Python - 100天从新手到大师:第五十八天 Python中的并发编程(1-3)
Python中的并发编程-1
现如今,我们使用的计算机早已是多 CPU 或多核的计算机,而我们使用的操作系统基本都支持“多任务”,这使得我们可以同时运行多个程序,也可以将一个程序分解为若干个相对独立的子任务,让多个子任务“并行”或“并发”的执行,从而缩短程序的执行时间,同时也让用户获得更好的体验。因此当下,不管用什么编程语言进行开发,实现“并行”或“并发”编程已经成为了程序员的标配技能。为了讲述如何在 Python 程序中实现“并行”或“并发”,我们需要先了解两个重要的概念:进程和线程。
线程和进程
我们通过操作系统运行一个程序会创建出一个或多个进程,进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。简单的说,进程是操作系统分配存储空间的基本单位,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据;操作系统管理所有进程的执行,为它们合理的分配资源。一个进程可以通过 fork 或 spawn 的方式创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此两个进程如果要共享数据,必须通过进程间通信机制来实现,具体的方式包括管道、信号、套接字等。
一个进程还可以拥有多个执行线索,简单的说就是拥有多个可以获得 CPU 调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核 CPU 系统中,多个线程不可能同时执行,因为在某个时刻只有一个线程能够获得 CPU,多个线程通过共享 CPU 执行时间的方式来达到并发的效果。
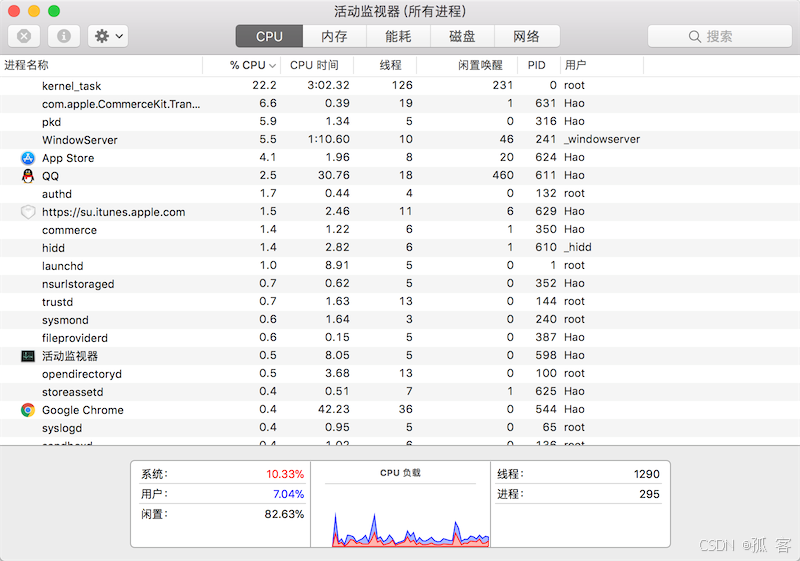
在程序中使用多线程技术通常都会带来不言而喻的好处,最主要的体现在提升程序的性能和改善用户体验,今天我们使用的软件几乎都用到了多线程技术,这一点可以利用系统自带的进程监控工具(如 macOS 中的“活动监视器”、Windows 中的“任务管理器”)来证实,如下图所示。
这里,我们还需要跟大家再次强调两个概念:并发(concurrency)和并行(parallel)。并发通常是指同一时刻只能有一条指令执行,但是多个线程对应的指令被快速轮换地执行。比如一个处理器,它先执行线程 A 的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A 执行一段时间。由于处理器执行指令的速度和切换的速度极快,人们完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行,但微观上其实只有一个线程在执行。并行是指同一时刻,有多条指令在多个处理器上同时执行,并行必须要依赖于多个处理器,不论是从宏观上还是微观上,多个线程可以在同一时刻一起执行的。很多时候,我们并不用严格区分并发和并行两个词,所以我们有时候也把 Python 中的多线程、多进程以及异步 I/O 都视为实现并发编程的手段,但实际上前面两者也可以实现并行编程,当然这里还有一个全局解释器锁(GIL)的问题,我们稍后讨论。
多线程编程
Python 标准库中threading模块的Thread类可以帮助我们非常轻松的实现多线程编程。我们用一个联网下载文件的例子来对比使用多线程和不使用多线程到底有什么区别,代码如下所示。
不使用多线程的下载。
import random
import timedef download(*, filename):start = time.time()print(f'开始下载 {filename}.')time.sleep(random.randint(3, 6))print(f'{filename} 下载完成.')end = time.time()print(f'下载耗时: {end - start:.3f}秒.')def main():start = time.time()download(filename='Python从入门到住院.pdf')download(filename='MySQL从删库到跑路.avi')download(filename='Linux从精通到放弃.mp4')end = time.time()print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__':main()
说明:上面的代码并没有真正实现联网下载的功能,而是通过
time.sleep()休眠一段时间来模拟下载文件需要一些时间上的开销,跟实际下载的状况比较类似。
运行上面的代码,可以得到如下所示的运行结果。可以看出,当我们的程序只有一个工作线程时,每个下载任务都需要等待上一个下载任务执行结束才能开始,所以程序执行的总耗时是三个下载任务各自执行时间的总和。
开始下载Python从入门到住院.pdf.
