MySQL专题Day(3)————索引
很久不见同好们,甚是想念!当然,近期有幸和同站大佬交流一些新技术去了,疏于了更新。今特来补上,本周休息加更几个AI面经。闲话少说,开始正文!
目录
索引简介
索引的优缺点
✅ 优点:
❌ 劣势:
索引结构
🌲 B+Tree 索引
🌲B+Tree的节点组成
🌲B+Tree的查询过程
🌲B+Tree的插入与删除
🔍 Hash 索引
🔍 哈希索引的优缺点对比
🔍 哈希索引的适用场景
🔍 哈希索引的实现示例
🗺️ 空间索引(R-Tree)——(了解即可)
常见的空间索引包括:
📝 全文索引(Full-text)
常见的全文索引技术包括:
全文索引通常支持以下功能:
索引分类
🏷️ 主键索引(PRIMARY)
🔑 唯一索引(UNIQUE)
📄 常规索引
📖 全文索引
关于索引常见的问题
索引优化策略
索引失效场景
索引使用分析工具
索引维护建议
索引简介
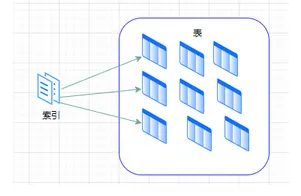
索引是帮助 MySQL 高效获取数据的数据结构。它就像一本书的目录,能够快速定位到你想找的内容,而不需要一页一页翻。在数据之外,数据库系统维护着特定算法查找的数据结构,这些数据以某种方式指向数据。
索引的优缺点
✅ 优点:
-
提高检索效率:大大减少需要扫描的数据量,降低 I/O 成本。
-
优化排序:索引本身有序,可避免再次排序,降低 CPU 开销。
❌ 劣势:
-
占用存储空间:索引本身也是数据,会占用额外的磁盘空间。
-
降低写操作效率:对数据进行增、删、改时,索引也需要同步更新,影响写入性能。
索引结构
🌲 B+Tree 索引
最常见的索引类型,大部分存储引擎(如 InnoDB)都支持。
特点:只有叶子节点才存放真实数据,非叶子节点只存键值和指针,层级更少,查询更稳定。
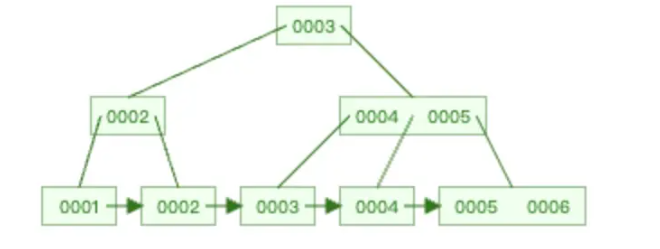
🌲B+Tree的节点组成
内部节点(非叶子节点):仅存储键值(索引字段)和指向子节点的指针,不存储实际数据。键值用于路由查询路径。
叶子节点:存储键值和实际数据(或数据指针)。若为聚簇索引,叶子节点直接包含行数据;若为非聚簇索引,则存储指向数据行的指针。
| 核心特点 | 特征 |
| 多层级结构 | 由根节点、内部节点和叶子节点组成,所有数据记录存储在叶子节点。 |
| 平衡性 | 所有叶子节点位于同一层级,保证查询效率稳定。 |
| 双向链表 | 叶子节点通过指针相互连接,支持范围查询的高效遍历。 |
🌲B+Tree的查询过程
step1——从根节点开始:根据键值比较确定下一层子节点。
step2——逐层向下:重复比较过程,直到抵达叶子节点。
step3——叶子节点检索:在叶子节点中定位目标键值,获取数据或指针。若为范围查询,利用双向链表遍历相邻节点。
🌲B+Tree的插入与删除
插入操作:定位到目标叶子节点并插入键值。若节点已满,触发分裂操作:将中间键值提升至父节点,生成新节点。分裂可能递归向上传播。
删除操作:从叶子节点移除键值。若节点键值数低于阈值,可能触发合并或借用相邻节点的键值,以维持平衡。
🔍 Hash 索引
- 基于哈希表实现,只能精确匹配,不支持范围查询。
- 适合等值查询,但不适合排序或范围查找。
🔍 哈希索引的优缺点对比
优点
- 等值查询效率极高,适合精确匹配(如
=、IN操作)。 - 数据量大小对查询性能影响较小。
缺点
- 不支持范围查询(如
BETWEEN、>)。 - 不支持排序和部分匹配(如
LIKE 'abc%')。 - 哈希冲突可能降低性能(需处理链表或开放寻址)。
🔍 哈希索引的适用场景
- 频繁等值查询且无需排序的场景,如缓存表、字典表。
- 内存表(如MySQL的
MEMORY引擎)默认使用哈希索引。
🔍 哈希索引的实现示例
InnoDB引擎的自适应哈希索引(Adaptive Hash Index)会在频繁访问的索引键上自动创建哈希索引,加速查询。
-- 查看自适应哈希索引状态
SHOW ENGINE INNODB STATUS;
-- 输出中查找 "Hash table size" 部分🗺️ 空间索引(R-Tree)——(了解即可)
MyISAM 引擎支持,主要用于地理空间数据(如地图坐标),使用较少。其是一种用于高效查询和检索空间数据(如地理坐标、多边形区域等)的数据结构。空间索引它通过将空间数据划分为可管理的区域或层级结构,加速空间查询操作,如范围查询、最近邻查询和空间连接。
