4.cuda全局内存--还没完事
4. cuda 全局内存
本章目的:剖析核函数与全局内存的联系以及对性能的影响。
4.1 CUDA内存模型概述
目的:在现有的硬件存储子系统下,必须依靠内存模型获得最佳的延迟与带宽。
4.1.1 内存层次结构的优点
应用程序往往遵循局部性原则,这表明他们可以在任意时间点访问相对较小的局部地址空间。有两种不同类型的局部性:
- 时间局部性:如果一个数据位置被引用的话,则该数据可能在较短的时间周期内会再次被引用。随着时间退役,则数据被引用的可能性会逐步降低。
- 空间局部性:如果一个内存位置被引用,则附近的位置也可能会被引用。
内存结构分布,自顶而下:
- 寄存器
- 缓存
- 主存
- 磁盘存储器
容量依次增长,价格依次降低。
cpu与gpu的主存采用的时DRAM(动态随机存取存储器),而低延迟内存(如cpu一级缓存) 采用的时SRAM(静态随机存取存储器)。
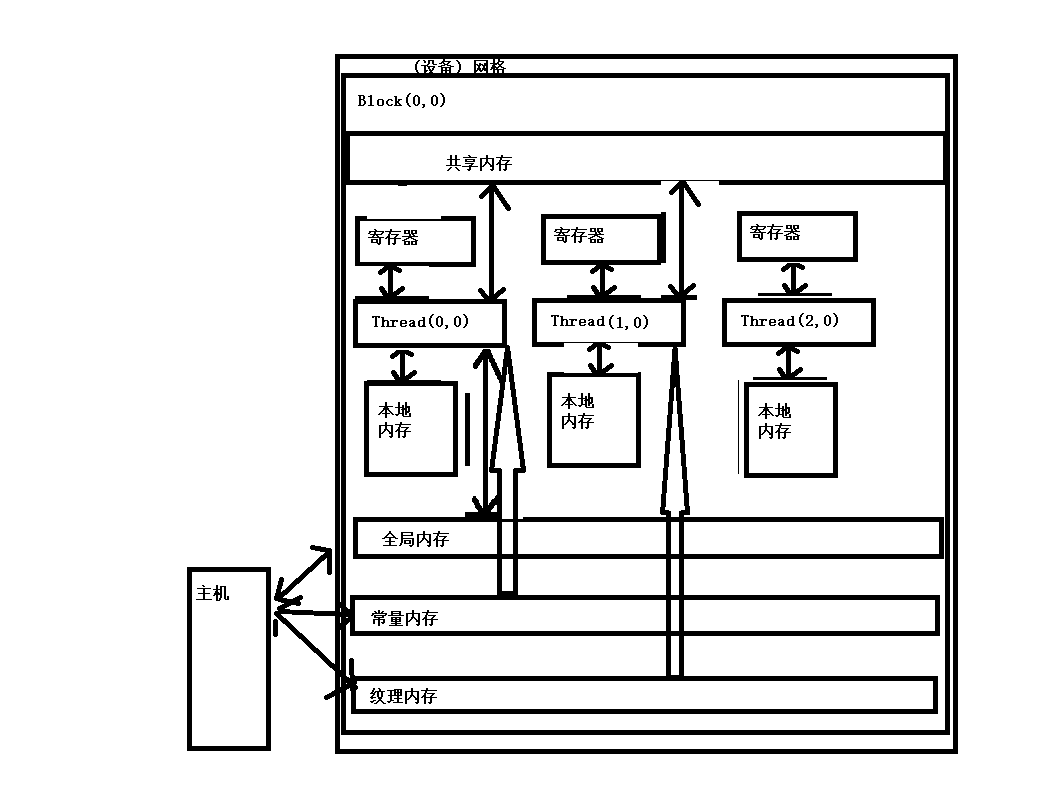
4.1.2 CUDA内存模型
对于程序员来讲的话,通常会有两种类型存储器
- 可编程的:你需要显式的控制拿写数据存放在可编程内存中。
- 不可编程的:你不能决定数据的存储位置,程序将自动决定数据存放的位置已获得良好的性能。
在cpu内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。另一方面,CUDA内存模型提出了多种可编程内存的类型:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
4.1.2.4 常量内存
修饰符:
__constant__
常量内存拷贝
cudaError_t cudaMemecpyTosymbol(const void* symbol,const void* src,size_t count);
将count个字节从src指向的内存复制到symbol中。
#include <iostream>
#include <cuda_runtime.h>#define N 5// 定义 __constant__ 常量内存数组
__constant__ int const_data[N];// kernel 访问常量内存
__global__ void readConstantKernel(int* out) {int idx = threadIdx.x;if (idx < N) {out[idx] = const_data[idx]; // 从常量内存中读取}
}int main() {int h_data[N] = {1, 2, 3, 4, 5};// 将主机数据拷贝到 __constant__ 内存中cudaMemcpyToSymbol(const_data, h_data, sizeof(int) * N);// 为输出数据分配设备内存int* d_out;cudaMalloc(&d_out, sizeof(int) * N);// 启动 kernelreadConstantKernel<<<1, N>>>(d_out);// 拷贝结果回主机int h_out[N];cudaMemcpy(h_out, d_out, sizeof(int) * N, cudaMemcpyDeviceToHost);// 打印结果std::cout << "从 __constant__ 内存读取的数据: ";for (int i = 0; i < N; ++i) {std::cout << h_out[i] << " ";}std::cout << std::endl;// 清理cudaFree(d_out);return 0;
}4.1.2.5 全局内存
是gpu中最大,延迟最高,并且最常使用的内存。global指的是其作用域和生命周期。它的声明可以在任何SM设备中被访问到,并且贯穿应用程序的整个声明周期。
__device__
#include<iostream>
#include<stdio.h>
#include<cuda_runtime.h>
