Python爬虫抓取豆瓣TOP250数据
目录
一、开门见山,探究网页结构
二、确定思路
1.拿到页面源代码/响应
2.编写正则,提取页面数据
3.保存数据
三、步骤详解
1.初步爬取
2.绕过反爬
3.编写正则表达式与正则匹配
4.翻页爬取
5.注意点

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
一、开门见山,探究网页结构
在爬取之前我们要确定需要的数据究竟是在页面源代码里,还是不在页面源代码里(是不是一次性全加载进来的),如果页面源代码里没有想要的数据,说明还有其它请求获取的数据。
让我们打开页面:
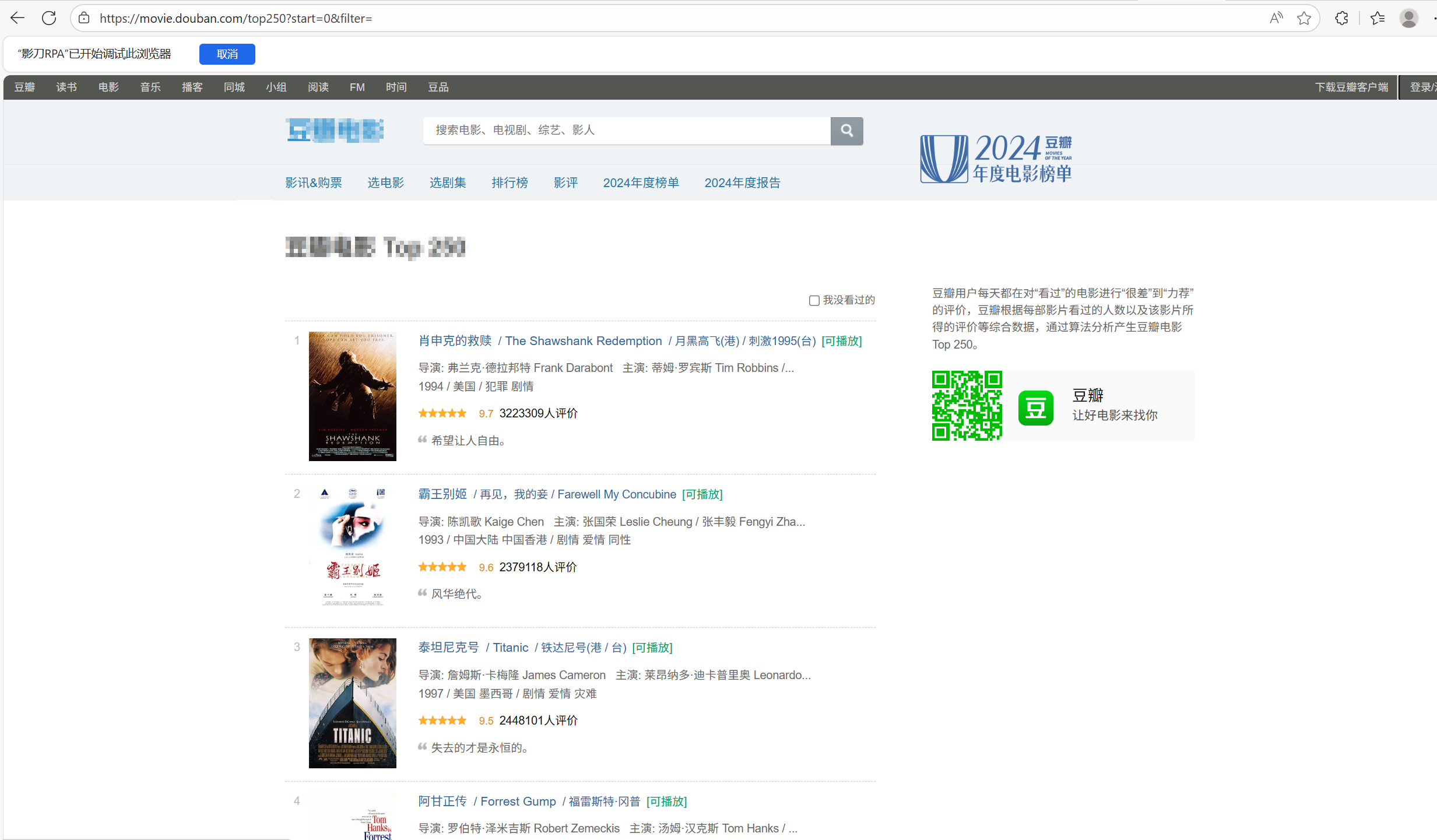
右键查看页面源代码,Ctrl+/页面搜索关键词:肖申克
可以看到这时候我们需要的数据是都在页面源代码里的,验证了我们的想法:该页面数据是一次性全加载进来的,因此得到以下思路。
二、确定思路
1.拿到页面源代码/响应
2.编写正则,提取页面数据
3.保存数据
三、步骤详解
1.初步爬取
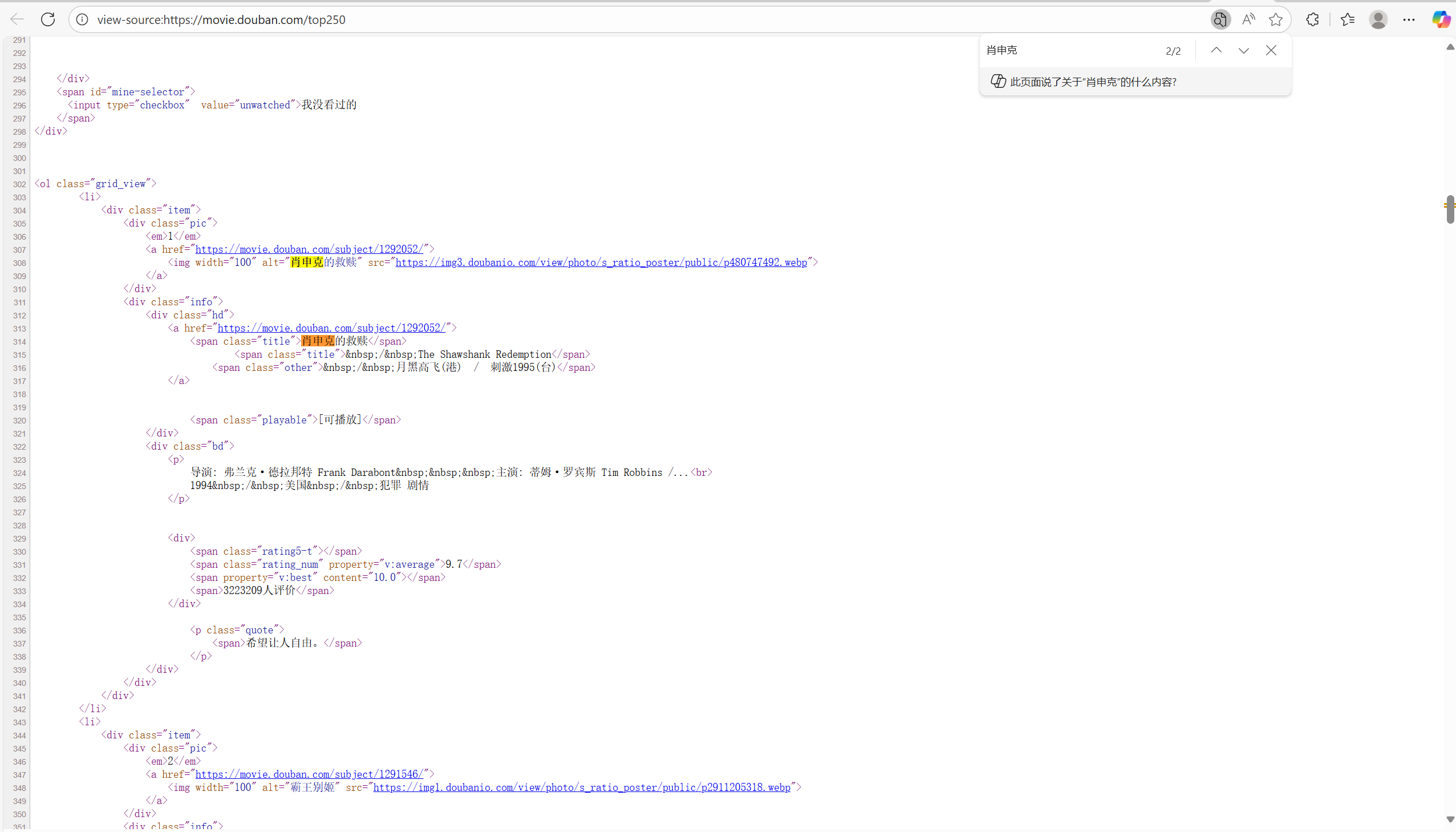
1.1 确定请求方式
接下来按F12,进入开发者工具看看怎么个事儿,发现有个Top250(这个就是第一页的页面url链接,即响应就是页面源代码)
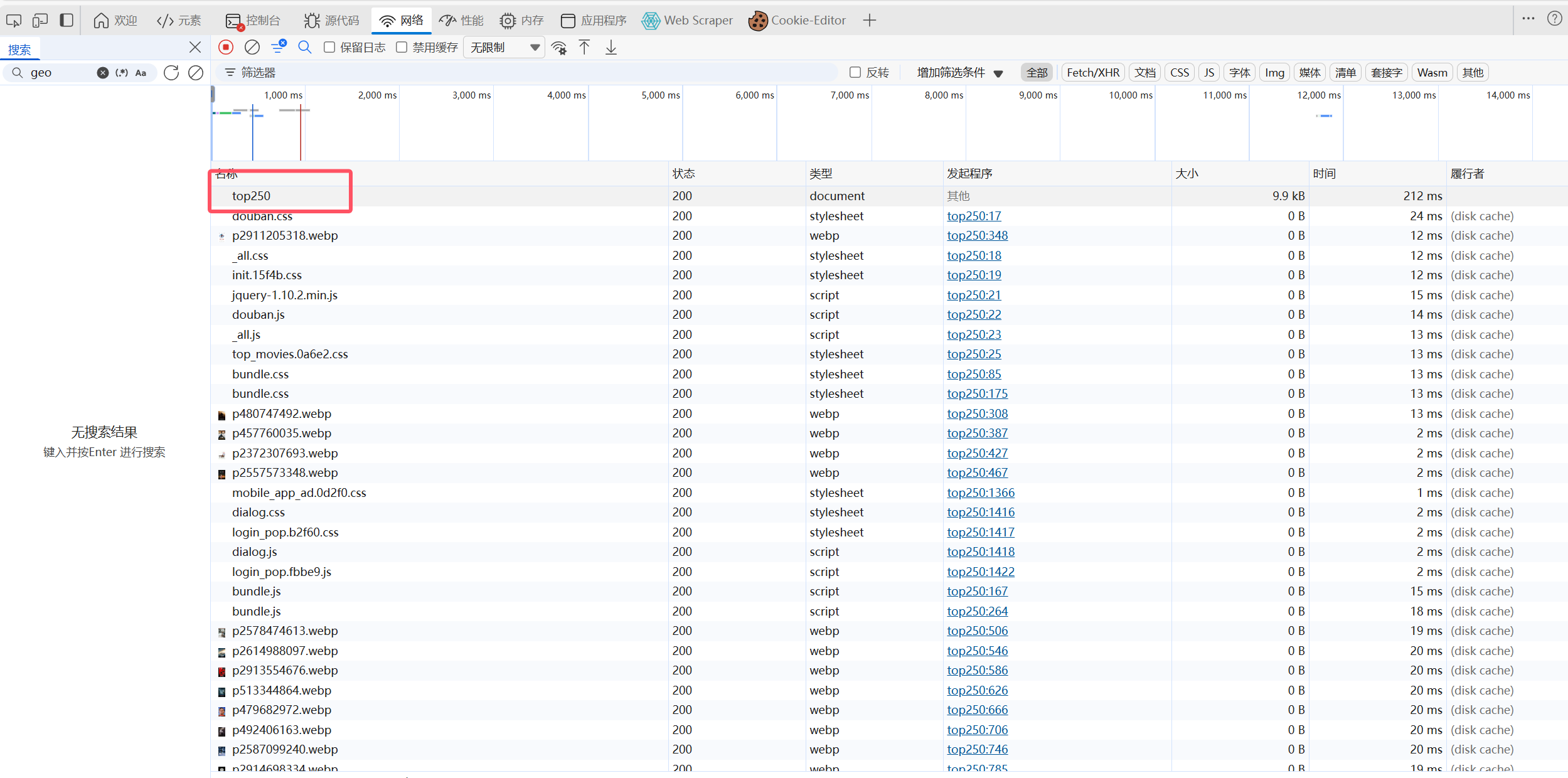
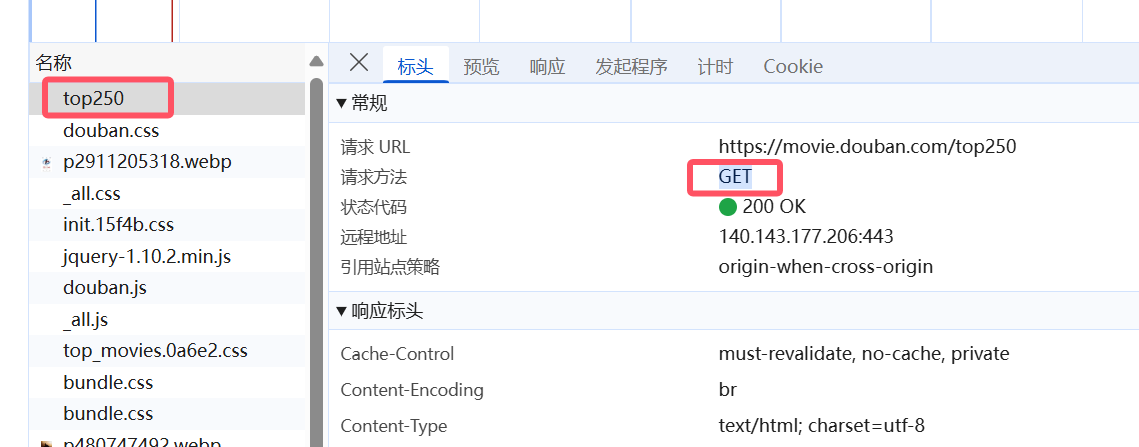
1.2 引入request模块
发现这里的请求是Get,因此引入request模块,导入request.get(页面链接)
import requestsurl="https://movie.douban.com/top250"resp=requests.get(url) #获取对应页面url的请求响应pageSource=resp.text #把页面源代码输出print(pageSource) #打印这时候运行发现结果是空的:
2.绕过反爬
2.1 加入请求头
说明缺少一个反爬的验证,浏览器自动拦截了,这时候需要加一个请求头
import requestsurl="https://movie.douban.com/top250"headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"}
resp=requests.get(url,headers=headers)pageSource=resp.textprint(pageSource)这样就可以了:
3.编写正则表达式与正则匹配
3.1 编写正则表达式
接下来就需要进行数据分离:
引入re模块,编写正则表达式:
首先从标题开始提取,从<div class="item">为开头,目标是第二个框里的文字内容,这时候需要用到惰性匹配:.*?

