NeurIPS2025 |TrajMamba:编码器 + 双预训练,智能交通轨迹学习难题突破!
本篇论文解读使用的论文原文,由作者提供~前段时间小时介绍了一篇NeurIPS2025的优秀论文~发布不久后,作者看到后主动联系到了小时,表明传在arxiv的版本太老旧了,怕产生误导,所以小时当时发布不久就下架了~因此作者特意在国庆休假期间更新了arxiv上的论文版本~今天小时给大家重新介绍一下这篇中稿顶会的优秀论文~
重新介绍一下,本篇论文来自NeurIPS2025,最新前沿时序技术~针对车辆 GPS 轨迹的轨迹学习,提出了TrajMamba 模型,解决轨迹学习中 “提取出行目的计算量大” 和 “轨迹冗余点影响效率与质量” 两大核心问题,在多个下游任务中实现了精度与效率的双重超越。
重新整理以及补充了2025顶会时序合集,整合了更完整的“2025顶会时序合集”,包含论文及代码,无偿分享给大家~需要的可以在宫🀄蚝“时序大模型”回复“资料”自取~
文章信息
论文名称:TrajMamba: An Efficient and Semantic-rich Vehicle Trajectory Pre-training Model
论文作者:Yichen Liu, Yan Lin, Shengnan Guo, Zeyu Zhou, Youfang Lin1, Huaiyu Wan
最新论文传送门:https://arxiv.org/abs/2510.17545

研究背景
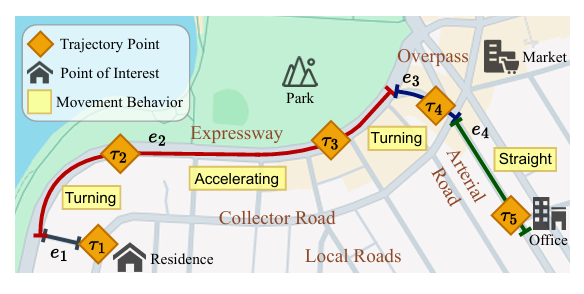
车辆 GPS 轨迹以(位置,时间)对序列形式记录车辆移动过程,蕴含移动模式(如转弯、加速)、出行目的(如通勤、购物)等关键出行语义,可支撑智能交通系统(ITS)中的多项核心任务,包括轨迹预测、行程时间估计、异常检测、轨迹相似度计算与聚类等。随着 GPS 轨迹数据量激增,高效提取语义信息的轨迹学习模型成为 ITS 构建的关键需求。现有的技术还存在瓶颈:
出行目的提取计算负担重:出行目的依赖轨迹途经道路的功能(如高速路、住宅区道路)与周边 POI(兴趣点,如办公楼、公园)的属性,但这些信息多以文本形式(如道路名称、POI 地址描述)存在。现有研究虽尝试整合语言模型(LMs)提取文本语义,但 LMs 规模远大于传统轨迹模型,会显著增加计算成本。
轨迹冗余点影响效率与质量:实际 GPS 轨迹采样频率高,易包含冗余点(如车辆停车、匀速行驶时的重复记录),不仅降低编码效率,还会干扰轨迹嵌入质量。传统轨迹压缩方法(如 Douglas-Peucker、Visvalingam-Whyatt)依赖规则或几何逻辑,时间复杂度高,且无法自适应学习关键信息,缺乏灵活性。
因此提出了TrajMamba模型,以解决上述问题。
模型框架
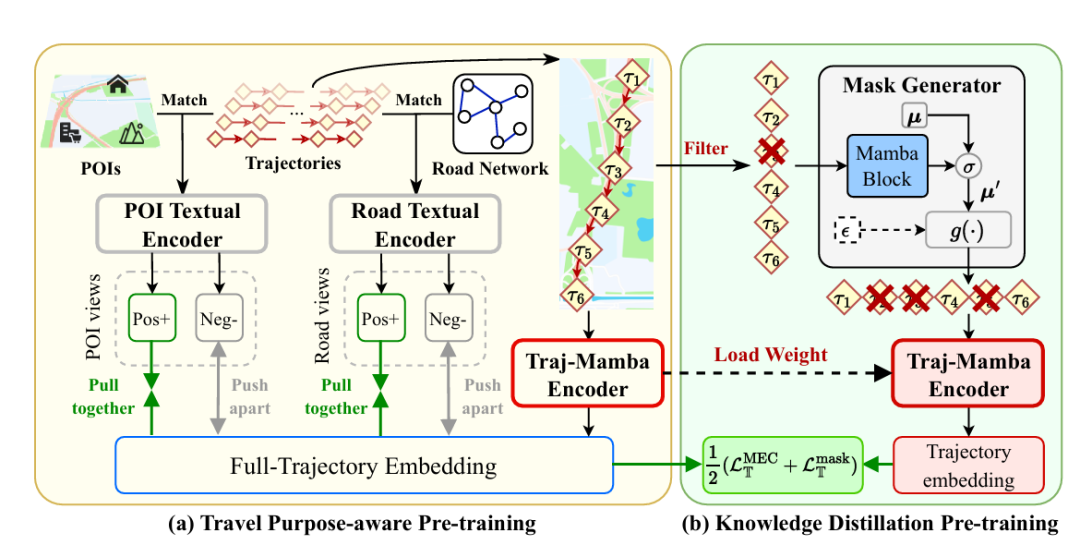
TrajMamba 通过 “编码器 + 双预训练” 架构,同时实现语义提取与效率优化,具体包括三大核心部分:
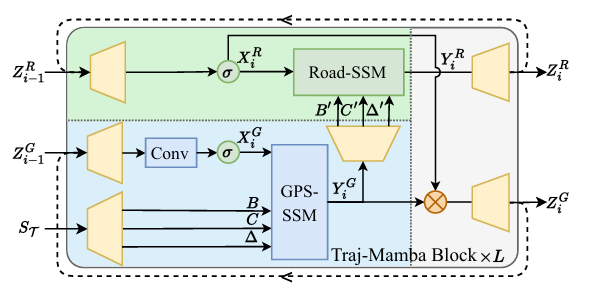
1.Traj-Mamba 编码器:联合 GPS 与道路视角的运动模式捕捉
结构基础:基于 Mamba2 结构,由 L 层堆叠的 Traj-Mamba 块组成,每个块包含 GPS-SSM(GPS 视角选择性状态空间模块)与 Road-SSM(道路视角选择性状态空间模块),二者均为多输入选择性 SSM,可实现线性时间复杂度的长时时空关联捕捉,避免 Transformer 类模型的二次复杂度问题。
输入特征处理:
GPS 视角特征:提取每个轨迹点的 GPS 坐标(经纬度)、相对起始时间差(Δt)、时间戳(分钟级),并计算速度、加速度、移动角度等高阶运动特征,形成 GPS 视角特征序列;通过线性层与傅里叶编码层,将这些特征映射为维度为 E/2 的 GPS latent 向量序列。
道路视角特征:提取每个轨迹点所在道路的 ID、星期、小时、分钟等信息,通过索引嵌入层()与线性层,映射为维度为 E/2 的道路 latent 向量序列。
输出融合:每层 Traj-Mamba 块通过点积门控机制实现 GPS 与道路视角特征的交互,最后一层块输出的与 经拼接、均值池化,得到最终的轨迹嵌入向量。
2. 出行目的感知预训练(Travel Purpose-aware Pre-training):无额外开销的语义融入
核心目标:在不增加嵌入计算负担的前提下,将出行目的语义整合到轨迹嵌入中。
实现流程:
道路与 POI 视角嵌入生成:先用共享预训练文本编码器(如 OpenAI text-embedding-3-large)处理道路文本描述与 POI 文本描述,生成初始文本嵌入;再结合轨迹起点 / 终点的全局信息、道路 / POI 的邻域局部信息(如 300 米内邻接 POI),通过聚合函数更新嵌入,最终经 2 层 Mamba2 块与均值池化,得到道路视角嵌入与 POI 视角嵌入 。
