AI编程 -- LangChain
一、概述
官网地址:Introduction | 🦜️🔗 LangChain
最新文档地址:LangChain Overview - Docs by LangChain
1.1、简介
- 随着大语言模型(LLM)在各类应用中快速发展,仅依靠单一的模型输出已经难以满足复杂的业务需求。此时,LangChain作为一个专为构建基于语言模型的应用程序而设计的框架,提供了一种模块化、可拓展、易于集成的解决方案。
LangChain是一个开源框架,它的核心目标是帮助开发者更轻松地将LLM与外部世界连接起来,是一个连接大模型与真实任务的编排中枢, 为很多问题提供了标准化的解决方案和封装接口,极大简化了开发流程,包括:- 文本、文档、数据库、API等外部数据源;
- 用户的输入/输出流程控制(多轮对话、工具调用、工作流编排)。
- 向量数据库检索、RAG、Agent、多模型协作等高级能力封装。通过使用LangChain,我们可以解决如下问题。
- 如何把用户问题与知识文档联系起来?
- 如何在多个步骤中使用 LLM?
- 如何管理记忆、多轮对话和上下文?
- 如何在生成前引入数据、工具或函数?
- 通过使用LangChain,可以轻松使用以下类型的应用:
- 基于知识库的问答系统(结合RAG的检索机制)
- 多轮对话助手(自动记忆上下文)
- Agent智能体(自动调用工具,如搜索、计算、数据库查询)
- 文档解析与摘要生成
- 编排多个模型或服务的复杂任务链
1.2、准备工作
- 从阿里百炼Dashscope平台获取api调用在线的大模型。阿里百炼平台的优势有以下几点:
- 阿里的大模型一直处于国内第一梯队,其研发的Qwen系列大模型的能力在全球稳居前列
- 对于每一位开发者,开放了几乎所有大模型的100万个免费token,可以0成本学习使用
- 模型种类丰富,包含每种Qwen系列模型的各种参数模型,以及多模态、向量化、重排等模型,可以用于解决多种领域的问题
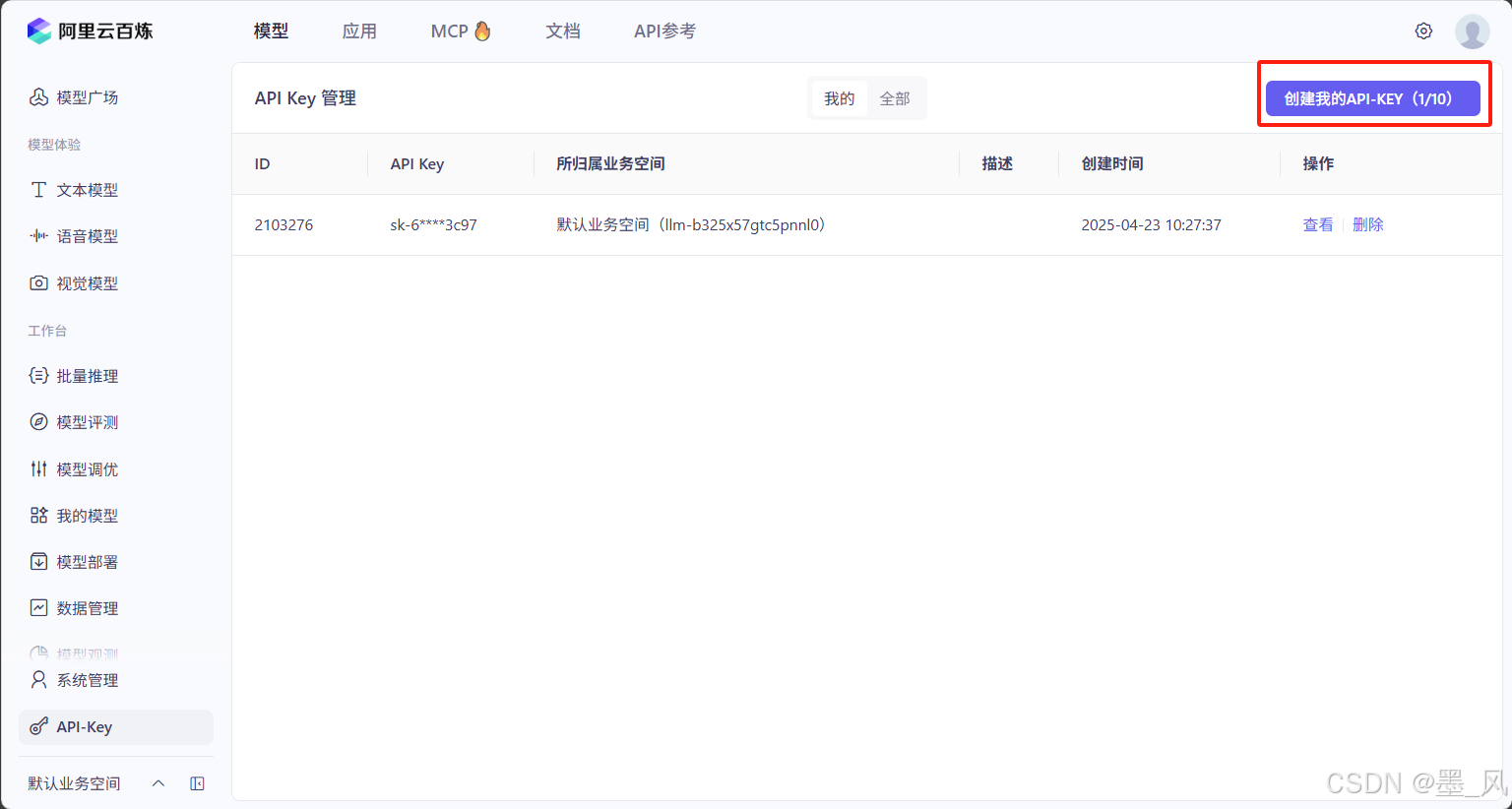
- 点击大模型服务平台百炼控制台进行注册认证,然后获取自己的API-KEY,这个API-KEY之后会用到。
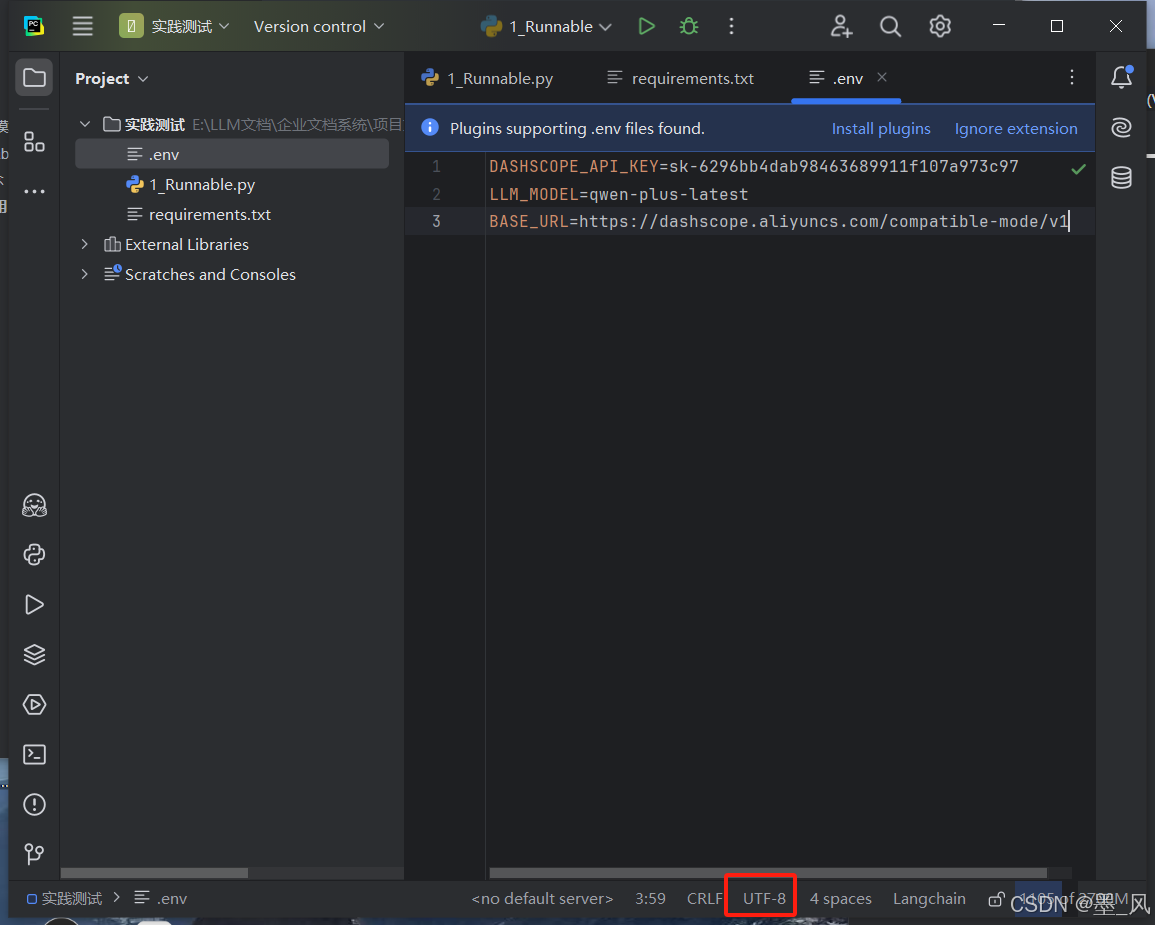
- 使用Pycharm创建一个新项目文件,将项目解析器设置为Anaconda下的Python3.10。在项目文件下创建一个**.env**文件,注意,一定要使用UTF-8编码,否则后续无法正常读取环境信息。创建完成后,加入以下内容
#替换为你自己的API-KEY
DASHSCOPE_API_KEY=sk-6296bb4dab98463689911f107a973c97
QWEN_LLM_MODEL=qwen-plus-latest
BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
1.3、LangChain相关依赖的下载
在Anaconda Prompt中输入以下指令查看目前拥有的环境
conda env list
然后使用激活环境指令
conda activate YOUR_ENV
执行依赖安装命令,从清华镜像源进行下载,
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
requirements.txt
python-dotenv
langchain
langchain-core
langchain-openai
openai
typing-inspect
typing_extensions
需要一个文件,文件中需要指明下载的依赖环境,如果没有则会error; **必须将requirements.txt文件拷贝到项目目录中与.env同级
ERROR: Could not open requirements file: [Errno 2] No such file or directory: 'requirements.txt
二、基本模块
2.1、可运行单元(Runnable)
2.1.1、Runnable的概念
- 在LangChain中,所有可以执行的东西,无论是大语言模型、提示模板、工具调用、检索器还是自定义函数,都被抽象成了一个统一的接口Runnable。
- 简单理解:可以把 Runnable 看作是
可以输入数据 → 执行处理 → 返回结果的模块。
2.1.2、Runnable的详解
LangChain引入了Runnable的概念,它就像一个“标准化的处理模块”,能够:- 把不同类型的组件(如:模型、函数、检索器)都统一看作“可以运行”的单元;
- 支持像搭积木一样,把多个功能按顺序串起来,构建处理链;
- 提供
invoke()、ainvoke()等简洁的方法来同步或异步调用链。这就像把 AI 应用开发“流水线化”,让复杂流程可以拆解、组合、调试。以下是LangChain官方对于Runnable部分的文档:Runnable interface | 🦜️🔗 LangChain
2.1.3、Runnable的使用
- LangChain的Runnable通过管道符将各个组件连接在一起,进而构成一个完整的可运行链。下面我们来做一个简单的实践去体验一下。以下是此程序的流程。
- 从环境中获取了大模型的AKI-KEY、模型名称、url
- 初始化llm
- 初始化提示词prompt
- 构造Runnable chain
from dotenv import load_dotenv
import os
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI# 加载环境变量,从根目录的.env文件中读取环境变量,并将这些变量加载到当前进程中。之后这些变量可以通过os.getenv()获取。
load_dotenv()def main():# 获取API密钥api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')# 初始化大模型,使用OpenAI架构调用Dashscope#ChatOpenAI来自langchain_openai包,用于与支持OpenAI兼容API的大语言模型进行交互的接口。这里的Dashscope平台的大模型提供了与OpenAI API兼容的接口llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,temperature=0.7,)# 固定提示词prompt = "你好,请简单介绍一下你自己"#使用RunnableLambda封装器将字符串转换为LangChain的可执行对象,让prompt可以作为工作流中的节点使用prompt_runnable = RunnableLambda(lambda _: prompt)# 链式结构更清晰chain = prompt_runnable | llm# 执行链式调用,invoke函数需要传递进一个参数,如果没有参数则传入空字典进行占位response = chain.invoke({})print(response.content)if __name__ == "__main__":main()
追加流式输出:
# 想要流式输出response = chain.stream({})for result in response:# 获取到响应结果print(result.content, end="", flush=True)
- 部分代码解析
RunnableLambda是LangChain框架中的一个包装器类- 作用:将普通的Python函数或数据类型转换为LangChain可以识别的可执行对象
- 让函数能够在LangChain的工作流中作为节点使用
lambda:prompt:匿名函数lambda:定义匿名函数的关键字_:参数占位符,表示接受一个输入,但是无所谓此输入是什么。使用_的好处是保持代码整洁,这里其实也可以不使用下划线,比如写为lambda x:prompt,但x会显得较为多余,这里使用下划线更清晰表明这个参数是忽略的
-
response = chain.invoke({}):获取响应结果.invoke():执行链条{}:空的字典参数- 表示不向链条传递任何输入变量
- 链条将使用其内部定义的默认值或提示模板
- 为什么一定要传入这个空字典?
invoke()被设计为必须接受一个参数,这是为了保持API的一致性invoke的内部处理逻辑中,LangChain内部需要这个参数进行流程的运行,所以如果不给invoke传入一个参数的话,则无法使用。在没有需要传递的参数时需要传入一个空字典{}
def invoke(self, input):# 1. 验证输入格式,isinstance用于检查对象类型,如果这里的str不是字典则会报错if not isinstance(input, (str, dict)):raise ValueError("Input must be string or dict")# 2. 处理输入(即使是空的)#self表示对当前对象实例的引用,_process_input中,下划线表示是一个私有方法,不会暴露给外部使用,此方法用于处理输入processed_input = self._process_input(input)# 3. 执行链条逻辑,将上一步处理的输入用result进行承接result = self._execute(processed_input)return result
- 固定提示词
prompt = "你好,请简单介绍一下你自己"
prompt_runnable = RunnableLambda(lambda _: prompt)
# 你好!我是Qwen,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。我支持多种语言,包括但不限于中文、英文、德语、法语、西班牙语等。如果你有任何问题或需要帮助,欢迎随时告诉我!
2.2、模型(Models)
2.2.1、Models的概念
- 在LangChain中,Models模块在整个框架中有着很重要的地位,它负责调用和封装各种LLM或嵌入模型。这使得可以轻松接入 OpenAI、Anthropic、阿里通义、百度文心、Azure、Hugging Face 等平台的模型无缝接入到你的应用中。在这里,我们接入两个阿里百炼平台上的模型,分别是qwen-plus-latest和deepseek-v3
- 配置的时候在.env环境配置文件中加入:
QWEN_LLM_MODEL=qwen-plus-latest
DEEPSEEK_LLM_MODEL=deepseek-v3
- 在开发大模型应用的时候,模型的选择和调用方式往往对项目起到了极大的影响。不同的模型有着不同的语言特点、理解能力以及参数大小。永远没有一个绝对意义上优于一切的模型,这里主要需要考虑模型能力与参数量大小两个最重要的指标。
- 模型的能力与两个重要因素有关,分别是模型的本身设计以及该模型的参数量版本。模型本身的设计是其优秀与否的最根本基础,比如说Qwen系列的Qwen2、Qwen2.5、Qwen3,他们属于一种不断发展的形态,大模型领域迭代速度非常的快,后来者的能力往往会在短短几个月内就明显优于前者。
- 其次是模型参数量这个因素,每个开源的大模型都会提供其各种参数量版本的模型文件,比如0.5b、1.5b、7b、14b等等,参数量越大代表这个模型训练得越成熟,但也意味着更高的部署成本和模型大小。在开发大模型的时候无论是调用在线服务还是本都部署,成本都会与模型参数量大小紧紧关联,所以选取一个合适与当前任务目标的参数量模型也是很重要的一步,要避免资源的浪费,也要避免选择到了能力不足以胜任工作的模型。
2.2.2、温度(Temperature)
温度是控制LLM输出随机性和创造性的一个重要参数,决定了模型在生成文本时对概率分布的平滑程度。
- 温度参数
- 取值范围:通常是0.0到2.0之间
- 默认值:通常在0.7或1.0
- 温度值的影响
- 低温(0.0 - 0.3)
- 特点:输出更加确定和一致
- 行为:模型倾向于选择概率最高的词汇
- 适用场景:
- 事实问答、代码生成、翻译任务
- 中温(0.4 - 0.7)
- 特点:平衡确定性和创造性
- 行为:在保持合理性的同时允许一定变化
- 适用场景
- 一般对话、内容创作、日常任务
- 高温(0.8 - 1.2)
- 特点:输出更加多样性和创造性
- 行为:模型更愿意选择概率较低的词汇
- 适用场景
- 创意写作、故事生成
- 低温(0.0 - 0.3)
- 数学原理
- P ′ ( t o k e n ) = P ( t o k e n ) ( 1 / t e m p e r a t u r e ) P'(token) = P(token)^(1/temperature) P′(token)=P(token)(1/temperature)
- 当温度 = 1 时,概率分布保持不变
- 当温度 < 1 时,高概率词汇的概率被放大
- 当温度 > 1 时,概率分布被"平滑",低概率词汇获得更多机会
2.2.3、Models的使用
- 在使用模型调用的时候,会涉及到以下几个功能:
| 步骤 | 说明 |
|---|---|
model=model_name | 动态选择模型(如 qwen-plus-latest、deepseek-v3) |
temperature=0.7 | 控制生成文本的“随机性”,数值越高回答越灵活 |
llm.invoke(prompt) | 执行调用,将用户输入发送给模型 |
.content | 提取模型返回的实际文本内容 |
- 这里我们可以按照上一部分的Runnable中的演示案例进行详细分析。
- 这里是定义了
model的相关配置信息,便于之后的调用。
api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')
- 初始化了的大模型,使用OpenAI架构去调用Dashscope的相关配置信息,并且对温度进行设置。
llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,temperature=0.7,)
- 构造提示词,并将其转换为Runnable形式
prompt = "你好,请简单介绍一下你自己"
prompt_runnable = RunnableLambda(lambda _: prompt)
- 构造Runnable链,将上述的llm和prompt放入链中
chain = prompt_runnable | llm
- 提取模型返回的实际文本内容,进行输出。这里使用了
print()函数进行操作,在实际的项目中,可以将response.content作为参数或者返回值进行后续的传递。
print(response.content)
输出
# qwen-plus-latest
你好!我是Qwen,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。我支持多种语言,包括但不限于中文、英文、德语、法语、西班牙语等。如果你有任何问题或需要帮助,欢迎随时告诉我!# deepseek-v3
你好!我是 **DeepSeek Chat**,由深度求索公司(DeepSeek)开发的智能 AI 助手。我可以帮助你解答问题、提供信息、协助写作、分析数据、编程辅助等。我的知识截至 **2024 年 7 月**,支持 **128K 上下文**,还能读取并分析 **txt、pdf、ppt、word、excel** 等文件内容。 **我的特点包括:**
✅ **免费使用**:目前没有任何收费计划。
✅ **超长上下文**:能处理复杂对话和长文档。
✅ **多语言支持**:可以用中文、英文等多种语言交流。
✅ **文件解析**:可帮助你从上传的文档中提取关键信息。 如果你有任何问题,无论是学习、工作还是日常需求,都可以问我!😊 你今天想聊些什么呢?
2.3、提示词(Prompt)
2.3.1、Prompt的概念
- 在LangChain中,Prompt是与LLM进行交互的核心方式。它是用户提供给LLM的输入,用于引导模型产出期望的输出。可以通过设计Prompt影响模型的行为后回答。
- LLM虽然对于Prompt的容错性很高,但为了构造一个高质量的Prompt,我们可以按照RAFT Prompt 构造模式进行编写Prompt。
R = Role(角色设定)告诉模型“你是谁”,为回答设定上下文身份,有助于控制语气、准确性等。A = Action(任务指令)明确告诉模型“你需要做什么”, 这一步很重要,一定要避免歧义。F = Format(输出格式)让模型输出想要的结构,比如JSON、自然语言、Markdown格式等。T = Tone(语气/风格)(可选)控制模型回答的风格,比如“简洁”、“专业”、“面向儿童理解”等。
2.3.2、Prompt的使用
在这里我们可以使用两种截然不同的风格prompt去运行测试,观察其不同的效果
from dotenv import load_dotenv
import os
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI# 加载环境变量
load_dotenv()def main():# 获取API密钥api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')# 初始化大模型,使用OpenAI架构调用Dashscopellm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,)# 固定提示词question= "你好,请问怎么骑自行车"professor_prompt = ("# 角色定位: 你是一位拥有博士学位的学术顾问和专业研究人员\n""# 任务指令: 分析用户提出的问题,提供一个基于研究和数据的专业回答。包括:\n""- 对问题进行概念界定\n""- 分析不同观点和理论\n""- 给出有深度的见解和结论\n""# 输出格式: \n""- 使用学术论文风格的结构化回答\n""- 控制回答长度在150-200字左右\n""- 每一句话自然换行一次,增强可读性\n""- 可以适当引用研究数据(无需具体引用格式)\n""# 语气风格: \n""- 严谨、客观、专业\n""- 使用学术性和专业性术语\n""- 避免情绪化或主观判断的表达\n"f"\n用户问题: {question}")professor_prompt_runnable = RunnableLambda(lambda _: professor_prompt)friend_prompt = ("# 角色定位: 你是用户的一位亲密好友,性格开朗活泼\n""# 任务指令: 针对用户的问题,提供一个轻松友好的回答,就像你们在咖啡厅闲聊一样。请:\n""- 用简单易懂的方式解释问题\n""- 分享一些生活化的例子或比喻\n""- 加入一些个人观点或建议\n""# 输出格式:\n""- 使用简短段落和日常对话风格\n""- 控制回答长度在150-200字左右\n""- 每40-50个字左右自然换行一次,增强可读性\n""- 可以使用表情符号增加亲切感\n""# 语气风格:\n""- 轻松、友好、活泼\n""- 充满热情和幽默感\n""- 像朋友间聊天一样自然随意\n"f"\n用户问题: {question}")friend_prompt_runnable = RunnableLambda(lambda _: friend_prompt)friend_chain = friend_prompt_runnable | llmprofessor_chain = professor_prompt_runnable | llmprofessor_response = professor_chain.invoke({})print("————————————————————研究人员提示词————————————————————")print(professor_response.content)friend_response = friend_chain.invoke( {})print("————————————————————亲密好友提示词————————————————————")print(friend_response.content)if __name__ == "__main__":main()
输出:
————————————————————亲密好友提示词————————————————————
哎呀,想学骑车啊?超简单的!
咱们先从平衡开始找感觉~
就像端着一杯奶茶不洒那样 你找个空地,先用脚蹬着滑行
感受车子不倒的节奏
等找到平衡感了
再慢慢加上踩踏板的动作 我当初学的时候可有意思了
摔了几次才发现
其实放松心态最重要!
别攥着车把太用力哦~
对了,戴个酷酷的头盔也很重要呢 ✨ 等你学会了
咱们就可以一起去骑行啦!🚴♀️💨————————————————————研究人员提示词————————————————————
骑自行车涉及一系列协调的运动技能与平衡机制。
从概念上讲,骑行过程依赖于身体的本体感觉、视觉反馈以及下肢的周期性运动控制。
研究表明,初学者主要通过试错学习调整重心与方向(Adolph et al., 2019)。
主流理论认为,保持平衡是通过前庭系统与躯体感觉系统的整合实现的(Peterka, 2002)。
此外,研究指出,掌握骑行技能通常需要3到10次练习,每次持续20至60分钟(Schmidt & Lee, 2014)。
综上所述,骑自行车是一个多感官整合与动作协调的过程,需通过反复练习逐步建立神经肌肉控制能力。
2.4、记忆(Memory)
2.4.1 Memory的概念
记忆(Memory)是在LangChain中用于多轮对话中保存和管理上下文信息的组件,它让应用能够记住用户之前说了什么,从而进行更连贯、更自然的对话。
2.4.2 Memory的使用
- 下面的例子提供了一段完整的Memory使用案例
1. 加载环境变量
2. 创建main函数
1. 获取大模型环境变量
2. 初始化大模型
3. 创建会议记忆对象ConversationBufferMemory
4. 定义函数拼接历史问题
5. 构建链式调用传递LLM
6. 定义字典提出多个问题,并调用大模型进行回答输出
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain_core.runnables import RunnableLambda# 加载环境变量
load_dotenv()def main():api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')# 初始化大模型llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,)# 创建对话记忆对象#ConversationBufferMemory是LangChain中的对话记忆类,可以在内存中存储对话历史,支持多轮对话的上下文管理#对话历史以chat_history键存储在记忆中#输入内容以question键存储#对话的输出内容以answer键存储#return_messages=True 控制返回格式以对象形式,而不是纯文本memory = ConversationBufferMemory(memory_key="chat_history",input_key="question",output_key="answer",return_messages=True)# 构造链:输入问题 -> 拼接历史和问题 -> LLMdef build_prompt(inputs):#load_memory_variables({})表示从记忆中加载所有存储的变量,这里的{}表示无需传入参数,传人空字典占位即可。这里从返回的字典中提取chat_history键对应的值chat_history = memory.load_memory_variables({})["chat_history"]question = inputs["question"]return f"历史对话:{chat_history}\n用户: {question}"#这里传入RunnableLambda中的是一个函数,而不是固定值,所以无需Lambda表达式即可传入prompt_runnable = RunnableLambda(build_prompt)chain = prompt_runnable | llm# 多轮对话演示questions = ["你好,请介绍一下你自己。","你能记住我刚才说的话吗?","请用一句话总结我们的对话。"]for q in questions:response = chain.invoke({"question": q})print(f"用户: {q}")print(f"AI: {response.content}\n")# 保存到记忆memory.save_context({"question": q}, {"answer": response.content})if __name__ == "__main__":main()
- 具体解析:创建一个对话记忆对象
memory,用于存储和管理多轮的历史内容- memory_key=“chat_history”:历史内容会以 chat_history 这个key存储。
- input_key=“question”:每轮对话的输入字段名为 question。
- output_key=“answer”:每轮对话的输出字段名为 answer。
- return_messages=True:历史内容以消息对象的形式返回,便于后续处理。
memory = ConversationBufferMemory(memory_key="chat_history",input_key="question",output_key="answer",return_messages=True
)
- 自定义函数
build_prompt,用于动态生成大模型的输入内容(prompt)。- inputs:是一个字典,包含当前用户输入的问题(如 {“question”: “你好,请介绍一下你自己。”})。
- memory.load_memory_variables({})[“chat_history”]:从记忆对象中读取当前所有历史对话内容。
- {}是空字典参数,用于在没有参数需要传递时传入load_memory_variables()中,从而满足处理逻辑
- [“chat_history”]表示从返回的字典中获取特定的键值,这里是从字典中获取chat_history的值
- question = inputs[“question”]:取出本轮用户输入的问题。
- 返回值:将历史对话和当前问题拼接成一个完整的 prompt,作为大模型的输入。
def build_prompt(inputs):chat_history = memory.load_memory_variables({})["chat_history"]question = inputs["question"]return f"历史对话:{chat_history}\n用户: {question}"
把build_prompt函数包装成一个可链式调用的节点。用管道符 | 把prompt生成节点和大模型节点串联起来,形成一个完整的“处理链”。
prompt_runnable = RunnableLambda(build_prompt)
chain = prompt_runnable | llm
- 遍历每一个问题 q。
- 用
chain.invoke({"question": q})执行链式调用:- 先把
{"question": q}传给prompt_runnable,拼接历史和当前问题。 - 再把拼接好的
prompt传给LLM,获得回答。
- 先把
- 打印本轮回答
- 用
memory.save_context({"question": q},{"answer": response.content})把本轮问答存入记忆,为下一轮对话做准备。
questions = ["你好,请介绍一下你自己。","你能记住我刚才说的话吗?","请用一句话总结我们的对话。"
]for q in questions:response = chain.invoke({"question": q})print(f"用户: {q}")print(f"AI: {response.content}\n")# 保存到记忆memory.save_context({"question": q}, {"answer": response.content})
测试:
用户: 你好,请介绍一下你自己。
AI: 你好!我是Qwen,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,欢迎随时告诉我!用户: 你能记住我刚才说的话吗?
