告别“读字”,开始“看图”:AI正在用人类的方式学习“阅读”
想象一下,你正在教一个超级聪明的AI学会阅读。过去十多年,我们教它的方法,很像教一个刚启蒙的小学生:我们需要把一篇文章、一句话,甚至一个词,小心翼翼地切分成更细碎的“零件”(在AI领域,这被称为Token,你可以理解为“词块”)。然后,AI再像拼乐高一样,学习这些“词块”的含义和组合规律。
这个方法成就了今天的ChatGPT等大模型,但它有个核心麻烦:这个“切词”的步骤本身就很复杂,而且容易出错,就像一本字典总有些模糊不清的释义,限制了AI对语言更精妙的理解。
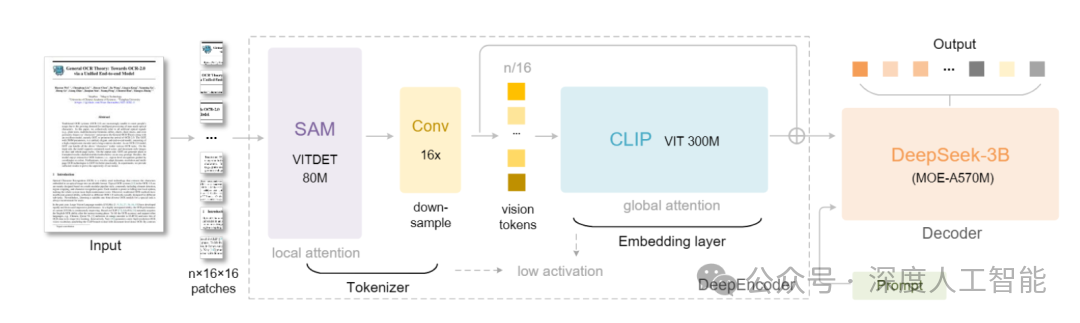
但现在,DeepSeek推出了一款名为DeepSeek-OCR的新模型,它提出了一种让整个科技圈为之震惊的新思路:我们何必让AI一个个地“读”字?为什么不直接让它“看”整页文字的“照片”,让它像我们人类扫读一样,从整体布局和图像中直接汲取信息?

这不仅仅是思路的转变,在工程上它取得了惊人的突破:这个模型能将一篇1000字的文章,“拍摄”成一张高度压缩的“信息快照”,这张“快照”里只包含100个关键信息点(称为视觉Token)。效率提升了十倍,但识别准确率却高达97%。这意味着,原本AI需要“吃下”1000个零件才能理解的内容,现在只看100个“信息胶囊”就足够了。
这听起来或许只是个技术优化,但其背后隐藏着一个足以动摇整个行业根基的预言:我们为AI设定的“学习路径”,可能从最开始就走偏了。
01
从“听力”到“视力”的范式转移
传统AI模型处理信息时,就像是一个戴着耳机的转录员:它接收的是已经被转换成文字的内容,却从未真正“看见”原始材料。这种依赖文字输入的方式,我们称之为“文本至上”范式。
而DeepSeek-OCR的突破在于,它让AI直接处理视觉信息——就像给AI装上了一双真正的“眼睛”。这项技术的核心洞见是:人类通过视觉感知世界,为什么AI不能这样做呢?
