LLama 3分组查询注意力与KV缓存机制
文章目录
- 一 背景知识:为什么需要GQA?
- 1.1 自回归生成与 KV Cache
- 1.2 KV Cache 的问题:内存瓶颈
- 二 注意力机制的演进:从 MHA 到 MQA 再到 GQA
- 2.1 多头注意力(MHA)- 标准配置
- 2.2 多查询注意力(MQA) - 激进的优化
- 2.3 分组查询注意力(GQA) - 精妙的平衡
- 2.4 形象理解MHA&MQA&GQA
- 2.5 GQA与 MQA、MHA 的关系
- 三 GQA与KV Cache
- 3.1 GQA与KV Cache在Llama 3中的协同工作过程
- 3.2 GQA 的详细计算流程
- 3.3 KVCache详细的追加过程
- 四 总结
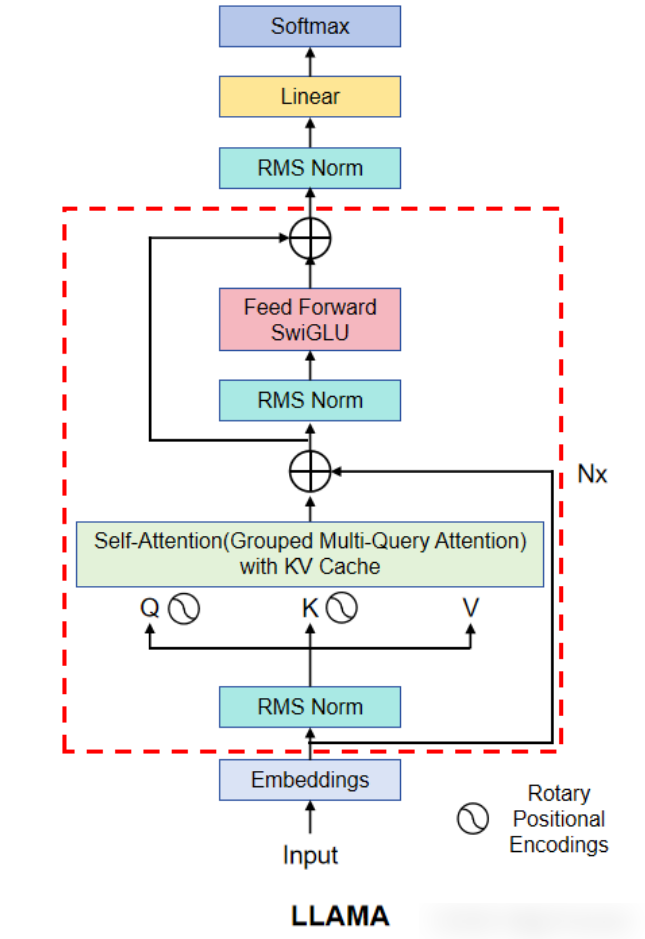
一 背景知识:为什么需要GQA?
要理解分组查询注意力(Group Mulit-Query Attention,GQA) 的价值,我们首先要明白它解决了什么问题。这个问题主要源于 LLM 的自回归生成方式和多头注意力机制。
1.1 自回归生成与 KV Cache
-
LLM 在生成文本时,是一个词一个词(或一个 token 一个 token)地“吐”出来的。比如,要生成 “I love AI”,过程是:
- 输入
<s>,预测出 “I”。 - 输入
<s> I,预测出 “love”。 - 输入
<s> I love,预测出 “AI”。
- 输入
-
在这个过程中,每生成一个新 token,模型都需要“看到”之前所有的 token。如果每次都从头计算所有历史 token 的 Key (K) 和 Value (V) 矩阵,计算量会非常巨大。
KV Cache 就是为了解决这个问题。它是一种缓存机制:
- 原理:在第一次计算时(处理输入序列),我们把每个 token 的 K 和 V 矩阵计算出来并存储在内存(显存)中。
- 使用:在后续生成新 token 时,我们只需要计算当前这个新 token 的 K 和 V,然后把它追加到缓存中。这样,模型在做注意力计算时,就可以直接使用缓存里所有历史 token 的 K 和 V,大大减少了重复计算。
1.2 KV Cache 的问题:内存瓶颈
- KV Cache 虽然快,但它非常消耗内存。缓存的大小与以下因素成正比:
KV Cache 大小 ∝ (序列长度) × (注意力头数量) × (每个头的维度) - 当生成长文本或处理大批量请求时,KV Cache 会变得异常庞大,成为推理服务的主要内存瓶颈。这限制了模型能处理的最大序列长度和服务的并发用户数。
二 注意力机制的演进:从 MHA 到 MQA 再到 GQA
- 分组注意力机制GQA(Grouped Multi-Query Attention)是在解决上述内存瓶颈的探索中诞生的。让我们看看它的“前辈们”。
2.1 多头注意力(MHA)- 标准配置
多头注意力机制(Mulit-Head Attenttion,MHA) 是 Transformer 模型的标准配置。
- 结构:假设有
h个注意力头。每个头都有自己独立的、从输入投影而来的 Q、K、V 矩阵。 - 优点:每个头可以学习到输入序列的不同方面的信息(比如语法、语义、长距离依赖等),表达能力非常强。
- 缺点:每个头都需要为自己的 K 和 V 矩阵开辟缓存空间。KV Cache 的大小与头数
h成正比,内存开销巨大。
2.2 多查询注意力(MQA) - 激进的优化
为了解决多头注意力机制(Mulit-Head Attenttion,MHA) 的内存问题,多查询注意力(Mulit-Query Attention,MQA) 被提了出来。
- 结构:仍然有多个 Q 头,但所有 Q 头共享同一组 K 头和 V 头。
- 优点:KV Cache 的大小急剧减小!因为无论有多少个 Q 头,我们只需要缓存 1 组 K 和 V 矩阵。这极大地降低了内存占用,并显著提升了推理速度。
- 缺点:性能下降。因为所有 Q 头都“看”同一份 K/V 信息,相当于用一套“知识”去回答多个不同角度的“问题”,信息的丰富度受损,可能导致模型质量下降。