Python从入门到住院.pdf下载完成.
下载耗时: 3.005秒.
开始下载MySQL从删库到跑路.avi.
MySQL从删库到跑路.avi下载完成.
下载耗时: 5.006秒.
开始下载Linux从精通到放弃.mp4.
Linux从精通到放弃.mp3下载完成.
下载耗时: 6.007秒.
总耗时: 14.018秒.
事实上,上面的三个下载任务之间并没有逻辑上的因果关系,三者是可以“并发”的,下一个下载任务没有必要等待上一个下载任务结束,为此,我们可以使用多线程编程来改写上面的代码。
import random
import time
from threading import Threaddef download(*, filename):start = time.time()print(f'开始下载 {filename}.')time.sleep(random.randint(3, 6))print(f'{filename} 下载完成.')end = time.time()print(f'下载耗时: {end - start:.3f}秒.')def main():threads = [Thread(target=download, kwargs={'filename': 'Python从入门到住院.pdf'}),Thread(target=download, kwargs={'filename': 'MySQL从删库到跑路.avi'}),Thread(target=download, kwargs={'filename': 'Linux从精通到放弃.mp4'})]start = time.time()# 启动三个线程for thread in threads:thread.start()# 等待线程结束for thread in threads:thread.join()end = time.time()print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__':main()
某次的运行结果如下所示。
开始下载 Python从入门到住院.pdf.
开始下载 MySQL从删库到跑路.avi.
开始下载 Linux从精通到放弃.mp4.
MySQL从删库到跑路.avi 下载完成.
下载耗时: 3.005秒.
Python从入门到住院.pdf 下载完成.
下载耗时: 5.006秒.
Linux从精通到放弃.mp4 下载完成.
下载耗时: 6.003秒.
总耗时: 6.004秒.
通过上面的运行结果可以发现,整个程序的执行时间几乎等于耗时最长的一个下载任务的执行时间,这也就意味着,三个下载任务是并发执行的,不存在一个等待另一个的情况,这样做很显然提高了程序的执行效率。简单的说,如果程序中有非常耗时的执行单元,而这些耗时的执行单元之间又没有逻辑上的因果关系,即 B 单元的执行不依赖于 A 单元的执行结果,那么 A 和 B 两个单元就可以放到两个不同的线程中,让他们并发的执行。这样做的好处除了减少程序执行的等待时间,还可以带来更好的用户体验,因为一个单元的阻塞不会造成程序的“假死”,因为程序中还有其他的单元是可以运转的。
使用 Thread 类创建线程对象
通过上面的代码可以看出,直接使用Thread类的构造器就可以创建线程对象,而线程对象的start()方法可以启动一个线程。线程启动后会执行target参数指定的函数,当然前提是获得 CPU 的调度;如果target指定的线程要执行的目标函数有参数,需要通过args参数为其进行指定,对于关键字参数,可以通过kwargs参数进行传入。Thread类的构造器还有很多其他的参数,我们遇到的时候再为大家进行讲解,目前需要大家掌握的,就是target、args和kwargs。
继承 Thread 类自定义线程
除了上面的代码展示的创建线程的方式外,还可以通过继承Thread类并重写run()方法的方式来自定义线程,具体的代码如下所示。
import random
import time
from threading import Threadclass DownloadThread(Thread):def __init__(self, filename):self.filename = filenamesuper().__init__()def run(self):start = time.time()print(f'开始下载 {self.filename}.')time.sleep(random.randint(3, 6))print(f'{self.filename} 下载完成.')end = time.time()print(f'下载耗时: {end - start:.3f}秒.')def main():threads = [DownloadThread('Python从入门到住院.pdf'),DownloadThread('MySQL从删库到跑路.avi'),DownloadThread('Linux从精通到放弃.mp4')]start = time.time()# 启动三个线程for thread in threads:thread.start()# 等待线程结束for thread in threads:thread.join()end = time.time()print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__':main()
使用线程池
