说一下SpringBoot3新特新和JDK17新特性
JDK1.8(Java8)新特性
stream流式编程
流处理 Stream API 提供了对集合数据进行操作的一种高效、简洁的方式。它支持顺序和并行的聚合操作
如:过滤(filter)、排序(sort)、映射(map)、归约、collect(收集)等。

Lambda表达式
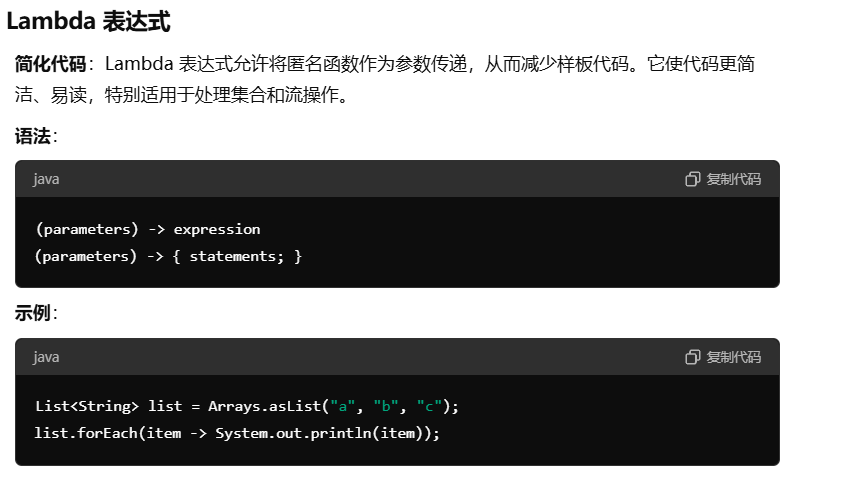
CompletableFuture并发编程
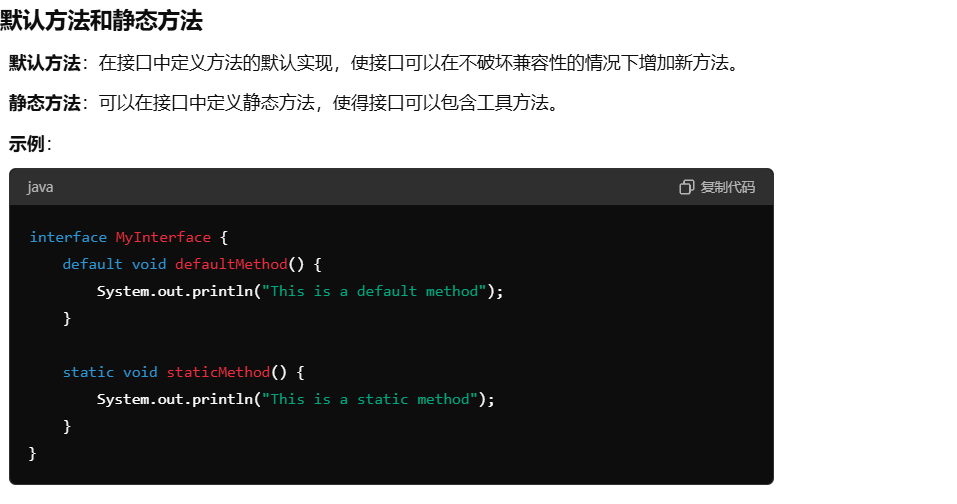
接口中的默认方法和静态方法
新日期和时间类型
旧
之前的包:java.util.Date,java.util.Calendar,java.text.SimpleDateFormat
新
新的包:java.time
里面有LocalDate 表示日期(不含时间)
LocalTime 表示时间(不含日期)
LocalDateTime 表示日期和时间
zonedDateTime 表示带时区的日期和时间
均为不可变对象,天然线程安全
为什么说之前的日期类型线程不安全而且可用性差
线程不安全
Date和Calendar是可变的,对象可能在多线程环境下被意外修改,导致数据不一致
例如可以通过setTime()和add()方法直接修改对象的值
Calendar calendar = Calendar.getInstance();
calendar.set(2023, Calendar.JANUARY, 1);
// 其他代码可能修改 calendar 的值,导致不可预测的行为SimpleDateFormat是非线程安全类,开发者必须通过同步或每次创建新实例来规避问题
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
// 多线程调用 sdf.parse(dateStr) 会导致竞争条件功能缺失
问题:旧 API 缺少现代日期时间操作所需的特性:
不支持时区处理:需要手动计算时区偏移,容易出错。
无法直接进行日期算术:如计算两个日期之间的天数差需要复杂操作。
格式化与解析能力弱:依赖 SimpleDateFormat,且格式字符串易出错(如大小写敏感)
// 计算两个日期相差的天数(旧 API)
Calendar c1 = Calendar.getInstance();
Calendar c2 = Calendar.getInstance();
long diffMillis = c2.getTimeInMillis() - c1.getTimeInMillis();
long diffDays = diffMillis / (24 * 60 * 60 * 1000); // 可能因闰秒、时区等问题出错JDK17新特性
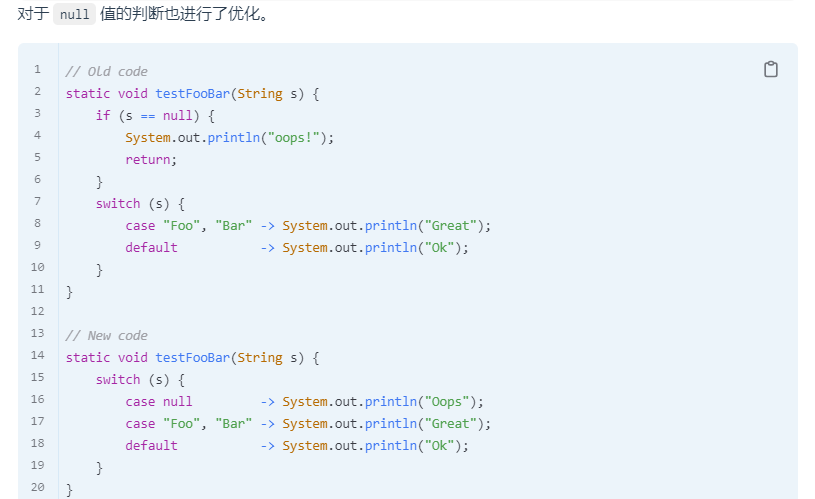
switch的类型匹配
正如 instanceof 一样, switch 也紧跟着增加了类型匹配自动转换功能
instanceof代码展示

swtich代码示例
switch有了类型转换


case能对null进行判断
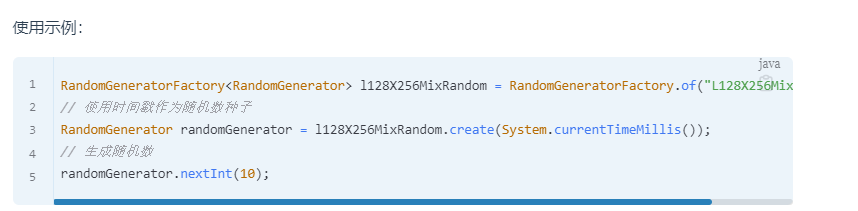
增强的伪随机数生成器
之前我们的Random,ThreadLocalRandom,SplittableRandom来生成伪随机数
