LangChain最详细教程之Model I/O(一)
目录
简介
一、Model I/O介绍
二、Model I/O之调用模型1
1 、模型的不同分类方式
2、 角度1出发:按照功能不同举例
3 、角度2出发:参数位置不同举例
4 角度3出发:各平台API的调用举例
三、Model I/O之调用模型2
1 、关于对话模型的Message(消息)
2 、关于多轮对话与上下文记忆
3 、关于模型调用的方法
简介
本系列教程将以「系统梳理 + 实战落地」为核心,从基础到进阶全面拆解 LangChain—— 这个目前最流行的大语言模型(LLM)应用开发框架。之前对langchain进行了系统的概述,现在我们就来详细看看每一个板块
LangChain最详细教程之使用概述(一)
LangChain最详细教程之使用概述(二)
LangChain最详细教程之使用概述(三)
一、Model I/O介绍
Model I/O 模块是与语言模型(LLMs)进行交互的 核心组件 ,在整个框架中有着很重要的地位。
所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着 Prompt Template , Model 和 Output Parser 。 简单来说,就是输⼊、模型处理、输出这三个步骤。
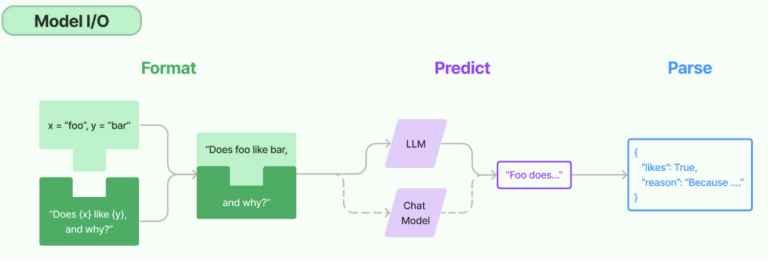
针对每个环节,LangChain都提供了模板和工具,可以快捷的调用各种语言模型的接口
二、Model I/O之调用模型1
LangChain作为一个“工具”,不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将 OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的应用。
1 、模型的不同分类方式
简单来说,就是⽤谁家的API以什么⽅式调⽤哪种类型的⼤模型
角度1:按照模型功能的不同:
- 非对话模型(LLMs、Text Model)
- 对话模型(Chat Models)( 推荐 )
- 嵌入模型(Embedding Models)( 暂不考虑 )
角度2:模型调用时,几个重要参数的书写位置的不同:
- 硬编码:写在代码文件中使用环境变量
- 使用配置文件( 推荐 )
角度3:具体调用的API
- OpenAI提供的API
- 其它大模型自家提供的API
- LangChain的统一方式调用API( 推荐 )
2、 角度1出发:按照功能不同举例
类型1:LLMs(非对话模型)
LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
- 输入:接受 文本字符串 或 PromptValue 对象
- 输出:总是返回 文本字符串
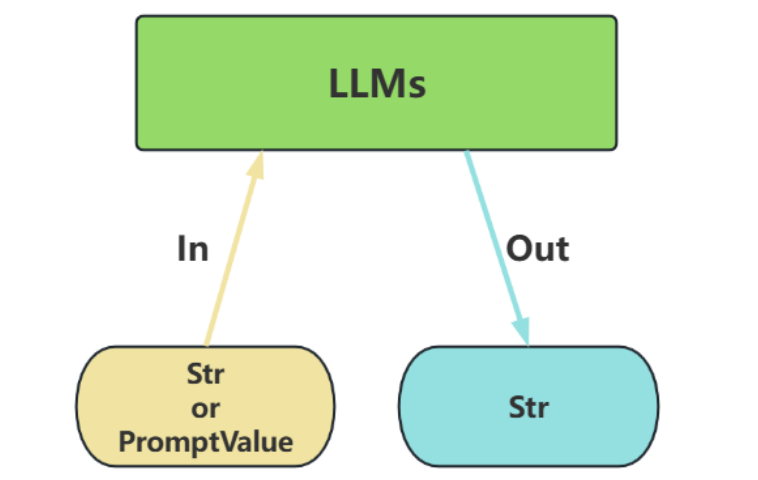
- 适用场景:仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)( 言外之意,优先推荐ChatModel )
- 不支持多轮对话上下文。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文 本)。
- 局限性:无法处理角色分工或复杂对话逻辑。
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")###########核心代码############
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗") # 直接输入字符串
print(str)
print(type(str))类型2:Chat Models(对话模型)
ChatModels,也叫聊天模型、对话模型,底层使用LLMs。
大语言模型调用,以 ChatModel 为主!