我们还可以通过线程池的方式将任务放到多个线程中去执行,通过线程池来使用线程应该是多线程编程最理想的选择。事实上,线程的创建和释放都会带来较大的开销,频繁的创建和释放线程通常都不是很好的选择。利用线程池,可以提前准备好若干个线程,在使用的过程中不需要再通过自定义的代码创建和释放线程,而是直接复用线程池中的线程。Python 内置的concurrent.futures模块提供了对线程池的支持,代码如下所示。
import random
import time
from concurrent.futures import ThreadPoolExecutor
from threading import Threaddef download(*, filename):start = time.time()print(f'开始下载 {filename}.')time.sleep(random.randint(3, 6))print(f'{filename} 下载完成.')end = time.time()print(f'下载耗时: {end - start:.3f}秒.')def main():with ThreadPoolExecutor(max_workers=4) as pool:filenames = ['Python从入门到住院.pdf', 'MySQL从删库到跑路.avi', 'Linux从精通到放弃.mp4']start = time.time()for filename in filenames:pool.submit(download, filename=filename)end = time.time()print(f'总耗时: {end - start:.3f}秒.')if __name__ == '__main__':main()
守护线程
所谓“守护线程”就是在主线程结束的时候,不值得再保留的执行线程。这里的不值得保留指的是守护线程会在其他非守护线程全部运行结束之后被销毁,它守护的是当前进程内所有的非守护线程。简单的说,守护线程会跟随主线程一起挂掉,而主线程的生命周期就是一个进程的生命周期。如果不理解,我们可以看一段简单的代码。
import time
from threading import Threaddef display(content):while True:print(content, end='', flush=True)time.sleep(0.1)def main():Thread(target=display, args=('Ping', )).start()Thread(target=display, args=('Pong', )).start()if __name__ == '__main__':main()
说明:上面的代码中,我们将
flush设置为True,这是因为flush参数的值如果为False,而flush参数设置为True,强制每次输出都清空输出缓冲区。
上面的代码运行起来之后是不会停止的,因为两个子线程中都有死循环,除非你手动中断代码的执行。但是,如果在创建线程对象时,将名为daemon的参数设置为True,这两个线程就会变成守护线程,那么在其他线程结束时,即便有死循环,两个守护线程也会挂掉,不会再继续执行下去,代码如下所示。
import time
from threading import Threaddef display(content):while True:print(content, end='', flush=True)time.sleep(0.1)def main():Thread(target=display, args=('Ping', ), daemon=True).start()Thread(target=display, args=('Pong', ), daemon=True).start()time.sleep(5)if __name__ == '__main__':main()
上面的代码,我们在主线程中添加了一行time.sleep(5)让主线程休眠5秒,在这个过程中,输出Ping和Pong的守护线程会持续运转,直到主线程在5秒后结束,这两个守护线程也被销毁,不再继续运行。
思考:如果将上面代码第12行的
daemon=True去掉,代码会怎样执行?有兴趣的读者可以尝试一下,并看看实际执行的结果跟你想象的是否一致。
资源竞争
在编写多线程代码时,不可避免的会遇到多个线程竞争同一个资源(对象)的情况。在这种情况下,如果没有合理的机制来保护被竞争的资源,那么就有可能出现非预期的状况。下面的代码创建了100个线程向同一个银行账户(初始余额为0元)转账,每个线程转账金额为1元。在正常的情况下,我们的银行账户最终的余额应该是100元,但是运行下面的代码我们并不能得到100元这个结果。
import timefrom concurrent.futures import ThreadPoolExecutorclass Account(object):"""银行账户"""def __init__(self):self.balance = 0.0def deposit(self, money):"""存钱"""new_balance = self.balance + moneytime.sleep(0.01)self.balance = new_balancedef main():"""主函数"""account = Account()with ThreadPoolExecutor(max_workers=16) as pool:for _ in range(100):pool.submit(account.deposit, 1)print(account.balance)if __name__ == '__main__':main()
