Prometheus 监控系统详解
Prometheus 监控系统详解:从原理到实战
前言
在云原生与微服务快速发展的背景下,一套高效、灵活的监控系统成为保障业务稳定运行的核心基础设施。Prometheus 作为开源监控领域的标杆,凭借其多维数据模型、时序数据高效存储及丰富的生态组件,已成为容器化环境与分布式系统监控的首选方案。本文将从核心原理、生态组件、部署实战到高级配置,全面解析 Prometheus 监控系统。
一、Prometheus 核心原理
1.1 什么是 Prometheus?
Prometheus 是一款开源的时序数据库与服务监控系统,由 SoundCloud 于 2012 年开发,2016 年加入 CNCF(云原生计算基金会),目前已成为云原生监控的事实标准。
其核心能力包括:
- 基于 HTTP 的 pull 模式采集时序数据
- 灵活的多维数据模型(指标名 + 键值对标签)
- 强大的查询语言 PromQL
- 内置时序数据库(TSDB)
- 动态服务发现与静态配置结合
- 原生支持告警与可视化集成
1.2 时序数据与 TSDB
监控数据的核心是时序数据(Time Series Data)—— 按时间顺序记录的系统/服务状态变化(如 CPU 使用率、接口响应时间)。Prometheus 内置的 TSDB(时序数据库)专为监控场景设计,具备以下特性:
| 特性 | 说明 |
|---|---|
| 高写入性能 | 每秒可处理百万级样本写入,适配监控高频采集场景 |
| 顺序写入为主 | 数据按时间递增写入,避免随机 IO 损耗 |
| 按时间块存储 | 数据按时间分片(默认 2 小时/块),便于批量删除 |
| 自动过期清理 | 支持数据保留周期配置(默认 15 天) |
| 压缩存储 | 对重复标签、时序数据进行特殊压缩,节省磁盘空间 |
1.3 核心工作流程
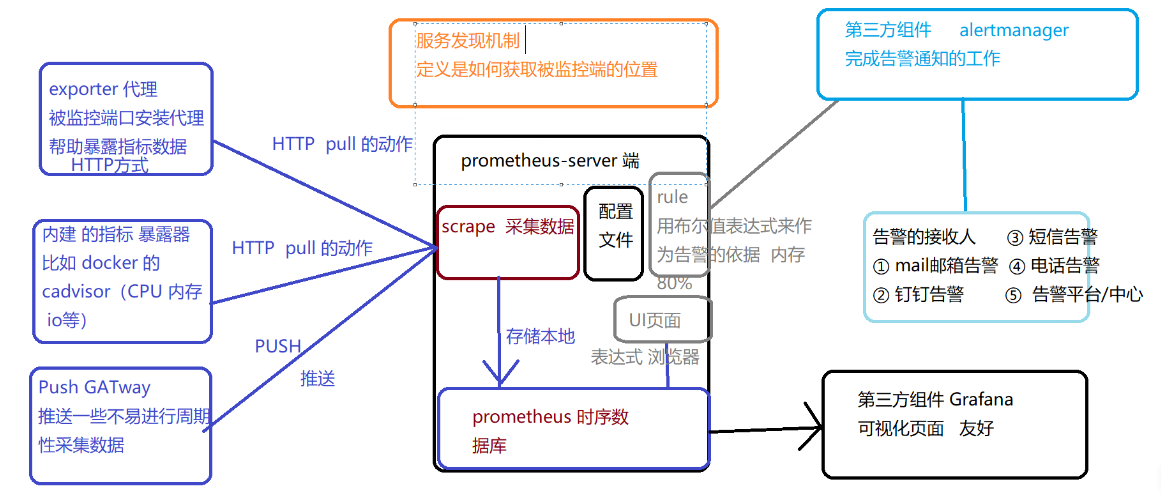
-
数据采集:Prometheus Server 通过静态配置或服务发现识别监控目标(Target),定期从目标的 Exporter 接口(默认
/metrics)拉取(pull)数据;短期任务通过 Pushgateway 推送数据,再由 Server 拉取。 -
数据存储:采集的时序数据存储到内置 TSDB,按时间序列(Metric + Labels)索引。
-
数据查询:通过 PromQL 对存储的时序数据进行过滤、聚合、计算(如计算 5 分钟内的 CPU 平均使用率)。
-
告警触发:Prometheus Server 定期评估告警规则,当指标满足告警条件时,发送告警到 Alertmanager。
-
告警处理:Alertmanager 对告警进行去重、分组、路由,最终发送到邮件、钉钉等接收端。
-
可视化展示:通过 Grafana 对接 Prometheus 数据源,以图表形式展示监控数据。
二、Prometheus 生态组件
Prometheus 核心仅负责数据采集与存储,完整的监控体系需结合以下生态组件:
| 组件 | 作用 | 核心功能 |
|---|---|---|
| Prometheus Server | 核心组件 | 数据采集、存储、PromQL 查询、告警规则评估 |
| Exporters | 指标暴露工具 | 收集第三方服务(如 MySQL、Nginx)指标,转换为 Prometheus 格式并通过 HTTP 暴露 |
| Alertmanager | 告警管理工具 | 告警去重、分组、路由、抑制,支持多渠道通知 |
| Pushgateway | 数据推送中转站 | 接收短期任务的推送数据,供 Prometheus 拉取 |
| Client Libraries | 应用埋点库 | 为开发语言(Go、Java 等)提供原生指标采集接口 |
| Grafana | 可视化平台 | 对接 Prometheus 数据源,生成仪表盘与图表 |
| Service Discovery | 服务发现机制 | 动态识别监控目标(支持 Kubernetes、Consul 等) |
2.1 常用 Exporters 介绍
Exporters 是连接 Prometheus 与被监控对象的桥梁,常见类型:
- Node Exporter:监控服务器硬件与系统指标(CPU、内存、磁盘、网络等),是基础设施监控的必备组件。
- mysqld_exporter:采集 MySQL 数据库指标(连接数、查询效率、锁状态等)。
- nginx-vts-exporter:基于 Nginx 的 vts 模块,采集 Nginx 流量、请求量、响应时间等。
- kube-state-metrics:监控 Kubernetes 资源对象(Pod、Deployment 等)的状态指标(副本数、重启次数等)。
- cAdvisor:监控容器资源使用(CPU、内存、磁盘 IO 等),常与 Kubernetes 集成。
- blackbox_exporter:监控网络端点可用性(HTTP 状态码、ICMP 连通性、TCP 端口存活等)。
三、Prometheus 部署实战
3.1 环境准备
- 操作系统:CentOS 7.x(或 Ubuntu 20.04+)
- 依赖:
wget、tar、systemd(用于服务管理) - 关闭防火墙或开放必要端口(Prometheus 9090、Node Exporter 9100 等)
# 关闭防火墙与 SELinux(测试环境,生产环境建议配置规则)
systemctl stop firewalld && systemctl disable firewalld
setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
3.2 Prometheus Server 部署
步骤 1:下载并安装