主要特点如下:
- 输入:接收消息列表 List[BaseMessage] 或 PromptValue ,每条消息需指定角色(如 SystemMessage、HumanMessage、AIMessage)
- 输出:总是返回带角色的 消息对象 ( BaseMessage 子类),通常是 AIMessage
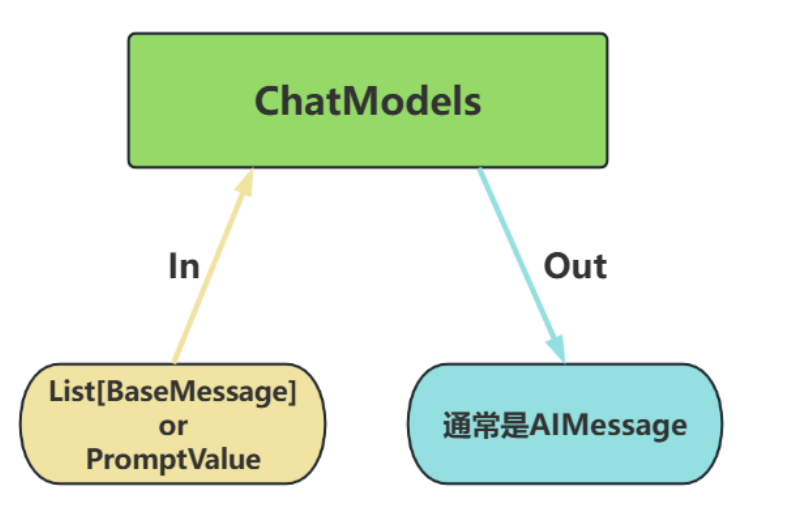
- 原生支持多轮对话。通过消息列表维护上下文(例如: [SystemMessage, HumanMessage, AIMessage, ...] ),模型可基于完整对话历史生成回复。
- 适用场景:对话系统(如客服机器人、长期交互的AI助手)
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")########核心代码############
chat_model = ChatOpenAI(model="gpt-4o-mini")messages = [SystemMessage(content="我是人工智能助手,我叫小智"),HumanMessage(content="你好,我是小明,很高兴认识你")
]#输入:list[basemessage]
#输出:AIMessage
response = chat_model.invoke(messages) # 输入消息列表print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
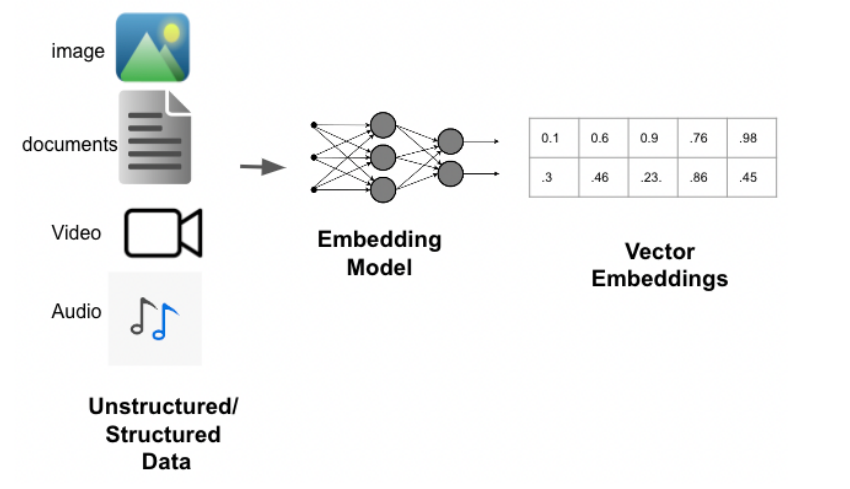
print(response.content)类型3:Embedding Model(嵌入模型)
Embedding Model:也叫文本嵌入模型,这些模型将 文本 作为输入并返回 浮点数列表 ,也就是 Embedding。后面会详细说
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")#############
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002"
)res1 = embeddings_model.embed_query('我是文档中的数据')
print(res1)
# 打印结果:[-0.004306625574827194, 0.003083756659179926, -0.013916781172156334, ...., ]3 、角度2出发:参数位置不同举例
这里以 LangChain 的API为准,使用对话模型,进行测试。
模型调用的主要方法及参数 相关方法及属性:
- OpenAI(...) / ChatOpenAI(...) :创建一个模型对象(非对话类/对话类)
- model.invoke(xxx) :执行调用,将用户输入发送给模型
- .content :提取模型返回的实际文本内容
模型调用函数使用时需初始化模型,并设置必要的参数。
1)必须设置的参数:
- base_url :大模型 API 服务的根地址
- api_key :用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供
- model/model_name :指定要调用的具体大模型名称(如 gpt-4-turbo 、 ERNIE-3.5-8K 等)
2)其它参数:
- temperature :温度,控制生成文本的“随机性”,取值范围为0~1。 值越低 → 输出越确定、保守(适合事实回答) 值越高 → 输出越多样、有创意(适合创意写作) 通常,根据需要设置如下:
- 精确模式(0.5或更低):生成的文本更加安全可靠,但可能缺乏创意和多样性。
- 平衡模式(通常是0.8):生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确 性。
- 创意模式(通常是1):生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
- max_tokens :限制生成文本的最大长度,防止输出过长。
Token是什么?
基本单位 : 大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token 依次生成。
收费依据 :大语言模型(LLM)通常也是以token的数量作为其计量(或收费)的依据。
1个Token≈1-1.8个汉字,1个Token≈3-4个英文字母
Token与字符转化的可视化工具:
OpenAI提供: https://platform.openai.com/tokenizer
