ICCV 2025 最佳论文系列整理:聚焦计算机视觉前沿突破
引言
国际计算机视觉大会(International Conference on Computer Vision, ICCV)是计算机视觉领域最具影响力的顶级会议之一,每两年举办一次,汇聚了全球最前沿的研究成果。ICCV 2025于10月19日至23日在夏威夷檀香山举行,本届大会共收到11239篇论文,录用超过2500篇,规模空前。其中,中国学者贡献了超过一半的论文,彰显了中国在计算机视觉领域的强大实力。
本文将深入探讨ICCV 2025的各项最佳论文奖项,包括最佳论文(Marr Prize)、最佳论文荣誉提名、最佳学生论文、最佳学生论文荣誉提名,以及表彰十年经典之作的Helmholtz Prize,旨在为读者呈现这些引领未来计算机视觉发展的突破性研究。
最佳论文(Marr Prize):BrickGPT——文本到物理积木结构生成 [1]
论文地址:Generating Physically Stable and Buildable Brick Structures from Text
开源地址:https://github.com/AvaLovelace1/BrickGPT
ICCV 2025的最高荣誉——最佳论文奖(Marr Prize)颁发给了卡内基梅隆大学(CMU)团队提出的 BrickGPT。这项开创性的工作首次实现了从文本描述直接生成物理稳定且可实际建造的积木结构模型。BrickGPT的核心在于其独特的全流畅生成方法,能够将文本指令转化为具体的3D物理结构。
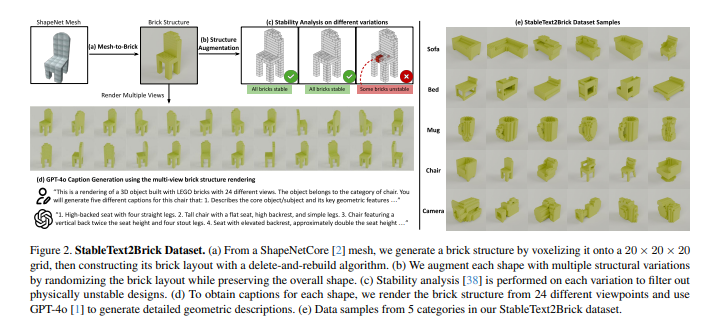
为了实现这一目标,研究团队构建了一个名为 StableText2Brick 的大规模数据集,其中包含超过47,000个积木结构,涵盖28,000多个独立的3D物体,并为每个结构配有详细的文本描述,同时确保其物理稳定性。在此基础上,团队训练了一个自回归大语言模型,通过“下一token预测”机制来推断下一个应添加的积木块。
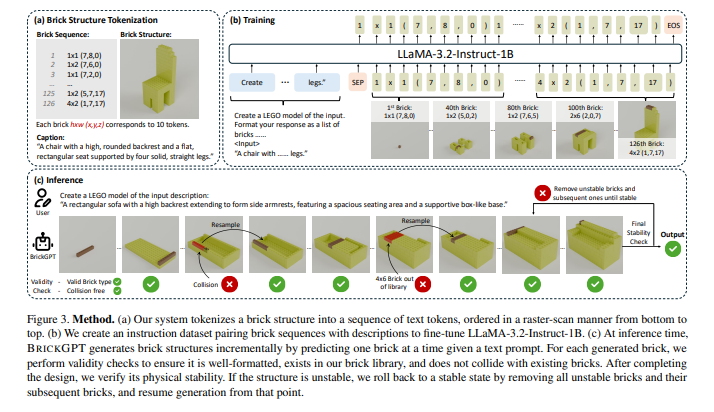
为了进一步提升生成设计的稳定性,BrickGPT在推理阶段引入了“有效性检查”和“物理感知回滚”机制。该机制利用物理定律和组装约束,实时剪枝不可行的token预测,确保最终生成的积木结构不仅美观、多样,而且与输入文本提示高度吻合,并具有实际的可建造性。实验证明,这些设计不仅可以由人工手动组装,甚至可以通过机械臂实现自动化搭建 [2]。
最佳论文荣誉提名:Spatially-Varying Autofocus——全景深成像的新型镜头与算法框架 [1]
论文地址:Spatially-Varying Autofocus
项目地址:https://imaging.cs.cmu.edu/svaf/