3.2 对比表格
这里样例的惰性匹配的结果是两个结果的额原因是开启了全局模式
特性 .*(贪婪).*?(非贪婪/懒惰)核心原则 匹配尽可能多的字符 匹配尽可能少的字符 别名 贪婪模式 非贪婪模式、懒惰模式、最小匹配模式 回溯行为 先吃到尾,再往回找 吃一个看一次,满足就停 示例文本 Hello "World" and "Universe"Hello "World" and "Universe"正则 ".*"".*?"匹配结果 一个结果: "World" and "Universe"两个结果: "World"和"Universe"适用场景 匹配大块的、从开始标志到结束标志之间的所有内容 匹配多个、成对标签/引号之间的单个内容
没有
g标志:
引擎在找到第一个匹配项后就停止。
有
g标志:
引擎在找到第一个匹配项后,会从上次匹配结束的位置开始,继续寻找下一个匹配项。
但是这里还有一个坑,那就是.在匹配的时候是跳过所有非换行符的内容
而re.S可以让正则表达式中的.匹配换行符
#编写正则表达式
re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)3.3 进行正则匹配
接下来进行正则匹配:
#进行正则匹配
result=obj.finditer(pageSource)
for item in result:print(item.group("name"))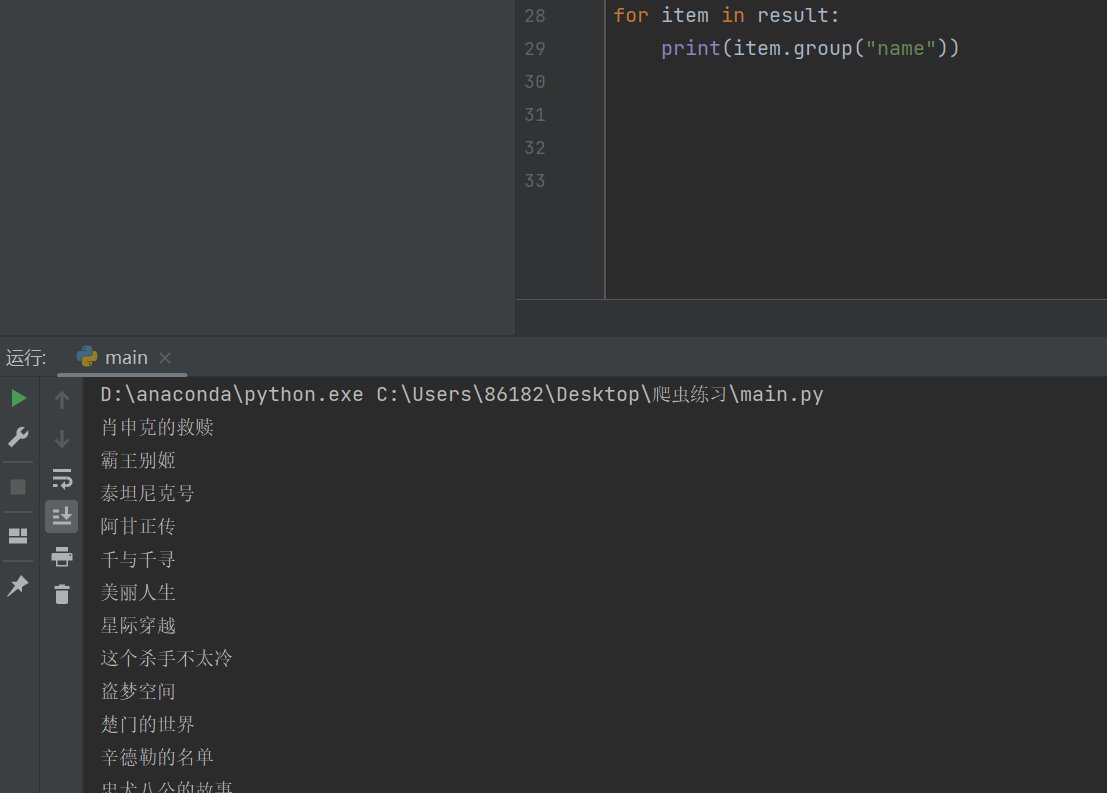
然后根据上面的规则对源代码进行匹配:
#编写正则表达式
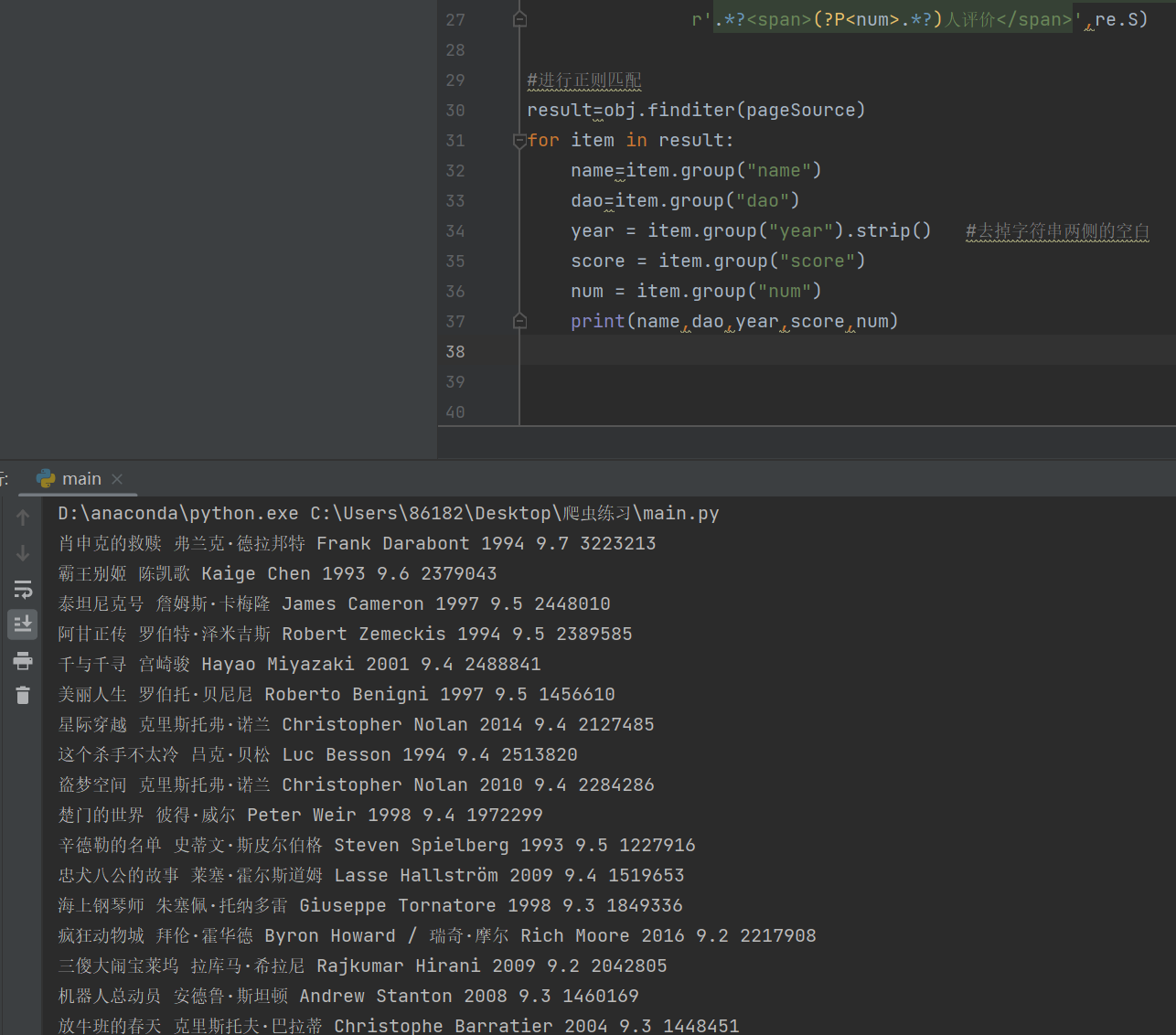
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'r'.*?<p>.*?导演: (?P<dao>.*?) 'r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'r'.*?<span>(?P<num>.*?)人评价</span>',re.S)#进行正则匹配
result=obj.finditer(pageSource)
for item in result:name=item.group("name")dao=item.group("dao")year = item.group("year").strip() #去掉字符串两侧的空白score = item.group("score")num = item.group("num")print(name,dao,year,score,num)得到了结果:
3.4 保存文件
接下来保存为文件:
f=open("top250.csv",mode="w",encoding='utf-8')导出数据:
f.write(f"{name}{dao}{year}{score}{num}\n")
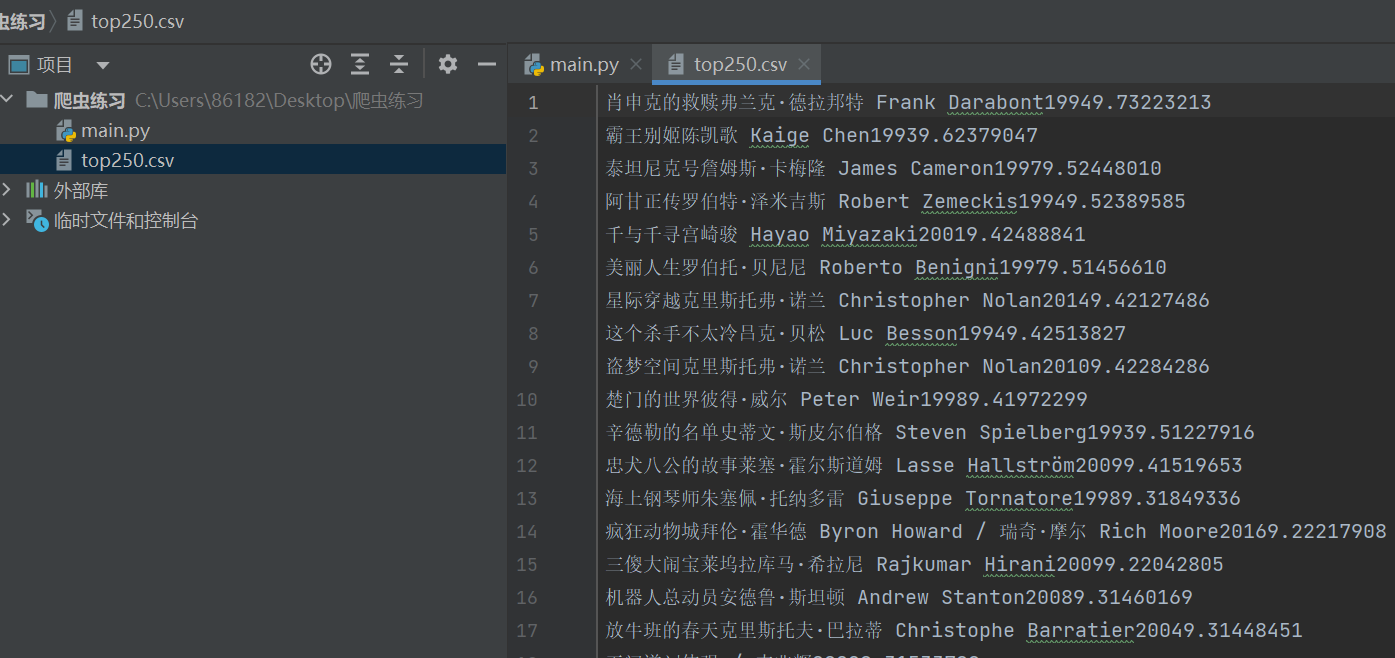
爬取一页的完整代码:
# 思路:
#
# 1.拿到页面源代码
#
# 2.编写正则,提取页面数据
#
# 3.保存数据import requests
import ref=open("top250.csv",mode="w",encoding='utf-8')url="https://movie.douban.com/top250"headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"}