__device__ float static_global_data;
__global__ void checkGlobalData() {printf("enter it : %f\n",static_global_data);// std::cout << "enter it :" << static_global_data << std::endl;static_global_data += 2.0f;
}
int main() {float value = 3.14f;cudaMemcpyToSymbol(static_global_data,&value,sizeof(float));std::cout << "host copy to global varaiable :" << value << std::endl;checkGlobalData<<<1,1>>>();cudaMemcpyFromSymbol(&value,static_global_data,sizeof(float));std::cout << "change :host copy to global varaiable :" << value << std::endl;cudaDeviceReset();return 0;
}
host copy to global varaiable :3.14
enter it : 3.140000
change :host copy to global varaiable :5.14
4.2 内存管理
4.2.1 内存分配和释放
cudaError_t cudaMalloc(void** devptr,size_t count)
cudaError_t cudaMemset(void* devptr,int value,size_t count);
cudaError_t cudaFree(void* ptr);
4.2.2 内存传输
cudaError_t cudaMemcpy(void* dst,const void* src,size_t count,enum cudaMemcpyKind kind);
enum:{cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevice
}
#include<iostream>
#include<cuda_runtime.h>
int main(int argc,char** argv) {int dev = 0;cudaSetDevice(dev);unsigned int issize = 1 << 22;unsigned int bytes = issize * sizeof(float);cudaDeviceProp deviceProp;cudaGetDeviceProperties( &deviceProp,dev);std::cout << "starting at :" << argv[0] << std::endl;float* h_a;h_a = (float*) malloc(sizeof(float) * issize);float* d_a;cudaMalloc((float**) &d_a , bytes);for(int i = 0; i < issize; ++i) {h_a[i] = 0.5f;}cudaMemcpy( d_a, h_a, bytes , cudaMemcpyHostToDevice);cudaMemcpy( h_a, d_a, bytes , cudaMemcpyDeviceToHost);cudaFree(d_a);free(h_a);cudaDeviceReset();return 0;
}
结论:尽可能的减少主机与设备之间的传输。
4.2.3 固定内存
存在的意义:gpu不能在可分页主机内存上安全地访问数据,因为当主机操作系统在物理位置上移动该数据时,它无法控制。当从可分页主机内存传输数据到设备内存中时,cuda驱动程序首先分配临时页面锁定的或固定的主机内存,将主机源数据复制到固定内存中时,然后从固定内存中传输数据给设备内存。
分配固定主机内存函数:
cudaError_t cudaMallocHost(void** devptr,size_t count);
cudaError_t cudaFreeHost(void* ptr);
why?