同样来自卡内基梅隆大学(CMU)团队的 Spatially-Varying Autofocus 获得了最佳论文荣誉提名。这项研究创新性地提出了一种用于全景深成像的新型镜头与算法框架,成功打破了传统镜头“一次只能对一个平面清晰对焦”的基本限制 [3]。

该研究设计了一个由Lohmann透镜和纯相位空间光调制器组成的光学系统,使得图像中的每个像素都能够独立地对焦于不同的深度。此外,研究人员还将经典的自动对焦技术扩展到空间可变场景,利用对比度和视差线索迭代估算深度图,从而使相机能够逐步调整景深以适应场景的深度变化。
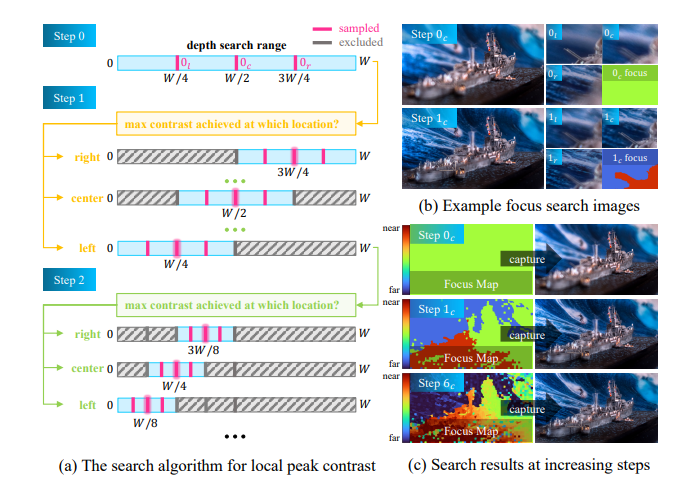
相较于以往的研究,Spatially-Varying Autofocus直接从光学层面获取“全清晰”图像,实现了两大关键突破:一是能够同时使整个场景清晰对焦;二是能够保持最高的空间分辨率。这项技术在计算成像领域具有重要意义,有望为未来的相机系统带来革命性的改变 [4]。
最佳学生论文:FlowEdit——免反演的文本图像编辑 [1]
论文地址:FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models
项目地址:https://github.com/fallenshock/FlowEdit
以色列理工学院团队的 FlowEdit 荣获ICCV 2025最佳学生论文奖。该研究贡献了一种利用文本到图像流模型,实现免反演的文本图像编辑的创新方法。当前,基于预训练文生图(T2I)模型的图像编辑方法通常需要通过反转和干预采样实现,但这往往存在缺陷,例如反转无法完美重建原始图像,以及干预采样方法难以在不同模型架构之间迁移。
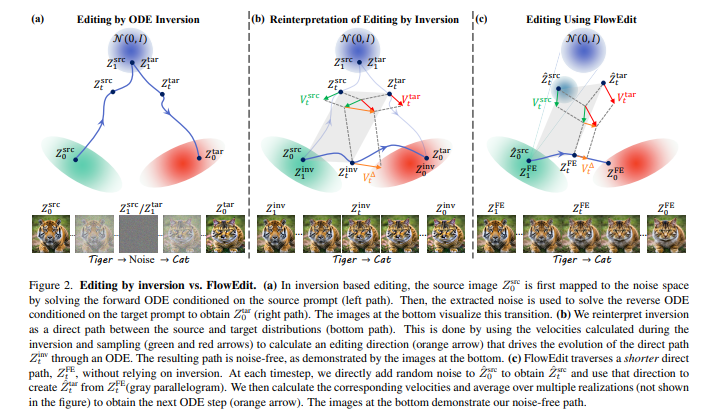
FlowEdit通过构建一个全新的常微分方程(ODE)来解决这些问题。该ODE直接在“源分布”与“目标分布”之间进行映射,并实现了比传统反演方法更低的传输成本。FlowEdit的精髓在于其“免反演、免优化且模型无关”的特性,使其能够高效且灵活地进行文本图像编辑。论文通过在Stable Diffusion 3和FLUX模型上的实验,证明了FlowEdit达到了最先进的编辑效果 [5]。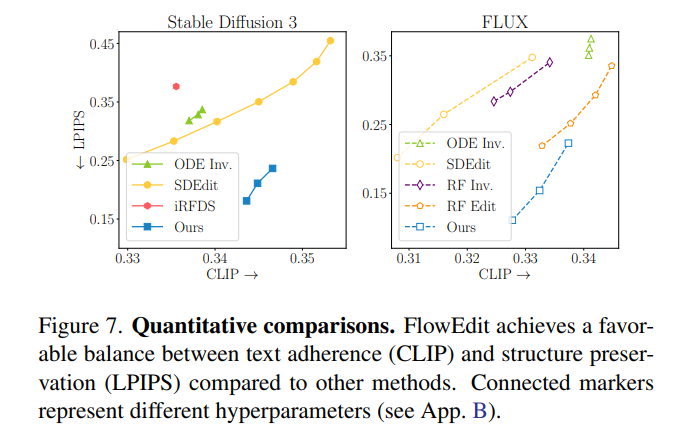
最佳学生论文荣誉提名:RayZer——基于未知姿态图像的自监督光线学习推进3D合成 [1]
论文地址:RayZer: A Self-supervised Large View Synthesis Model
项目地址:https://hwjiang1510.github.io/RayZer/
来自UT-Austin、Adobe和康奈尔大学团队的 RayZer 获得了最佳学生论文荣誉提名。这项研究提出了一种无需3D标注数据即可从2D图像中学习3D场景表示的新方法。RayZer能够以未知姿态、未经校准的图像作为输入,恢复相机参数,重建场景表示,并合成新视角 [6]。