resp=requests.get(url,headers=headers)
resp.encoding="utf-8" #解决乱码问题
pageSource=resp.text#编写正则表达式
obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'r'.*?<p>.*?导演: (?P<dao>.*?) 'r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'r'.*?<span>(?P<num>.*?)人评价</span>',re.S)#进行正则匹配
result=obj.finditer(pageSource)
for item in result:name=item.group("name")dao=item.group("dao")year = item.group("year").strip() #去掉字符串两侧的空白score = item.group("score")num = item.group("num")f.write(f"{name}{dao}{year}{score}{num}\n")print(name,dao,year,score,num)f.close()
resp.close()print("豆瓣Top250提取完毕")
这时候思考,现在的代码只能爬取一页的25条信息,如何爬取全部250条?
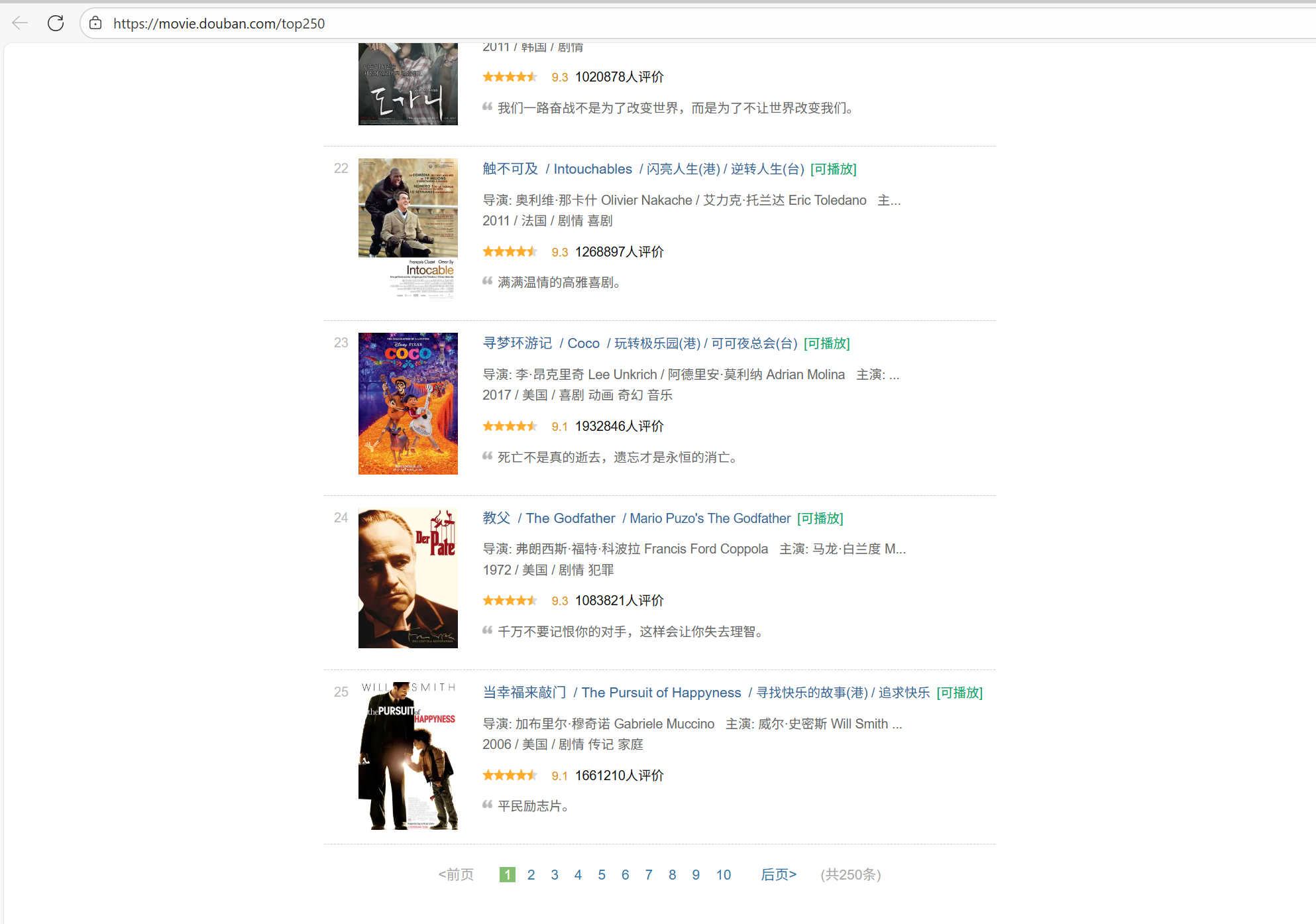
4.翻页爬取
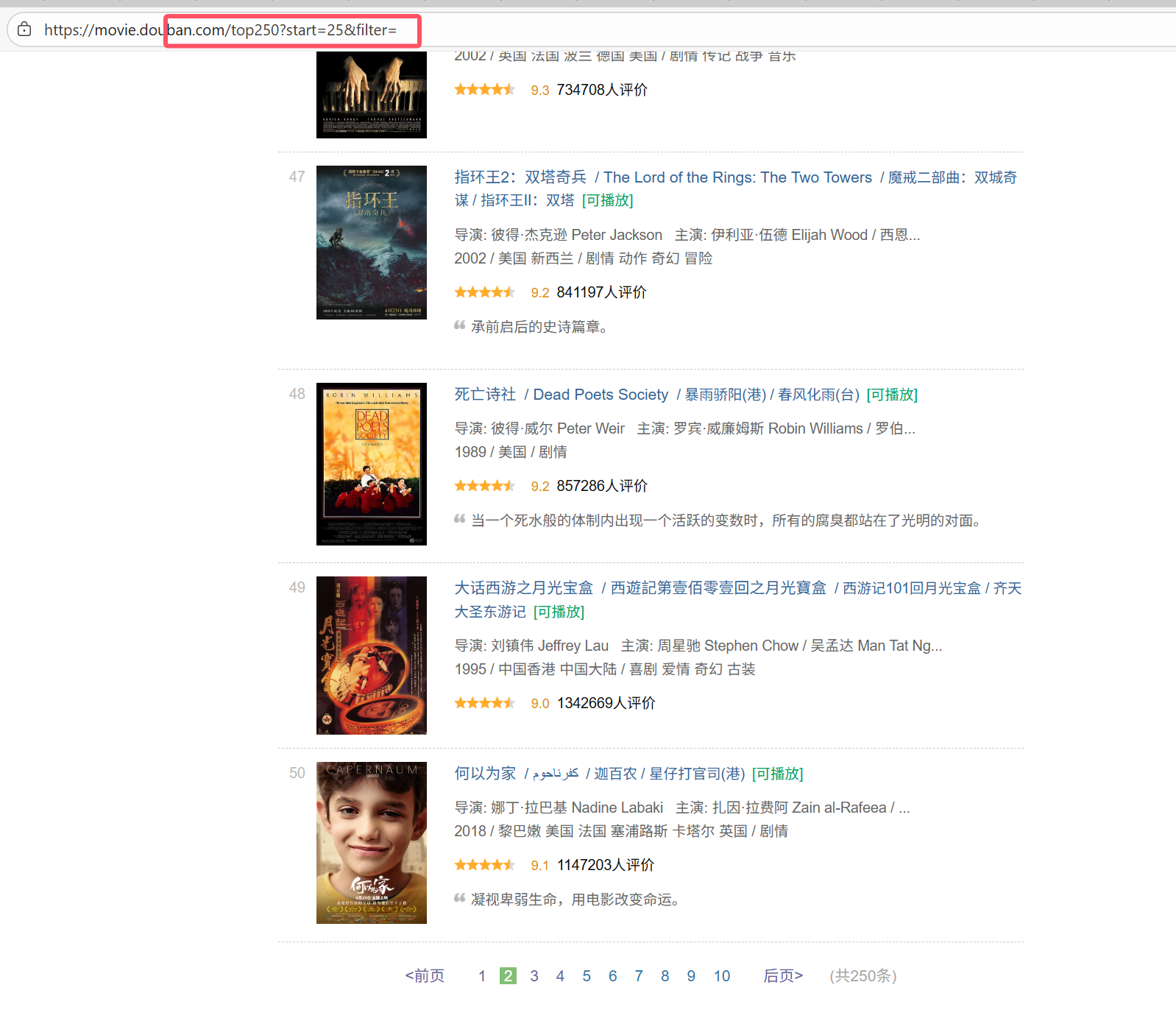
