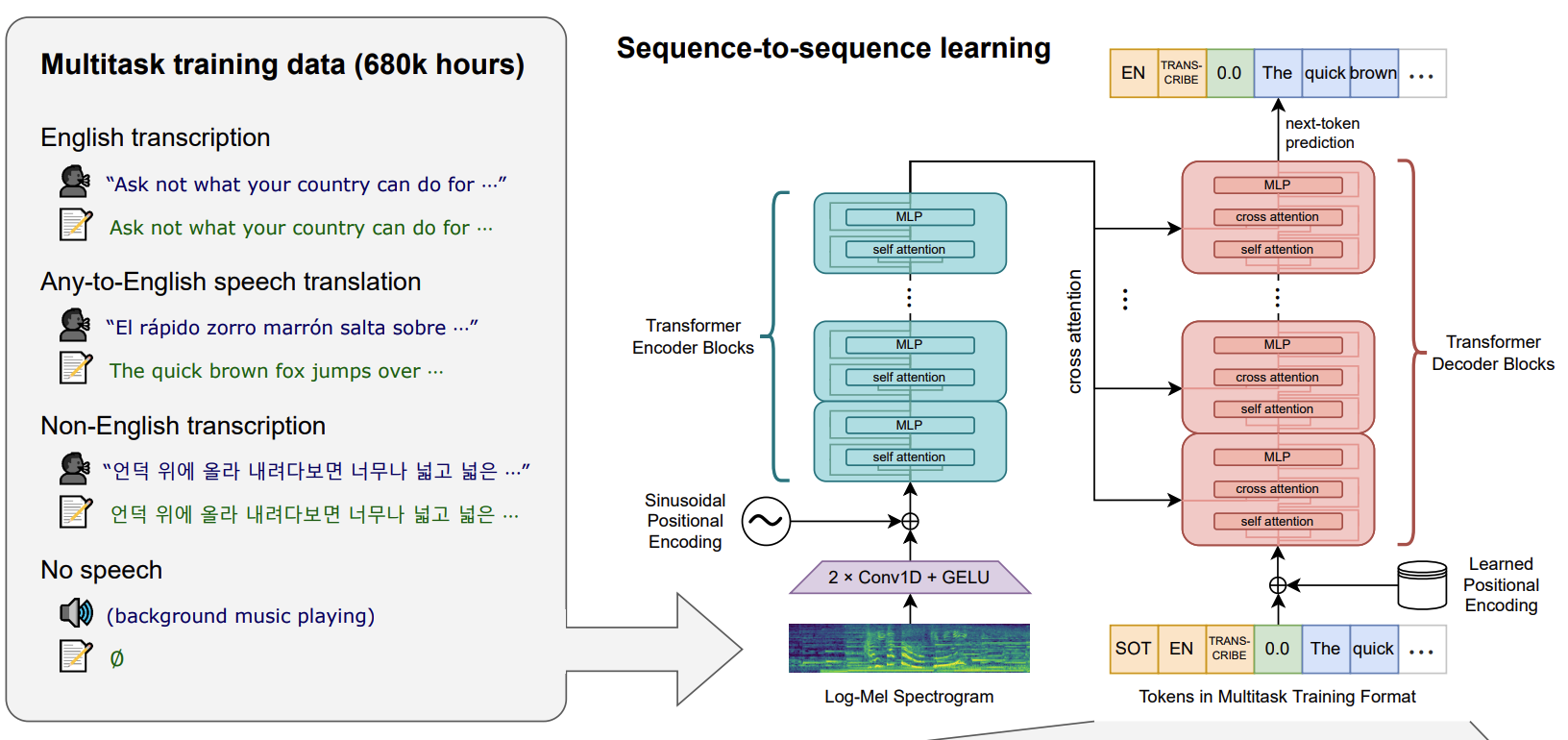
要理解Whisper模型的音频处理流程、输入细节(尤其是梅尔频谱图)、CNN处理逻辑及音频长度不一致的解决方案,需结合文档中「2. Approach」章节的「2.1 Data Processing」和「2.2 Model」部分,按“预处理→特征提取→特征归一化→CNN编码→长度统一”的逻辑拆解,以下是详细解析:
Robust Speech Recognition via Large-Scale Weak Supervision
https://arxiv.org/pdf/2212.04356
一、核心目标:先解决“音频长度不一致”问题
音频数据的天然痛点是长度差异极大(从几秒的短句到几小时的长音频),Whisper通过「预处理阶段的固定长度分段」从源头解决该问题,为后续特征提取和模型输入统一奠定基础。
1.1 音频预处理:标准化输入长度的3个关键步骤
Whisper采用“极简预处理”思路,核心是将所有音频转化为固定30秒的片段,具体操作如下:
-
步骤1:统一采样率
所有输入音频先被重采样到16kHz单声道。- 原因:不同音频的原始采样率(如8kHz、44.1kHz)会导致“相同时间长度对应不同样本数”,重采样到16kHz后,30秒音频的总样本数固定为
16000 Hz × 30 s = 480000 个样本,确保时间维度的“单位一致性”。
- 原因:不同音频的原始采样率(如8kHz、44.1kHz)会导致“相同时间长度对应不同样本数”,重采样到16kHz后,30秒音频的总样本数固定为
-
步骤2:强制分段为30秒
无论原始音频长度是几秒还是几小时,均被切割为30秒的连续片段,并为每个片段匹配对应时间段的转录文本(如30秒片段对应该时间段内的文字)。- 特殊情况:若音频末尾不足30秒,仍保留为一个片段(但文档未提及补零,推测通过“时间戳对齐”确保转录文本与片段匹配);若音频无语音(如纯背景音),也保留为30秒片段(用于训练语音活动检测VAD)。
- 作用:这是解决“音频长度不一致”的核心手段——所有输入模型的音频片段长度统一为30秒,后续特征提取和模型输入形状完全固定。
-
步骤3:无语音片段的子采样
为避免无语音片段(如 silence、背景音)过多影响训练,对这类片段采用低概率子采样(文档提及“sub-sampled probability”),仅保留部分用于VAD训练,平衡数据分布。
二、梅尔频谱图:从“原始音频”到“模型可理解特征”的关键转换
Whisper不直接使用原始音频样本(480000个数值/30秒),而是将其转化为80通道对数幅度梅尔频谱图——这是模拟人耳听觉特性的核心特征,也是模型的直接输入。
2.1 梅尔频谱图的提取参数与计算逻辑
文档明确描述:
“All audio is re-sampled to 16,000 Hz, and an 80-channel log-magnitude Mel spectrogram representation is computed on 25-millisecond windows with a stride of 10 milliseconds.”
拆解关键参数和计算过程:
| 参数 | 数值/设置 | 作用与计算逻辑 |
|---|---|---|
| 采样率 | 16kHz | 统一后的音频采样率,确保时间维度的一致性。 |
| 窗口大小(Window) | 25毫秒(ms) | 每次分析音频的“短时片段”,对应样本数:16000 Hz × 0.025 s = 400 个样本,捕捉局部频率特征。 |
| 步长(Stride) | 10毫秒(ms) | 窗口滑动的间隔,对应样本数:16000 Hz × 0.01 s = 160 个样本,控制时间分辨率(步长越小,时间分辨率越高)。 |
| 梅尔滤波器组数量 | 80通道 | 将音频的线性频率映射到“梅尔频率”(人耳对低频更敏感,对高频不敏感),80个通道覆盖人耳敏感的频率范围。 |
| 特征类型 | 对数幅度(Log-magnitude) | 将梅尔频谱的幅度值取对数,压缩动态范围,更符合人耳对声音响度的感知特性(人耳对响度的感知是对数级的)。 |
2.2 梅尔频谱图的最终形状(30秒音频为例)
对于30秒(30000毫秒)的音频片段,梅尔频谱图的时间步数量计算如下:
时间步 = (总时长 - 窗口大小) / 步长 + 1 = (30000 - 25) / 10 + 1 ≈ 2998 步
因此,30秒音频对应的梅尔频谱图形状为 [时间步, 通道数] = [2998, 80]——这是输入CNN前的核心特征形状。
三、特征归一化:确保输入分布一致性
为避免不同音频的梅尔频谱图数值范围差异影响模型训练,Whisper对特征进行全局归一化:
“For feature normalization, we globally scale the input to be between -1 and 1 with approximately zero mean across the pre-training dataset.”
- 逻辑:基于整个预训练数据集的统计信息(均值、范围),将所有梅尔频谱图的数值线性缩放至
[-1, 1],且确保缩放后均值接近0。 - 作用:消除不同音频(如 loud 与 quiet 音频)的幅度差异,让模型聚焦于“频率模式”而非“绝对幅度”,提升训练稳定性和泛化能力。
四、CNN处理:梅尔频谱图的“局部特征提取与下采样”
Whisper的编码器(Encoder)并非直接接收梅尔频谱图,而是先通过一个两层CNN“茎干(Stem)” 处理——核心作用是提取局部频率特征、压缩时间维度(减少后续Transformer的计算量)。
4.1 CNN Stem的具体结构
文档描述:
“The encoder processes this input representation with a small stem consisting of two convolution layers with a filter width of 3 and the GELU activation function (Hendrycks & Gimpel, 2016) where the second convolution layer has a stride of two.”
拆解结构细节:
| 层级 | 类型 | 滤波器参数 | 激活函数 | 步长 | 核心作用 |
|---|---|---|---|---|---|
| 第一层 | 1D卷积 | 滤波器宽度=3,输出通道数=模型宽度(如Large模型为1280) | GELU | 1 | 提取梅尔频谱图的“局部频率-时间特征”(如短时频谱模式、频率跳变),不改变时间维度长度。 |
| 第二层 | 1D卷积 | 滤波器宽度=3,输出通道数=模型宽度 | GELU | 2 | 进一步提取复杂局部特征,并通过“步长=2”对时间维度下采样(压缩为原来的1/2),减少后续Transformer的计算压力。 |
4.2 CNN处理后的特征形状变化(以Large模型为例)
以30秒音频的梅尔频谱图 [2998, 80] 为输入,经过CNN Stem后的形状变化:
- 输入CNN前:
[时间步=2998, 通道数=80](归一化后的梅尔频谱图); - 第一层CNN(步长=1):时间步仍为2998,通道数变为模型宽度(如Large模型的1280),形状为
[2998, 1280]; - 第二层CNN(步长=2):时间步压缩为
2998 // 2 ≈ 1499,通道数保持1280,最终输出形状为[1499, 1280]。
- 关键:CNN仅处理“时间-通道”维度,不改变模型的整体序列建模逻辑,下采样后的特征会被添加正弦位置嵌入(Sinusoidal Position Embeddings),再输入Transformer编码器。
五、整体流程总结:从音频到模型输入的完整链路
将上述步骤串联,Whisper的音频处理与输入流程可概括为:
graph TDA[原始音频] --> B[重采样到16kHz单声道]B --> C[切割为30秒固定片段(解决长度不一致)]C --> D[计算80通道对数幅度梅尔频谱图<br>(窗口25ms,步长10ms)]D --> E[全局归一化到[-1, 1](均值≈0)]E --> F[输入两层CNN Stem<br>(3x滤波器+GELU,第二层步长2)]F --> G[输出下采样后的特征+正弦位置嵌入]G --> H[输入Transformer编码器]
关键设计的核心原因
- 30秒片段的选择:平衡“上下文长度”与“计算效率”——30秒足够覆盖大多数语音场景的上下文,同时避免片段过长导致Transformer计算量爆炸。
- 梅尔频谱图的使用:模拟人耳对频率的非线性感知(对低频敏感、对高频不敏感),比原始音频样本更贴合语音识别的需求。
- 两层CNN的设计:仅用少量卷积层提取局部特征(避免过度复杂),同时通过步长2下采样,将Transformer的输入序列长度减半,大幅降低训练和推理成本。
- 全局归一化:消除音频幅度差异的干扰,让模型专注于“语音内容”而非“音量大小”,提升鲁棒性。
在Whisper中,一维卷积主要用于音频编码器(AudioEncoder)的前端处理,目的是从梅尔频谱图中提取局部特征并进行下采样,为后续的Transformer层提供更紧凑的特征表示。以下结合核心代码详细说明其具体用法:
1. 输入:梅尔频谱图的格式
Whisper首先通过log_mel_spectrogram函数(位于whisper/audio.py)将原始音频转换为梅尔频谱图,其形状为(batch_size, n_mels, n_ctx),其中:
n_mels:梅尔滤波器数量(支持80或128),代表频谱的通道维度;n_ctx:时间帧数量,代表频谱的时间维度。
该梅尔频谱图会作为输入传递给AudioEncoder进行处理。
2. 音频编码器中的一维卷积层
在whisper/model.py的AudioEncoder类中,定义了两个一维卷积层(conv1和conv2),用于对梅尔频谱图进行特征提取和下采样:
class AudioEncoder(nn.Module):def __init__(self, n_mels: int, n_ctx: int, n_state: int, n_head: int, n_layer: int):super().__init__()# 第一个一维卷积:提取局部特征,将梅尔通道映射到模型隐藏维度self.conv1 = Conv1d(n_mels, n_state, kernel_size=3, padding=1)# 第二个一维卷积:进一步提取特征并下采样(时间维度减半)self.conv2 = Conv1d(n_state, n_state, kernel_size=3, stride=2, padding=1)# ... 其他初始化(位置嵌入、Transformer块等)
conv1:输入通道为n_mels(梅尔频谱的通道数),输出通道为n_state(模型的隐藏维度),卷积核大小为3,padding=1。作用是将梅尔频谱的通道维度转换为模型所需的隐藏维度,同时通过3x1的卷积核捕捉时间维度上的局部相关性(如相邻帧的频谱变化)。conv2:输入和输出通道均为n_state,卷积核大小为3,步长为2,padding=1。作用是在保持特征维度的同时,对时间维度进行下采样(步长=2),将时间帧数量减少一半,压缩序列长度以降低后续Transformer层的计算成本。
3. 卷积层的前向计算流程
在AudioEncoder的forward方法中,梅尔频谱图通过两个卷积层的处理过程如下:
def forward(self, x: Tensor):"""x : torch.Tensor, shape = (batch_size, n_mels, n_ctx)输入的梅尔频谱图"""# 第一个卷积:特征映射 + GELU激活x = F.gelu(self.conv1(x)) # 形状:(batch_size, n_state, n_ctx)# 第二个卷积:下采样 + GELU激活x = F.gelu(self.conv2(x)) # 形状:(batch_size, n_state, n_ctx//2)(步长=2导致时间维度减半)# 转换维度顺序:(batch_size, 时间维度, 隐藏维度),适配Transformer输入格式x = x.permute(0, 2, 1)# ... 后续与位置嵌入相加,进入Transformer编码器块
- 经过
conv1后,梅尔频谱图的通道从n_mels转换为n_state,时间维度保持不变(因padding=1、步长=1)。 - 经过
conv2后,时间维度因步长=2变为n_ctx//2,通道维度保持n_state,实现了时间维度的下采样。 - 最终通过
permute(0, 2, 1)将维度转换为(batch_size, 时间维度, n_state),以匹配Transformer层对“序列长度-隐藏维度”格式的要求。
4. 一维卷积的核心作用
- 特征提取:通过3x1的卷积核捕捉梅尔频谱在时间维度上的局部相关性(如相邻帧的频谱变化模式),将原始梅尔特征映射到更高维的抽象特征空间。
- 降维压缩:
conv2的步长=2设计减少了时间维度的长度,降低了后续Transformer自注意力层的计算复杂度(自注意力的时间复杂度与序列长度的平方成正比)。 - 维度适配:将输入的
n_mels通道转换为模型统一的n_state隐藏维度,为后续Transformer层的特征处理提供一致的输入格式。
综上,Whisper通过两个一维卷积层构成的前端网络,高效处理梅尔频谱图的时空特征,为后续的Transformer编码器提供了更紧凑、更具判别性的输入特征。