2.3 分组查询注意力(GQA) - 精妙的平衡
分组查询注意力(Grouped Multi-Query Attention,GQA) 是 MHA 和 MQA 之间一个完美的折中方案,也是 Llama 3 采用的策略。
- 结构:它将 Q 头分成若干组,每组 Q 头共享一组 K 头和 V 头。
- 关键参数:
num_q_heads(Q 头数量) 和num_kv_heads(K/V 头数量)。通常num_q_heads是num_kv_heads的整数倍。 - 优点:
- 性能与效率的平衡:它不像 MQA 那么极端,保留了多组 K/V,允许不同组的 Q 关注不同维度的信息,模型质量损失很小,甚至可以忽略不计。
- 显著的内存节省:KV Cache 的大小从与
num_q_heads成正比,变为与num_kv_heads成正比。缓存大小缩减为num_kv_heads / num_q_heads。
- Llama 3 的具体实现:
- Llama 3 8B:
num_q_heads = 32,num_kv_heads = 8。这意味着每 4 个 Q 头共享一组 K/V 头。KV Cache 大小减少到原来的 1/4。 - Llama 3 70B:
num_q_heads = 64,num_kv_heads = 8。这意味着每 8 个 Q 头共享一组 K/V 头。KV Cache 大小减少到原来的 1/8。
- Llama 3 8B:
2.4 形象理解MHA&MQA&GQA
为了更好地理解,我们用一个“专家小组研讨会”的比喻:
- MHA (标准多头):一个研讨会邀请了 32 位专家(Q 头)。为每位专家都配备了一个专属的研究团队(K/V 头)。效果最好,但成本极高(32 个团队)。
- MQA (多查询):还是 32 位专家,只配备 1 个共享的研究团队。成本极低,但团队可能不堪重负,无法满足所有专家的个性化需求,导致讨论质量下降。
- GQA (分组查询):将 32 位专家分成 8 个小组,每组 4 人。为每个小组配备 1 个专属的研究团队(K/V 头)。这样总共有 8 个研究团队,每个团队可以专注于自己小组的 4 位专家,提供更有针对性的信息。成本(8 个团队)远低于 MHA,但讨论质量远高于 MQA。这是一个成本和效果的最佳平衡点。
- GQA (分组查询)研讨会过程:第 1 小组的 4 位专家,他们的问题(Q)虽然各不相同,但都由同一个研究小组 ( K 0 , V 0 ) (K_0, V_0) (K0,V0)提供背景资料。第 2 小组的 4 位专家,则由另一个研究小组 ( K 1 , V 1 ) (K_1, V_1) (K1,V1) 提供资料。
2.5 GQA与 MQA、MHA 的关系
| 机制 | 查询头(Q) | 键/值头(K/V) | 优势与劣势 |
|---|---|---|---|
| MHA(多头) | 每个头独立 | 每个头独立 | 表达能力最强,但内存占用最大 |
| MQA(多查询) | 每个头独立 | 全部共享同一组 | 内存占用最小,但表达能力下降 |
| GQA(分组查询) | 每个头独立 | 分组共享 | 在表达力和内存之间取得平衡 |
- 当 GQA 的组数为 1 时,退化为 MQA;
- 当组数等于查询头数时,退化为 MHA。
三 GQA与KV Cache
3.1 GQA与KV Cache在Llama 3中的协同工作过程
假设我们使用 Llama 3 8B 模型(32 Q 头,8 K/V 头)进行自回归生成。
- 初始阶段(处理 Prompt):
- 输入一个 Prompt 序列,比如 “The future of AI is”。
- 模型为序列中的每个 token 计算出 Q, K, V。
- 对于每个 token,我们得到 32 个 Q 向量,但只有 8 个 K 向量和 8 个 V 向量。
- 这 8 个 K/V 向量被存入 KV Cache。此时 Cache 的大小是
seq_len * 8 * head_dim。
- 生成阶段(解码):
- 模型要生成下一个 token。
- 计算当前 token:只计算这一个新 token 的 Q, K, V。同样,得到 32 个 Q 向量,8 个 K 向量,8 个 V 向量。
- 更新 Cache:将新生成的 8 个 K 向量和 8 个 V 向量追加到 KV Cache 的末尾。
- 注意力计算:将当前 token 的 32 个 Q 向量,分成 8 组,每组 4 个。第 1 组的 4 个 Q 向量,与 Cache 中它所属的那一组的K 向量进行注意力计算,得到权重,然后加权 Cache 中它所属的那一组的V向量,得到一个输出。…以此类推,第 2 组到第 8 组的 Q 向量也执行同样的操作。
- 最终输出:将所有 8 组的输出拼接起来,经过最后的线性层,预测出下一个 token。
- 在实际计算过程中,通过将k矩阵进行拼接,然后与Q矩阵进行相乘一次性求得整体 Q K T QK^T QKT。
核心优势体现:在整个生成过程中,KV Cache 的增长速度非常慢,因为它只存储 8 个头的 K/V,而不是 32 个。这使得 Llama 3 能够:
- 支持更长的上下文:在有限的显存下处理更长的对话或文档。
- 提高推理吞吐量:更小的缓存意味着更少的内存读写,这是推理速度的关键瓶颈。缓存越小,速度越快。
- 降低服务成本:单张 GPU 可以同时服务更多的用户请求。
3.2 GQA 的详细计算流程
准备阶段:定义分组
- Q 头索引
i从 0 到 31。 - K/V 头索引
j从 0 到 7。 - 分组规则:第
i个 Q 头属于第g = i // 4组。它将使用第j = g个 K 头和 V 头。
计算阶段:
- 生成所有头:
- 计算出 32 个 Q 头:
Q_0, Q_1, ..., Q_31。 - 计算出 8 个 K 头:
K_0, K_1, ..., K_7。 - 计算出 8 个 V 头:
V_0, V_1, ..., V_7。
- 计算出 32 个 Q 头:
- 分组计算注意力:
- 对于第 0 组:
- 它包含 Q 头:
Q_0, Q_1, Q_2, Q_3。 - 它共享 K/V 头:
K_0和V_0。 - 计算过程:
Output_0 = Attention(Q_0, K_0, V_0)Output_1 = Attention(Q_1, K_0, V_0)Output_2 = Attention(Q_2, K_0, V_0)Output_3 = Attention(Q_3, K_0, V_0)
- 这一组的 4 个 Q 头,每一个都和同一个
K_0、V_0进行了独立的注意力计算,得到了 4 个不同的输出。
- 它包含 Q 头:
- 对于第 1 组:
- 它包含 Q 头:
Q_4, Q_5, Q_6, Q_7。 - 它共享 K/V 头:
K_1和V_1。 - 计算过程:
Output_4 = Attention(Q_4, K_1, V_1)Output_5 = Attention(Q_5, K_1, V_1)- …以此类推。
- 它包含 Q 头:
- …一直到第 7 组,所有 32 个 Q 头都完成了计算。
- 合并输出:
- 我们现在得到了 32 个输出向量:
Output_0, Output_1, ..., Output_31。 - 将这 32 个输出向量拼接起来,然后通过一个最终的输出线性层
W^O,得到该层的最终输出。
- 我们现在得到了 32 个输出向量:
3.3 KVCache详细的追加过程
- KV Cache 的本质:一个不断增长的列表。你可以把 KV Cache 想象成一个备忘录或者一个历史记录本。当你在写一个长句子时:
“The future of AI is…”
- 处理 “The” 时:你在本子上记下 “The” 对应的 K 和 V。
- 处理 “future” 时:你在本子上新增一行,记下 “future” 对应的 K 和 V。现在本子上有两条记录。
- 处理 “of” 时:你再次新增一行,记下 “of” 对应的 K 和 V。本子上有三条记录。
- …以此类推。
KV Cache 就是这样工作的。它是一个在“序列长度”这个维度上不断变大的张量。
初始状态(处理完 Prompt “The future of AI is”)
