基于类内类间优化的元学习少样本故障诊断方法
基于类内类间优化的元学习少样本故障诊断方法详解
1. 引言
在工业设备故障诊断领域,深度学习技术虽然取得了显著成果,但通常需要大量标注数据进行模型训练。然而在实际工业场景中,收集足够的故障数据往往十分困难,这严重限制了智能诊断方法的应用。本文提出了一种创新的类内类间优化元学习(MLIIO)方法,旨在通过有限的训练数据构建有效的基于度量的故障分类器。
2. 方法原理
2.1 整体框架概述
MLIIO方法基于度量学习元学习(MML)框架,通过设计新型损失函数来优化特征空间。整体诊断流程如图2所示:
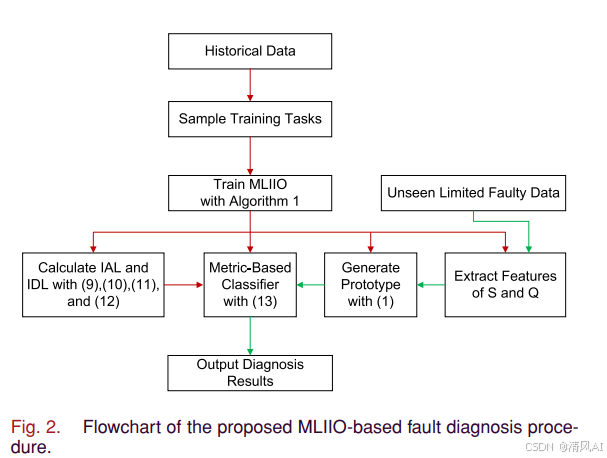
该方法的核心创新在于设计了两个互补的损失函数组件:
-
类内聚合损失(IAL):促使同类样本特征聚集在一起
-
类间判别损失(IDL):强制不同类样本特征保持较大间隔
2.2 类间判别损失(IDL)
传统三元组损失在工业场景中存在局限性,因为单个样本容易受到噪声干扰。MLIIO创新性地使用类别原型间的距离来表示类间差异:
IDL公式:
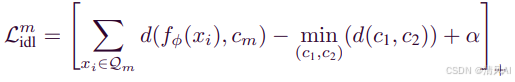
总IDL:
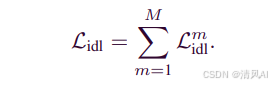
其中d(⋅,⋅)为平方欧氏距离,α为强制间隔,[⋅]+=max(0,⋅)。
该方法的关键优势在于利用原型间的最小距离来表示类间差异,如图1所示,即使锚点样本距离正类原型较近但绝对距离较大时,仍能有效优化特征空间:
2.3 类内聚合损失(IAL)
IAL借鉴中心损失思想,但针对元学习框架进行了改进:
IAL公式:
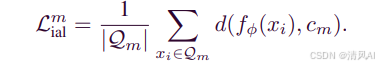
总IAL:
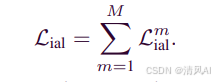
与传统中心损失不同,IAL使用支持集原型cm作为聚合中心,更适合元学习的任务式训练范式。
2.4 整体损失函数
MLIIO的总体损失函数为两个损失的加权和:
![]()
其中λ>0为平衡超参数,根据两个损失的数值范围进行调整。
3. 创新点分析
3.1 理论创新
-
原型间距离度量:首次使用类别原型间的最小距离来表示类间差异,克服了传统三元组损失对噪声敏感的问题
-
元学习适配的聚合损失:改进了中心损失,使其更适合元学习的 episodic 训练机制
-
双重约束优化:同时优化类内紧凑性和类间可分性,形成完整的特征空间优化框架
3.2 技术优势
-
抗噪声能力强:使用原型而非单个样本计算类间差异
-
训练稳定性高:避免了MAML方法的梯度不稳定问题
-
计算效率优:相比两阶段优化的MAML,训练过程更简洁高效
4. 算法实现
4.1 元学习训练流程
MLIIO采用典型的元学习episodic训练机制,算法流程如下:
算法1:MLIIO训练过程
输入:训练数据集𝒟_train,超参数λ, α
输出:优化后的模型参数φ*1: 随机初始化模型参数φ
2: for 每个训练epoch do
3: for 每个episode中的任务𝒟^μ do
4: 从𝒟^μ中随机采样支持集𝒮^μ和查询集𝒬^μ
5: 计算每个类别的原型c_m ← (1/|𝒮_m|)∑f_φ(x_i)
6: 计算总体损失ℒ_total ← ℒ_ial + λℒ_idl
7: 通过梯度下降更新参数:φ ← φ - η∇ℒ_total
8: end for
9: end for
10: return φ*4.2 网络架构设计
MLIIO使用的嵌入网络架构如表II所示:
核心组件:
-
