建立网站一般要多少钱wordpress 预订插件
实现目的:Python读取Excel文件里面指定列(“J”列)中从第3行至第8行的单元格内容。有两种处理方式,第一种方式是先读取Excel文件里面指定列的所有行,然后再去里面寻找需要的指定范围行;第二种方式是一次性直接读取Excel文件里面指定列中的指定范围行;
一、Excel文件
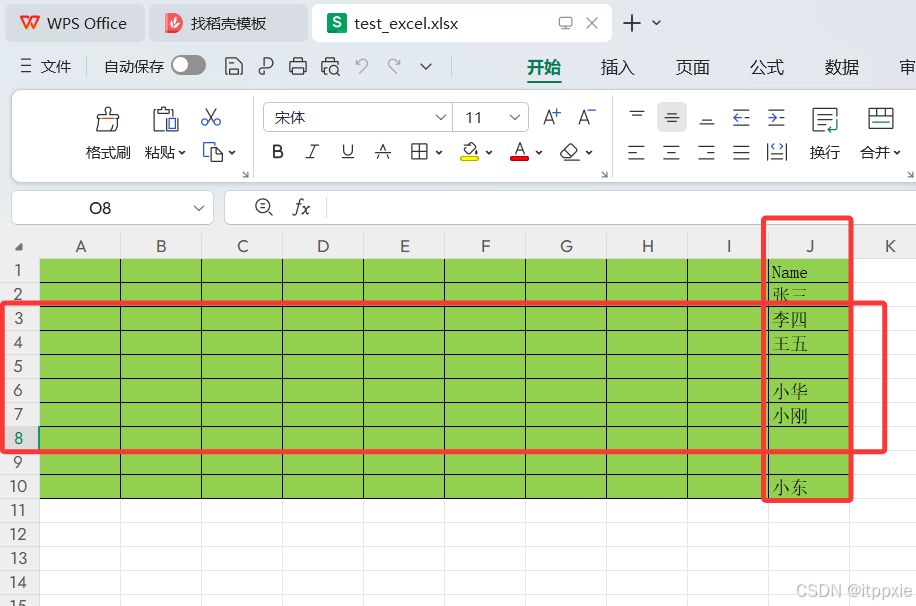
需要读取的excel文件如下:
二、代码实现
1、方式一:
import os
import pandas as pd
import openpyxl########### todo: 将大写英文字母char转换成对应的数字,如'A'转换成1,'C'转换成3
def alphabet2number(char):result = ord(char) - ord('A') + 1 # ord('A')将字母“A”转换成ascii 65return result##########todo:读取Excel文件里面"J"列中从第3行至第8行的单元格内容
def read_excel_column_ppxie(excel_file_path, excel_sheet_name, column_char, start_row, end_row):# todo:从Excel文件中,读取指定的表单sheetexcel_file = pd.read_excel(excel_file_path, excel_sheet_name)print('打印excel_file的数据类型', type(excel_file)) # <class 'pandas.core.frame.DataFrame'>print('打印excel_file:\n', excel_file)print('\n\n')# todo: 获取Excel中指定列的内容,如第'J'列内容num = alphabet2number(column_char) # 获取大写字母的序号,如'A'就是1,'C'就是3column_data = excel_file.iloc[:, num - 1] # 切片,column_data里面存放了"J"列中所有行的单元格内容# 打印print('打印column_data的数据类型(里面存放了“J”列中所有行的单元格数据):', type(column_data)) # <class 'pandas.core.series.Series'>print('打印column_data中的所有单元格数据:\n', column_data) # column_data里面存放了“J”列中所有行的单元格数据print('打印column_data中的单元格个数:', len(column_data)) # 9print('\n\n')# 两种方式遍历Excel里面 该列中的所有单元格内容print('以下是遍历该列的所有单元格内容(索引遍历):')for index in range(0, len(column_data), 1):cell_data = column_data[index]print(cell_data)print('打印column_data中的单元格cell_data数据类型:', type(cell_data), '在原始Excel文件中的行号:', (index + 2))print('\n\n')print('以下是遍历该列的所有单元格内容(直接遍历):')for cell_data in column_data:print(cell_data)print('打印column_data中的单元格cell_data数据类型:', type(cell_data))print('\n\n')# 索引遍历Excel里面“J”列中第3行至第8行的所有单元格内容print('以下是遍历J列中第3行至第8行的所有单元格内容:')for index in range(start_row - 2, (end_row -2) + 1, 1):cell_data = column_data[index]print(cell_data)print('打印column_data中的单元格cell_data数据类型:', type(cell_data), '在原始Excel文件中的行号:', (index + 2))# test
if __name__ == '__main__':excel_file_path = './other_files/test_excel.xlsx'excel_sheet_name = 'Sheet2'column_char = 'J'start_row, end_row = 3, 8 # Excel文件中的开始行和结束行read_excel_column_ppxie(excel_file_path, excel_sheet_name, column_char, start_row, end_row)
输出结果:
打印excel_file的数据类型 <class 'pandas.core.frame.DataFrame'>
打印excel_file:Unnamed: 0 Unnamed: 1 Unnamed: 2 ... Unnamed: 7 Unnamed: 8 Name
0 NaN NaN NaN ... NaN NaN 张三
1 NaN NaN NaN ... NaN NaN 李四
2 NaN NaN NaN ... NaN NaN 王五
3 NaN NaN NaN ... NaN NaN NaN
4 NaN NaN NaN ... NaN NaN 小华
5 NaN NaN NaN ... NaN NaN 小刚
6 NaN NaN NaN ... NaN NaN NaN
7 NaN NaN NaN ... NaN NaN NaN
8 NaN NaN NaN ... NaN NaN 小东[9 rows x 10 columns]打印column_data的数据类型(里面存放了“J”列中所有行的单元格数据): <class 'pandas.core.series.Series'>
打印column_data中的所有单元格数据:0 张三
1 李四
2 王五
3 NaN
4 小华
5 小刚
6 NaN
7 NaN
8 小东
Name: Name, dtype: object
打印column_data中的单元格个数: 9以下是遍历该列的所有单元格内容(索引遍历):
张三
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 2
李四
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 3
王五
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 4
nan
打印column_data中的单元格cell_data数据类型: <class 'float'> 在原始Excel文件中的行号: 5
小华
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 6
小刚
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 7
nan
打印column_data中的单元格cell_data数据类型: <class 'float'> 在原始Excel文件中的行号: 8
nan
打印column_data中的单元格cell_data数据类型: <class 'float'> 在原始Excel文件中的行号: 9
小东
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 10以下是遍历该列的所有单元格内容(直接遍历):
张三
打印column_data中的单元格cell_data数据类型: <class 'str'>
李四
打印column_data中的单元格cell_data数据类型: <class 'str'>
王五
打印column_data中的单元格cell_data数据类型: <class 'str'>
nan
打印column_data中的单元格cell_data数据类型: <class 'float'>
小华
打印column_data中的单元格cell_data数据类型: <class 'str'>
小刚
打印column_data中的单元格cell_data数据类型: <class 'str'>
nan
打印column_data中的单元格cell_data数据类型: <class 'float'>
nan
打印column_data中的单元格cell_data数据类型: <class 'float'>
小东
打印column_data中的单元格cell_data数据类型: <class 'str'>以下是遍历J列中第3行至第8行的所有单元格内容:
李四
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 3
王五
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 4
nan
打印column_data中的单元格cell_data数据类型: <class 'float'> 在原始Excel文件中的行号: 5
小华
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 6
小刚
打印column_data中的单元格cell_data数据类型: <class 'str'> 在原始Excel文件中的行号: 7
nan
打印column_data中的单元格cell_data数据类型: <class 'float'> 在原始Excel文件中的行号: 82、方式二:
import os
import pandas as pd
import openpyxl########### todo: 将大写英文字母char转换成对应的数字,如'A'转换成1,'C'转换成3
def alphabet2number(char):result = ord(char) - ord('A') + 1 # ord('A')将字母“A”转换成ascii 65return result##########todo:读取Excel文件里面"J"列中从第3行至第8行的单元格内容
def read_excel_column_ppxie(excel_file_path, excel_sheet_name, column_char, start_row, end_row):# todo:从Excel文件中,读取指定的表单sheetexcel_file = pd.read_excel(excel_file_path, excel_sheet_name)print('打印excel_file的数据类型', type(excel_file)) # <class 'pandas.core.frame.DataFrame'>print('打印excel_file:\n', excel_file)print('\n\n')# todo: 获取Excel中指定列的内容,如第'J'列内容num = alphabet2number(column_char) # 获取大写字母的序号,如'A'就是1,'C'就是3column_data = excel_file.iloc[(start_row - 2):((end_row - 2) + 1), num - 1] # 切片,column_data直接存放了"J"列中从第3行至第8行的所有单元格内容# 打印print('打印column_data的数据类型(里面存放了“J”列中从第3行至第8行的单元格数据):', type(column_data)) # <class 'pandas.core.series.Series'>print('打印column_data中的所有单元格数据:\n', column_data) # column_data里面存放了“J”列中从第3行至第8行的单元格数据print('打印column_data中的单元格个数:', len(column_data)) # 6print('\n\n')# 直接遍历该列的从第3行至第8行的所有单元格print('以下是遍历该列的从第3行至第8行的所有单元格:')for cell_data in column_data:print(cell_data)print('打印column_data中的单元格cell_data数据类型:', type(cell_data))# print('\n\n')# test
if __name__ == '__main__':excel_file_path = './other_files/test_excel.xlsx'excel_sheet_name = 'Sheet2'column_char = 'J'start_row, end_row = 3, 8 # Excel文件中的开始行和结束行read_excel_column_ppxie(excel_file_path, excel_sheet_name, column_char, start_row, end_row)输出结果:
打印excel_file的数据类型 <class 'pandas.core.frame.DataFrame'>
打印excel_file:Unnamed: 0 Unnamed: 1 Unnamed: 2 ... Unnamed: 7 Unnamed: 8 Name
0 NaN NaN NaN ... NaN NaN 张三
1 NaN NaN NaN ... NaN NaN 李四
2 NaN NaN NaN ... NaN NaN 王五
3 NaN NaN NaN ... NaN NaN NaN
4 NaN NaN NaN ... NaN NaN 小华
5 NaN NaN NaN ... NaN NaN 小刚
6 NaN NaN NaN ... NaN NaN NaN
7 NaN NaN NaN ... NaN NaN NaN
8 NaN NaN NaN ... NaN NaN 小东[9 rows x 10 columns]打印column_data的数据类型(里面存放了“J”列中从第3行至第8行的单元格数据): <class 'pandas.core.series.Series'>
打印column_data中的所有单元格数据:1 李四
2 王五
3 NaN
4 小华
5 小刚
6 NaN
Name: Name, dtype: object
打印column_data中的单元格个数: 6以下是遍历该列的从第3行至第8行的所有单元格:
李四
打印column_data中的单元格cell_data数据类型: <class 'str'>
王五
打印column_data中的单元格cell_data数据类型: <class 'str'>
nan
打印column_data中的单元格cell_data数据类型: <class 'float'>
小华
打印column_data中的单元格cell_data数据类型: <class 'str'>
小刚
打印column_data中的单元格cell_data数据类型: <class 'str'>
nan
打印column_data中的单元格cell_data数据类型: <class 'float'>三、解释
Python读取Excel文件时,“A”列是索引0列、“B”列是索引1列、……、第n列数据是索引(n-1)列,因此“J”列是索引9列;并且,Excel文件中的第1行数据作为单元格名称显示,第2行数据才是索引0行、第3行数据是索引1行、……、第n行数据是索引(n-2)行。如下: