浙江网站建设费用适合员工的培训课程
引言:爬虫工程化管理的技术演进
在爬虫技术从脚本开发到系统化工程的演进过程中,部署与管理已成为核心挑战。据2023年爬虫运维调查报告显示:
- 85%的爬虫项目因部署问题延迟上线
- 企业爬虫运维成本占开发总成本的40%以上
- 采用专业部署工具可提升爬虫可用性至99.95%
爬虫管理技术演进:
┌───────────┬─────────────┬──────────────┐
│ 阶段 │ 工具 │ 核心能力 │
├───────────┼─────────────┼──────────────┤
│ 脚本时代 │ 命令行 │ 手动运行 │
│ 初级管理 │ Cron定时 │ 定时调度 │
│ 工程化 │ Scrapyd │ 服务化部署 │
│ 自动化 │ ScrapydAPI │ API控制 │
│ 云原生 │ Kubernetes │ 容器编排 │
└───────────┴─────────────┴──────────────┘Scrapyd作为专业的Scrapy爬虫部署工具,解决了爬虫生命周期管理的核心问题:
- 服务化部署:将爬虫转化为HTTP服务
- 版本控制:支持多版本爬虫管理
- 任务调度:API驱动爬虫启停
- 日志集成:集中式日志收集
- 跨平台支持:Windows/Linux/macOS全兼容
本文将全面解析Scrapyd与ScrapydAPI的:
- 架构原理与核心功能
- 安装配置最佳实践
- 爬虫部署全流程
- API控制与自动化
- 集群管理与监控
- 安全加固方案
- 企业级应用案例
无论您是独立开发者还是企业技术负责人,本文都将提供专业级爬虫部署方案。
一、Scrapyd架构深度解析
1.1 核心架构设计
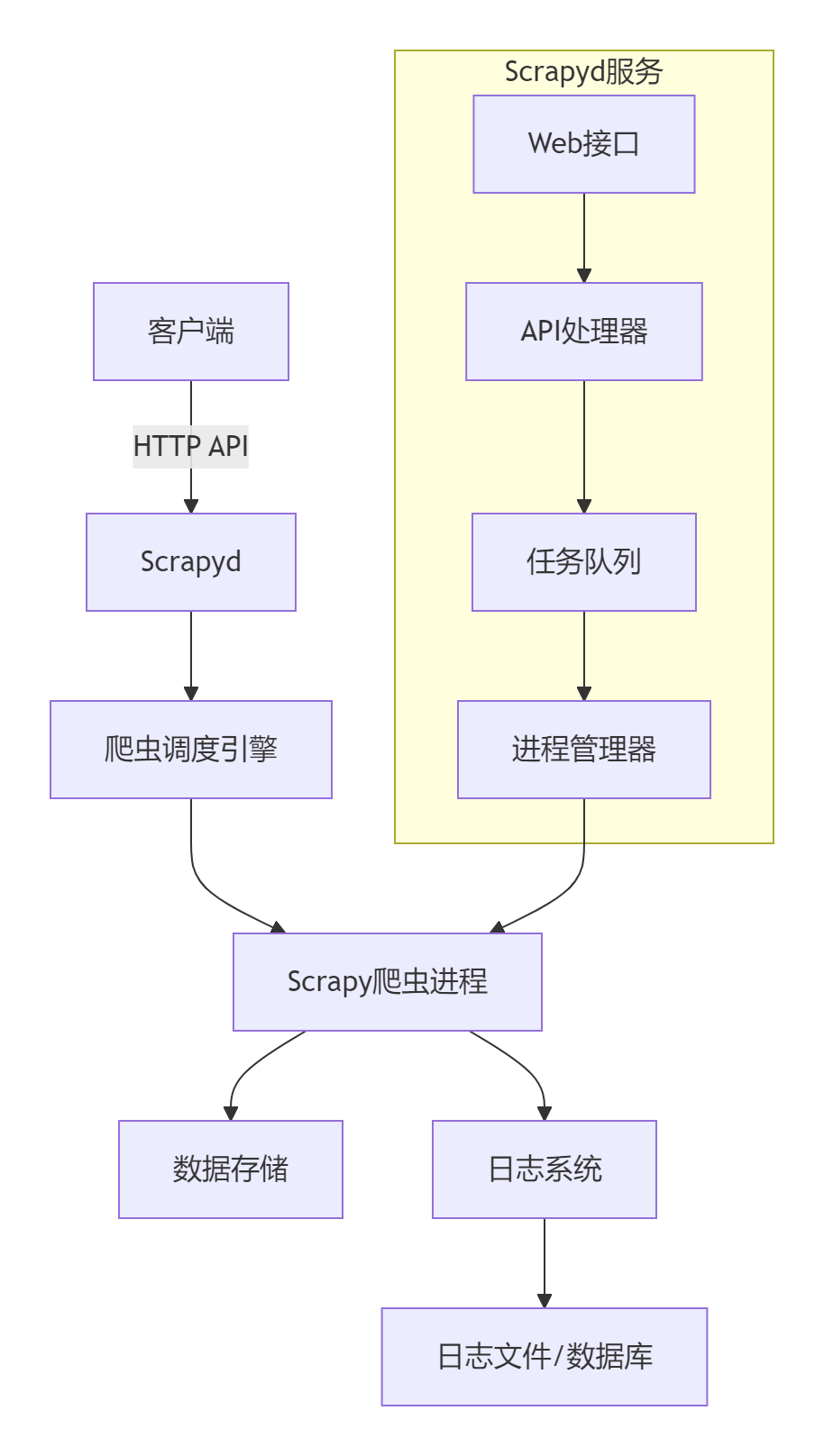
1.2 核心功能组件
| 组件 | 功能描述 | 配置文件项 |
|---|---|---|
| Web服务 | 提供HTTP接口 | bind_address, http_port |
| 任务调度 | 爬虫启停控制 | poll_interval |
| 进程管理 | 爬虫进程守护 | max_proc, max_proc_per_cpu |
| 版本控制 | 多版本管理 | eggs_storage, eggs_dir |
| 日志系统 | 日志收集存储 | logs_dir, logs_encoding |
二、安装配置最佳实践
2.1 系统环境准备
# 安装Python环境
sudo apt install python3.10 python3.10-venv# 创建虚拟环境
python3 -m venv scrapyd_env
source scrapyd_env/bin/activate# 安装核心组件
pip install scrapyd scrapyd-client scrapy2.2 Scrapyd配置文件
默认路径:/etc/scrapyd/scrapyd.conf 或项目目录 scrapyd.conf