百度智能云提供: https://console.bce.baidu.com/support/#/tokenizer
max_tokens设置建议:
- 客服短回复:128-256。比如:生成一句客服回复(如“订单已发货,预计明天送达”)
- 常规对话、多轮对话:512-1024
- 长内容生成:1024-4096。比如:生成一篇产品说明书(包含功能、使用方法等结构)
方式1:硬编码
直接将 API Key 和模型参数写入代码,仅适用于临时测试 ,存在密钥泄露风险,在 生产环境不推荐 。
from langchain_openai import ChatOpenAI
# 调用非对话模型:
# llms = OpenAI(...)# 调用对话模型:
chat_model = ChatOpenAI(#必须要设置的3个参数model_name="gpt-4o-mini", #默认使用的是gpt-3.5-turbo模型base_url="https://api.openai-proxy.org/v1",api_key="",)# 调用模型
response = chat_model.invoke("什么是langchain?")# 查看响应的文本
# print(response.content)
print(response) 方式2:配置环境变量
通过系统环境变量存储密钥,避免代码明文暴露。
使用 python-dotenv 加载本地配置文件,支持多环境管理(开发/生产)。
创建 .env 文件(项目根目录):

from langchain_openai import ChatOpenAI
import os
import dotenv#加载配置文件
dotenv.load_dotenv()# 1、获取对话模型:
chat_model = ChatOpenAI(#必须要设置的3个参数model_name="gpt-4o-mini", #默认使用的是gpt-3.5-turbo模型base_url=os.getenv("OPENAI_BASE_URL"),api_key=os.getenv("OPENAI_API_KEY1"),)# 2、调用模型
response = chat_model.invoke("什么是langchain?")# 3、查看响应的文本
# print(response.content)
print(response)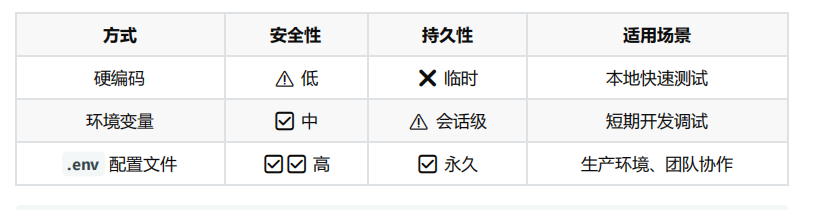
4 角度3出发:各平台API的调用举例
这里因为大模型种类太多就简单介绍两个,其他模型调用都是大差不差的
1 OpenAI 官方API
考虑到OpenAI在国内访问及充值的不便,我们仍然使用CloseAI网站( https://www.closeai
asia.com )不建议使用,要花钱咋们主打一个白嫖免费就行,这里主要看调用gpt模型就行
from openai import OpenAIclient = OpenAI(api_key="sk-zD4CB2Qe7G2Dp6veCfPRSxeDx9fQPxCUIfOFAk20ETV5B2VA", #填写自己的api-keybase_url="https://api.openai-proxy.org/v1")completion = client.chat.completions.create(model="gpt-3.5-turbo", # 对话模型messages=[{"role": "system", "content": "你是一个乐于助人的智能AI小助手"},{"role": "user", "content": "你好,请你介绍一下你自己"}],max_tokens=150,temperature=0.5
)print(completion.choices[0].message) 2 百度千帆平台
开发参考文档:
https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
获取API Key和App ID:
创建API Key: https://console.bce.baidu.com/qianfan/ais/console/apiKey
创建App ID: https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/applicatio
n/v2
from openai import OpenAIclient = OpenAI(api_key="bce-v3/ALTAK-Ynzfb6RBYeGiyI08yEXuf/21f994aeb874bbc0c55c3c4dc37a6b9b0cccaac1", # 千帆bearer tokenbase_url="https://qianfan.baidubce.com/v2", # 千帆域名default_headers={"appid": "app-y3sQKuT2"} # 用户在千帆上的appid,非必传