由于发现每跳转一页页面url的start都会增加25,因此得出可以用while循环来爬取全部数据
start=(页数-1)*25
四、完整代码与注意点
1.完整代码
# 思路:
#
# 1.拿到页面源代码
#
# 2.编写正则,提取页面数据
#
# 3.保存数据import requests
import ref=open("top250.csv",mode="w",encoding='utf-8')
#start=(页数-1)*25
page=1while page<=10:url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0"}resp=requests.get(url,headers=headers)resp.encoding="utf-8" #解决乱码问题pageSource=resp.text#编写正则表达式obj=re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<div class="bd">'r'.*?<p>.*?导演: (?P<dao>.*?) 'r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'r'.*?<span>(?P<num>.*?)人评价</span>',re.S)#进行正则匹配result=obj.finditer(pageSource)for item in result:name=item.group("name")dao=item.group("dao")year = item.group("year").strip() #去掉字符串两侧的空白score = item.group("score")num = item.group("num")f.write(f"{name}{dao}{year}{score}{num}\n")print(name,dao,year,score,num)print(f"第{page}页爬取完成")page = page + 1f.close()
resp.close()print("豆瓣Top250提取完毕")2.注意点
解释一下
url=f"https://movie.douban.com/top250?start={(page - 1) * 25}&filter="这里的f必须要加
不加 f 的情况:
url="https://movie.douban.com/top250?start={(page - 1) * 25}&filter="实际URL变成了:
https://movie.douban.com/top250?start={(page - 1) * 25}&filter=注意:{(page - 1) * 25} 被当作普通字符串,而不是要计算的表达式。无论 page 是多少,URL 始终是这个固定的字符串。
豆瓣服务器收到这个请求时,看到 start={(page - 1) * 25},它不知道这是什么,通常会将其视为 start=0 或者忽略这个参数,所以每次都返回第一页的数据。
五、结果展示
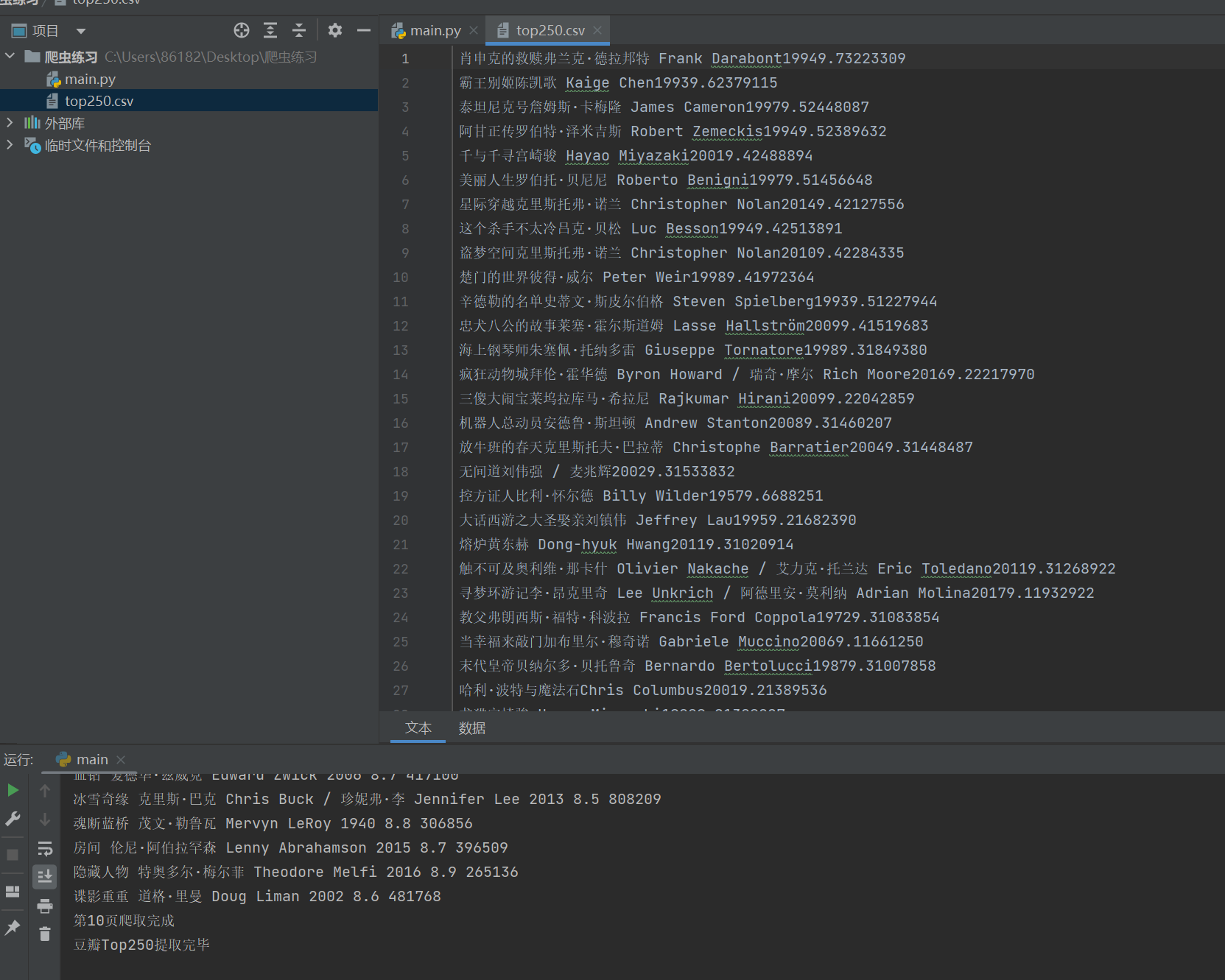
成功爬取250条数据~
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!