AI大事记13:GPT 与 BERT 的范式之争(上)
2018 年,人工智能领域发生了一场意义深远的技术革命。在这一年,两个基于 Transformer 架构的模型相继问世,它们不仅彻底改变了自然语言处理(NLP)的研究范式,更开启了 AI 发展的新纪元。这两个模型就是 OpenAI 在 6 月发布的GPT-1和 Google 在 10 月推出的BERT。虽然它们都采用了 Transformer 架构,但在技术路线上却选择了截然不同的方向:GPT-1 专注于生成任务,而 BERT 则聚焦于理解任务。这场 "范式之争" 不仅展现了两种不同的技术哲学,更共同推动了预训练模型黄金时代的到来。
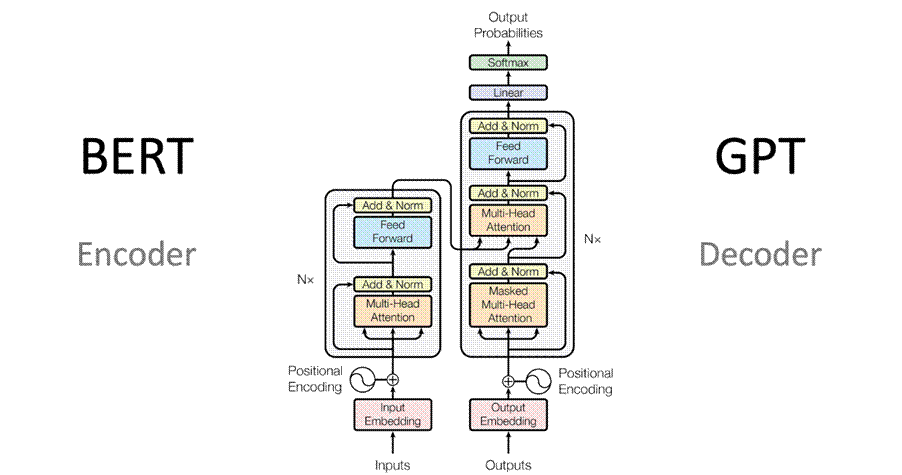
图 1 BERT与GPT
1 GPT-1:开创 "预训练 + 微调" 范式的先行者
1.1 技术架构与创新突破
2018 年 6 月,OpenAI 发布了具有里程碑意义的 GPT-1 模型,全称为Generative Pre-trained Transformer(生成式预训练 Transformer)。

图 2 OpenAI 的 GPT 系列
这是首个基于 Transformer 解码器的生成模型,其技术架构包含 12 层 Transformer 解码器,采用 12 个掩码自注意力头,每个头的维度为 64(总共 768 维)。与传统的循环神经网络(RNN)相比,Transformer 架构具有强大的并行计算能力,能够有效捕捉长距离依赖关系。
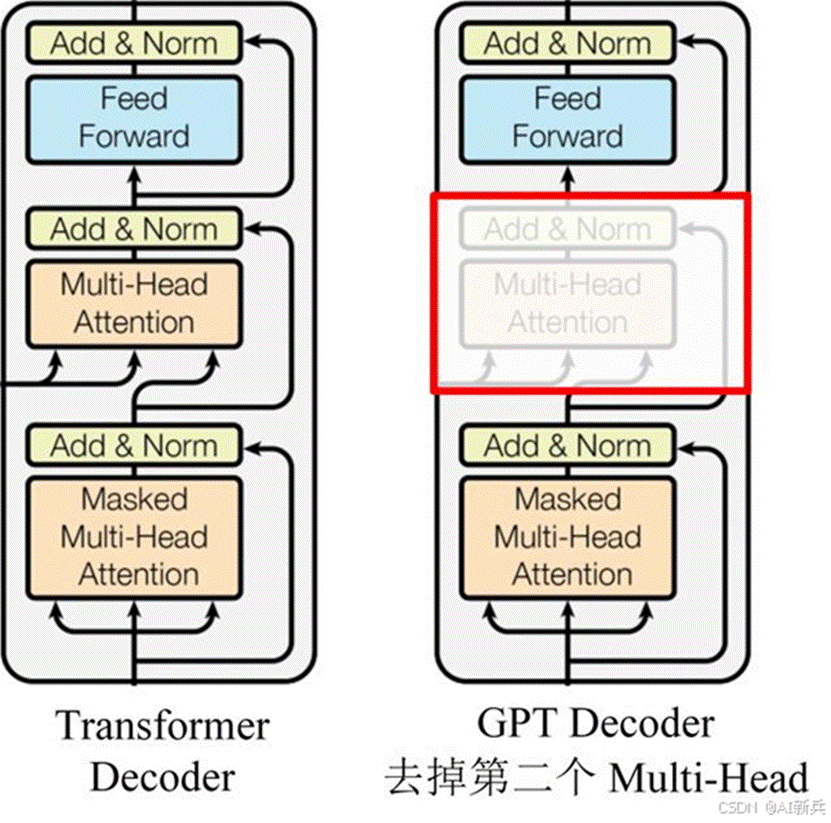
图 3 GPT Decoder架构与Transformer Decoder架构的对比
GPT-1 的参数量达到1.17 亿,在当时是最大的语言模型之一。模型在 BooksCorpus 数据集上进行训练,该数据集包含超过 7000 本未出版的书籍,总数据量达到 40GB。这种大规模无监督预训练的方式,让 GPT-1 能够从海量文本中学习语言的深层规律和语义知识。
在预训练阶段,GPT-1 采用了标准的语言建模任务,即预测下一个单词。具体而言,模型通过自回归的方式,根据前面的单词序列来预测下一个单词的概率分布。这种方法虽然看似简单,但却能够让模型学习到语言的语法结构、语义关系和知识表示。
1.2 "预训练 + 微调" 范式的确立
GPT-1 最具革命性的贡献在于确立了 **"预训练 + 微调"(Pre-training + Fine-tuning)的两阶段训练范式 **。这一范式彻底改变了传统 NLP 任务 "一事一训" 的模式,即每个任务都需要单独设计和训练一个模型。
在微调阶段,GPT-1 通过任务特定的输入转换方法,将不同类型的 NLP 任务(如文本蕴含、语义相似度、问答等)转换为统一的 token 序列格式。例如,对于文本蕴含任务,模型将前提句和假设句拼接为 "[前提;; 假设]"的格式;对于问答任务,则构造"[上下文; 问题; ; 答案]" 的序列。这种统一的输入格式使得同一个预训练模型可以适配各种下游任务。
更重要的是,GPT-1 在微调时保留了语言建模任务作为辅助目标,最终的优化目标是主任务损失和语言建模损失的加权和。这种设计不仅提高了模型的泛化能力,还加快了收敛速度。
1.3 性能表现与技术影响
GPT-1 在多个 NLP 任务上取得了显著的性能提升。在自然语言推理任务中,GPT-1 在 MNLI、SNLI、SciTail 等数据集上超越了当时的最先进方法;在问答和常识推理任务中,在 RACE 和 Story Cloze 上取得了最高准确率,其中 Story Cloze 的准确率提升了 8.9%;在语义相似度任务中,在 STS-B 上比前人提升了 1 个百分点;在文本分类任务中,在 CoLA 任务中的准确率从 35% 提升至 45%。
这些成果证明了通用预训练模型的有效性,通过微调可以在多种任务上取得优异成绩。GPT-1 的成功不仅推动了自然语言处理技术的发展,还引发了全球范围内的研究热潮,为后续的 GPT-2、GPT-3 等大规模模型提供了验证思路和实验基础。
2 BERT:双向编码器的理解革命
2.1 双向编码器架构的创新
如果说 GPT-1 开启了预训练模型的大门,那么 BERT 则彻底推开了这扇门。2018 年 10 月,Google 发布了BERT(Bidirectional Encoder Representations from Transformers),这是一个基于双向 Transformer 编码器的预训练模型。

图 4 BERT(Bidirectional Encoder Representations from Transformers)
与 GPT-1 的单向解码器架构不同,BERT 采用了双向 Transformer 编码器,能够同时捕捉左右上下文信息。这种架构设计的核心思想是:在理解一个词时,应该同时利用其左边和右边的所有上下文信息。BERT 通过自注意力机制实现了真正的 "深度双向",在模型的每一层都充分利用了双向上下文。
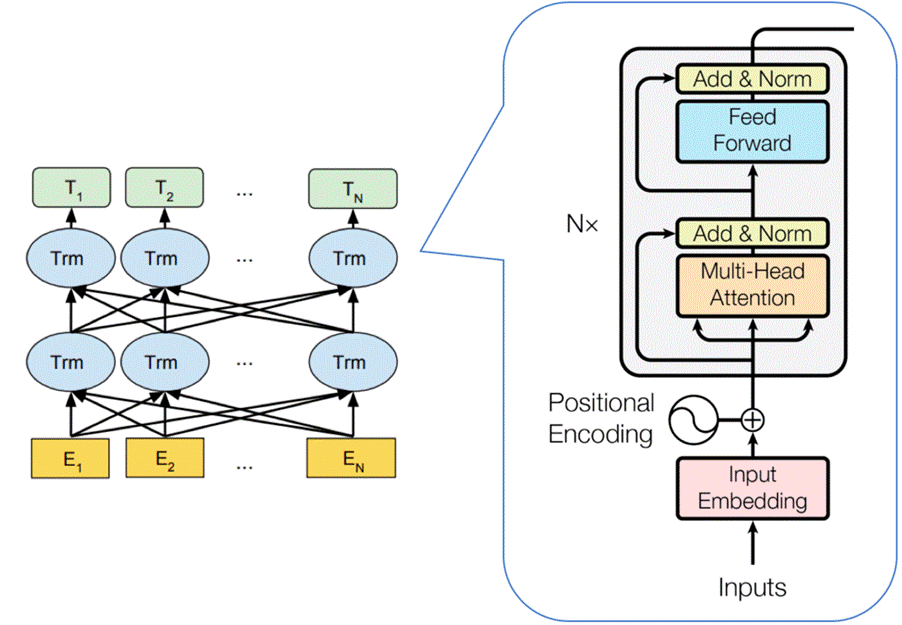
图 5 BERT 采用了双向架构
BERT 的技术架构与 GPT-1 在某些方面非常相似。BERT-Base 的参数设置与 GPT-1 完全相同:L=12 层、H=768 维、A=12 个注意力头。然而,正是因为采用了双向架构,BERT 在相同参数规模下取得了远超 GPT-1 的性能。
2.2 掩码语言模型与下一句预测
BERT 的成功很大程度上归功于其创新的预训练任务设计。与 GPT-1 的单向语言建模不同,BERT 采用了两个独特的预训练任务:掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)。
码语言模型(MLM)是 BERT 最核心的创新。在这个任务中,模型随机掩盖输入序列中 15% 的 tokens,然后预测这些被掩盖的 token 是什么。具体的掩盖策略是:80% 的概率用 [MASK] 标记替换,10% 的概率用随机 token 替换,10% 的概率保持不变。这种设计既让模型学习到上下文信息,又避免了预训练和推理时的不匹配问题。
下一句预测(NSP)任务则训练模型理解句子之间的关系。在这个任务中,BERT 需要预测两个句子是否在逻辑上连续,例如 "我今天去了公园" 和 "天气很好" 是否构成连续的文本。这个任务的准确率达到了 97%-98%,证明了 BERT 能够很好地理解句子间的语义关系。
2.3 11 项 NLP 任务的全面突破
BERT 在 11 项 NLP 任务上取得了突破性的成绩,彻底刷新了当时的基准记录。在 GLUE(通用语言理解评估)基准测试中,BERT 将分数提升至 80.5%,实现了 7.7 个百分点的绝对改进;在 MultiNLI(多体裁自然语言推理)任务中,准确率达到 86.7%,提升了 4.6 个百分点;在 SQuAD v1.1 问答任务中,测试 F1 得分达到 93.2,提升了 1.5 个点,甚至比人类表现还高出 2 分;在 SQuAD v2.0 任务中,测试 F1 得分达到 83.1,提升了 5.1 个点。
更令人惊讶的是,BERT-Base 和 OpenAI GPT 在模型架构上几乎相同,除了注意力掩码的差异。然而,BERT 的性能却全面超越了 GPT-1,这充分证明了双向训练对语言理解任务的重要性。在 GLUE 基准测试中,BERT-Base 的平均分达到 79.6,而 GPT 仅为 75.1;BERT-Large 更是达到了 82.1 的高分。
2.4 微调的高效性与通用性
BERT 在微调方面展现出了极高的效率。所有结果都可以在单个 Cloud TPU 上最多 1 小时内复现,或在 GPU 上几小时内完成。这种高效性使得研究人员能够快速验证不同的任务和参数设置。
在微调策略上,BERT 采用了简单而有效的方法:为每个任务插入特定的输入和输出,然后端到端地微调所有参数。在输入方面,句子 A 和句子 B 在预训练中类似于:(1)释义任务中的句子对;(2)蕴含任务中的假设 - 前提对;(3)问答任务中的问题 - 段落对;(4)文本分类或序列标注中的文本 - 空对。在输出方面,token 表示被输入到输出层用于 token 级任务,而 [CLS] 表示被输入到输出层用于分类任务。