4个卷积模块(Conv-BN-ReLU-MaxPool)
-
特征维度从600压缩到30
-
适用于振动信号和电流信号处理
4.3 关键代码实现
基于PyTorch的核心代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MLIIOLoss(nn.Module):def __init__(self, lambda_param=5e-5, alpha=20):super(MLIIOLoss, self).__init__()self.lambda_param = lambda_paramself.alpha = alphadef forward(self, features, labels, prototypes):"""features: 查询集样本特征 [batch_size, feature_dim]labels: 查询集样本标签 [batch_size]prototypes: 各类别原型 [num_classes, feature_dim]"""batch_size, feature_dim = features.shapenum_classes = prototypes.shape[0]# 计算类内聚合损失(IAL)ial_loss = 0.0for i in range(num_classes):class_mask = (labels == i)if class_mask.sum() > 0:class_features = features[class_mask]class_center = prototypes[i].unsqueeze(0)# 计算样本到原型的距离distances = torch.norm(class_features - class_center, dim=1)ial_loss += distances.mean()# 计算类间判别损失(IDL)idl_loss = 0.0# 计算原型间距离矩阵proto_distances = torch.cdist(prototypes, prototypes, p=2)# 将对角线元素设为无穷大,避免自身比较proto_distances.fill_diagonal_(float('inf'))for i in range(num_classes):# 找到当前类别到其他类别的最小距离min_inter_dist = proto_distances[i].min()class_mask = (labels == i)if class_mask.sum() > 0:class_features = features[class_mask]class_center = prototypes[i].unsqueeze(0)# 计算样本到本类原型的距离intra_dists = torch.norm(class_features - class_center, dim=1)# 计算IDL损失class_idl_loss = F.relu(intra_dists - min_inter_dist + self.alpha)idl_loss += class_idl_loss.mean()total_loss = ial_loss + self.lambda_param * idl_lossreturn total_loss, ial_loss, idl_lossclass PrototypicalNetwork(nn.Module):def __init__(self, input_dim=600, hidden_dims=[300, 100], output_dim=30):super(PrototypicalNetwork, self).