常见的空间索引包括:
- R树:一种平衡树结构,将空间对象组织为嵌套的矩形,适用于动态数据集。
- 四叉树:将空间递归划分为四个象限,适用于静态或均匀分布的数据。
- 网格索引:将空间划分为固定大小的网格单元格,适合简单查询和均匀分布数据。
- GeoHash:将二维坐标编码为一维字符串,支持前缀匹配和范围查询。
空间索引广泛应用于地理信息系统(GIS)、导航软件和位置服务中。
📝 全文索引(Full-text)
全文索引是一种用于快速检索文本内容的技术,它通过分析文档中的词汇并建立词汇到文档的映射,支持关键词搜索、模糊匹配和语义查询。
常见的全文索引技术包括:
- 倒排索引:记录每个词汇出现的文档列表,是全文检索的核心数据结构。
- 前缀树(Trie):用于高效匹配前缀或部分关键词。
- B树/B+树:用于数据库中的文本字段索引,支持范围查询。
全文索引通常支持以下功能:
- 分词处理(如中文分词、停用词过滤)。
- 词干提取和同义词扩展。
- 相关性排序(如TF-IDF、BM25算法)。
全文索引被广泛应用于搜索引擎、文档管理系统和数据库的文本字段查询(如MySQL的FULLTEXT索引、Elasticsearch等)。
索引分类
🏷️ 主键索引(PRIMARY)
基于主键创建,唯一且非空。
每张表有且只有一个。
🔑 唯一索引(UNIQUE)
保证列中值的唯一性,允许有空值。
一张表可以有多个。
📄 常规索引
也叫普通索引,用于快速定位特定数据。
一张表可以有多个。
📖 全文索引
用于查找文本中的关键词,适用于大段文字的搜索场景。
关于索引常见的问题
索引优化策略
选择合适的列建立索引 优先为WHERE子句、JOIN条件、ORDER BY和GROUP BY涉及的列创建索引。高选择性的列(唯一值比例高)更适合建立索引。
复合索引设计 复合索引遵循最左前缀原则。将选择性高的列放在前面,同时考虑查询频率和排序需求。例如:
CREATE INDEX idx_name_age ON users(name, age);
覆盖索引优化 查询只需通过索引即可获取所需数据,避免回表操作。通过EXPLAIN查看Extra列是否为"Using index"。
SELECT id, name FROM users WHERE name = 'Alice';
索引失效场景
违反最左前缀原则 复合索引未从最左列开始使用,导致索引失效。例如索引是(name, age),但查询条件只有age。(这里大家可以去查看博主先前编写的AI面经,也曾提及索引失效问题!)
使用函数或表达式 对索引列使用函数、计算或类型转换会使索引失效。
SELECT * FROM users WHERE YEAR(create_time) = 2023;
使用不等于操作符 !=、<>、NOT IN等操作通常导致索引失效。IN操作符在大多数情况下能使用索引。
LIKE以通配符开头 LIKE '%abc'无法使用索引,而LIKE 'abc%'可以使用。
OR条件不当使用 OR连接的多个条件中,只要有一个列没有索引,整个查询就会全表扫描。
索引使用分析工具
- EXPLAIN
- 慢(
man~牢大)查询日志- 索引选择性计算
EXPLAIN命令 通过EXPLAIN分析查询执行计划,关注type、key、rows、Extra等列:
EXPLAIN SELECT * FROM users WHERE name = 'John';
慢查询日志 开启慢查询日志,识别需要优化的查询:
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2;
索引选择性计算 评估索引效果,选择性越高越好:
SELECT COUNT(DISTINCT column_name)/COUNT(*) FROM table_name;
索引维护建议
定期使用ANALYZE TABLE更新索引统计信息。删除未使用的冗余索引,减少维护开销。对于大表,考虑在线DDL操作或pt-online-schema-change工具减少锁表时间。
监控索引使用情况,通过performance_schema或sys库查询:
SELECT * FROM sys.schema_unused_indexes;