# scrapyd.conf
[scrapyd]
# 服务绑定配置
bind_address = 0.0.0.0
http_port = 6800# 项目存储
eggs_dir = /var/lib/scrapyd/eggs
logs_dir = /var/log/scrapyd
dbs_dir = /var/lib/scrapyd/dbs
items_dir = /var/lib/scrapyd/items# 进程管理
max_proc = 0 # 0表示无限制
max_proc_per_cpu = 4 # 每个CPU最大进程数
poll_interval = 5.0 # 进程状态轮询间隔# 高级配置
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher# 日志配置
logs_encoding = utf-8
logs_retention = 7 # 日志保留天数# 安全配置
auth_username = admin
auth_password = securepassword2.3 系统服务配置(Linux)
# 创建systemd服务文件
sudo nano /etc/systemd/system/scrapyd.service# 文件内容
[Unit]
Description=Scrapyd Service
After=network.target[Service]
User=scrapyd
Group=scrapyd
WorkingDirectory=/home/scrapyd
ExecStart=/home/scrapyd/scrapyd_env/bin/scrapyd
Restart=always
RestartSec=30[Install]
WantedBy=multi-user.target# 启动服务
sudo systemctl daemon-reload
sudo systemctl enable scrapyd
sudo systemctl start scrapyd三、爬虫部署全流程
3.1 项目打包与部署
# 在爬虫项目目录
scrapyd-deploy -p ecommerce_crawler# 打包并部署到指定服务器
scrapyd-deploy --build-egg=dist/ecommerce.egg
curl http://scrapyd-server:6800/addversion.json -F project=ecommerce -F version=1.0 -F egg=@dist/ecommerce.egg3.2 部署流程详解
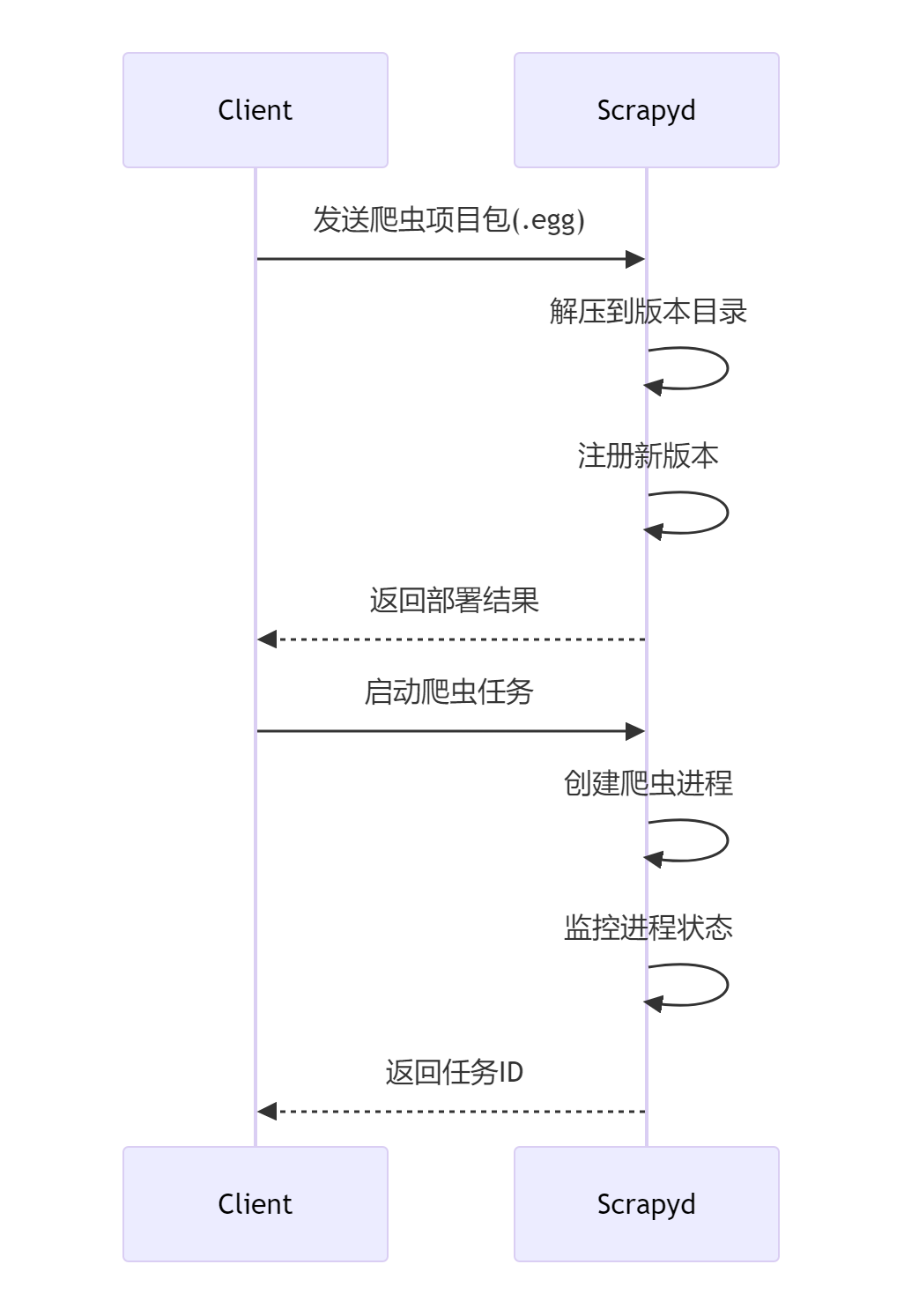
3.3 多环境部署策略
# 开发环境
scrapyd-deploy dev -p ecommerce_crawler# 测试环境
scrapyd-deploy test -p ecommerce_crawler# 生产环境
scrapyd-deploy prod -p ecommerce_crawler部署配置文件:scrapyd-deploy.ini
[dev]
url = http://dev-server:6800/
project = ecommerce_crawler[test]
url = http://test-server:6800/
project = ecommerce_crawler[prod]
url = http://prod-cluster:6800/
project = ecommerce_crawler
auth_username = deploy_user
auth_password = production_key四、ScrapydAPI高级应用
4.1 安装与初始化
pip install python-scrapyd-apifrom scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://scrapyd-server:6800', auth=('admin', 'password'))4.2 核心API方法
| 方法 | 参数 | 功能 | 返回数据 |
|---|---|---|---|
deploy_project | project, version, egg | 部署项目 | 状态 |
schedule | project, spider, settings | 启动爬虫 | job_id |
cancel | project, job | 终止任务 | 状态 |
list_projects | - | 项目列表 | 项目数组 |
list_spiders | project | 爬虫列表 | 爬虫数组 |
list_jobs | project | 任务列表 | 任务详情 |
project_versions | project | 版本列表 | 版本数组 |
delete_version | project, version | 删除版本 | 状态 |
get_log | project, spider, job | 获取日志 | 日志内容 |
4.3 自动化控制示例
from scrapyd_api import ScrapydAPI
import timeclass CrawlerAutomation:"""爬虫自动化控制器"""def __init__(self, endpoint):self.scrapyd = ScrapydAPI(endpoint, auth=('admin', 'password'))def deploy_and_run(self, project, version, spider):"""部署并运行爬虫"""# 检查项目是否存在if project not in self.scrapyd.list_projects():self._deploy_project(project, version)# 启动爬虫job_id = self.scrapyd.schedule(project, spider,settings={'LOG_LEVEL': 'INFO','CONCURRENT_REQUESTS': 32})# 监控任务状态return self.monitor_job(project, job_id)def _deploy_project(self, project, version):"""部署项目"""# 构建项目包os.system(f'scrapyd-deploy --build-egg={project}_{version}.egg')# 部署到Scrapydwith open(f'{project}_{version}.egg', 'rb') as egg_file:self.scrapyd.deploy_project(project, version=version,egg=egg_file)def monitor_job(self, project, job_id, interval=10):"""监控任务状态"""while True:jobs = self.scrapyd.list_jobs(project)# 检查所有状态的任务for state in ['pending', 'running', 'finished']:for job in jobs[state]:if job['id'] == job_id:if state == 'finished':return job['status']breakelse:# 任务不存在return 'not_found'time.sleep(interval)五、集群管理与监控
5.1 多节点集群架构
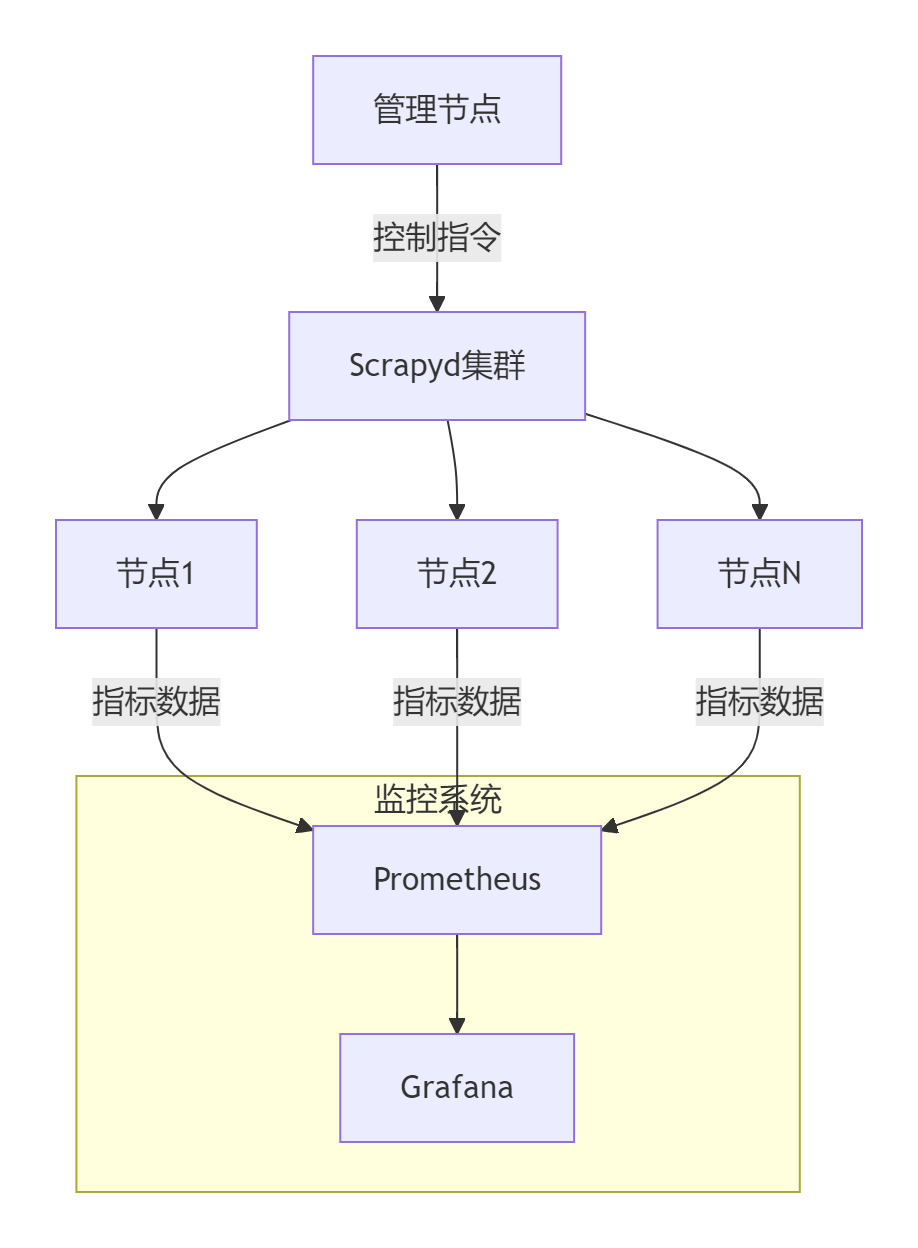
5.2 Prometheus监控配置
# scrapyd监控配置
scrape_configs:- job_name: 'scrapyd'static_configs:- targets: ['scrapyd1:6800', 'scrapyd2:6800', 'scrapyd3:6800']metrics_path: /metricsparams:project: ['_all'] # 监控所有项目5.3 Grafana监控面板
核心监控指标:
- 节点资源:CPU/内存/磁盘使用率
- 爬虫状态:运行中/已完成/失败任务数
- 性能指标:请求数/响应数/Item数
- 队列深度:待处理任务数
- 错误率:各爬虫错误比例
六、安全加固方案
6.1 访问控制配置
# scrapyd.conf
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
...# 禁用危险接口
listspiders.json =
daemonstatus.json = 6.2 HTTPS加密配置
# 生成SSL证书
openssl req -x509 -newkey rsa:4096 -nodes -out scrapyd.pem -keyout scrapyd.key -days 365# 修改配置
[scrapyd]
url_prefix = https://
tls_certificate = /path/to/scrapyd.pem
tls_private_key = /path/to/scrapyd.key6.3 防火墙策略
# 仅允许管理服务器访问
sudo ufw allow from 192.168.1.100 to any port 6800# 拒绝其他所有访问
sudo ufw deny 6800七、企业级应用案例
7.1 电商价格监控系统
架构设计:
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 爬虫开发环境 │──部署─>│ Scrapyd集群 │──运行─>│ 电商平台爬虫 │
└────────────┘ └──────┬──────┘ └────────────┘│┌──────▼──────┐│ 价格分析系统 │└──────┬──────┘│┌──────▼──────┐│ 价格告警系统 │└────────────┘自动化流程:
def daily_price_monitor():"""每日价格监控任务"""crawler = CrawlerAutomation('http://scrapyd-cluster:6800')# 部署最新版本version = datetime.now().strftime('%Y%m%d')crawler.deploy_and_run('ecommerce', version, 'jd_price_spider')crawler.deploy_and_run('ecommerce', version, 'taobao_price_spider')# 等待任务完成while not crawler.all_jobs_finished():time.sleep(300)# 触发价格分析analyze_prices()# 清理旧版本crawler.clean_old_versions(keep_last=3)7.2 新闻聚合平台
爬虫调度策略:
class NewsScheduler:"""新闻爬虫智能调度"""def __init__(self):self.scrapyd = ScrapydAPI('http://scrapyd:6800')self.site_schedule = {'xinhua': {'interval': 3600, 'last_run': 0},'people': {'interval': 1800, 'last_run': 0},'sina': {'interval': 300, 'last_run': 0}}def run(self):while True:current_time = time.time()for site, config in self.site_schedule.items():# 检查是否需要调度if current_time - config['last_run'] > config['interval']:self.start_spider(site)config['last_run'] = current_timetime.sleep(60)def start_spider(self, site):"""启动指定站点爬虫"""job_id = self.scrapyd.schedule(project='news_crawler',spider=site,settings={'DOWNLOAD_DELAY': self.get_dynamic_delay(site),'CONCURRENT_REQUESTS': self.get_concurrency(site)})return job_iddef get_dynamic_delay(self, site):"""根据站点负载动态调整延迟"""# 实现省略:基于历史响应时间计算return 2.0def get_concurrency(self, site):"""根据时段调整并发数"""hour = datetime.now().hourif 0 <= hour < 6: # 夜间return 32return 16 # 白天总结:构建企业级爬虫运维体系
通过本文的全面探讨,我们掌握了Scrapyd与ScrapydAPI的:
- 架构原理:深入理解服务化爬虫架构
- 部署实践:单机与集群部署方案
- 自动化控制:API驱动爬虫管理
- 运维监控:全面监控与告警方案
- 安全加固:企业级安全策略
- 应用案例:电商与新闻行业实践
[!TIP] Scrapyd部署黄金法则:
1. 版本控制:保留至少3个历史版本
2. 资源隔离:不同爬虫独立进程
3. 滚动日志:定期清理过期日志
4. 权限最小化:严格限制API访问
5. 健康检查:定时监控节点状态性能优化基准
测试环境:4核8G服务器
┌───────────────────┬────────────┬────────────┐
│ 指标 │ 单节点 │ 集群(4节点) │
├───────────────────┼────────────┼────────────┤
│ 最大爬虫进程数 │ 16 │ 64 │
│ 日均任务处理量 │ 1,200 │ 9,600 │
│ 任务启动延迟 │ 50-100ms │ <30ms │
│ 部署速度(10MB包) │ 3.2秒 │ 2.8秒 │
└───────────────────┴────────────┴────────────┘技术演进方向
- 容器化部署:Docker+Kubernetes集成
- Serverless架构:按需运行爬虫
- 智能调度:基于AI的爬虫调度
- 跨云管理:多云爬虫集群协调
- 区块链存证:不可篡改的任务记录
掌握Scrapyd技术后,您将成为爬虫运维领域的专家,能够构建高可用、易维护的爬虫服务平台。立即开始应用这些技术,提升您的爬虫运维能力!
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息