不过这些类里面缺少常见的伪随机算法支持
所以我们有了个RandomGenerator类

说一下以前的随机数生成器的缺陷
主要就是线程不安全,算法单一,算法不能灵活切换这些问题
Random
Random 在多线程环境下的性能较差,因为多个线程可能会竞争同一个随机数生成器的实例,导致性能瓶颈
多线程环境中,如果多个线程使用 Random 的同一个实例,访问会被锁定。假设有 10 个线程同时请求随机数,只有一个线程能生成随机数,其他线程需要等待,这会导致性能瓶颈
ThreadLocalRandom
ThreadLocalRandom 虽然为多线程优化,但它的功能相对单一,缺乏对多种伪随机算法的支持
ThreadLocalRandom 每个线程都有自己的实例,避免了锁竞争,但不能自由切换到其他伪随机算法
SplittableRandom
SplittableRandom 提供了一些改进,但仍然不够灵活,无法轻松地切换和使用不同的伪随机算法
RandomGenerator类的优点
1.允许开发者轻松选择和交换不同的伪随机数生成算法
2.新设计的随机数生成器在多线程环境下表现更佳,因为它们可以避免锁竞争。
3.新版算法支持多种常见的伪随机算法,开发者可以根据具体需求选择最适合的。
外部函数和内存API(孵化)
在 Java 开发中,有时需要使用 Java 本身无法直接提供的功能,比如调用操作系统底层的函数、使用一些用 C 或 C++ 编写的高性能库等
外部函数和内存 API 提供了一种机制,让 Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作
通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 JEP 412 提出
删除远程方法调用激活机制(RMI)
删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。RMI 激活机制已过时且不再使用
RMI(远程方法调用)
RMI 是 Java 提供的一种机制,允许一个 Java 程序调用另一个 Java 程序中的对象方法,即使它们在不同的计算机上运行。RMI 提供了一种简单的方式来实现分布式计算。
激活机制
RMI 激活机制是一种允许远程对象在需要时被动态创建和激活的机制。这意味着如果一个远程对象没有在 JVM 中运行,RMI 可以根据需要自动启动它。这种机制最初是为了提供灵活性,使得远程对象可以按需创建,而不需要在每次调用时都确保对象已存在。
删除激活机制的原因
过时:随着技术的发展,RMI 激活机制被认为已经不再适用或使用频率低,可能是因为新的技术和框架(如 RESTful API、gRPC、微服务架构等)提供了更好的解决方案。
复杂性:激活机制增加了 RMI 的复杂性,可能导致开发者在使用时遇到更多问题。
维护成本:随着时间推移,维护不再使用的功能会增加开发团队的负担。
密封类(转正)
密封类在JDK17中变成了一个稳定的特性
密封类(Sealed Classes)是 Java 语言的一项特性,最初由 JEP 360 提出,并在 Java 15 中以预览形式集成。
密封类允许开发者控制哪些类可以继承或实现该类,从而提高代码的安全性和可维护性。
JEP 360:这是提出密封类的提案,定义了密封类的基本概念和用法。
Java 15:在此版本中,密封类作为预览特性被引入,意味着开发者可以尝试使用,但它仍可能会在未来的版本中进行修改。