)completion = client.chat.completions.create(model="ernie-4.0-turbo-8k", # 预置服务请查看模型列表,定制服务请填入API地址messages=[{'role': 'system', 'content': 'You are a helpful assistant.'},{'role': 'user', 'content': 'Hello!'}]
)print(completion.choices[0].message)三、Model I/O之调用模型2
1 、关于对话模型的Message(消息)
聊天模型,出了将字符串作为输入外,还可以使用 聊天消息 作为输入,并返回 聊天消息 作为输出。
LangChain有一些内置的消息类型:
- 🔥 SystemMessage :设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总
- 体目标。比如“作为一个代码专家”,或者“返回json格式”。通常作为输入消息序列中的第一个
- 传递。
- 🔥 HumanMessage :表示来自用户输入。比如“实现 一个快速排序方法”
- 🔥 AIMessage :存储AI回复的内容。这可以是文本,也可以是调用工具的请求
- ChatMessage :可以自定义角色的通用消息类型
- FunctionMessage/ToolMessage :函数调用/工具消息,用于函数调用结果的消息类型
注意:
FunctionMessage和ToolMessage分别是在函数调⽤和⼯具调⽤场景下才会使⽤的特殊消息类
型,HumanMessage、AIMessage和SystemMessage才是最常⽤的消息类型。
from langchain_openai import ChatOpenAI
import os
import dotenv# 前提:加载配置文件
dotenv.load_dotenv()os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")# 1、获取对话模型
chat_model = ChatOpenAI(# api_key=,# base_url=,model_name="gpt-4o-mini",
)# 2、调用对话模型
response = chat_model.invoke("帮我解释一下什么是langchain?")# 3、处理响应数据
# print(response)
print(response.content)
print(type(response)) #<class 'langchain_core.messages.ai.AIMessage'>from langchain_core.messages import SystemMessage, HumanMessagesystem_message = SystemMessage(content="你是一个英语教学方向的专家")
human_message = HumanMessage(content="帮我制定一个英语六级学习的计划")messages = [system_message, human_message]print(messages)response = chat_model.invoke(messages)
print(type(response))
print(response.content)2 、关于多轮对话与上下文记忆
前提:获取大模型
import os
import dotenv
from langchain_openai import ChatOpenAIdotenv.load_dotenv()os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")chat_model = ChatOpenAI(model="gpt-4o-mini"
) 测试1:
大模型本身是没有上下文记忆能力的
from langchain_core.messages import SystemMessage, HumanMessagesys_message = SystemMessage(content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")messages = [sys_message, human_message]#调用大模型,传入messages
response = chat_model.invoke(messages)