- 假设这个 Prompt 有 6 个 token。此时,我们的 KV Cache 看起来是这样的(为了简化,只看 Key Cache):
KV_Cache_Keys = {"KV_Head_0": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is], // 长度为 5"KV_Head_1": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is], // 长度为 5..."KV_Head_7": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is] // 长度为 5
}
- 注意:每个 KV 头(
KV_Head_0到KV_Head_7)都缓存了 5 个 token 的 Key 向量。这些 Key 向量是不同的,因为它们来自不同的投影矩阵W^K。
生成步骤一:预测下一个 token “bright”
- 计算新 token:模型拿到当前上下文,计算出 “bright” 这个新 token 的 Q, K, V。
- 我们得到了 32 个 Q 向量。
- 我们得到了 8 个 K 向量(
K_bright_head_0,K_bright_head_1, …,K_bright_head_7)。 - 我们得到了 8 个 V 向量(
V_bright_head_0,V_bright_head_1, …,V_bright_head_7)。
- 追加到 Cache:现在,我们将这 8 个新的 K 向量和 8 个新的 V 向量追加到对应 KV 头的缓存末尾。
// 追加操作 KV_Cache_Keys["KV_Head_0"].append(K_bright_head_0) KV_Cache_Keys["KV_Head_1"].append(K_bright_head_1) ... KV_Cache_Keys["KV_Head_7"].append(K_bright_head_7) - 更新后的 Cache:追加后,Cache 变成了:
KV_Cache_Keys = {"KV_Head_0": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is, K_bright_head_0], // 长度变为 6"KV_Head_1": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is, K_bright_head_1], // 长度变为 6..."KV_Head_7": [K_of_The, K_of_future, K_of_of, K_of_AI, K_of_is, K_bright_head_7] // 长度变为 6 }
-
原来的
K_of_The等历史记录完好无损,只是在每个 KV 头的列表末尾增加了一个新的元素。没有任何替换发生。 -
KV Cache 的全部意义就在于保留完整的上下文历史,让模型在每一步都能“看到”从开始到现在的所有内容。
- KV Cache 是追加,不是替换:它像一个不断增长的列表,记录下所有历史 token 的 Key 和 Value。
- 追加发生在序列维度:每生成一个新 token,它的 K/V 就被添加到每个 KV 头缓存的末尾。
- KV 头的结构是固定的:GQA 中的 8 个 KV 头(
KV_Head_0到KV_Head_7)是模型结构的一部分,它们本身不会被创建或销毁,只是它们内部缓存的内容在增长。
四 总结
- Llama 3 中的 Grouped Multi-Query Attention (GQA) with KV Cache 是一项精妙的工程优化,其核心思想是:
- 解耦 Q 和 K/V 的数量:允许模型拥有更多的查询头(用于捕捉丰富的模式)和较少的键/值头(用于缓存)。
- 分组共享:让多个查询头共享一组键/值头,在不显著牺牲模型表达能力的前提下,大幅压缩了 KV Cache 的体积。
- 释放推理潜力:通过减少内存占用和内存带宽需求,极大地提升了 Llama 3 的推理速度、吞吐量和长文本处理能力,使其在实际部署中更具竞争力。