freertos入门---栈的概念
freertos入门—栈的概念
1 栈的概念
栈也是一块内存空间,CPU的SP寄存器指向它,它可以用于函数调用、局部变量、多任务系统里保存现场。栈对于多任务系统非常的重要,每个任务都有自己的栈,我们只有深入理解栈的作用,才能深入理解多任务系统。
2 函数调用
我们首先编写一个程序,程序流程为:在主函数中调用函数a_func(),在a_func()中调用b_func()与c_func()。
#include "stm32f10x.h"
int g_cnt;
int b_func(volatile int a)
{
a += 2;
return a;
}
int c_func(volatile int a)
{
a += 3;
return a;
}
void a_func(volatile int a)
{
g_cnt = b_func(a);
g_cnt = c_func(g_cnt);
}
int main(void)
{
char ch = 65;
volatile int i = 99;
a_func(i);
return 0;
}
接着利用下述方法生成反汇编码:


fromelf --text -a -c --output=test.dis .\Objects\点亮一个LED灯.axf
打开生成的反汇编码,将反汇编码显示如下:

函数调用的本质就是使用 BL 指令,但是我们main函数调用 a_func 函数时,我们设置了LR。然后我们在 a_func 函数里调用 b_func 函数时,又使用同样的 BL 指令设置 LR 等于另外一个值,那么我们的 LR 不就是被覆盖了吗?由此我们引出以下问题:
- LR被覆盖了,怎么办?
- 局部变量在栈中如何分配?
- 为何每个RTOS任务中都有自己的栈?
在函数调用过程中,我们调用函数a,我们设置了 LR 等于函数 a 执行完后的返回地址,在函数 a 中我们马上去调用函数 b,BL 指令同时会去设置 LR,会把之前的 LR 覆盖掉,那么显然在 LR 被覆盖前会去保存 LR。

同样在函数 b 中,我们不管三七二十一,也是先把 LR 保存下来,后面我们可能不会去修改 LR ,但是为了以防万一,或者说编译器为了统一处理,在函数入口处会保存 LR。

接着我们把函数调用时栈的分配具体讲解:
-
假设一开始,寄存器指向某一位置,我们调用 main 函数,保存 r3 以及 lr 。

-
main 函数调用函数 a,会去保存 lr 和 r0。

-
函数 a 调用函数 b ,函数 b 里也去保存两个寄存器。

-
接着我们调用函数 c ,那么函数 c 的栈是在 函数 b 的栈下面吗?答案是否定的,我们调用完函数 b 后,函数 b 的栈就被回收了,所以当函数 b 的栈被回收后,我们才开始分配函数 c 的栈。

所以,在每一个c函数的入口,会划分出自己的栈,保存 LR 进栈里,保存局部变量。
2 局部变量
对于局部变量的讲解,我们从下面 main 函数中的局部变量开始分析:

一进入 main 函数时,就入栈了若干个寄存器:
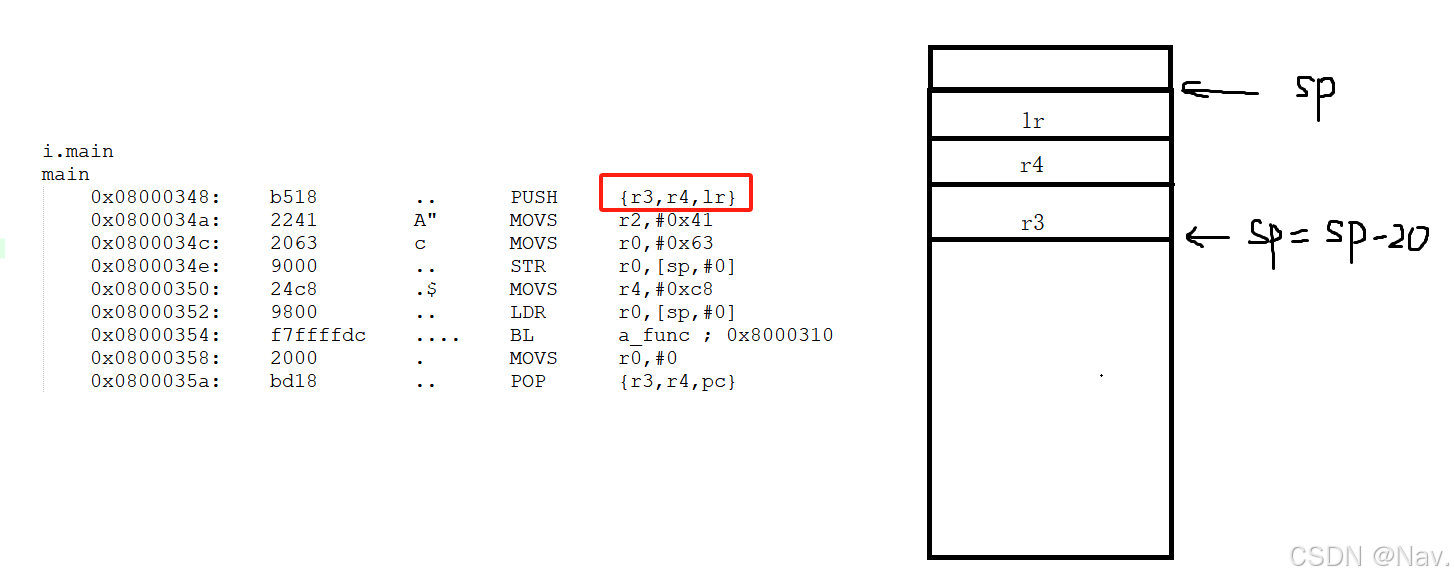
我们分析 MOVS r2,#0x41 ,0x41是65,那么我们的 r2 寄存器其实就是局部变量 ch ,所以说局部变量有可能保存寄存器中,不一定保存在内存里,当我们加上 volatile 后它就保存在内存里了,或者说寄存器不够用时也保存在内存里。

继续分析 MOVS r0,#0x63 , 0X63 是99,那么 r0 是 i 变量,接着将 r0 写入[sp,#0]中,所以变量i是保存在栈中。

所以 main 函数一进来的时候他就划分了栈,在栈中保存了一些寄存器,它使用保持寄存器的方式给我们划分出了一块空间,这块空间在后面代码我们分析了知道 [sp,#0] 对应的是 i 。
我们继续分析 MOVS r4,#0xc8 ,0xc8 是 200 ,那么 r4 是 uch 变量。该变量保存在寄存器中而不是内存中。

3 RTOS如何使用栈
为什么每一个 RTOS 任务都要有一个属于自己的栈?我们以下面函数 b 为例,在函数中它会将变量 a 加 2 ,然后返回这个新的值。

现在假设有两个任务,Task_A 中定义一个变量 cnt ,然后定义一个死循环,在这个死循环中不断的去累加这个 cnt ,任务 b 也是一样。

那么这两个任务如何运行呢?任务A运行一阵子发生切换,然后任务B运行一阵子再发生切换,接着再发生切换,这个切换在哪发生我们根本无法控制。

我们来看下面一个场景,函数 a 调用函数 b ,他可能辛辛苦苦才执行到 ADDS r0,r0,#2 ,这个数值还未返回就发生了切换:

在任务A发生切换时会先保存A的现场然后恢复B,任务B发生切换时会先保存B的现场然后恢复A。

&emsps; 以人为例,这个人要看两本书,一本是语文一本是数学。他的脑子只有一个,只能先读语文再读数学,学腻之后再看语文再看数学。一开始的时候语文读到了100页,读累了想看数学了,那得在100页加入书签。看了200页数学也看累了,那得在200页处加入书签,然后从前面语文100页处继续看。这加书签就是保存现场,从书签那里继续看就是恢复现场。

任务A运行到黑线这个位置,辛辛苦苦把 r0 加上了2,但是很不幸在这里我们还没有使用这个新结果呢,我就被切换出去了,那怎么办?我们辛辛苦苦算出的结果不能够浪费,在这个场景里是 r0 ,在其他的场景里可能是 r1 或者 r2 ,所以干脆把所有的寄存器都保存下来。那么这些寄存器保存在什么位置,我们分析下处理器架构。

保存的寄存器只能保存在内存里。假设任务A一开始的时候我们给它分配了一块内存,我们让sp寄存器指向addr a,分配 Task_A 函数的栈,接着 Task_A 函数调用 b 函数,分配 b 函数的栈,任务 A 发生切换时是被内核的定时器中断函数来切换,定时器中断函数需要保存任务 A 的现场,保存切换瞬间所有的寄存器到任务A的栈里面。

当保存现场完成后sp指向最后,并且将sp记录到任务A的结构体中。为什么需要在任务A的结构体中记录sp,因为以后切换的时候我们需要先找到任务A的结构体,从这结构体中我们才可以找到sp,把sp赋给硬件的寄存器。
接着我们应该讲解任务 B 的恢复,但是任务 B 的恢复与任务 A 的恢复一样,因此我们以任务 A 的恢复进行讲解。恢复任务 A 首先找到任务 A 的结构体得到 A 的sp。得到任务 A 的sp后我们就可以把保存的寄存器值全部恢复到硬件上,恢复到 cpu 里。这样虽然在 ADDS r0,r0,#2 发生了切换,但是恢复现场后寄存器的值都能被恢复到cpu中,因此可以继续执行下面的程序。
所以RTOS中每个任务有不同的栈是因为:1.有不同的调用关系 2.有自己的局部变量 3.保存现场