__init__()layers = []prev_dim = input_dimfor hidden_dim in hidden_dims:layers.extend([nn.Linear(prev_dim, hidden_dim),nn.BatchNorm1d(hidden_dim),nn.ReLU(),nn.Dropout(0.2)])prev_dim = hidden_dimlayers.append(nn.Linear(prev_dim, output_dim))self.encoder = nn.Sequential(*layers)def forward(self, x):return self.encoder(x)def compute_prototypes(self, support_features, support_labels):"""计算各类别的原型(特征均值)"""unique_labels = torch.unique(support_labels)prototypes = []for label in unique_labels:class_mask = (support_labels == label)class_features = support_features[class_mask]class_prototype = class_features.mean(dim=0)prototypes.append(class_prototype)return torch.stack(prototypes)def episodic_training(model, train_tasks, num_episodes=1000):"""episodic训练循环"""optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)criterion = MLIIOLoss()for episode in range(num_episodes):# 采样一个训练任务support_data, query_data = sample_episode(train_tasks)support_inputs, support_labels = support_dataquery_inputs, query_labels = query_data# 前向传播support_features = model(support_inputs)query_features = model(query_inputs)# 计算原型prototypes = model.compute_prototypes(support_features, support_labels)# 计算损失total_loss, ial_loss, idl_loss = criterion(query_features, query_labels, prototypes)# 反向传播optimizer.zero_grad()total_loss.backward()optimizer.step()if episode % 100 == 0:print(f'Episode {episode}: Total Loss: {total_loss.item():.4f}, 'f'IAL: {ial_loss.item():.4f}, IDL: {idl_loss.item():.4f}')5. 实验验证
5.1 数据集介绍
5.1.1 CWRU轴承数据集