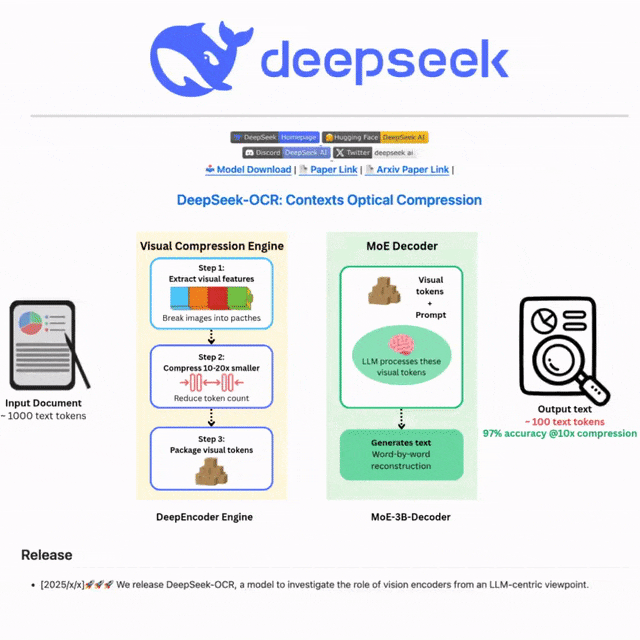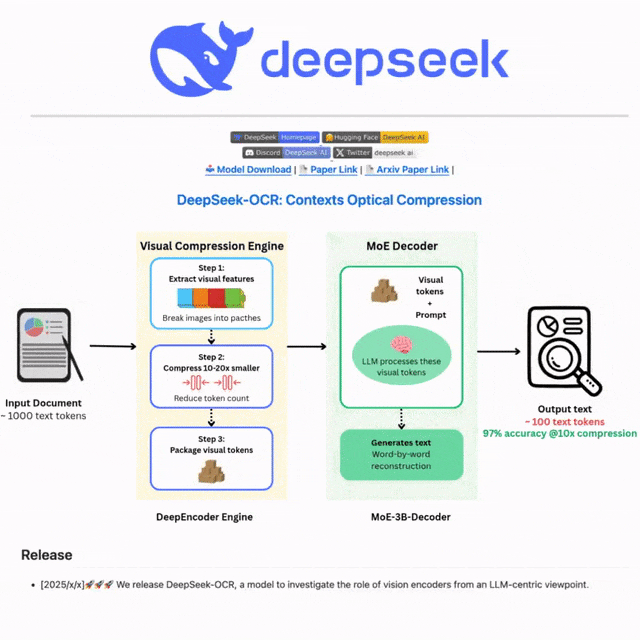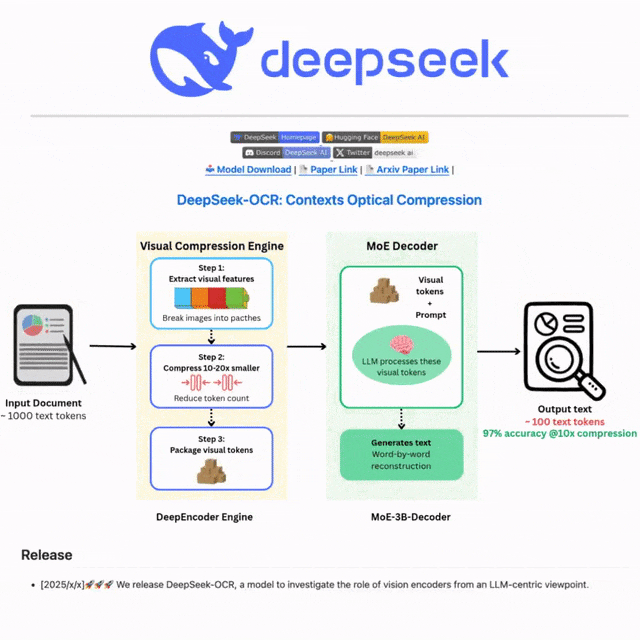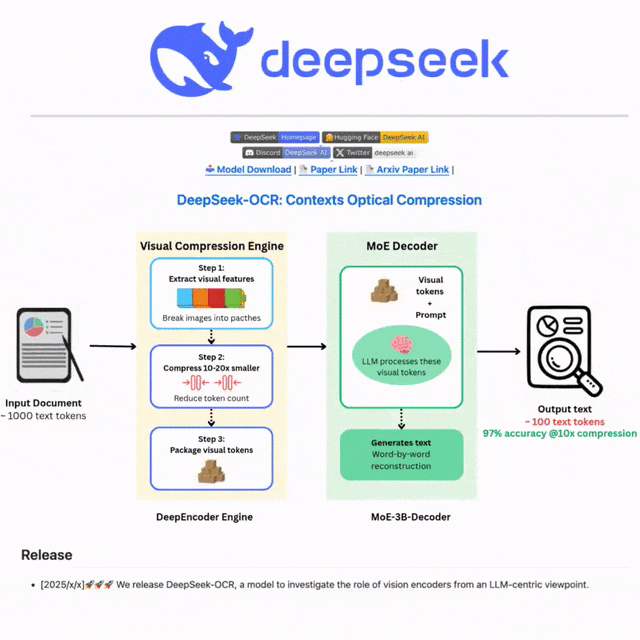
在“听力”范式下,AI需要依赖分词器将文本拆解成最小的语言单位,逐个进行分析和理解,就如同一个听力敏锐但缺乏整体感知能力的人,只能通过逐个捕捉声音片段来拼凑信息。这种方式不仅处理流程繁琐,而且容易丢失文本中蕴含的上下文关联和整体语义。
而“视力”范式则彻底改变了这一局面,AI不再局限于对离散文字的线性处理,而是像人类阅读时一样,通过视觉系统对整个页面的布局、字体、段落结构等视觉元素进行综合感知,从而快速把握文本的核心内容和整体逻辑。这种从局部到整体、从离散到连续的认知方式转变,使得AI在信息处理的效率和深度上都实现了质的飞跃,也为其在更复杂的场景中理解和应用信息开辟了全新的可能性。

这种范式转移的意义远不止于技术层面的优化,更代表着AI向人类认知模式的进一步贴近。在“听力”时代,AI如同隔着一层文字的滤镜观察世界,所有信息都必须先经过文本化的转译才能被处理,这不仅增加了信息损耗的风险,也限制了AI对非文本视觉信息的直接理解能力。
“视力”范式的建立,让AI得以直接面对原始的视觉输入,无论是手写笔记的潦草笔触、古籍文献的斑驳字迹,还是复杂图表中的数据关联,都能被其以更自然、更贴近人类感知习惯的方式捕捉和解读。
这种转变打破了长期以来文本作为AI理解世界唯一入口的局限,使得AI能够更全面、更真实地感知和处理多元信息,就像一个原本只能通过听觉来想象世界的人,突然获得了视觉能力,从此能够直接看见色彩、形状和空间布局,从而对世界产生更立体、更深刻的认知。
02
技术突破的具体表现
在实际性能上,DeepSeek-OCR交出了一份令人惊叹的成绩单:
•极速处理能力
在一张标准的A100显卡上,DeepSeek-OCR每秒能够处理约2500个文字单位。这个速度意味着什么?对比人类阅读速度,一个快速阅读者每分钟大约能读1000字,而DeepSeek-OCR一秒钟就能处理相当于15万个汉字的内容!这种速度优势使得实时处理海量文档成为可能。
•智能压缩技术
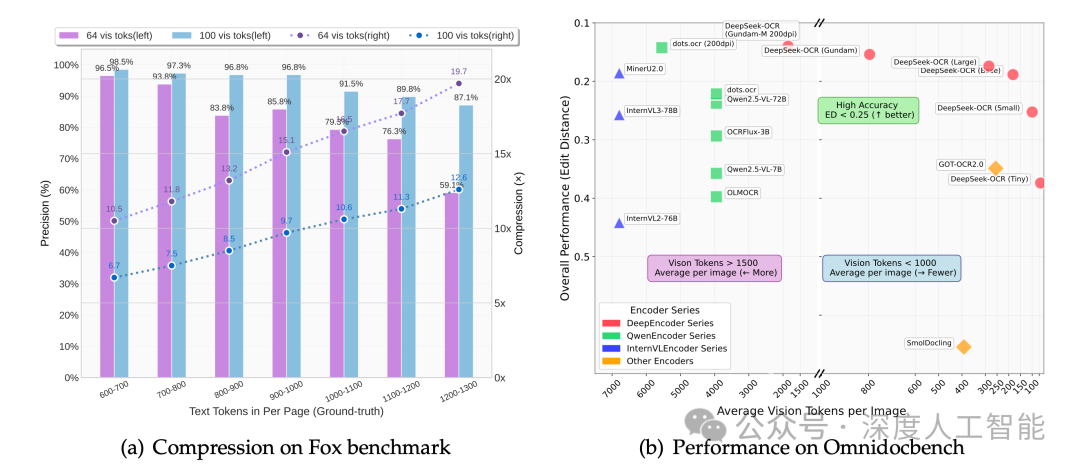
更令人称奇的是其压缩能力。在保持97%超高准确率的前提下,DeepSeek-OCR能够将视觉信息压缩至原来的1/20。即使是常规使用情况下,压缩比也能轻松达到1/10以下。

想象一下:一整页密密麻麻的学术论文,包含数千个字符和复杂的排版格式,被神奇地压缩成仅仅100个视觉单元。这就像把一本厚重的百科全书压缩成一张明信片的大小,而AI仍然能够准确读取其中的所有信息。
•卓越的基准测试表现
在权威的OmniDocBench测试中,DeepSeek-OCR使用更少的视觉单元,就超越了GOT-OCR2.0和MinerU2.0等顶尖模型的表现。最高实现了60倍的压缩比率,这一数字在业界堪称前所未有。
•多语言支持与实用价值
DeepSeek-OCR支持全球100多种主要语言,从英文、中文到阿拉伯文、梵文,覆盖了世界上绝大多数书写系统。这种广泛的语言支持使得该技术具有真正的全球应用潜力。
03
核心革命:“看图识字”与“逐个认字”的天壤之别
为了帮您更好地理解这场变革,我们不妨做一个更生动的对比:
•传统方法(逐个认字):就像你收到一封重要的手写信,你却选择用一个字一个字地抄录下来再读。一旦字迹潦草或有一个字不认识,整个过程就可能卡住。
•新方法(看图识字):就像你直接拿起这封信,快速扫视一遍。你不仅读懂了文字,还瞬间捕捉到了笔迹的轻重、关键句下的划线、段落旁的感叹号,乃至信纸抬头的Logo所传递的额外信息。

为什么“看图”可能是一种降维打击?AI领域的顶尖专家、OpenAI的联合创始人安德烈·卡帕西(Andrej Karpathy) 对此极为兴奋,他指出了几个颠覆性的优点:
1.信息密度暴增,记忆长度飞跃:一张“图片”是信息的富矿。它能同时编码文字的字体、颜色、加粗、斜体、布局,甚至旁边附带的简单图表和印章。这就像从听一首歌曲的歌词,升级到观看它的MV,获得的信息量不可同日而语。这意味着,AI可以用同样的“脑容量”,记住并处理十倍于以前的长篇内容,比如一整本小说或一家公司的全部档案。
2.万物归一,无所不包:今天的AI通常是“专项生”——处理文字的模型看不懂图片,需要额外嫁接功能。但如果所有输入,无论是纯文本、网页、表格、海报还是手写笔记,从一开始就被统一成“图像”,那么AI就天然具备了处理一切视觉信息的能力。它只用一种“语言”(视觉语言)就能理解整个世界。
3.双向理解的突破:Karpathy特别强调了一个技术细节:视觉输入天然支持“双向注意力机制”。简单理解就是,当AI“看”一张图片时,它能够同时理解整幅图像的所有部分及其相互关系,而不是像阅读文字那样只能从左到右线性理解。
04
分词器:AI发展的“历史包袱”