AI: 是的,我可以记住我们之前的对话内容。在我们的交流中,我会尽量保持上下文的一致性,以便更好地理解和回应你的问题。如果你有特别需要我记住的信息,也可以随时告诉我,我会尽力帮助你保存和回忆这些信息。不过,请注意,为了保护用户隐私和数据安全,具体的记忆能力可能会受到一定限制,并遵循相关的隐私政策。用户: 请用一句话总结我们的对话。
AI: 你询问了我的自我介绍和记忆能力,我介绍了自己并说明了可以记住对话内容的能力及限制。
2.5、模式(Schema)
2.5.1、Schema的概念
Langchain中Schema是一套用于规范LLM输入输出格式的标准接口和结构定义,其核心目标是:- 模块化抽象:把人类消息、AI回复、文档内容、训练示例等概念标准化。
- 兼容多种LLM场景:如对话系统、文档问答、链式调用等。
- 提高模型交互效率与一致性Schema覆盖了多个类型,包括:
- 聊天消息类:
ChatMessage/HumanChatMessage/AIChatMessage - 文档对象:
Document - 示例(Example):Few-shot 提示用的输入/输出对
- 纯文本(Text):最基础的输入输出类型
- 聊天消息类:
- 聊天消息类
- ChatMessage最基础的消息类型,它只指定了一个角色名和消息内容,灵活但语义不明确。
- HumanChatMessage是ChatMessage的语义化版本,明确表示消息是“人类发送的”。
- AIChatMessage表示是AI模型生成的消息内容。
- Document文档是用于存储文本和其原信息的结构,广泛用于RAG、摘要、分类等场景。
- ExampleExample是在Few-shot Prompt中用于告诉模型“我希望你这样回答”的训练样本结构,本质是一个输入输出对。
- Text最原始的输入格式,只是简单的字符串,没有结构化语义,不适合复杂对话、多轮聊天、上下文追踪。
2.5.2、Schema的使用
- 加载环境变量
- 定义函数初始化大模型
- 创建不同类型的消息
- 打印消息类型与内容
- 使用消息列表调用LLM
- 输出大模型回复与回复类型
举例:在下面的案例中,体现了schema中的ChatMessage、HumanChatMessage、AIChatMessage的功能
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage# 加载环境变量
load_dotenv()def main():# 获取API密钥api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')# 初始化大模型llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,)# 创建不同类型的消息# 这里的content的作用在于明确参数功能,因为这三种方法中也可以传入其他配置参数,比如role、metadata。这里指定后可以避免混淆,且增强代码可读性system_message = SystemMessage(content="你是一个友好的助手")human_message = HumanMessage(content="你好,请介绍一下你自己")ai_message = AIMessage(content="你好!我是AI助手,很高兴为你服务。")# 打印消息类型和内容print(f"SystemMessage: {system_message.content}")print(f"HumanMessage: {human_message.content}")print(f"AIMessage: {ai_message.content}")# 使用消息列表调用LLMmessages = [system_message, human_message]response = llm.invoke(messages)print(f"\nLLM回复: {response.content}")print(f"回复类型: {type(response)}")if __name__ == "__main__":main()
具体解析:这里是对三种类型的聊天信息进行了定义,并通过输出检验。
system_message = SystemMessage(content="你是一个友好的助手")human_message = HumanMessage(content="你好,请介绍一下你自己")ai_message = AIMessage(content="你好!我是AI助手,很高兴为你服务。")print(f"SystemMessage: {system_message.content}")print(f"HumanMessage: {human_message.content}")print(f"AIMessage: {ai_message.content}")
调用llm进行回答,将system_message、human_message作为参数传入。在输出检验的时候,不仅输出返回消息内容,并且输出检验了消息的类型。
messages = [system_message, human_message]
response = llm.invoke(messages)print(f"\nLLM回复: {response.content}")
print(f"回复类型: {type(response)}")
结果:
SystemMessage: 你是一个友好的助手
HumanMessage: 你好,请介绍一下你自己
AIMessage: 你好!我是AI助手,很高兴为你服务。LLM回复: 你好!我是Qwen,是阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以帮助你回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。我支持多种语言,包括但不限于中文、英文、德语、法语、西班牙语等。如果你有任何问 题或需要帮助,随时告诉我!
回复类型: <class 'langchain_core.messages.ai.AIMessage'>
三、提示词工程
3.1、提示词工程的概念
- 当人类与LLM进行交互时,最根本的原理其实就是人类构造好一段信息发送给大模型,大模型返回针对于这段信息的回复。这个过程看似简单,实则可以进行精细化拆解、分析,进而通过提示词工程实现更好的调用LLM。
- 提示词工程(
Prompt Engineering) 是指设计、优化和调整输入给大语言模型(LLM)的文本指令(提示词/Prompt),以获得更准确、更有用、更符合预期的输出结果的技术和方法。简单来说,就是"如何更好地跟AI说话",让AI理解你的意图并给出你想要的答案。
3.2、提示词工程的核心原则
3.2.1、清晰性
- 使用简洁明确的语言
- 避免歧义和模糊表达
- 具体说明想要的需求
示例:
- 告诉我Python的知识 ( 不好 × )
- 请解释Python中列表与元组的区别,并且给出代码示例 ( 好 √ )
##3.2.2、具体性 - 提供足够的上下文信息
- 明确指出输出格式
- 给出具体的要求和限制
示例:
请为一家咖啡店写一段50字左右的营销文案,
要求:温馨、亲切的语调,突出手工制作和新鲜原料。
3.2.3、结构化
- 使用清晰的段落结构
- 用标记或编号组织信息
- 分步骤给出指令
3.3、提示词工程的核心技巧
3.3.1、角色扮演
# 角色定位
你是一位拥有10年经验的[专业领域]专家# 任务
请针对[具体问题]给出专业建议# 要求
- 使用专业术语
- 给出具体可行的方案
- 控制回答长度在200字内
3.3.2、思维链
引导AI逐步思考,提高推理质量。
请逐步分析这个数学问题:
1. 首先理解题目要求
2. 列出已知条件
3. 确定解题思路
4. 逐步计算
5. 验证答案问题:一个班级有30名学生...
3.3.3、少样本学习
提供几个示例,让AI理解期望的输出格式
请逐步分析这个数学问题:
1. 首先理解题目要求
2. 列出已知条件
3. 确定解题思路
4. 逐步计算
5. 验证答案问题:一个班级有30名学生...
3.3.4、分步指令
请帮我制定学习计划,按以下步骤:
1. 分析我的当前水平
2. 确定学习目标
3. 制定时间安排
4. 推荐学习资源
5. 设定检查节点我的情况:[具体描述]
3.4、提示词优化技巧
3.4.1、迭代改进
- 先写基础版本
- 测试效果
- 根据结果调整
- 持续优化
3.4.2、添加约束条件
请回答以下问题,但要遵守这些规则:
- 回答长度不超过100字
- 不要使用专业术语
- 必须包含至少一个实例
- 语调要友好亲切
3.4.3、使用输出格式化
请按照以下JSON格式回答:
{"answer": "主要回答内容","confidence": "置信度(1-10)","sources": ["相关来源1", "相关来源2"]
}
四、流式输出与非流式输出
4.1、流式输出与非流式输出的意义
- 在构建LLM应用的时候,用户与模型之间的交互方式非常重要。无论是开发一个聊天机器人、文档问答系统、代码助手,模型如何响应都直接决定了用户的使用体验。
- 在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。这两种模式对于用户感知速度。交互流畅度、系统反馈能力上有着很大的区别。
- 下面是两个场景,可以体现出其之间的差别:
- 用户提问,请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌,这是非流式输出
- 用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句进行回复,仿佛在一边思考一百年输出,这是流式输出。非流式输出如同一种“提交请求,等待结果”的流程,而流式输出更像是“实时对话”,更为贴近人类交互的习惯。在现代应用中,用户往往更期望系统可以即刻响应。
- 作为开发者,我们在开发的时候要根据实际需求恰当地指定开发策略:非流式实现简单,但体验单调;流式更有吸引力,但是实现更为复杂。因此本章中会全面介绍这两种输出技术。
4.2、非流式输出
- 非流式输出是Langchain中与LLM交互时的默认行为:当用户发出请求后,系统在后台等待模型生成完整响应,然后一次性将全部结果返回。在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。在之前演示的全部案例均为非流式输出。
- 通过非流式输出,Langchain 为开发者提供了最简单、最稳定的语言模型调用方式。如果你正在构建一个以准确回答、稳定返回为核心的应用,非流式输出通常是最稳妥的起点。接下来的部分,我们将深入介绍流式输出的使用方式与其带来的交互体验提升。
4.3、流式输出
- 流式输出(Streaming Output)是一种更具交互感的模型输出方式,它允许大语言模型边生成、边输出内容。换句话说,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容,就像“打字机”在眼前慢慢敲出一段话。
- Langchain 中通过设置
stream=True并配合 回调机制(CallbackHandler) 来启用流式输出。它适合构建强调“实时反馈”的应用,如聊天机器人、写作助手等。 - 以下是一个流式输出的例子
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableLambda
from langchain_core.messages import HumanMessage, SystemMessage# 加载环境变量
load_dotenv()def main():# 获取API密钥api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')# 初始化支持流式输出的大模型llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,streaming=True)# 构建消息格式化函数def format_messages(inputs):question = inputs["question"]return [SystemMessage(content="你是一个友好的助手。"),HumanMessage(content=question)]# 创建Runnable链:输入 -> 格式化消息 -> LLM流式输出message_formatter = RunnableLambda(format_messages)streaming_chain = message_formatter | llm# 测试流式输出question = "请介绍一下Python编程语言的特点"print(f"问题:{question}")print("回答:", end="", flush=True)# 使用链进行流式输出for chunk in streaming_chain.stream({"question": question}):print(chunk.content, end="", flush=True)print() # 换行if __name__ == "__main__":main()
详解:在构造llm的时候把streaming设置为true
llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url,streaming=True)
设置end=“”,取消自动换行。设置flush=True,Python会把输出暂存在缓冲区,等缓冲区满了或程序结束时才显示。设置 flush=True:立即强制显示,不等缓冲区。之后使用链进行流式输出。
print("回答:", end="", flush=True)# 使用链进行流式输出for chunk in streaming_chain.stream({"question": question}):print(chunk.content, end="", flush=True)
这里的streaming=true与.stream()都是与流式输出相关的配置。但是这里的**.stream()以及非流式输出调用的.invoke()都会覆盖掉streaming的设置,因此在通过Runnable链使用LLM的时候可以忽略这个选项**。streaming的用处在于当使用一些其他方法去调用LLM的时候,可以控制是否采用流式输出,streaming的默认值为true。
五、MCP与Function Calling
- 在大模型应用开发领域,Function Call(函数调用)曾经是让大语言模型具备“动手能力”的重要技术。它允许模型在理解用户自然语言的基础上,自动调用后端预定义的函数或 API,将外部数据和操作能力引入到对话和推理流程中。这一机制极大地拓展了大模型的应用边界,让模型不仅能“说”,还能“做”。
- 然而,随着大模型应用场景的不断复杂化,Function Call 的局限性逐渐显现:它通常只支持单步、单函数的调用,难以灵活应对多步骤、多工具协作的复杂业务需求。为了解决这些问题,MCP(Multi-Component Pipeline,多组件流水线) 技术应运而生,并迅速成为 Function Call 的上位替代方案。
- MCP 技术不仅继承了 Function Call 的“模型驱动外部调用”能力,更在此基础上实现了多组件、可组合、可扩展的智能流水线。通过 MCP,开发者可以将检索、推理、函数调用、外部服务、数据处理等多种能力灵活串联,构建出复杂的智能应用流程。MCP 让大模型的智能决策和自动化能力从“单点”跃升到“系统级”,极大提升了大模型应用的工程化水平和业务适应性。
- MCP并不是某种单一的工具,而是一种思想,将组件变为工具提供给外部调用。在实现的时候可以通过多种方法。无论是哪种工具调用实现方式,都是MCP的思想。
5.1、LangChain Function Calling
5.1.1、LangChain Function Calling的介绍与优势
- 在LangChain框架中,同样提供了内置的一种Function Calling的调用方法,其相比于OpenAI原生的调用实现有着以下的优势:
- 开发效率显著提升:无需编写JSON Schema代码,使用@tool装饰器编写一个带有类型注解的Python函数和响应的文档字符串接口接口,剩下的工作都由LangChain自动完成。
- 类型安全和自动验证:当使用类型注解的时候,LangChain会自动生成相应的验证规则。比如,如果你定义了一个枚举类型的参数,工具定义中会自动包含枚举值的约束;如果你使用了Optional类型,参数会被标记为可选的。
- 函数与工具的完美同步
- 在原生方式中,Python函数和JSON工具定义是分离的两个部分,当修改函数签名的时候,必须记住同步更新JSON定义,否则会导致参数不匹配的错误。
- 使用@tool装饰器的时候,工具定义是从函数自动生成的,任何函数的修改都会全自动反映到工具定义上,这种紧密的耦合确保了一致性,消除了手动同步的负担和错误风险
- 更好的代码可读性和维护性
- @tool装饰器支持Python的各种复杂类型,包括泛型、联合类型、可选类型、枚举等。可以使用List、Dict、Optional、Union等类型注解,LangChain会自动将它们转换为相应的JSON Schema约束。
- 这种丰富的类型支持意味着可以定义非常复杂和精确的工具接口,而不需要手动编写复杂的JSON Schema代码。
5.1.2、LangChain Function Calling的实现方法
1.实现原理
LangChain的@tool装饰器是一个智能的代码生成器,工作原理可以分为以下四个阶段:
- 函数分析:当在函数上添加@tool装饰器时,LangChain会自动分析这个Python函数。它会读取函数的签名信息,包括参数名称、参数类型注解、默认值等。同时,它还会提取函数的docstring文档字符串作为工具的描述信息。
- 自动转换:LangChain将Python类型注解自动转换为OpenAI Function Calling 所需的JSON Schema格式,比如Python的str类型会转换为JSON Schema的"type": “string”,int类型转换为"type": “integer”,List[str]转换为数组类型等。
