大模型如何协助知识图谱进行实体关系之间的分析

大模型在知识图谱中协助进行实体关系分析的方式主要体现在以下几个方面:
-
增强数据标注与知识抽取
大模型通过强大的自然语言处理能力,能够高效地对原始数据进行实体、关系和事件的标注,从而提高数据处理的效率和准确性。例如,DeepKE-LLM等模型可以用于实体抽取、关系抽取和因果关系抽取,显著提升知识图谱构建的质量和效率。此外,大模型还可以通过少量标注数据实现非结构化文本中的实体和关系抽取,减少人工标注的需求。
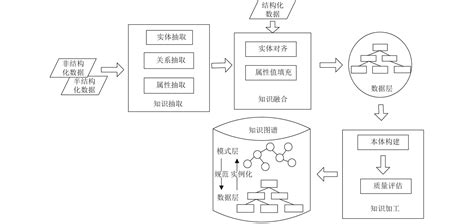
-
提升知识图谱的构建质量
大模型能够通过语义理解能力,从文本中提取复杂的实体和关系信息,并将其组织成知识图谱的形式。例如,BERT等模型可以用于实体识别和链接,将文本中的实体与知识图谱中的实体进行匹配,从而构建更加完整和准确的知识图谱。此外,大模型还可以通过预测实体之间的关系(如TransE模型),进一步完善知识图谱的结构。

-
增强知识建模与推理能力
大模型不仅能够提取知识,还能对知识进行更深层次的理解和建模。例如,通过将实体和关系编码为向量表示,大模型可以实现深度学习和推理,挖掘知识图谱中的复杂结构和语义关系。这种能力使得大模型能够在知识图谱的推理任务中发挥重要作用,例如基于规则或逻辑的推理。 -
自动化知识图谱构建与扩展
大模型可以辅助知识图谱的自动化构建,减少人工干预。例如,通过图计算技术,大模型可以从海量文本中自动挖掘有价值的实体、关系及属性,并动态扩充知识图谱。此外,大模型还可以通过跨领域和跨语言的知识整合,构建更全面的知识图谱。 -
提升知识图谱的应用性能
大模型可以通过语义匹配能力提高知识图谱在问答系统、推荐系统等应用场景中的表现。例如,通过计算用户问题与知识图谱中实体和关系的语义相似度,大模型可以返回最相关的答案。此外,大模型还可以通过知识补全和图扩展功能,自动修正和补充知识图谱中的缺失信息。 -
结合知识图谱优化大模型训练
知识图谱也可以反过来指导大模型的学习过程。例如,通过将知识图谱中的实体和关系作为输入,大模型可以更好地理解和预测文本中的内容。这种方法不仅可以提高大模型的性能,还能增强其在特定领域的应用能力。
大模型通过其强大的语义理解、数据标注和推理能力,在知识图谱的构建、优化和应用中发挥了重要作用。它不仅提升了知识图谱的质量和效率,还为其在复杂任务中的应用提供了强有力的支持。
大模型在实体关系分析中处理多义词和同义词的方式主要依赖于其强大的上下文建模能力和语义理解能力。以下是基于我搜索到的资料对这一问题的详细分析:
-
多义词的处理:
-
大模型通过上下文敏感的词向量表示来区分多义词的不同含义。例如,Transformer模型通过分词和上下文分析,结合每个词的特征,来理解词在具体语境中的实际含义。这种方法使得模型能够捕捉到多义词在不同语境下的细微差异,并据此进行预测。
-
在某些研究中,多义词被建模为一个共同的机制,而不是独立的表示。这种生成模型认为多义词的不同含义可以通过其内部结构的修改和解释来生成。这种方法避免了为每个多义词的不同含义创建单独表示的复杂性。
-
另外,一些研究通过特定的模型(如多义性模型)来处理多义词问题。例如,多义性模型能够生成不同语境下多义词的典型性值,并生成相应的多义词。
-
-
同义词的处理:
- 大模型通过上下文建模能力来区分同义词的不同用法。例如,通过计算词向量之间的相似度,模型可以识别出在特定语境下具有相似语义的词语。
- 在电商搜索等场景中,AI大模型通过深度学习技术对同义词进行识别和转换,从而优化搜索结果的匹配度。
- 一些研究还利用知识库或语义网络来增强对同义词的理解。例如,通过将知识库中的嵌入映射到模型的嵌入空间中,可以实现知识的平滑转移,从而更好地处理同义词。
-
结合上下文和知识库:
- 大模型通常结合上下文信息和外部知识库来提高对多义词和同义词的理解能力。例如,在生物医学领域,通过结合具体上下文推断实体类型,可以有效解决多义词问题。
- 在知识图谱构建中,大模型通过实体链接技术将新实体与知识库中的对应实体进行链接,从而解决多义词和同义词带来的歧义问题。
-
技术挑战与未来方向:
- 尽管大模型在处理多义词和同义词方面表现出色,但仍存在一些挑战。例如,模型对细微语义差异的理解不足,以及在复杂语境中的泛化能力有限。
- 未来的研究方向包括进一步提升模型对语义歧义的辨识与处理能力,优化模型在复杂语境中的语义分析能力。
大模型通过上下文敏感的词向量表示、知识库结合以及生成模型等方法,有效处理了多义词和同义词的问题。这些技术不仅提高了模型的语义理解能力,还增强了其在自然语言处理任务中的准确性和泛化能力。