Karpathy对传统分词器的批评尤为激烈,他将分词器称为“AI发展的历史包袱”和“一个笨重、丑陋且充满安全漏洞的‘假肢’”。
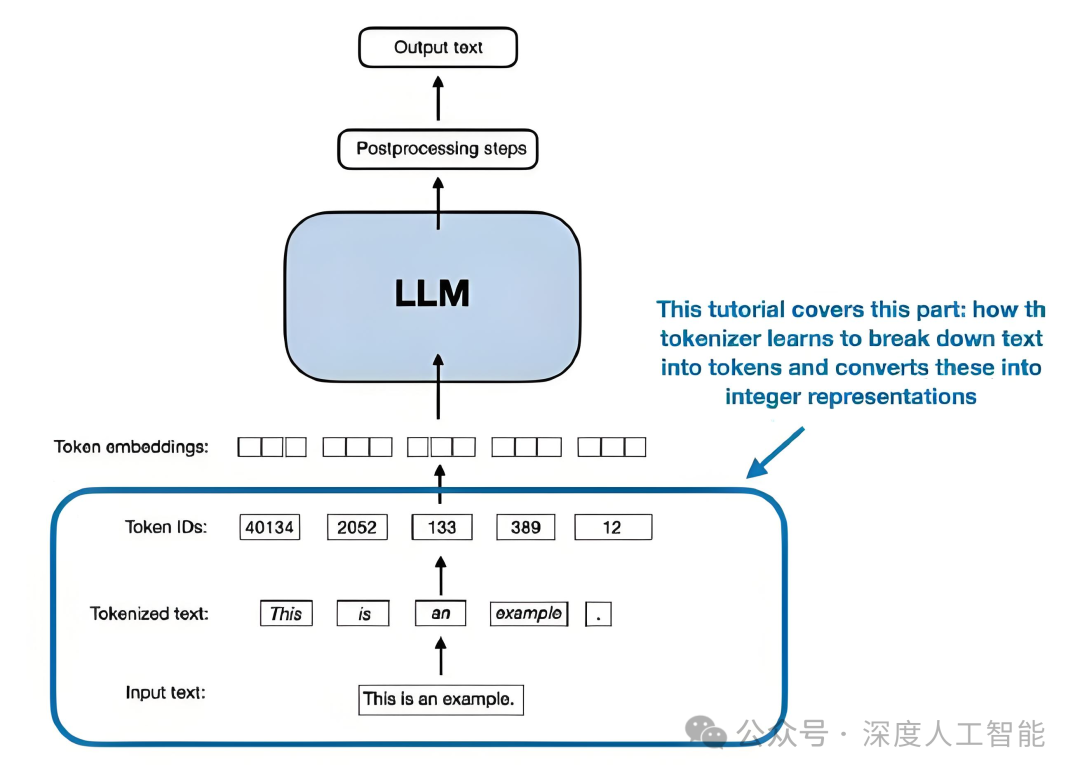
分词器到底是什么?
我们可以把分词器理解为AI的“识字课本”。当AI遇到文字时,它需要依靠这个课本把连续的字符切分成一个个有意义的单元。但问题在于,这个“课本”充满了各种缺陷:
•处理特殊字符困难:遇到生僻字、表情符号或者特殊格式时经常“卡壳”
•一致性差:两个肉眼看起来完全相同的字符,可能被识别成不同的单元
•缺乏真正理解:笑脸表情对AI来说只是一串代码,而不是真正的笑脸
Karpathy直言:“分词器引入了Unicode编码的所有历史包袱,就像让现代人用甲骨文来思考一样低效。” 如果直接输入像素,这个制造了无数麻烦的中间商就可以被彻底拿掉,让AI的学习过程变得更加纯粹和高效。
这项技术最迷人的地方在于,它似乎在无意中模仿了人类自身的认知机制。
请你现在尝试回忆一本你读过的书中的某句经典台词。你的第一反应是什么?你很可能首先在脑海中“看到”了那句话在书的哪一页、大概在页面的哪个位置、左边还是右边,这样一个清晰的视觉空间画面,然后才清晰地浮现出文字本身。
我们的大脑,本身就极其擅长运用“视觉快照”来辅助记忆和定位知识。DeepSeek的新方法,仿佛让AI也拥有了这种“视觉记忆”的能力。
05
重塑未来:当AI真正实现“过目不忘”
如果这条“以视觉为中心”的道路被证明是可行的,那么它对我们的日常生活和工作方式将产生深远的影响:
•个人超级知识库:想象一下,你可以将你读过的所有教材、行业报告、个人笔记,全部“拍照”存入一个AI助理的“大脑”。此后在任何需要的时候,你都可以像询问一位博闻强识的贴身专家一样,即时获得最精准的解答,它永远不需要翻箱倒柜地查找。

•企业智慧中枢:一家公司可以将所有历史文件、合同、流程手册、代码库,一次性注入AI的长期记忆。新员工培训、合规查询、技术难题排查,都将变得前所未有的高效和简单。
•教育领域革命:想象一个智能学习助手,学生可以直接拍摄教科书的一页,AI不仅能够识别文字,还能理解图表、公式、重点标记的颜色,甚至根据排版结构判断内容的重要性层次。这将彻底改变数字学习体验。
•办公自动化飞跃:传统的文档数字化需要复杂的OCR识别和格式重建,而DeepSeek-OCR可以直接“理解”文档的视觉呈现,保留所有的原始格式和布局。法律文档、学术论文、商业报告的处理将变得前所未有的准确和高效。
•文化遗产保护:对于古籍、档案等珍贵文献,传统数字化过程往往面临格式丢失的问题。DeepSeek-OCR能够原汁原味地保存文献的视觉特征,为文化遗产的永久保存提供了理想解决方案。
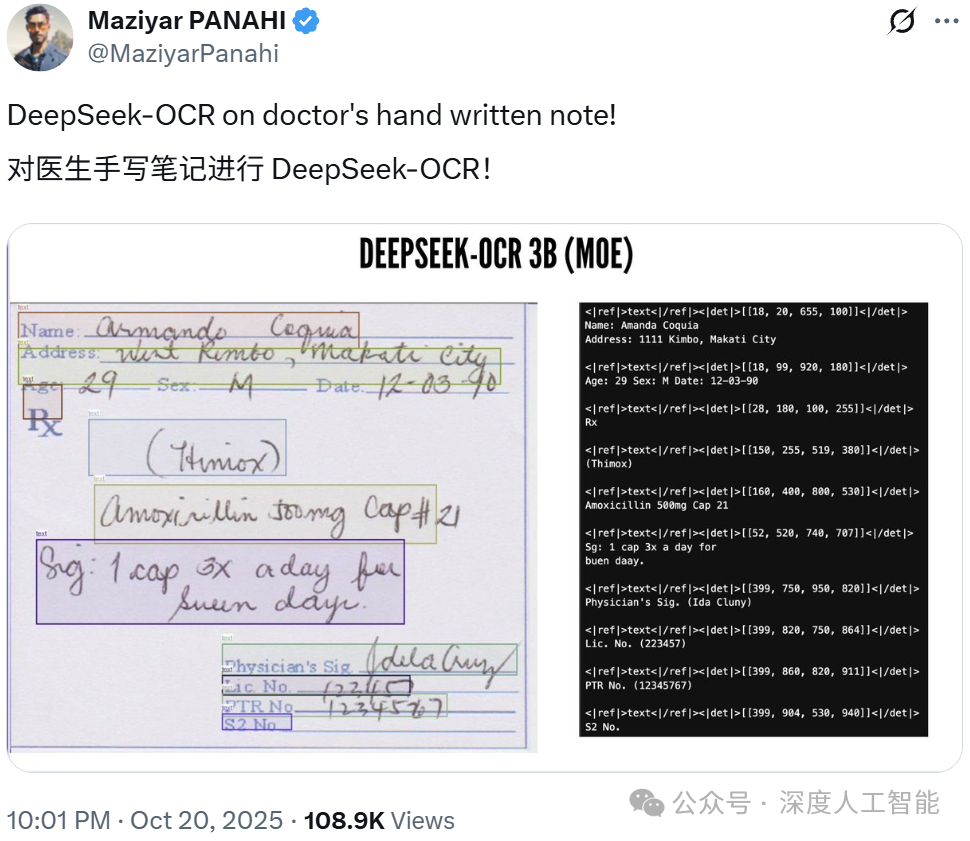
•打破所有信息壁垒:任何被印在实体载体上的信息——从古旧书籍的扫描件到超市的宣传单,从复杂的设计图纸到医生的手写处方——AI都能用一种统一的方式瞬间解读,让信息真正实现无障碍流动。
06
业界反应与未来展望
DeepSeek-OCR的开源项目在GitHub上一经发布,一夜之间就获得了4.4k星标,截止目前已经飙升到6k多星标,显示了开发者社区对这一突破的高度认可。

更有趣的是,这项技术引发了一个根本性思考:也许未来所有的AI输入都应该是视觉形式的?
Karpathy提出了一个大胆的设想:“即使用户输入的是纯文本,也许我们也应该先将其渲染成图像,再交给AI处理。”这种方法的优势在于统一了处理范式,使得AI能够用同样的方式处理所有类型的输入。
当然,这项技术的普及还面临一些挑战。视觉数据处理对计算资源的要求更高,需要优化的推理框架。此外,建立基于视觉输入的全新AI训练方法论也需要时间。
但是,这些挑战背后是巨大的机遇。Karpathy透露,他正在认真考虑开发一个完全基于视觉输入的“nanochat”系统,这将是对传统聊天机器人的彻底革新。
这场讨论甚至引发了更宏大的思考。埃隆·马斯克在相关讨论中提出了一个科幻般的展望:“长期来看,AI模型超过99%的输入和输出将是光子。”
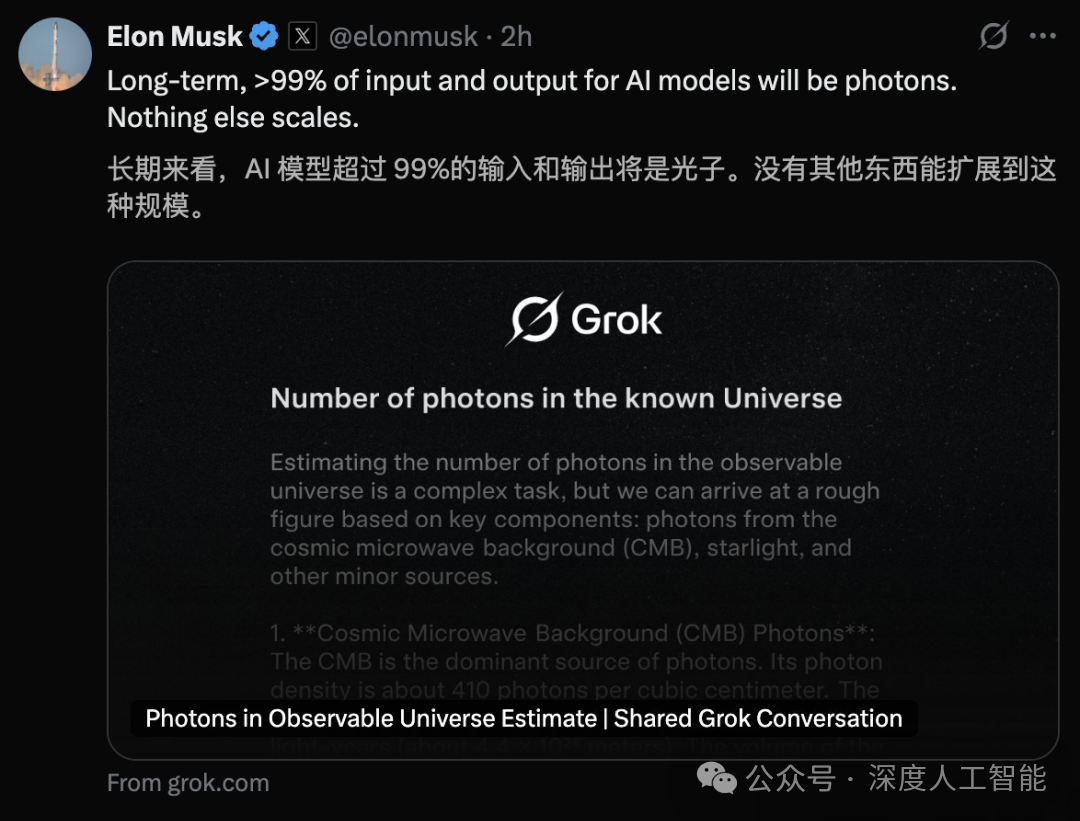
他的AI助手Grok甚至计算了可观测宇宙中的光子总数——约1.5×10⁸⁹个。马斯克指出,光子是宇宙中最基本的信息载体,人类视觉系统本身就是一种高效的光子处理机制。这暗示着,基于视觉的AI可能是通向更通用智能的必经之路。
结语:一场关于“如何学习”的范式革命
DeepSeek的这次开源,其价值远不止于提供了一个强大的文档识别工具。它更像是在AI高歌猛进的时代,按下的一次暂停键,引导整个行业进行一场深刻的反思:我们一直以来让机器理解世界的方式,是唯一且最优的吗?
它为我们推开了一扇全新的窗户,让我们窥见了一个不一样的未来:在那里,人工智能或许不是通过解构文本来逼近我们的智能,而是通过一种更接近人类本能的、整体性的“视觉感知”,最终实现对复杂世界的真正理解。

这不仅仅是技术的迭代,这是一次关于“如何学习”的范式革命。而这场革命的起点,或许就始于一个简单的转变:从“读”到“看”。AI正在从“识字”阶段迈向“感知”阶段,就像人类婴儿先学会看世界,再学会读文字一样。
在这个视觉革命的开端,我们也许正在见证一个新时代的黎明——AI真正睁开双眼,开始像我们一样感知这个丰富多彩的世界。这条路还很长,但DeepSeek-OCR已经为我们指明了方向。