- 分配和释放成本更高。但是它为大规模数据传输提供了更高的传输吞吐量。
- 相对于分页内存来看,使用固定内存可以获得加速。
- 减少单位传输消耗。
- 主机和设备之间可能于内核执行重叠。
4.2.4 零拷贝内存
原理:
统一内存虚拟寻址方式(UVA). 通过这种方式,其有cudaHostAlloc 函数分配的固定主机内存具有相同的主机和设备指针。 然后使用cudaHostGetDevicePointer 函数将返回的指针直接应用于核函数
GPU线程可以直接访问零拷贝内存。在cuda核函数中使用零拷贝内存有以下几个优势:
- 当设备内存不足时可利用主机内存。
- 避免主机和设备间的显式数据传输。
- 提高pcle 传输率。
零拷贝内存时固定(不可分页) 内存。该内存映射到设备地址空间中。****
cudaError_t cudaHostAlloc(void** pHost,size_t count,unsigned int flags);
flags:cudaHostAllocDefault == cudaMallocHostcudaHostAllocPortable 可以返回能被所有cuda上下文使用的固定内存,而不仅时执行内存分配的哪一个cudaHostAllocWriteCombined 该内存通过设备使用映射的固定内存或主机到设备的传输cudaHostAllocMapped 可以实现主机写入和设备读取被映射到设备地址空间中的主机内存。如何获取映射到固定内存的设备指针:
cudaError_t cudaHostGetDevicePointer(void** pDevice,void* pHost,unsigned int flags)#include<stdio.h>
#include<cuda_runtime.h>
#include<sys/time.h>
void init_data(float* data,int size) {for(int i = 0; i < size; ++i) {data[i] = i * 1.1;}
}
void sumArrayOnHost(float* a, float* b,float* c ,size_t nelem) {for(int i = 0; i < nelem; ++i) {c[i] = a[i] + b[i];}
}
double cpuSecond() {struct timeval tp;gettimeofday(&tp,NULL);return ((double)tp.tv_sec + (double)tp.tv_usec*1e-6);}
__global__ void sumOnArray(float* a,float*b, float*c , int n_elem) {int idx = blockIdx.x * blockDim.x + threadIdx.x;if(idx < n_elem) {c[idx] = a[idx] + b[idx];}
}
bool checkResult(float* a, float* b, int n_elem) {for(int i = 0; i < n_elem; ++i) {if(a[i] != b[i]) {return false;}}return true;
}
int main() {int dev = 0;cudaSetDevice(dev);cudaDeviceProp prop;cudaGetDeviceProperties(&prop ,dev);if(!prop.canMapHostMemory) {printf("%ddevice can not support mapping cpu host memeory\n",dev);cudaDeviceReset();exit(EXIT_SUCCESS);}printf("using Devvie %d \t: %s\n",dev,prop.name);int nelem = 1 << 24;size_t n_bytes = sizeof(float) * nelem;float* h_a ,*h_b,*hostRef,*gpuRef;double start = cpuSecond();h_a = (float*) malloc(n_bytes);h_b = (float*) malloc(n_bytes);hostRef = (float*) malloc(n_bytes);gpuRef = (float*) malloc(n_bytes);init_data(h_a,nelem);init_data(h_b,nelem);memset(hostRef,0,n_bytes);memset(gpuRef,0,n_bytes);sumArrayOnHost(h_a,h_b,hostRef,nelem);float* d_a,*d_b,*d_c;cudaMalloc((float**)&d_a ,n_bytes );cudaMalloc((float**)&d_b ,n_bytes );cudaMalloc((float**)&d_c ,n_bytes );cudaMemcpy(d_a ,h_a ,n_bytes , cudaMemcpyHostToDevice);cudaMemcpy(d_b ,h_b ,n_bytes , cudaMemcpyHostToDevice);int iLen = 512;dim3 block(iLen);dim3 grid((nelem + block.x - 1) / block.x);sumOnArray<<<grid,block>>>(d_a,d_b,d_c,nelem);cudaMemcpy( gpuRef,d_c ,n_bytes , cudaMemcpyDeviceToHost);printf("check result is %s\n", checkResult(gpuRef, hostRef, nelem) ? "True" : "False");cudaFree(d_a);cudaFree(d_b);free(h_a);free(h_b);double end = cpuSecond();printf("as usually cost %f ms\n",end-start);start = cpuSecond();unsigned int flags = cudaHostAllocMapped;cudaHostAlloc((void**)&h_a ,n_bytes ,flags);cudaHostAlloc((void**)&h_b ,n_bytes ,flags);memset(hostRef,0,n_bytes);memset(gpuRef,0,n_bytes);cudaHostGetDevicePointer((void**)&d_a,(void*)h_a,0);cudaHostGetDevicePointer((void**)&d_b,(void*)h_b,0);sumArrayOnHost(h_a,h_b,hostRef,nelem);sumOnArray<<<grid,block>>>(d_a,d_b,d_c,nelem);cudaMemcpy(gpuRef ,d_c ,n_bytes , cudaMemcpyDeviceToHost);printf("check result is %s\n", checkResult(gpuRef, hostRef, nelem) ? "True" : "False");cudaFree(d_c);cudaFreeHost(h_a);cudaFreeHost(h_b);free(hostRef);free(gpuRef);cudaDeviceReset();end = cpuSecond();printf("use zero copy memeory cost %f ms\n",end-start);return 0;
}
4.3 内存访问模式
cuda执行的显著特征之一是**指令必须以线程束为单位进行发布与执行。存储操作也是同样。**在执行内存指令时,线程束中的每个线程都提供了一个正在加载或存储的内存地址。在线程束的32 个线程中,每个线程都提出了一个包含请求地址的单一内存访问请求,它并由一个或多个设备内存传输提供服务。以下是几种内存访问的模式。
4.3.1 对齐与合并访问
全局内存通过缓存来实现加载/存储。全局内存是一个逻辑内存空间,可通过核函数来访问它。数据最初存在DRAM(物理设备内存上)。核函数的内存请求通常是在DRAM设备和片上内存间以128字节或32 字节内存事务中实现的。
特性:若只通过二级缓存的话,则这个内存访问是由一个32字节的内存事务实现的。若两级缓存都被用到的话,则是128字节。
| 特性 | L1 Cache | L2 Cache |
|---|---|---|
| 位置 | 每个 SM(Streaming Multiprocessor)独立拥有 | 所有 SM 共享的全局缓存 |
| 访问范围 | 仅限当前 SM 中的线程访问 | 所有 SM 都能访问(跨 SM 共享) |
| 容量 | 一般 48 KB ~ 128 KB,可与共享内存共享配置 | 几 MB(如 4MB ~ 40MB,视 GPU 而定) |
| 延迟 | 极低(几十个周期) | 中等(约 200~300 周期) |
| 带宽 | 极高,受 SM 内部总线限制 | 次高,连接所有 SM 的 crossbar |
| 一致性(Coherency) | 各 SM 之间 不保证一致性 | L2 是全局一致的(L2 coherence) |
| 缓存粒度 | 一般按 32B 或 128B 行进行缓存 | 一般按 128B 缓存行 |
| 用途 | 加速局部数据访问、重复访问数据 | 缓冲显存访问、跨 SM 数据共享 |
| 可配置性 | 部分架构可调共享内存:L1 比例(如 64:64 或 32:96) | 不可配置,由硬件固定 |
为啥L2 cache 是32字节呢?为啥用到L1 cache的时候就是128呢?
这与 cache line 大小和 warp 合并机制 有关:
| 层级 | Cache Line | 对应机制 |
|---|---|---|
| L1 Cache | 128 字节 | warp 合并访问时,每 32 线程的访问被合并为 128B 对齐的事务(对齐到 128B 边界) |
| L2 Cache | 32 字节 | L2 内部使用更细粒度(32B line)以减少带宽浪费,提高命中率 |
原因:
- L1 Cache 直接面对 warp 内部访问,128B 对齐能匹配 warp(32 线程 × 4B = 128B)一次性取数;
- L2 Cache 面对多个 SM 的并发请求,为了减少带宽浪费,采用更小的 32B 粒度,提升灵活性;
- 当 L1 被禁用或 bypass 时(例如通过
-Xptxas -dlcm=cg),加载会直接走 L2 → 寄存器,事务大小就变成 32B。
合并内存访问:
理想状态:线程束从对其地址开始访问一个连续的内存块。提高带宽的利用率,否则会造成带宽的浪费。
4.3.2 全局内存的读取
三种方式:
-
一级与二级缓存(默认的方式)
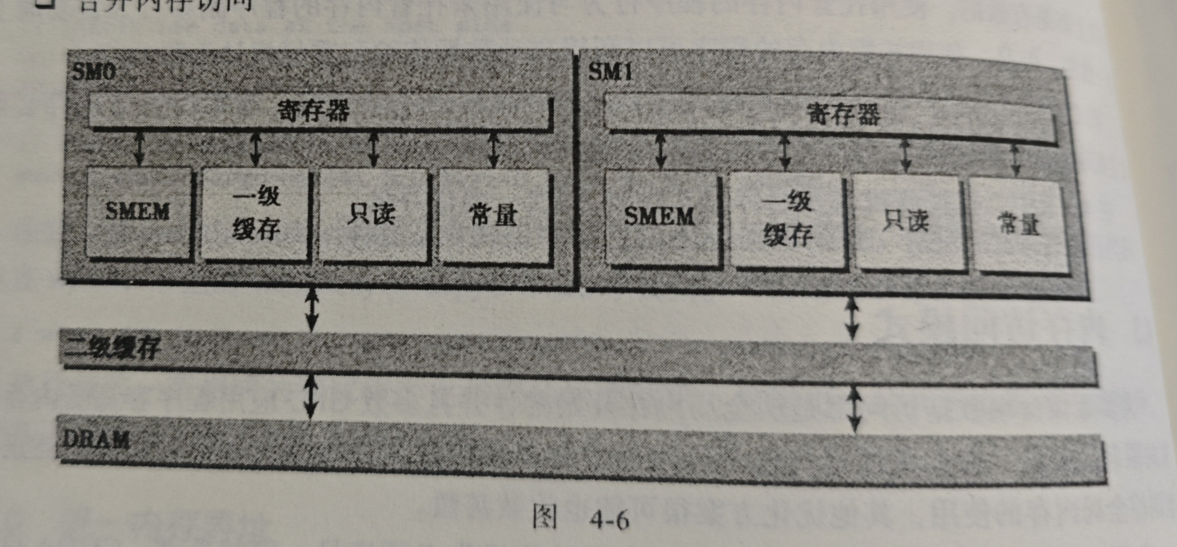
但一级缓存的使用取决于两个条件(设备的计算能力、编译器选项(-Xptxas -dlcm=cg 禁用标志 -Xptxas -dlcm=cg 启用标志)),如果禁用的话,则使用二级缓存,如果二级缓存缺失,则就是DRAM,如上面那张图。
-
常量缓存
-
只读缓存
内存加载访问模式:
-
缓存加载(有一级缓存)
-
非缓存加载(无一级缓存)
访问模式 __ldca(L1+L2)__ldcg(L2 only)__ldg(readonly)连续访问 ✅ 最快 ❌ 稍慢 ✅ 接近 随机访问 ❌ 最慢 ✅ 快 ✅ 快 只读数据 ❌ 容易污染 L1 ✅ 中等 ✅ 最佳
float val1 = __ldca(&data[i]); // L1+L2
float val2 = __ldcg(&data[i]); // 仅L2
float val3 = __ldg(&data[i]); // 只读缓存---------- | ------------------ | ------------------ |
| 连续访问 | ✅ 最快 | ❌ 稍慢 | ✅ 接近 |
| 随机访问 | ❌ 最慢 | ✅ 快 | ✅ 快 |
| 只读数据 | ❌ 容易污染 L1 | ✅ 中等 | ✅ 最佳 |
float val1 = __ldca(&data[i]); // L1+L2
float val2 = __ldcg(&data[i]); // 仅L2
float val3 = __ldg(&data[i]); // 只读缓存上面代码是不同访存模式的方法,其实也可以通过编译器选项(-Xptxas -dlcm=cg 禁用标志 -Xptxas -dlcm=cg 启用标志) 支持。看需求吧。