# print(response.content)response1 = chat_model.invoke("你叫什么名字?")
print(response1.content)测试2:
from langchain_core.messages import SystemMessage, HumanMessagesys_message = SystemMessage(content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
human_message1 = HumanMessage(content="你叫什么名字?")messages = [sys_message, human_message,human_message1]#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)测试3:
from langchain_core.messages import SystemMessage, HumanMessagesys_message = SystemMessage(content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")sys_message1 = SystemMessage(content="我可以做很多事情,有需要就找我吧",
)human_message1 = HumanMessage(content="你叫什么名字?")messages = [sys_message, human_message,sys_message1,human_message1]#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)测试4:
from langchain_core.messages import SystemMessage, HumanMessage# 第1组
sys_message = SystemMessage(content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")messages = [sys_message, human_message]# 第2组
sys_message1 = SystemMessage(content="我可以做很多事情,有需要就找我吧",
)human_message1 = HumanMessage(content="你叫什么名字?")messages1 = [sys_message1,human_message1]#调用大模型,传入messages
response = chat_model.invoke(messages)
# print(response.content)response = chat_model.invoke(messages1)
print(response.content)测试5:
from langchain_core.messages import SystemMessage, HumanMessage, AIMessagemessages = [SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),HumanMessage(content="人工智能英文怎么说?"),AIMessage(content="AI"),HumanMessage(content="你叫什么名字"),
]messages1 = [SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),HumanMessage(content="很高兴认识你"),AIMessage(content="我也很高兴认识你"),HumanMessage(content="你叫什么名字"),
]messages2 = [SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),HumanMessage(content="人工智能英文怎么说?"),AIMessage(content="AI"),HumanMessage(content="你叫什么名字"),
]chat_model.invoke(messages2)3 、关于模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个 "Runnable" 协议。许多LangChain组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
- invoke : 处理单条输入,等待LLM完全推理完成后再返回调用结果
- stream : 流式响应,逐字输出LLM的响应结果
- batch : 处理批量输入
- 这些也有相应的异步方法,应该与 asyncio 的 await 语法一起使用以实现并发:
- astream : 异步流式响应
- ainvoke : 异步处理单条输入
- abatch : 异步处理批量输入
- astream_log : 异步流式返回中间步骤,以及最终响应
- astream_events : (测试版)异步流式返回链中发生的事件(在 langchain-core 0.1.14 中引入)
流式输出与非流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出 与 非流式输出 。
下面是两个场景:
非流式输出:这是Langchain与LLM交互时的 默认行为 ,是最简单、最稳定的语言模型调用方式。 当用户发出请求后,系统在后台等待模型 生成完整响应 ,然后 一次性将全部结果返回 。
举例:用户提问,请编写一首诗,系统在静默数秒后 突然弹出 了完整的诗歌。(体验较单
调) 在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。
流式输出:一种 更具交互感 的模型输出方式,用户不再需要等待完整答案,而是能看到模型 逐个 token 地实时返回内容。
举例:
用户提问,请编写一首诗,当问题刚刚发送,系统就开始 一字一句 (逐个token)进行回复,感觉是一边思考一边输出。更像是“实时对话”,更为贴近人类交互的习惯,更有吸引力。 适合构建强调“实时反馈”的应用,如聊天机器人、写作助手等。 Langchain 中通过设置 stream=True 并配合 回调机制 来启用流式输出。
非流式输出:
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAIdotenv.load_dotenv()os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")#初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]# 非流式调用LLM获取响应
response = chat_model.invoke(messages)# 打印响应内容
print(response) 流式输出
一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容。适合构建强调“实时反馈”的应用,如聊天机器人、写作助手等。 Langchain 中通过设置 streaming=True 并配合 回调机制 来启用流式输出。
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAIdotenv.load_dotenv()os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini",streaming=True # 启用流式输出)# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]# 流式调用LLM获取响应
print("开始流式输出:")
for chunk in chat_model.stream(messages):# 逐个打印内容块print(chunk.content, end="", flush=True) # 刷新缓冲区 (无换行符,缓冲区未刷新,内容可能不会立即显示)print("\n流式输出结束") 批量调用
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAIdotenv.load_dotenv()os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),HumanMessage(content="请帮我介绍一下什么是机器学习"), ]messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"),HumanMessage(content="请帮我介绍一下什么是AIGC"), ]messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"),HumanMessage(content="请帮我介绍一下什么是大模型技术"), ]messages = [messages1, messages2, messages3]# 调用batch
response = chat_model.batch(messages)print(response)