# 下载安装包(版本可替换为最新稳定版)
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz# 解压并移动到安装目录
tar xf prometheus-2.45.0.linux-amd64.tar.gz
mv prometheus-2.45.0.linux-amd64 /usr/local/prometheus# 创建数据目录(必须手动创建,否则启动失败)
mkdir -p /usr/local/prometheus/data
步骤 2:配置文件解析(prometheus.yml)
核心配置文件结构:
global: # 全局配置scrape_interval: 15s # 采集间隔(默认 15 秒)evaluation_interval: 15s # 告警规则评估间隔scrape_timeout: 10s # 采集超时时间alerting: # Alertmanager 配置alertmanagers:- static_configs:- targets: ["192.168.10.80:9093"] # Alertmanager 地址rule_files: # 告警规则文件路径- "rules/*.yml" # 规则文件存放目录scrape_configs: # 采集目标配置- job_name: "prometheus" # 任务名称(会作为标签添加到指标)static_configs:- targets: ["localhost:9090"] # 监控自身
步骤 3:配置系统服务
cat > /usr/lib/systemd/system/prometheus.service <<'EOF'
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io
After=network.target[Service]
Type=simple
# 启动参数:配置文件路径、数据存储路径、保留周期、启用配置热重载
ExecStart=/usr/local/prometheus/prometheus \--config.file=/usr/local/prometheus/prometheus.yml \--storage.tsdb.path=/usr/local/prometheus/data/ \--storage.tsdb.retention=30d \ # 数据保留 30 天(默认 15 天)--web.enable-lifecycle # 启用配置热重载(通过 HTTP POST 触发)
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
User=root # 生产环境建议使用专用用户(如 prometheus)[Install]
WantedBy=multi-user.target
EOF
步骤 4:启动并验证
# 启动服务
systemctl daemon-reload
systemctl start prometheus && systemctl enable prometheus# 验证端口(默认 9090)
netstat -natp | grep :9090 # 输出包含 prometheus 进程即正常# 访问 Web UI
浏览器访问 http://<服务器IP>:9090,通过 Status -> Targets 查看监控目标状态(UP 表示正常)。
3.3 常用 Exporters 部署
3.3.1 Node Exporter(监控服务器)
# 下载安装
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar xf node_exporter-1.6.1.linux-amd64.tar.gz
mv node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin/# 配置系统服务
cat > /usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=Node Exporter
After=network.target[Service]
Type=simple
# 启用常用采集器(NTP、系统服务、TCP 连接等)
ExecStart=/usr/local/bin/node_exporter \--collector.ntp \--collector.systemd \--collector.tcpstat \--collector.mountstats
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF# 启动并验证
systemctl start node_exporter && systemctl enable node_exporter
netstat -natp | grep :9100 # 默认端口 9100
接入 Prometheus:在 prometheus.yml 的 scrape_configs 中添加:
- job_name: "nodes"static_configs:- targets:- "192.168.10.80:9100" # 服务器1- "192.168.10.81:9100" # 服务器2labels:env: "production" # 自定义标签(用于区分环境)
执行 curl -X POST http://localhost:9090/-/reload 热重载配置。
3.3.2 mysqld_exporter(监控 MySQL)
# 下载安装
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.15.0/mysqld_exporter-0.15.0.linux-amd64.tar.gz