对比学习对齐:以 Traj-Mamba 编码器输出的轨迹嵌入为锚点,道路 / POI 视角嵌入为正样本,其他轨迹的道路 / POI 视角嵌入为负样本,采用 InfoNCE 损失(温度参数可优化)构建损失函数,实现轨迹嵌入与出行目的语义的对齐。预训练后固定编码器权重,作为 “教师模型”。
3. 知识蒸馏预训练(Knowledge Distillation Pre-training):可学习的轨迹冗余压缩
核心目标:通过可学习机制识别关键轨迹点,去除冗余,生成高效且语义完整的压缩轨迹嵌入。
实现流程:
掩码生成器(Mask Generator):先预处理过滤显式冗余点(如车辆停车、同路段匀速行驶的中间点);再将预处理后的轨迹输入可学习掩码生成器,通过稀疏随机门(含二进制偏置参数 μ)生成掩码 m,筛选关键点点(如起点、终点、转弯点),得到压缩轨迹。
师生模型对齐:用教师模型权重初始化 “学生模型”(新的 Traj-Mamba 编码器),将压缩轨迹输入学生模型生成压缩嵌入;通过 MEC 损失(最大化熵编码,保证压缩嵌入保留全轨迹信息)与掩码损失(约束压缩轨迹长度,确保效率)构建总损失,实现学生模型嵌入与教师模型全轨迹嵌入的对齐。
实验数据
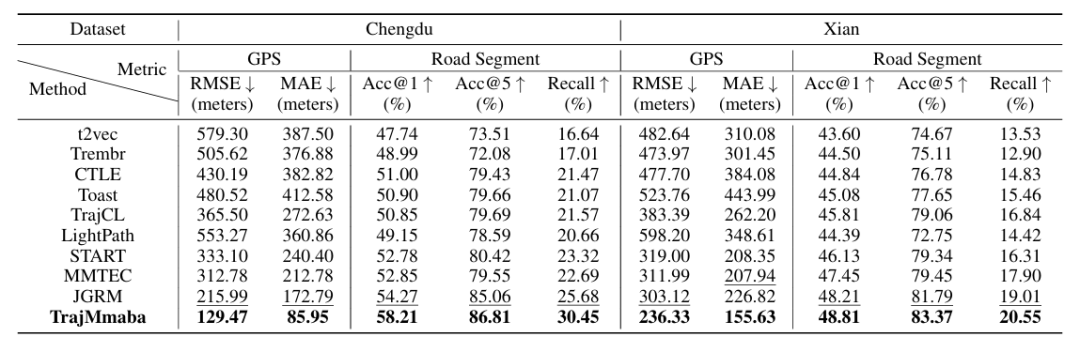
数据集:采用滴滴发布的两个真实出租车轨迹数据集(成都、西安),预处理后成都含 14 万条轨迹(1.88 亿个点)、4315 个道路段、1.24 万个 POI,西安含 21 万条轨迹(1.83 亿个点)、3392 个道路段、0.39 万个 POI;数据集按 8:1:1 划分为训练、验证、测试集,时间上按出发顺序划分。
下游任务:选择三大典型任务验证性能 —— 目的地预测(DP,预测轨迹终点的 GPS 坐标或道路段)、到达时间估计(ATE,预测未完成轨迹的到达时间)、相似轨迹搜索(STS,从候选集中找到与查询轨迹最相似的轨迹)。
基线模型:对比 9 个主流轨迹学习模型,包括 RNN 类(t2vec、Trembr)、Transformer 类(CTLE、Toast、START)、对比学习类(TrajCL、LightPath、MMTEC)、多模态融合类(JGRM)。
超参数:Traj-Mamba 的最优超参数为 L=5(Traj-Mamba 块层数)、E=256(嵌入维度)、N=32(SSM 状态维度)、H=4(SSM 头数);双预训练均执行 15 个 epoch,实验重复 5 次取均值。
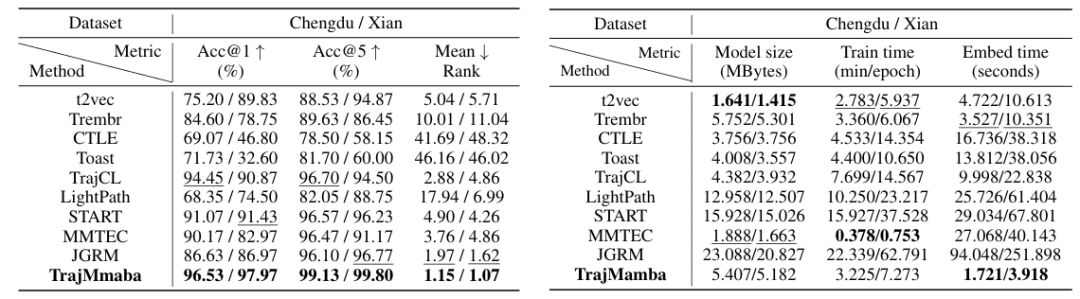
重点实验结果
(1)精度性能:全面超越基线
目的地预测(DP):在 GPS 预测(RMSE、MAE)与道路段预测(Acc@1、Acc@5、Recall)指标上均最优。以成都数据集为例,与次优模型 JGRM 相比,GPS 预测 RMSE 从 215.99 米降至 129.47 米(降低 45.16%),道路段 Acc@1 从 54.27% 提升至 58.21%(提升 9.30%);即使在 “不微调”(仅更新预测头)设置下,仍比 JGRM 的道路段 Acc@1 提升 27.47%。
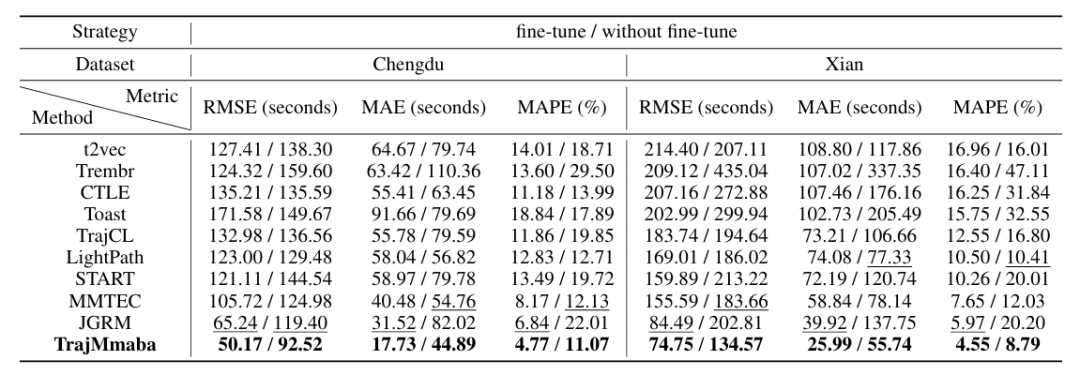
到达时间估计(ATE):成都数据集 RMSE 从 JGRM 的 65.24 秒降至 50.17 秒(降低 32.35%),MAE 从 31.52 秒降至 17.73 秒;西安数据集 RMSE 从 84.49 秒降至 74.75 秒(降低 23.44%),且 “不微调” 设置下性能优势更明显,证明预训练的有效性。
相似轨迹搜索(STS):成都数据集 Acc@1 达 96.53%(JGRM 为 86.63%),Mean Rank 从 1.97 降至 1.15;西安数据集 Acc@1 达 97.97%(JGRM 为 86.97%),Mean Rank 从 1.62 降至 1.07,且对无直接轨迹级表示的基线(如 CTLE、Toast)优势显著。
(2)效率性能:轻量化且快速
模型大小:Traj-Mamba 在成都 / 西安数据集的模型大小为 5.407/5.182MB,与轻量 RNN 模型(t2vec:1.641/1.415MB、Trembr:5.752/5.301MB)相当,远小于 Transformer 类模型(START:15.928/15.026MB、JGRM:23.088/20.827MB)。
嵌入时间:成都数据集嵌入时间仅 1.721 秒,西安为 3.918 秒,是 JGRM(94.048/251.898 秒)的 1/50 以上,也优于多数基线(如 CTLE:16.736/38.318 秒、LightPath:25.726/61.404 秒)。
训练时间:虽训练时间(成都 3.225 分钟 /epoch、西安 7.273 分钟 /epoch)并非最短,但预训练不增加嵌入阶段负担,而嵌入效率是真实场景的关键需求,因此额外训练时间具有性价比。
3. 消融实验与模型分析
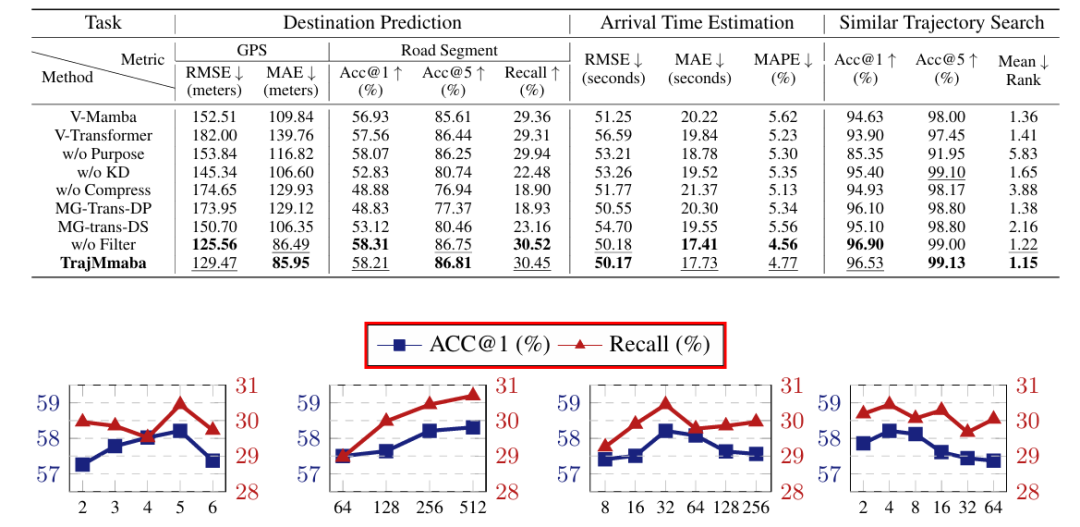
组件必要性验证:移除 Traj-Mamba 块(替换为 vanilla Mamba2 或 Transformer)、出行目的感知预训练(替换为重构任务)、知识蒸馏预训练后,模型在三大任务中性能均下降。例如,“无压缩”(w/o Compress)变体的 DP 任务 GPS RMSE 升至 174.65 米,STS 任务 Mean Rank 升至 3.88,证明压缩对语义保留与效率的重要性。
掩码生成器优势:对比传统压缩方法(如 Douglas-Peucker,MG-Trans-DP 变体)与直接下采样(MG-Trans-DS 变体),Traj-Mamba 的可学习掩码生成器能更精准保留关键点点(如起点、终点),DP 任务 Acc@1 比 MG-Trans-DP 高 9.38%,STS 任务 Mean Rank 低 0.23。
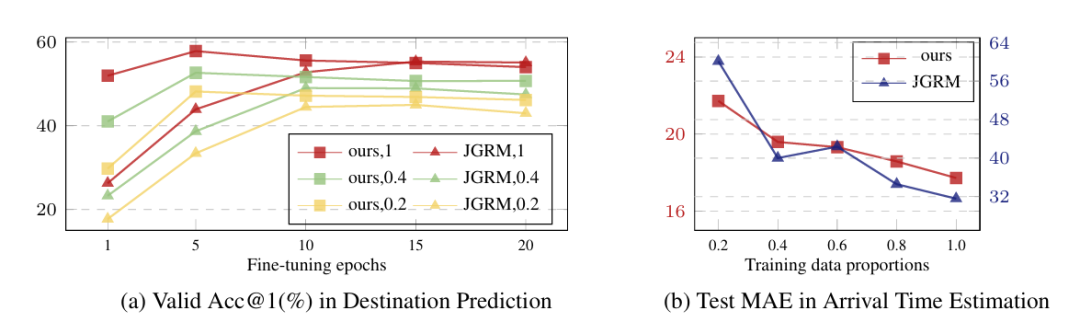
超参数与可扩展性:嵌入维度 E 对性能影响最大,E=256 时精度与效率平衡最优;模型在仅用 20% 训练数据时,DP 任务 Acc@1 仍比 JGRM 高 5% 以上,证明良好的小样本适应性。

小小总结
文章提出的TrajMamba 是一款高效且语义丰富的车辆轨迹预训练模型。提出了 Traj-Mamba 编码器,首次联合 GPS 与道路双视角,以线性时间复杂度捕捉轨迹运动模式,解决传统模型 “复杂度高” 或 “视角单一” 的问题。
设计了出行目的感知预训练方案,通过文本编码器与对比学习,在不增加嵌入计算负担的前提下,实现出行目的语义与轨迹嵌入的对齐。 提出了基于知识蒸馏的可学习轨迹压缩机制,通过掩码生成器与师生模型对齐,兼顾冗余去除与语义保留,提升编码效率。
关注小时,持续学习前沿时序技术!