上面代码中的Account类代表了银行账户,它的deposit方法代表存款行为,参数money代表存入的金额,该方法通过time.sleep函数模拟受理存款需要一段时间。我们通过线程池的方式启动了100个线程向一个账户转账,但是上面的代码并不能运行出100这个我们期望的结果,这就是在多个线程竞争一个资源的时候,可能会遇到的数据不一致的问题。注意上面代码的第14行,当多个线程都执行到这行代码时,它们会在相同的余额上执行加上存入金额的操作,这就会造成“丢失更新”现象,即之前修改数据的成果被后续的修改给覆盖掉了,所以才得不到正确的结果。
要解决上面的问题,可以使用锁机制,通过锁对操作数据的关键代码加以保护。Python 标准库的threading模块提供了Lock和RLock类来支持锁机制,这里我们不去深究二者的区别,建议大家直接使用RLock。接下来,我们给银行账户添加一个锁对象,通过锁对象来解决刚才存款时发生“丢失更新”的问题,代码如下所示。
import timefrom concurrent.futures import ThreadPoolExecutor
from threading import RLockclass Account(object):"""银行账户"""def __init__(self):self.balance = 0.0self.lock = RLock()def deposit(self, money):# 获得锁self.lock.acquire()try:new_balance = self.balance + moneytime.sleep(0.01)self.balance = new_balancefinally:# 释放锁self.lock.release()def main():"""主函数"""account = Account()with ThreadPoolExecutor(max_workers=16) as pool:for _ in range(100):pool.submit(account.deposit, 1)print(account.balance)if __name__ == '__main__':main()
上面代码中,获得锁和释放锁的操作也可以通过上下文语法来实现,使用上下文语法会让代码更加简单优雅,这也是我们推荐大家使用的方式。
import timefrom concurrent.futures import ThreadPoolExecutor
from threading import RLockclass Account(object):"""银行账户"""def __init__(self):self.balance = 0.0self.lock = RLock()def deposit(self, money):# 通过上下文语法获得锁和释放锁with self.lock:new_balance = self.balance + moneytime.sleep(0.01)self.balance = new_balancedef main():"""主函数"""account = Account()with ThreadPoolExecutor(max_workers=16) as pool:for _ in range(100):pool.submit(account.deposit, 1)print(account.balance)if __name__ == '__main__':main()
思考:将上面的代码修改为5个线程向银行账户存钱,5个线程从银行账户取钱,取钱的线程在银行账户余额不足时,需要停下来等待存钱的线程将钱存入后再尝试取钱。这里需要用到线程调度的知识,大家可以自行研究下
threading模块中的Condition类,看看是否能够完成这个任务。
GIL问题
如果使用官方的 Python 解释器(通常称之为 CPython)运行 Python 程序,我们并不能通过使用多线程的方式将 CPU 的利用率提升到逼近400%(对于4核 CPU)或逼近800%(对于8核 CPU)这样的水平,因为 CPython 在执行代码时,会受到 GIL(全局解释器锁)的限制。具体的说,CPython 在执行任何代码时,都需要对应的线程先获得 GIL,然后每执行100条(字节码)指令,CPython 就会让获得 GIL 的线程主动释放 GIL,这样别的线程才有机会执行。因为 GIL 的存在,无论你的 CPU 有多少个核,我们编写的 Python 代码也没有机会真正并行的执行。
GIL 是官方 Python 解释器在设计上的历史遗留问题,要解决这个问题,让多线程能够发挥 CPU 的多核优势,需要重新实现一个不带 GIL 的 Python 解释器。这个问题按照官方的说法,在 Python 发布4.0版本时会得到解决,就让我们拭目以待吧。当下,对于 CPython 而言,如果希望充分发挥 CPU 的多核优势,可以考虑使用多进程,因为每个进程都对应一个 Python 解释器,因此每个进程都有自己独立的 GIL,这样就可以突破 GIL 的限制。在下一个章节中,我们会为大家介绍关于多进程的相关知识,并对多线程和多进程的代码及其执行效果进行比较。
Python中的并发编程-2
在上一课中我们说过,由于 GIL 的存在,CPython 中的多线程并不能发挥 CPU 的多核优势,如果希望突破 GIL 的限制,可以考虑使用多进程。对于多进程的程序,每个进程都有一个属于自己的 GIL,所以多进程不会受到 GIL 的影响。那么,我们应该如何在 Python 程序中创建和使用多进程呢?
###创建进程
在 Python 中可以基于Process类来创建进程,虽然进程和线程有着本质的差别,但是Process类和Thread类的用法却非常类似。在使用Process类的构造器创建对象时,也是通过target参数传入一个函数来指定进程要执行的代码,而args和kwargs参数可以指定该函数使用的参数值。
from multiprocessing import Process, current_process
from time import sleepdef sub_task(content, nums):# 通过current_process函数获取当前进程对象# 通过进程对象的pid和name属性获取进程的ID号和名字print(f'PID: {current_process().pid}')print(f'Name: {current_process().name}')# 通过下面的输出不难发现,每个进程都有自己的nums列表,进程之间本就不共享内存# 在创建子进程时复制了父进程的数据结构,三个进程从列表中pop(0)得到的值都是20counter, total = 0, nums.pop(0)print(f'Loop count: {total}')sleep(0.5)while counter < total:counter += 1print(f'{counter}: {content}')sleep(0.01)def main():nums = [20, 30, 40]# 创建并启动进程来执行指定的函数Process(target=sub_task, args=('Ping', nums)).start()Process(target=sub_task, args=('Pong', nums)).start()# 在主进程中执行sub_task函数sub_task('Good', nums)if __name__ == '__main__':main()
说明:上面的代码通过
current_process函数获取当前进程对象,再通过进程对象的pid属性获取进程ID。在 Python 中,使用os模块的getpid函数也可以达到同样的效果。
如果愿意,也可以使用os模块的fork函数来创建进程,调用该函数时,操作系统自动把当前进程(父进程)复制一份(子进程),父进程的fork函数会返回子进程的ID,而子进程中的fork函数会返回0,也就是说这个函数调用一次会在父进程和子进程中得到两个不同的返回值。需要注意的是,Windows 系统并不支持fork函数,如果你使用的是 Linux 或 macOS 系统,可以试试下面的代码。
import osprint(f'PID: {os.getpid()}')
pid = os.fork()
if pid == 0:print(f'子进程 - PID: {os.getpid()}')print('Todo: 在子进程中执行的代码')
else:print(f'父进程 - PID: {os.getpid()}')print('Todo: 在父进程中执行的代码')
简而言之,我们还是推荐大家通过直接使用Process类、继承Process类和使用进程池(ProcessPoolExecutor)这三种方式来创建和使用多进程,这三种方式不同于上面的fork函数,能够保证代码的兼容性和可移植性。具体的做法跟之前讲过的创建和使用多线程的方式比较接近,此处不再进行赘述。
多进程和多线程的比较
对于爬虫这类 I/O 密集型任务来说,使用多进程并没有什么优势;但是对于计算密集型任务来说,多进程相比多线程,在效率上会有显著的提升,我们可以通过下面的代码来加以证明。下面的代码会通过多线程和多进程两种方式来判断一组大整数是不是质数,很显然这是一个计算密集型任务,我们将任务分别放到多个线程和多个进程中来加速代码的执行,让我们看看多线程和多进程的代码具体表现有何不同。
我们先实现一个多线程的版本,代码如下所示。
import concurrent.futuresPRIMES = [1116281,1297337,104395303,472882027,533000389,817504243,982451653,112272535095293,112582705942171,112272535095293,115280095190773,115797848077099,1099726899285419
] * 5def is_prime(n):"""判断素数"""for i in range(2, int(n ** 0.5) + 1):if n % i == 0:return Falsereturn n != 1def main():"""主函数"""with concurrent.futures.ThreadPoolExecutor(max_workers=16) as executor:for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):print('%d is prime: %s' % (number, prime))if __name__ == '__main__':main()
假设上面的代码保存在名为example.py的文件中,在 Linux 或 macOS 系统上,可以使用time python example.py命令执行程序并获得操作系统关于执行时间的统计,在我的 macOS 上,某次的运行结果的最后一行输出如下所示。
python example09.py 38.69s user 1.01s system 101% cpu 39.213 total
从运行结果可以看出,多线程的代码只能让 CPU 利用率达到100%,这其实已经证明了多线程的代码无法利用 CPU 多核特性来加速代码的执行,我们再看看多进程的版本,我们将上面代码中的线程池(ThreadPoolExecutor)更换为进程池(ProcessPoolExecutor)。
多进程的版本。
import concurrent.futuresPRIMES = [1116281,1297337,104395303,472882027,533000389,817504243,982451653,112272535095293,112582705942171,112272535095293,115280095190773,115797848077099,1099726899285419
] * 5def is_prime(n):"""判断素数"""for i in range(2, int(n ** 0.5) + 1):if n % i == 0:return Falsereturn n != 1def main():"""主函数"""with concurrent.futures.ProcessPoolExecutor(max_workers=16) as executor:for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):print('%d is prime: %s' % (number, prime))if __name__ == '__main__':main()
提示:运行上面的代码时,可以通过操作系统的任务管理器(资源监视器)来查看是否启动了多个 Python 解释器进程。
我们仍然通过time python example.py的方式来执行上述代码,运行结果的最后一行如下所示。
python example09.py 106.63s user 0.57s system 389% cpu 27.497 total
可以看出,多进程的版本在我使用的这台电脑上,让 CPU 的利用率达到了将近400%,而运行代码时用户态耗费的 CPU 的时间(106.63秒)几乎是代码运行总时间(27.497秒)的4倍,从这两点都可以看出,我的电脑使用了一款4核的 CPU。当然,要知道自己的电脑有几个 CPU 或几个核,可以直接使用下面的代码。
import osprint(os.cpu_count())
综上所述,多进程可以突破 GIL 的限制,充分利用 CPU 多核特性,对于计算密集型任务,这一点是相当重要的。常见的计算密集型任务包括科学计算、图像处理、音视频编解码等,如果这些计算密集型任务本身是可以并行的,那么使用多进程应该是更好的选择。
进程间通信
在讲解进程间通信之前,先给大家一个任务:启动两个进程,一个输出“Ping”,一个输出“Pong”,两个进程输出的“Ping”和“Pong”加起来一共有50个时,就结束程序。听起来是不是非常简单,但是实际编写代码时,由于多个进程之间不能够像多个线程之间直接通过共享内存的方式交换数据,所以下面的代码是达不到我们想要的结果的。
from multiprocessing import Process
from time import sleepcounter = 0def sub_task(string):global counterwhile counter < 50:print(string, end='', flush=True)counter += 1sleep(0.01)def main():Process(target=sub_task, args=('Ping', )).start()Process(target=sub_task, args=('Pong', )).start()if __name__ == '__main__':main()
上面的代码看起来没毛病,但是最后的结果是“Ping”和“Pong”各输出了50个。再次提醒大家,当我们在程序中创建进程的时候,子进程会复制父进程及其所有的数据结构,每个子进程有自己独立的内存空间,这也就意味着两个子进程中各有一个counter变量,它们都会从0加到50,所以结果就可想而知了。要解决这个问题比较简单的办法是使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,底层是通过操作系统底层的管道和信号量(semaphore)机制来实现的,代码如下所示。
import time
from multiprocessing import Process, Queuedef sub_task(content, queue):counter = queue.get()while counter < 50:print(content, end='', flush=True)counter += 1queue.put(counter)time.sleep(0.01)counter = queue.get()def main():queue = Queue()queue.put(0)p1 = Process(target=sub_task, args=('Ping', queue))p1.start()p2 = Process(target=sub_task, args=('Pong', queue))p2.start()while p1.is_alive() and p2.is_alive():passqueue.put(50)if __name__ == '__main__':main()
提示:
multiprocessing.Queue对象的get方法默认在队列为空时是会阻塞的,直到获取到数据才会返回。如果不希望该方法阻塞以及需要指定阻塞的超时时间,可以通过指定block和timeout参数进行设定。
上面的代码通过Queue类的get和put方法让三个进程(p1、p2和主进程)实现了数据的共享,这就是所谓的进程间的通信,通过这种方式,当Queue中取出的值已经大于等于50时,p1和p2就会跳出while循环,从而终止进程的执行。代码第22行的循环是为了等待p1和p2两个进程中的一个结束,这时候主进程还需要向Queue中放置一个大于等于50的值,这样另一个尚未结束的进程也会因为读到这个大于等于50的值而终止。
进程间通信的方式还有很多,比如使用套接字也可以实现两个进程的通信,甚至于这两个进程并不在同一台主机上,有兴趣的读者可以自行了解。
总结
在 Python 中,我们还可以通过subprocess模块的call函数执行其他的命令来创建子进程,相当于就是在我们的程序中调用其他程序,这里我们暂不探讨这些知识,有兴趣的读者可以自行研究。
对于Python开发者来说,以下情况需要考虑使用多线程:
- 程序需要维护许多共享的状态(尤其是可变状态),Python 中的列表、字典、集合都是线程安全的(多个线程同时操作同一个列表、字典或集合,不会引发错误和数据问题),所以使用线程而不是进程维护共享状态的代价相对较小。
- 程序会花费大量时间在 I/O 操作上,没有太多并行计算的需求且不需占用太多的内存。
那么在遇到下列情况时,应该考虑使用多进程:
- 程序执行计算密集型任务(如:音视频编解码、数据压缩、科学计算等)。
- 程序的输入可以并行的分成块,并且可以将运算结果合并。
- 程序在内存使用方面没有任何限制且不强依赖于 I/O 操作(如读写文件、套接字等)。
Python中的并发编程-3
爬虫是典型的 I/O 密集型任务,I/O 密集型任务的特点就是程序会经常性的因为 I/O 操作而进入阻塞状态,比如我们之前使用requests获取页面代码或二进制内容,发出一个请求之后,程序必须要等待网站返回响应之后才能继续运行,如果目标网站不是很给力或者网络状况不是很理想,那么等待响应的时间可能会很久,而在这个过程中整个程序是一直阻塞在那里,没有做任何的事情。通过前面的课程,我们已经知道了可以通过多线程的方式为爬虫提速,使用多线程的本质就是,当一个线程阻塞的时候,程序还有其他的线程可以继续运转,因此整个程序就不会在阻塞和等待中浪费了大量的时间。
事实上,还有一种非常适合 I/O 密集型任务的并发编程方式,我们称之为异步编程,你也可以将它称为异步 I/O。这种方式并不需要启动多个线程或多个进程来实现并发,它是通过多个子程序相互协作的方式来提升 CPU 的利用率,解决了 I/O 密集型任务 CPU 利用率很低的问题,我一般将这种方式称为“协作式并发”。这里,我不打算探讨操作系统的各种 I/O 模式,因为这对很多读者来说都太过抽象;但是我们得先抛出两组概念给大家,一组叫做“阻塞”和“非阻塞”,一组叫做“同步”和“异步”。
基本概念
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。阻塞随时都可能发生,最典型的就是 I/O 中断(包括网络 I/O 、磁盘 I/O 、用户输入等)、休眠操作、等待某个线程执行结束,甚至包括在 CPU 切换上下文时,程序都无法真正的执行,这就是所谓的阻塞。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。非阻塞并不是在任何程序级别、任何情况下都可以存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。显然,某个操作的阻塞可能会导程序耗时以及效率低下,所以我们会希望把它变成非阻塞的。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。例如前面讲过的给银行账户存钱的操作,我们在代码中使用了“锁”作为通信信号,让多个存钱操作强制排队顺序执行,这就是所谓的同步。
异步
不同程序单元在执行过程中无需通信协调,也能够完成一个任务,这种方式我们就称之为异步。例如,使用爬虫下载页面时,调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是不相关的,也无需相互通知协调。很显然,异步操作的完成时刻和先后顺序并不能确定。
很多人都不太能准确的把握这几个概念,这里我们简单的总结一下,同步与异步的关注点是消息通信机制,最终表现出来的是“有序”和“无序”的区别;阻塞和非阻塞的关注点是程序在等待消息时状态,最终表现出来的是程序在等待时能不能做点别的。如果想深入理解这些内容,推荐大家阅读经典著作《UNIX网络编程》,这本书非常的赞。
生成器和协程
前面我们说过,异步编程是一种“协作式并发”,即通过多个子程序相互协作的方式提升 CPU 的利用率,从而减少程序在阻塞和等待中浪费的时间,最终达到并发的效果。我们可以将多个相互协作的子程序称为“协程”,它是实现异步编程的关键。在介绍协程之前,我们先通过下面的代码,看看什么是生成器。
def fib(max_count):a, b = 0, 1for _ in range(max_count):a, b = b, a + byield a
上面我们编写了一个生成斐波那契数列的生成器,调用上面的fib函数并不是执行该函数获得返回值,因为fib函数中有一个特殊的关键字yield。这个关键字使得fib函数跟普通的函数有些区别,调用该函数会得到一个生成器对象,我们可以通过下面的代码来验证这一点。
gen_obj = fib(20)
print(gen_obj)
输出:
<generator object fib at 0x106daee40>
我们可以使用内置函数next从生成器对象中获取斐波那契数列的值,也可以通过for-in循环对生成器能够提供的值进行遍历,代码如下所示。
for value in gen_obj:print(value)
生成器经过预激活,就是一个协程,它可以跟其他子程序协作。
def calc_average():total, counter = 0, 0avg_value = Nonewhile True:curr_value = yield avg_valuetotal += curr_valuecounter += 1avg_value = total / counterdef main():obj = calc_average()# 生成器预激活obj.send(None)for _ in range(5):print(obj.send(float(input())))if __name__ == '__main__':main()
上面的main函数首先通过生成器对象的send方法发送一个None值来将其激活为协程,也可以通过next(obj)达到同样的效果。接下来,协程对象会接收main函数发送的数据并产出(yield)数据的平均值。通过上面的例子,不知道大家是否看出两段子程序是怎么“协作”的。
异步函数
Python 3.5版本中,引入了两个非常有意思的元素,一个叫async,一个叫await,它们在Python 3.7版本中成为了正式的关键字。通过这两个关键字,可以简化协程代码的编写,可以用更为简单的方式让多个子程序很好的协作起来。我们通过一个例子来加以说明,请大家先看看下面的代码。
import timedef display(num):time.sleep(1)print(num)def main():start = time.time()for i in range(1, 10):display(i)end = time.time()print(f'{end - start:.3f}秒')if __name__ == '__main__':main()
上面的代码每次执行都会依次输出1到9的数字,每个间隔1秒钟,整个代码需要执行大概需要9秒多的时间,这一点我相信大家都能看懂。不知道大家是否意识到,这段代码就是以同步和阻塞的方式执行的,同步可以从代码的输出看出来,而阻塞是指在调用display函数发生休眠时,整个代码的其他部分都不能继续执行,必须等待休眠结束。