- 工具对象创建:装饰器会创建一个tool对象,这个对象包含了工具的名称、描述、参数模式等信息,这个tool对象既保留了原始python函数的调用,也具备了OpenAI工具定义的所有必要信息。
- 运行时调用:当AI决定调用某个工具时,LangChain可以直接通过Tool对象的invoke方法调用原始的Python函数,无需额外的映射代码。
以下是一个使用LangChain Function Calling的案例
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.runnables import RunnableLambda# 加载环境变量
load_dotenv()# 定义@tool工具
# 通过langchain.tools包下的@tool装饰器,将函数注册为工具。这里简单注册两个无输入,只有字符串输出的工具
@tool
def who_are_you() -> str:"""当被问到身份时,回答身份信息"""return "我是atguigu工具小助手"@tool
def what_can_you_do() -> str:"""当被问到功能时,回答功能信息"""return "我的功能是进行工具选择"# 根据用户输入信息,构造系统信息与用户信息,后续传入链中作为提示词。
def format_messages(inputs):return [SystemMessage(content="你是一个工具助手。"),HumanMessage(content=inputs["question"])]def execute_tool_calls(result):tools = [who_are_you, what_can_you_do]# 如果执行了工具调用,则进入if result.tool_calls:# LLM会给工具传入列表,越匹配的工具位置越靠前。对于此类调用单一工具的情况,只需要取出列表中的第一项即为被选中的工具tool_call = result.tool_calls[0]print(f"调用工具: {tool_call['name']}")print(f"参数: {tool_call['args']}")# 从工具列表中选择与上述被选定工具进行名称匹配,输出名称和参数信息for tool in tools:if tool.name == tool_call['name']:output = tool.invoke(tool_call['args'])print(f"执行结果: {output}")return outputelse:print(f"未调用工具: {result.content}")return result.contentdef main():api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url)tools = [who_are_you, what_can_you_do]# 通过bind_tools()将工具使用传入工具列表的方式,绑定到ChatOpenAI注册的llm中llm_with_tools = llm.bind_tools(tools)# 将函数转换为节点,接入链中message_formatter = RunnableLambda(format_messages)tool_executor = RunnableLambda(execute_tool_calls)processing_chain = message_formatter | llm_with_tools | tool_executortest_cases = ["你是谁?","你的功能是什么?"]# 通过enumerate获取索引和元素,test_case表示要遍历的列表,1 表示起始索引值# i对应起始索引值 1# question对应test_cases中的相应位置元素for i, question in enumerate(test_cases, 1):print(f"\n测试 {i}: {question}")print("-" * 60)try:result = processing_chain.invoke({"question": question})print(f"链式处理完成")except Exception as e:print(f"处理出错: {e}")if __name__ == "__main__":main()
2.详解
@tool装饰器:在程序启动时,将此函数包装成一个标准的工具对象,这个对象包含了自动生成的JSONSchema。- 在
main函数中,这个工具对象被添加到tools列表中,并通过llm.bind_tools(tools)绑定到LLM。 - 当用户问题被发送给
LLM的时候,LLM会分析这个问题和可用的工具列表 - LLM通过分析工具的描述和参数说明,决定调用这个工具
- LLM根据参数名和上下文自动解析参数表示了什么
- 生成一个工具调用指令
execute_tool_calls函数接收到这个指令,找到工具对象,并调用其invoke方法。invoke方法最终执行工具函数的实际代码,并按照工具的要求进行返回
- 定义两种问答时调用的工具
@tool
def who_are_you() -> str:"""当被问到身份时,回答身份信息"""return "我是atguigu工具小助手"@tool
def what_can_you_do() -> str:"""当被问到功能时,回答功能信息"""return "我的功能是进行工具选择"
- 格式化消息处理器
- 接收一个包含question字段的字典作为参数。
- 返回一个包含系统消息与人类消息的列表,其中人类消息是input中的question字段对应的值。
- 作用为进行角色设定,作为Runnable链的一部分,为后续的LLM处理做准备
def format_messages(inputs):return [SystemMessage(content="你是一个工具助手。"),HumanMessage(content=inputs["question"])]
- 执行工具调用
- 首先接收result (一个AIMessage对象),检查其中是否有result.tool_calls 。
- 如果存在的话则提取工具名,在tools列表中寻找那个被@tool装饰过的Tool对象
- 它调用工具函数,并将AI生成的参数传进去,从而执行了定义的Python函数
- 如果result.tool_calls不存在,则直接返回AI的普通聊天回复。
def execute_tool_calls(result):"""执行工具调用的函数"""tools = [format_time, calculate_statistics, create_user_profile]if result.tool_calls:tool_call = result.tool_calls[0]print(f"调用工具: {tool_call['name']}")print(f"参数: {tool_call['args']}")# 找到对应的工具并执行for tool in tools:if tool.name == tool_call['name']:output = tool.invoke(tool_call['args'])print(f"执行结果: {output}")return outputelse:print(f"未调用工具: {result.content}")return result.content
- 主函数的构建
- 进行初始化
- 定义工具列表
- 构造Runnable链
- 构造完善的处理链,将消息预处理、调用工具的LLM、工具执行全部加入链中
- 输出校验
def main():# 初始化模型api_key = os.getenv('DASHSCOPE_API_KEY')llm_model = os.getenv('QWEN_LLM_MODEL')base_url = os.getenv('BASE_URL')llm = ChatOpenAI(model=llm_model,api_key=api_key,base_url=base_url)# 定义工具列表tools = [who_are_you, what_can_you_do]llm_with_tools = llm.bind_tools(tools)# 构建Runnable链message_formatter = RunnableLambda(format_messages)tool_executor = RunnableLambda(execute_tool_calls)# 完整的处理链:消息格式化 -> LLM处理 -> 工具执行processing_chain = message_formatter | llm_with_tools | tool_executor# 测试用例test_cases = ["你是谁?","你的功能是什么?"]for i, question in enumerate(test_cases, 1):print(f"\n测试 {i}: {question}")print("-" * 60)# 通过Runnable链处理整个流程try:result = processing_chain.invoke({"question": question})print(f"链式处理完成")except Exception as e:print(f"处理出错: {e}")
测试 1: 你是谁?
------------------------------------------------------------
调用工具: who_are_you
参数: {}
执行结果: 我是atguigu工具小助手
链式处理完成测试 2: 你的功能是什么?
------------------------------------------------------------
调用工具: what_can_you_do
参数: {}
执行结果: 我的功能是进行工具选择
链式处理完成