未来做啥网站致富安阳网站公司
一、回顾:
- 对深度学习框架Python2.0进行自然语言处理有了一个基础性的认识
- 注意力模型编码器(encoder_layer,用于分类的全连接层dense_layer),抛弃了传统的循环神经网络和卷积神经网络,通过注意力模型将任意位置的两个单词的距离转换成1
- 编码器层和全连接层分开,利用训练好的模型作为编码器独立使用,并且根据具体项目接上不同的尾端,以便在运训练好的编码器上通过微调进行训
二、BERT简介:
Bidirectional Encoder Representation From transformer,替代了 word embedding 的新型文字编码方案,BERT 实际有多个encoder block叠加而成,通过使用注意力模型的多个层次来获得文本的特征提取
三、基本架构与应用
1.MLM:随机从输入语料中这闭掉一些单词,然后通过上下文预测该单词
2.NSP:判断句子B是否句子A的上下文
四、使用HUGGING FACE获取BERT与训练模型
1.安装
pip install transformers2.引用
import torch
from transformers import BertTokenizer
from transformers import BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
pretrain_model = BertModel.from_pretrained("bert-base-chinese")3. 运用代码_获取对应文本的TOKEN
3.1('bert-base-chinese'模型)
import torch
from transformers import BertTokenizer
from transformers import BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
pretrain_model = BertModel.from_pretrained("bert-base-chinese")tokens = tokenizer.encode("床前明月光",max_length=12,padding="max_length",truncation=True)