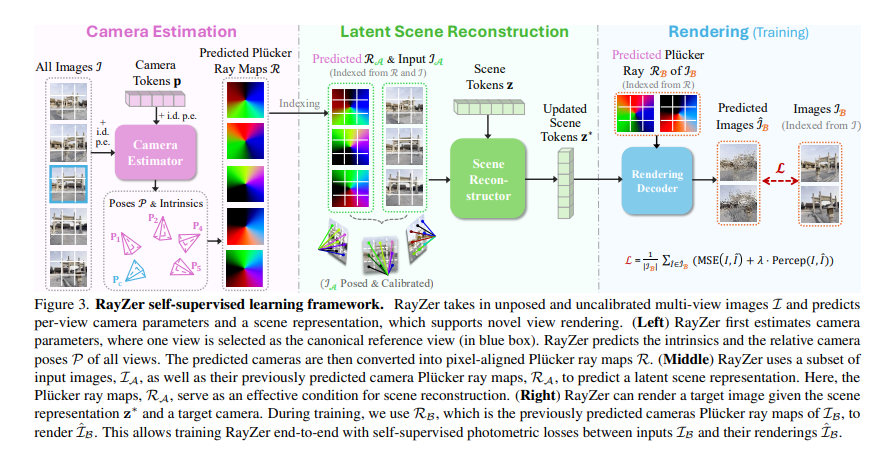
RayZer在训练过程中仅依赖自身预测的相机姿态来渲染目标视图,因此无需任何相机真值标注,使其能够仅通过2D图像监督进行训练。RayZer之所以能涌现出3D感知能力,主要归功于一个解耦相机与场景表示的自监督框架和一个基于Transformer的模型。该模型唯一的3D先验是能够同时连接相机、像素和场景的光线结构。在新视角合成任务上,RayZer取得了与依赖真实姿态信息“oracle”方法相比更优的性能,甚至在某些情况下超越了它们 [7]。
Helmholtz Prize:十年经典之作 [1]
两年一度的Helmholtz Prize由IEEE模式分析与机器智能(PAMI)技术委员会在每届ICCV大会上颁发,旨在表彰十年前发表于ICCV、并对计算机视觉研究产生了深远影响的论文。ICCV 2025的Helmholtz Prize颁发给了两篇具有里程碑意义的论文:
1. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification [8]
论文地址:https://arxiv.org/pdf/1502.01852
这篇由何恺明、张祥雨、任少卿和孙剑于2015年发表的论文,深入探讨了用于图像分类的修正线性神经网络。研究提出了参数化修正线性单元(PReLU),它是对传统修正单元的泛化,能够提升模型拟合效果,且几乎不带来额外计算开销,过拟合风险也极低。此外,论文还推导了一种针对修正单元非线性特性的稳健初始化方法,使得从零开始训练极深层修正网络模型成为可能,并为探索更深或更宽的网络架构奠定了基础。
基于PReLU网络,团队在ImageNet 2012分类数据集上取得了4.94%的top-5测试错误率,相较于ILSVRC 2014的冠军模型GoogLeNet(6.66%),性能相对提升了26%。值得一提的是,这是首次有研究成果在视觉识别挑战中超越了人类的表现水平(5.1%),堪称深度学习领域的里程碑 [1]。
2. Fast R-CNN [9]
论文地址:https://arxiv.org/pdf/1504.08083
项目地址:http://github.com/rbgirshick/fast-rcnn
由Ross Girshick于2015年发表的 Fast R-CNN 为目标检测任务提出了快速区域卷积网络方法。Fast R-CNN利用深度卷积网络对候选区域进行高效分类,并引入多项革新,显著提升了训练和测试速度,同时提高了检测精度。
在训练VGG16这一深度网络时,Fast R-CNN的速度是R-CNN的9倍,测试速度则快213倍,并在PASCAL VOC 2012数据集上取得了更高的平均精度均值(mAP)。与SPPnet相比,Fast R-CNN在训练VGG16时的速度快3倍,测试速度快10倍,且精度更高。Fast R-CNN的出现,极大地推动了目标检测领域的发展,为后续的Mask R-CNN等工作奠定了基础 [1]。
结论
ICCV 2025再次展示了计算机视觉领域蓬勃发展的创新活力。从CMU团队的文本到3D积木结构生成技术BrickGPT,到Spatially-Varying Autofocus的全景深成像,再到FlowEdit的免反演文本图像编辑和RayZer的自监督3D合成,这些获奖论文不仅在各自领域取得了突破性进展,也为未来的研究指明了方向。
特别是Helmholtz Prize对何恺明团队PReLU和Ross Girshick的Fast R-CNN的认可,再次证明了这些经典工作在推动计算机视觉发展中的深远影响。这些成果将继续激励研究人员探索更智能、更高效的视觉系统,共同塑造计算机视觉的未来。
参考文献
[1] ICCV 2025最佳论文出炉!何恺明、孙剑等十年经典之作夺奖. https://www.163.com/dy/article/KCFJV0AP0511ABV6.html
[2] Generating Physically Stable and Buildable Brick Structures from Text. https://avalovelace1.github.io/BrickGPT/
[3] Spatially-Varying Autofocus. https://imaging.cs.cmu.edu/svaf/static/pdfs/Spatially_Varying_Autofocus.pdf
[4] Spatially-Varying Autofocus Project Page. https://imaging.cs.cmu.edu/svaf/
[5] FlowEdit: Inversion-Free Text-Based Editing Using Pre-Trained Flow Models. https://matankleiner.github.io/flowedit/
[6] RayZer: A Self-supervised Large View Synthesis Model. https://arxiv.org/abs/2505.00702
[7] RayZer Project Page. https://hwjiang1510.github.io/RayZer/
[8] Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. https://arxiv.org/abs/1502.01852
[9] Fast R-CNN. https://arxiv.org/abs/1504.08083