tar xf mysqld_exporter-0.15.0.linux-amd64.tar.gz
mv mysqld_exporter-0.15.0.linux-amd64/mysqld_exporter /usr/local/bin/# 配置 MySQL 权限(创建专用用户)
mysql -uroot -p
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost' IDENTIFIED BY 'Exporter@123';
FLUSH PRIVILEGES;
EXIT;# 创建 exporter 配置文件(避免污染 MySQL 主配置)
cat > /etc/mysqld_exporter.cnf <<'EOF'
[client]
host=localhost
user=exporter
password=Exporter@123
EOF# 配置系统服务
cat > /usr/lib/systemd/system/mysqld_exporter.service <<'EOF'
[Unit]
Description=MySQL Exporter
After=mysqld.service[Service]
Type=simple
ExecStart=/usr/local/bin/mysqld_exporter --config.my-cnf=/etc/mysqld_exporter.cnf
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF# 启动并验证
systemctl start mysqld_exporter && systemctl enable mysqld_exporter
netstat -natp | grep :9104 # 默认端口 9104
接入 Prometheus:在 prometheus.yml 中添加:
- job_name: "mysql"static_configs:- targets: ["192.168.10.80:9104"] # MySQL 服务器地址
3.4 Grafana 部署与可视化
Grafana 是开源可视化平台,支持通过仪表盘展示 Prometheus 数据。
步骤 1:安装 Grafana
# 配置 Grafana 源(CentOS)
cat > /etc/yum.repos.d/grafana.repo <<'EOF'
[grafana]
name=grafana
baseurl=https://mirrors.aliyun.com/grafana/yum/rpm/
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF# 安装并启动
yum install -y grafana
systemctl start grafana-server && systemctl enable grafana-server
netstat -natp | grep :3000 # 默认端口 3000
步骤 2:配置 Prometheus 数据源
- 浏览器访问
http://<IP>:3000,默认账号密码admin/admin(首次登录需修改)。 - 点击 Configuration → Data Sources → Add data source,选择 Prometheus。
- 在
HTTP → URL中输入http://<Prometheus IP>:9090,点击 Save & Test(显示“Data source is working”即成功)。
步骤 3:导入仪表盘
Grafana 社区提供大量现成仪表盘,可直接导入:
- 访问 Grafana 仪表盘市场,搜索所需仪表盘(如 Node Exporter 对应 ID:
1860,MySQL 对应 ID:7362)。 - 在 Grafana 中点击 + → Import,输入仪表盘 ID,选择 Prometheus 数据源,点击 Load 完成导入。
3.5 Alertmanager 部署与告警配置
Alertmanager 负责处理 Prometheus 发送的告警,支持多渠道通知。
步骤 1:安装 Alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.25.0/alertmanager-0.25.0.linux-amd64.tar.gz
tar xf alertmanager-0.25.0.linux-amd64.tar.gz
mv alertmanager-0.25.0.linux-amd64 /usr/local/alertmanager# 配置系统服务
cat > /usr/lib/systemd/system/alertmanager.service <<'EOF'
[Unit]
Description=Alertmanager
After=network.target[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager \--config.file=/usr/local/alertmanager/alertmanager.yml \--storage.path=/usr/local/alertmanager/data
Restart=on-failure[Install]
WantedBy=multi-user.target
EOFsystemctl start alertmanager && systemctl enable alertmanager
步骤 2:配置告警规则(Prometheus 端)
在 Prometheus 目录创建规则文件 rules/node_rules.yml:
groups:
- name: node-alertsrules:- alert: HighCPUUsage # 告警名称expr: 100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80 # CPU 使用率 > 80%for: 2m # 持续 2 分钟触发labels:severity: "critical" # 告警级别annotations:summary: "高 CPU 使用率告警"description: "实例 {{ $labels.instance }} CPU 使用率超过 80%,当前值:{{ $value | humanizePercentage }}"
在 prometheus.yml 中引用规则文件:
rule_files:- "rules/*.yml"
步骤 3:配置 Alertmanager 路由(对接钉钉)
修改 alertmanager.yml:
global:resolve_timeout: 5mroute:group_by: ['alertname'] # 按告警名称分组group_wait: 10s # 组内等待时间group_interval: 10s # 组间间隔时间repeat_interval: 1h # 重复告警间隔receiver: 'dingtalk' # 默认接收者receivers:
- name: 'dingtalk'webhook_configs:- url: 'http://<钉钉机器人Webhook地址>' # 需提前创建钉钉机器人send_resolved: true # 发送告警恢复通知
四、PromQL 入门与实战
PromQL 是 Prometheus 的查询语言,用于从时序数据中提取信息,支持过滤、聚合、时间范围查询等。
4.1 基本语法
- 指标名 + 标签过滤:
node_cpu_seconds_total{mode="idle"}(筛选 idle 模式的 CPU 时间) - 时间范围:
node_memory_MemFree_bytes[5m](过去 5 分钟的内存空闲量) - 聚合函数:
sum(node_cpu_seconds_total) by (instance)(按实例汇总 CPU 时间)
4.2 常用查询示例
-
CPU 使用率:
100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) -
内存使用率:
(1 - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes) * 100 -
磁盘使用率:
100 - (node_filesystem_free_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100) -
MySQL 连接数:
mysql_connections
五、服务发现配置
在动态环境(如 Kubernetes、容器集群)中,静态配置监控目标难以维护,需通过服务发现动态管理。
5.1 基于文件的服务发现
通过 YAML/JSON 文件定义监控目标,Prometheus 定期读取文件更新目标列表:
# 创建目标配置目录
mkdir /usr/local/prometheus/targets# 定义节点目标(targets/nodes.yaml)
cat > /usr/local/prometheus/targets/nodes.yaml <<'EOF'
- targets:- "192.168.10.80:9100"- "192.168.10.81:9100"labels:env: "prod"
EOF# 在 prometheus.yml 中配置
scrape_configs:- job_name: "nodes-file-sd"file_sd_configs:- files: ["targets/nodes.yaml"]refresh_interval: 1m # 1 分钟刷新一次
5.2 基于 Kubernetes 的服务发现
在 Kubernetes 集群中,Prometheus 可通过 API Server 动态发现 Pod、Node 等资源:
scrape_configs:- job_name: "k8s-pods"kubernetes_sd_configs:- api_server: "https://kubernetes.default.svc" # 集群内 API 地址role: pod # 发现 Pod 资源relabel_configs: # 过滤需监控的 Pod(通过标签筛选)- source_labels: [__meta_kubernetes_pod_label_app]action: keepregex: "api-service" # 仅保留 app=api-service 的 Pod
六、Prometheus 局限性与扩展方案
6.1 局限性
- 本地存储有限:默认仅保留 15 天数据,不适合长期存储。
- 原生高可用弱:单节点部署存在单点故障风险。
- 不适合日志/事件存储:专注于指标监控,不适合存储非时序数据。
6.2 扩展方案
- 长期存储:对接远端存储(如 Thanos、Cortex、InfluxDB)。
- 高可用:通过 Thanos 实现 Prometheus 集群化,支持数据分片与联邦查询。
- 多集群监控:使用 Prometheus Federation(联邦)实现跨集群数据聚合。
总结
Prometheus 凭借灵活的架构与丰富的生态,已成为云原生监控的核心工具。通过本文的部署实战与原理解析,可快速搭建从服务器、数据库到应用服务的全链路监控体系。在实际应用中,需结合业务场景优化采集频率、告警阈值,并通过 Thanos 等工具扩展其能力,以满足大规模、长期监控的需求。
如需进一步深入,建议参考官方文档与社区实践,持续优化监控策略。