接下来,我们尝试用异步的方式改写上面的代码,让display函数以异步的方式运转。
import asyncio
import timeasync def display(num):await asyncio.sleep(1)print(num)def main():start = time.time()objs = [display(i) for i in range(1, 10)]loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait(objs))loop.close()end = time.time()print(f'{end - start:.3f}秒')if __name__ == '__main__':main()
Python 中的asyncio模块提供了对异步 I/O 的支持。上面的代码中,我们首先在display函数前面加上了async关键字使其变成一个异步函数,调用异步函数不会执行函数体而是获得一个协程对象。我们将display函数中的time.sleep(1)修改为await asyncio.sleep(1),二者的区别在于,后者不会让整个代码陷入阻塞,因为await操作会让其他协作的子程序有获得 CPU 资源而得以运转的机会。为了让这些子程序可以协作起来,我们需要将他们放到一个事件循环(实现消息分派传递的系统)上,因为当协程遭遇 I/O 操作阻塞时,就会到事件循环中监听 I/O 操作是否完成,并注册自身的上下文以及自身的唤醒函数(以便恢复执行),之后该协程就变为阻塞状态。上面的第12行代码创建了9个协程对象并放到一个列表中,第13行代码通过asyncio模块的get_event_loop函数获得了系统的事件循环,第14行通过asyncio模块的run_until_complete函数将协程对象挂载到事件循环上。执行上面的代码会发现,9个分别会阻塞1秒钟的协程总共只阻塞了约1秒种的时间,因为阻塞的协程对象会放弃对 CPU 的占有而不是让 CPU 处于闲置状态,这种方式大大的提升了 CPU 的利用率。而且我们还会注意到,数字并不是按照从1到9的顺序打印输出的,这正是我们想要的结果,说明它们是异步执行的。对于爬虫这样的 I/O 密集型任务来说,这种协作式并发在很多场景下是比使用多线程更好的选择,因为这种做法减少了管理和维护多个线程以及多个线程切换所带来的开销。
aiohttp库
我们之前使用的requests三方库并不支持异步 I/O,如果希望使用异步 I/O 的方式来加速爬虫代码的执行,我们可以安装和使用名为aiohttp的三方库。
安装aiohttp。
pip install aiohttp
下面的代码使用aiohttp抓取了10个网站的首页并解析出它们的标题。
import asyncio
import reimport aiohttp
from aiohttp import ClientSessionTITLE_PATTERN = re.compile(r'<title.*?>(.*?)</title>', re.DOTALL)async def fetch_page_title(url):async with aiohttp.ClientSession(headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',}) as session: # type: ClientSessionasync with session.get(url, ssl=False) as resp:if resp.status == 200:html_code = await resp.text()matcher = TITLE_PATTERN.search(html_code)title = matcher.group(1).strip()print(title)def main():urls = ['https://www.python.org/','https://www.jd.com/','https://www.baidu.com/','https://www.taobao.com/','https://git-scm.com/','https://www.sohu.com/','https://gitee.com/','https://www.amazon.com/','https://www.usa.gov/','https://www.nasa.gov/']objs = [fetch_page_title(url) for url in urls]loop = asyncio.get_event_loop()loop.run_until_complete(asyncio.wait(objs))loop.close()if __name__ == '__main__':main()
输出:
京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!
搜狐
淘宝网 - 淘!我喜欢
百度一下,你就知道
Gitee - 基于 Git 的代码托管和研发协作平台
Git
NASA
Official Guide to Government Information and Services | USAGov
Amazon.com. Spend less. Smile more.
Welcome to Python.org
从上面的输出可以看出,网站首页标题的输出顺序跟它们的 URL 在列表中的顺序没有关系。代码的第11行到第13行创建了ClientSession对象,通过它的get方法可以向指定的 URL 发起请求,如第14行所示,跟requests中的Session对象并没有本质区别,唯一的区别是这里使用了异步上下文。代码第16行的await会让因为 I/O 操作阻塞的子程序放弃对 CPU 的占用,这使得其他的子程序可以运转起来去抓取页面。代码的第17行和第18行使用了正则表达式捕获组操作解析网页标题。fetch_page_title是一个被async关键字修饰的异步函数,调用该函数会获得协程对象,如代码第35行所示。后面的代码跟之前的例子没有什么区别,相信大家能够理解。
大家可以尝试将aiohttp换回到requests,看看不使用异步 I/O 也不使用多线程,到底和上面的代码有什么区别,相信通过这样的对比,大家能够更深刻的理解我们之前强调的几个概念:同步和异步,阻塞和非阻塞。