-
10种工作状态(1正常 + 9故障)
-
4种不同负载条件(数据集A、B、C、D)
-
每种故障有3种严重程度
5.1.2 铁路道岔数据集
-
20种工作状态(15正常 + 5故障)
-
基于S700K转辙机的三相电流数据
-
采样频率25Hz,每样本600个测量点
5.2 对比方法
实验与以下先进方法进行对比:
-
MAML:模型无关元学习
-
RN:关系网络
-
PN:原型网络
-
CLPN:中心损失原型网络
-
MLCTL:中心三元组损失元学习
5.3 CWRU数据集结果
表III展示了不同方法在CWRU数据集上的少样本分类准确率:
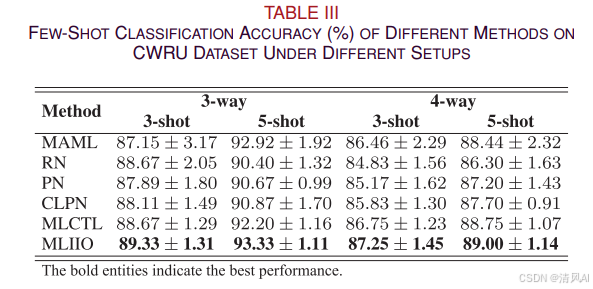
关键发现:
-
MLIIO在所有设置下均取得最佳性能
-
在3-way 5-shot任务中准确率超过90%
-
标准差普遍低于对比方法,表明结果更稳定
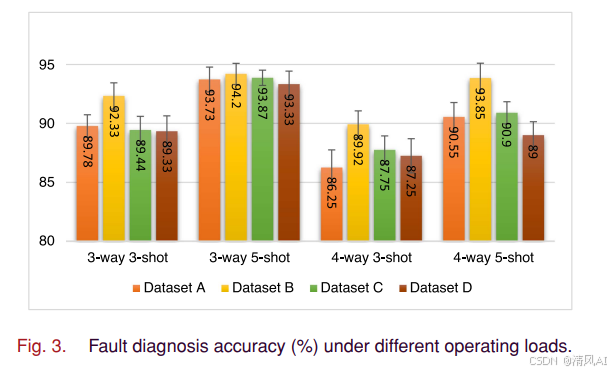
图3显示了不同负载条件下的诊断性能,MLIIO在各种工况下都表现稳健:
5.4 跨场景诊断结果
表IV展示了跨场景任务的诊断准确率: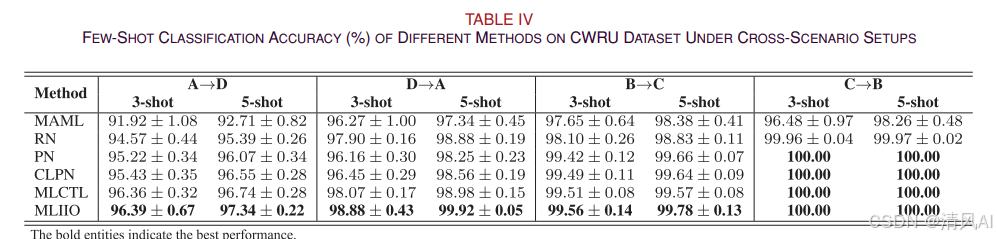
任务A→D(低负载到高负载)最具挑战性,但MLIIO仍保持最佳性能。
5.5 特征可视化分析
图4通过t-SNE可视化展示了不同方法学习到的特征分布:

MLIIO的特征分布显示出最佳的类内紧凑性和类间分离性。
图5的混淆矩阵进一步验证了MLIIO在易混淆故障类型(如球故障BF)上的优越判别能力:
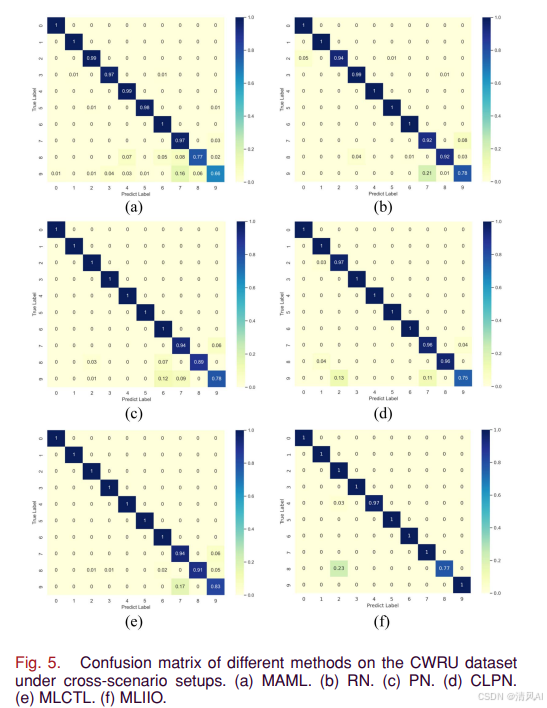
5.6 铁路道岔数据集结果
表VI显示了在真实工业数据集上的结果:
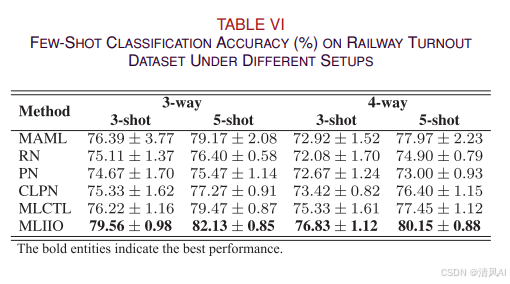
MLIIO在所有设置下均显著优于对比方法,证明了其在真实工业场景中的实用性。
图6的ROC曲线显示MLIIO具有最大的AUC面积:
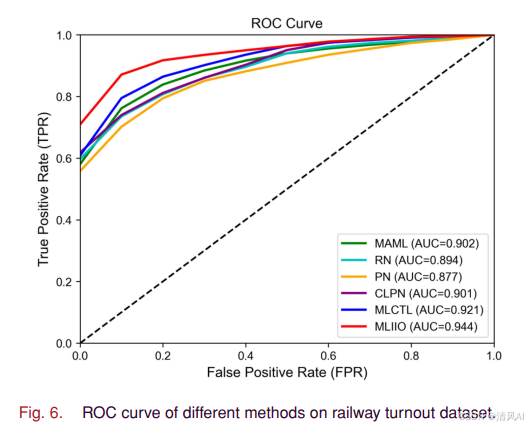
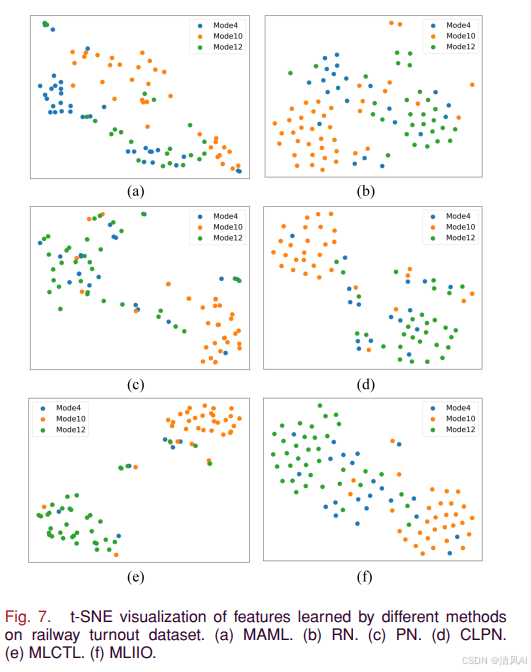
图7的t-SNE可视化再次确认了MLIIO在真实数据上的优越特征学习能力:
6. 消融实验分析
6.1 损失组件贡献分析
通过消融实验验证了两个损失组件的必要性:
-
单独使用IAL或IDL都能带来性能提升
-
两者结合产生协同效应,性能提升最显著
-
λ超参数需要精心调整以平衡两个损失项
6.2 超参数敏感性
实验分析了关键超参数的影响:
-
α(间隔参数):设置为20时效果最佳
-
λ(平衡参数):5e-5在大多数情况下表现良好
-
网络结构对性能有重要影响,需要与任务复杂度匹配
7. 方法优势总结
7.1 技术创新价值
-
理论创新:提出了新的类间距离度量方式
-
实用性强:在多个真实数据集上验证有效性
-
泛化能力好:在不同工况和场景下表现稳健
7.2 工业应用前景
-
适用于数据稀缺的工业故障诊断场景
-
能够快速适应新的故障类型
-
为少样本学习在工业AI中的应用提供了新思路
8. 结论与展望
本文提出的MLIIO方法通过创新的类内类间优化策略,有效解决了少样本故障诊断中的特征学习挑战。实验证明该方法在轴承故障诊断和铁路道岔诊断等实际应用中均表现出色。
未来研究方向:
-
设计针对难诊断故障类型的专用机制
-
结合过程机理知识减少对大量支持集的依赖
-
探索更复杂的工业场景应用
MLIIO为工业智能诊断提供了一种有效的少样本学习解决方案,具有重要的理论价值和实际应用前景。