print(tokens)
print("----------------------")
print(tokenizer("床前明月光",max_length=12,padding="max_length",truncation=True))
print("----------------------")
tokens = torch.tensor([tokens]).int()
print(pretrain_model(tokens))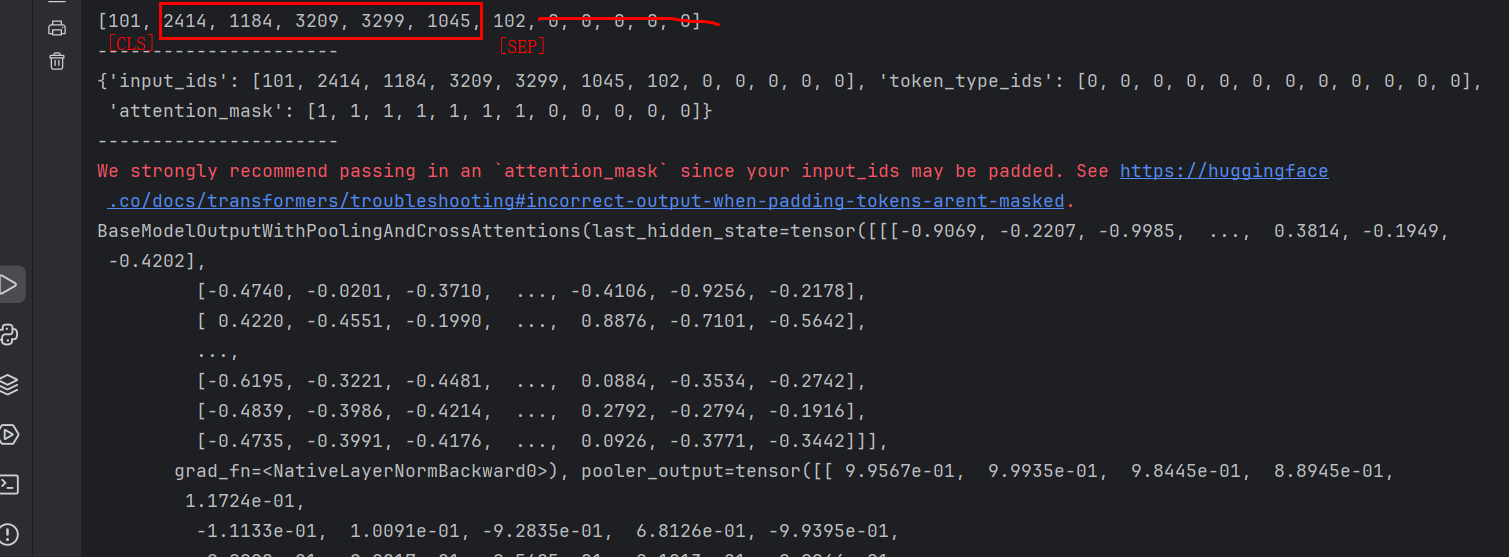
3.2("uer/gpt2-chinese-ancient"模型)
import torch
from transformers import BertTokenizer,GPT2Model
model_name = "uer/gpt2-chinese-ancient"
tokenizer = BertTokenizer.from_pretrained(model_name)
pretrain_model = GPT2Model.from_pretrained(model_name)tokens = tokenizer.encode("春眠不觉晓",max_length=12,padding="max_length",truncation=True)
print(tokens)
print("----------------------")
print(tokenizer("春眠不觉晓",max_length=12,padding="max_length",truncation=True))
print("----------------------")tokens = torch.tensor([tokens]).int()
print(pretrain_model(tokens))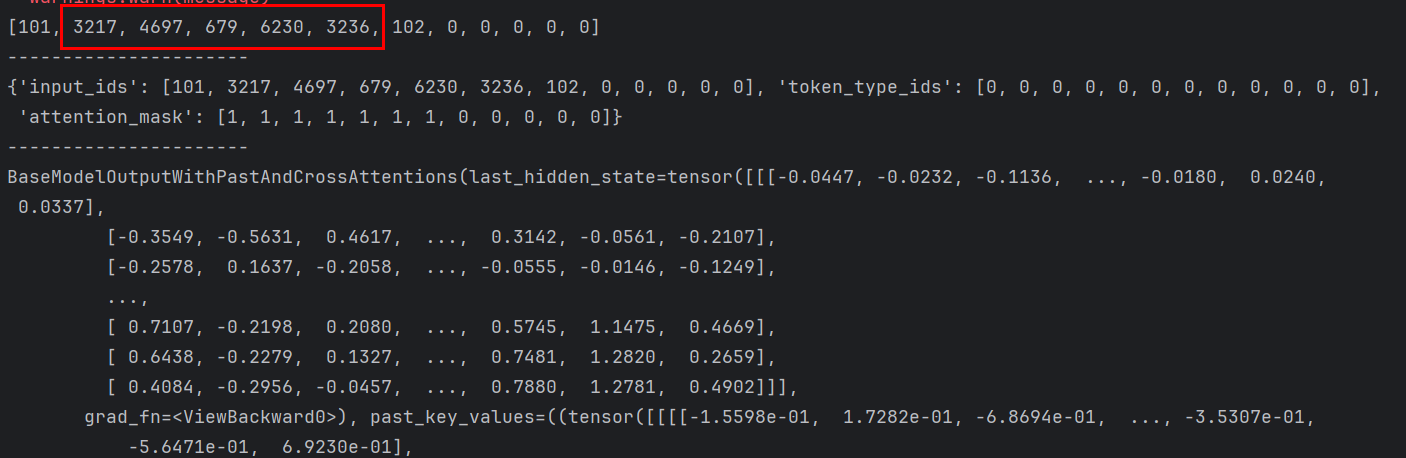
4.进行文本分类
数据准备>数据处理>模型设计>模型训练
get_data:
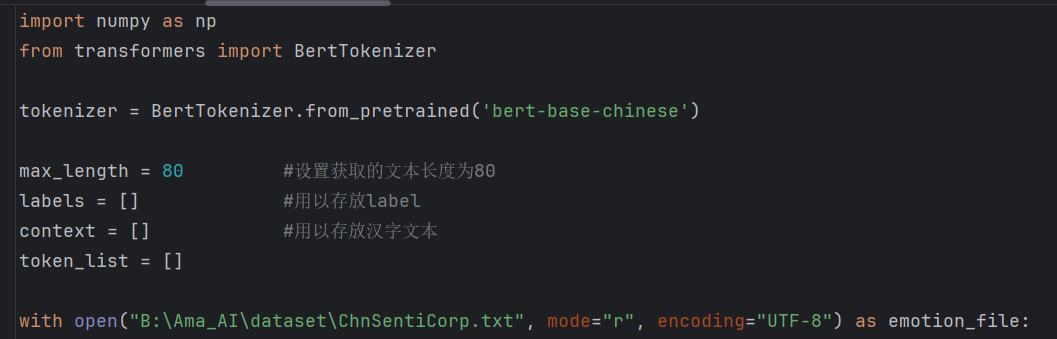
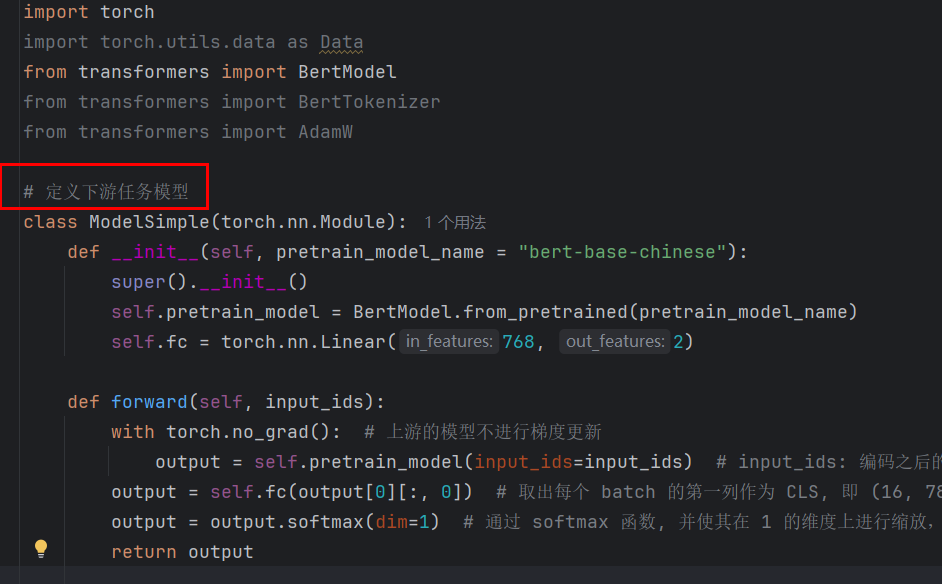
model:
train: