学pytorch的第一日
一、Dataset类的使用
__init__:构造函数,用于初始化数据集,例如读取数据文件的路径、初始化数据转换函数等。
__len__:返回数据集中样本的数量。
__getitem__:根据索引返回一个样本(数据和标签),并进行必要的预处理(如数据转换)。
二、tensorboard (channel为3)
a.SummaryWriter.add_scalar(tag,y轴,x轴)
b.SummaryWriter.add_image(tag,image,step)
c.SummaryWriter.add_graph(模型,输入)
d.reshape()reshape 只是改变数据的视图(view),而不会改变数据本身在内存中的存储顺序和值。
三、torchvision.transforms
1.torchvision.transforms.ToTensor() 之后的shape为(通道, 高, 宽)
a.PILimage
b.ndarray
c.tensor
2.torchvision.transforms.Normalize()
3.torchvision.transforms.Resize
4.torchvision.transforms.Compose([])
四、DataLoader (将数据集如何交给神经网络)
1.torchvision 处理视觉
2.torchvision.dataset 数据集的各种参数(目录,训练集,transform,download)
3.DataLoader中的各种参数 (数据集,批次,shuffle,drop_last)
a.每次取得数据由数据量 / 批次决定 b.之后的shape为(批次,通道, 高, 宽)
4.查看实例dataloader中的每一个值
for data in dataloader:imgs,targets =data
五、神经网络的基本骨架(写self其他函数也能引用此变量)
1.class Tudui(nn.Module):
2.def __init__(self):
super(Moudel,Self).__init__() Moudel是所要继承的哪个类的最近类
3.def forward(self,input): return(要有返回)
六、卷积层(特征提取 - 核心功能)
每个卷积核可以看作是一个特征检测器。由于每个卷积核的权重是随机初始化并通过训练学习得到的,它们会学习到不同的特征,有多少个输出通道就会产生多少特征图。
1:输入通道个数 等于 卷积核通道个数(卷积核的深度/切片)
2:卷积核个数 等于 输出通道个数
感受野的增大:经过两次池化,第三层卷积的每个神经元对应的感受野(在原始图像上)已经很大。例如,在第三层,一个5x5的卷积核在8x8的特征图上操作,但通过层层映射,它在原始图像上覆盖的区域可能接近整个图像的中心区域。因此,它能够看到更大的结构。
所以高层卷积对低层特征的组合具有高敏感性,因为它们能够整合多个低层特征来形成更有意义的高级特征。
卷积函数functional.conv2d
卷积类nn.Conv2d
1.Conv2d 的参数(in_channels,outchannels,kennel_size,stride,padding)(stride大,padding就会很大不合理)
2.经过卷积输出后的参数(batch_size,channel,h,w)
七、池化层 (降维和减少计算量 -- 提升速度)
保留每个2x2区域中最显著的特征(最大值)
减少特征图的尺寸,从而减少后续层的计算量
提供一定程度的平移不变性(因为只要最大值在池化窗口内,无论它在这个窗口内的哪个位置,输出都是这个最大值)
MaxPool2d的各类参数(kernel_size,stride,cell_model)
cell_model 为ture或者为false的计算公式 output_size = (input_size - kernel_size) / stride + 1
八、非线性激活
relu函数举例 (relu函数对tensor数据无要求,但卷积层之后张量为(batch_size,channel,h,w)
ReLU函数通过将负值设为零、正值保持不变来修改数据。
九、线性层(全连接层)
全连接层将1024个特征组合成64个新的特征,每个新的特征都是原始特征的线性组合。
对输入数据进行一次线性变换(加权求和 + 偏置),将输入特征空间映射到一个新的特征空间。
in_features、out_features、bias偏值是b,y = Wx + b,神经网络对W和b进行调整
计算像素的个数:
CIFAR10图像:3通道 × 32高度 × 32宽度 = 3072个像素
batch_size=64时:64 × 3072 = 196608
torch.flatten()展平,把多维的展平成一维的(可以知道多少个像素)
十、Sequential
1.神经网络层设计时只关心单个样本的维度,但前向传播时自动处理batch维度;
![]()
Sequential就是把模型搞在一起
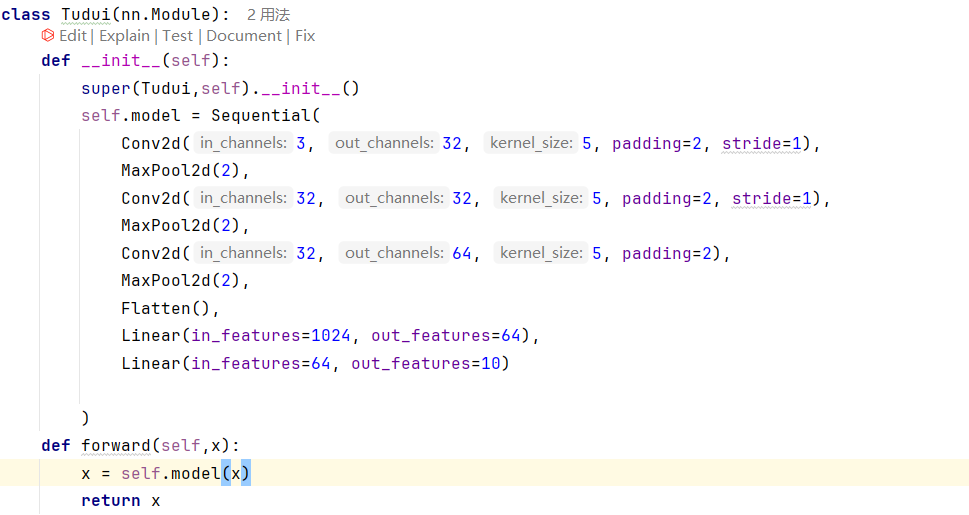
十一、损失函数
损失函数,也称为代价函数或目标函数,是一个用来量化模型预测值与真实值之间差距的函数。
1、计算实际输出和目标之间的差距
2、为我们更新输出提供一定的依据(反向传播)通过grad梯度
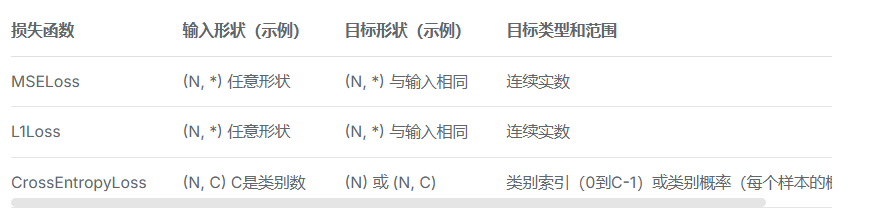

reduction 可以选择方式,是求和还是平均值

结果进行反向传播,backward之后会产生梯度

十二、优化器(optimizer)
![]()
优化器重要的两个参数 parameter、lr
两个用法 归零optim.zero_grad() 通过梯度调优optim.step()
前向传播:输入数据通过网络计算得到预测值。
计算损失:通过损失函数计算预测值与真实值之间的差异。
反向传播:计算损失相对于每个参数的梯度(使用链式法则)。
优化器步骤:根据梯度更新模型的参数

若batch_size是64的话,result_loss 是一个标量张量,它是64个样本损失的平均值。 result_loss.backward() 计算损失相对于模型参数的梯度,这里会计算64个样本的平均梯度(在这个平均损失上执行反向传播,梯度是平均损失相对于模型参数的梯度)。