JDK 16:在这个版本中,密封类得到了改进,包括更严格的引用检查和对密封类继承关系的增强,这些改进是通过 JEP 397 提出的,并再次以预览形式提供
弃用的Applet API进行删除
Applet API 是一种用于创建可以在 Web 浏览器中运行的 Java 小程序的技术。然而,这种技术在很多年前就已经被淘汰,现代的 Web 开发中几乎没有人再使用它,因此没有必要继续支持。
被标记弃用:在 Java 9 中,Applet API 被标记为弃用(通过 JEP 289),这意味着开发者被建议不再使用它,但它并没有立即被删除。
不再使用的原因:随着 Web 技术的发展,像 HTML5、JavaScript 和其他现代框架变得更流行,Applet 的使用逐渐减少,导致其不再适用。
因此,虽然 Applet API 仍然存在于 Java 中,但它被认为是过时的技术,未来可能会被完全删除。
弃用的安全管理器
安全管理器(Security Manager)是 Java 中的一种机制,主要用于控制应用程序的权限和访问限制。它通过定义安全策略来决定 Java 应用程序可以执行哪些操作,从而保护系统的安全性
然而,随着时间的推移,这个机制逐渐被认为不再适用于现代的安全需求。
弃用的原因:Java 17 中决定弃用安全管理器,意味着将来可能会完全移除它。安全管理器在多年来并未成为保护客户端和服务器端 Java 代码的主要方法,使用频率非常低。这使得继续维护和支持它变得不再必要。
与 Applet API 的关系:安全管理器的弃用与 Applet API 的弃用相辅相成,反映了 Java 在向前发展过程中,清理过时和不再使用的特性的决心
SpringBoot3新特性
语言与框架基础升级
Java 17+:强制要求 Java 17 或更高版本,利用新语言特性(如密封类、模式匹配等)
Jakarta EE 9+:包命名空间从 javax.* 迁移到 jakarta.*(如 Servlet、JPA 等接口)
现代化安全支持
Spring Security 6:默认集成,支持 OAuth2 2.0、更简洁的配置方式
更严格的 CSRF 策略:默认启用 CSRF 保护,对 RESTful API 更友好
引入新的安全特性、修复已知安全漏洞,提供更强大的身份验证和授权机制,例如默认启用 https 和更严格的 CSP(内容安全策略)配置
新增配置注解
@ConfigurationProperties,简化读取配置文件配置
@ConfigurationPropertiesScan,对特定的包进行扫描
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.ConfigurationPropertiesScan;
@SpringBootApplication
// 扫描带有 @ConfigurationProperties 注解的类
@ConfigurationPropertiesScan
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}@SpringBootApplication
@ConfigurationPropertiesScan(basePackages = "com.example.config")
public class MyApplication {
// ...
}智能事务回滚(精准定位脏数据)
传统事务(无脑回滚) :使用 @Transactional 注解的方法,当执行批量更新操作(如 100 条数据更新)时,只要其中某一条(如第 50 条)更新失败,整个事务就会全部回滚,所有已更新的数据都会恢复原状,即便其他数据更新操作本身没有问题。
Spring Boot 3.4 神技(精准回滚) :
- 新增
@Transactional的smartRollbackFor属性,可指定需要回滚的异常类,如DataIntegrityViolationException(数据完整性违规异常)和OptimisticLockingFailureException(乐观锁失败异常)。 - 执行批量更新时,若发生异常,仅会回滚触发异常的那笔记录。结合图中代码,
jdbcTemplate进行批量更新,并使用SmartBatchPreparedStatementSetter,可以更精准地控制事务回滚范围。
核心配置 :在 application.yml 配置文件中,通过 spring.transaction.smart-rollback.enabled 开启智能回滚功能,设为 true 表示启用;savepoint-interval 则用于设置保存点间隔,图中设置为每 10 条数据设置一个保存点,便于精准定位和回滚出现问题的数据 。
Spring Boot 3.4 的智能事务回滚机制,相比传统事务回滚,能减少不必要的数据回滚操作,提高数据处理的准确性和事务处理的效率
在 Spring 事务管理中,@Transactional 的 smartRollbackFor 属性和普通的 rollbackFor 属性有以下区别:
回滚粒度:
rollbackFor:它是一个传统的事务回滚控制属性,当方法执行过程中抛出的异常类型匹配到 rollbackFor 所指定的异常或其子类时,整个事务范围内的所有操作都会进行回滚 。比如在批量操作场景中,即便只有一条数据操作出现异常,只要该异常类型符合 rollbackFor 的设定,整个事务涉及的所有数据变更都会被回滚
smartRollbackFor:这是 Spring Boot 3.4 及后续版本新增的属性,主要用于实现精准回滚。当方法执行抛出 smartRollbackFor 指定的异常类型时,只会回滚触发异常的那笔记录或相关局部操作,而不是整个事务的所有操作
例如在数据批量更新时,某条数据更新因违反数据完整性约束抛出异常,使用 smartRollbackFor 就仅回滚这条有问题的数据更新,其他正常更新的数据不受影响
应用场景:
rollbackFor:适用于对事务一致性要求极高,希望在出现特定异常时,保证所有操作要么都成功、要么都失败的场景。比如金融系统中的转账操作,涉及多个账户的资金变动,只要其中一个步骤失败,就需要全部回滚,以保证资金的一致性
smartRollbackFor:更适合于一些批量处理或复杂业务逻辑场景,在这些场景中部分操作失败不影响其他操作的继续执行,并且希望尽可能保留已成功的操作结果,提高事务处理的效率和灵活性,减少不必要的数据回滚
底层机制差异:
rollbackFor:基于传统的事务回滚机制,当满足回滚条件时,Spring 会按照事务传播机制和隔离级别等相关配置,统一对整个事务进行回滚处理。
smartRollbackFor:其实现依赖于保存点(savepoint)机制等更精细的事务控制手段。在执行过程中,会按照配置(如设置保存点间隔)创建保存点,当遇到指定异常时,回滚到最近的相关保存点位置,实现精准的局部回滚
使用smartRollbackFor
场景一:电商订单商品批量更新
场景二:员工信息批量导入
保存点和回滚条数的关系
假设我们配置了每10条记录为一个保存点
spring:
transaction:
smart-rollback:
enabled: true
savepoint-interval: 10事务执行正常
事务开始
→ 处理第1-10条 → 设置保存点A
→ 处理第11-20条 → 设置保存点B
→ ... → 处理第91-100条 → 设置保存点J
事务提交(全部成功)第15条失败
事务开始
→ 处理第1-10条 → 设置保存点A ✔️
→ 处理第11-15条 → 第15条失败 ❌
→ 回滚到保存点A(保留前10条)
→ 重新处理第11-15条(若配置了重试)第7条失败
事务开始
→ 处理第1-7条 → 第7条失败 ❌
→ 没有保存点 → 回滚整个事务(前6条也丢失)第99条失败
事务开始
→ 处理第1-90条 → 设置保存点I ✔️
→ 处理第91-99条 → 第99条失败 ❌
→ 回滚到保存点I(保留前90条)配置 savepoint-interval 的权衡
| 配置值 | 优点 | 缺点 |
|
| 每条记录独立回滚,精度最高 | 保存点过多,性能差 |
|
| 平衡回滚精度和性能 | 可能丢失最多9条数据 |
|
| 性能最优 | 失败时可能丢失99条数据 |
声明式Http客户端
传统的RestTemplate调用
RestTemplate template = new RestTemplate();
ResponseEntity<User> response = template.getForEntity(url, User.class);
if (response.getStatusCode() == HttpStatus.OK) {
User user = response.getBody();
} @HttpExchange注解调用
@HttpExchange(url = "/api/users", accept = "application/json")
public interface UserClient {
@GetExchange("/{id}")
User getById(@PathVariable Long id);
@PostExchange
User create(@RequestBody User user);
}
// 自动注入使用
@Autowired
private UserClient userClient;
public User getUser(Long id) {
return userClient.getById(id);
}