Redis 特性/应用场景/通用命令
目录
1. Redis 特性
2. Redis 应用场景
3. 安装 Redis
4. Redis 命令
4.1 set & get
4.2 全局命令/通用命令
4.2.1 keys
4.2.2 exists
4.2.3 del
4.2.4 expire
4.2.5 ttl
4.2.6 type
5. Redis 过期策略 [经典面试题]
6. [拓展] 通过定时器实现 Redis 过期策略
6.1 基于优先级队列/堆
6.2 基于时间轮
1. Redis 特性
Redis 是一个在内存中存储数据的中间件, 而它最常见的用途是作为缓存或者数据库使用.
- 内存: 指的是计算机的 RAM(随机存取存储器), 是一个真实的物理硬件组件.
- 缓存: 是一种技术思想, 作用是临时存储那些会被频繁访问的 "热点" 数据, 从而加快访问速度.
Redis 具有以下优秀特性:
- 将数据存储在内存中, 并且支持多种数据结构类型, 如: strings(字符串)/hashs(哈希)/lists(列表)/sets(集合)/sorted(有序集合)/streams(流)/...
- Redis 主要是通过 "键值对" 的方式来存储数据, 其中 key 都是 字符串, 而 value 就是上述的数据结构. 因此, Redis 为 "非关系型数据库".
- 而 MySQL 是以 "表" 的方式来存储数据的, 称为 "关系型数据库".
- 可编程的: 操作 Redis 时, 可以直接通过简单的交互式命令进行操作, 也可以通过编写脚本, 批量执行一些操作(可以执行一些逻辑).
- 对于 Redis 的编程操作, 主要使用 Lua ("露啊") 作为脚本语言.
- 可拓展性: Redis 提供了一组 API, 用户可以在 Redis 原有功能的基础上, 使用 C/C++/Rust/... 编写 Redis 扩展(本质上是一个动态链接库).
- 比如: Redis 提供了多种数据结构和命令. 通过扩展, 就可以让 Redis 支持更多的数据结构和命令.
- 持久性: Redis 也可以持久化的保存数据, 不仅存在内存中, 也存在硬盘上.
- 如果只是将数据存到内存中, 那么系统重启/进程退出 内存上的数据都会丢失. 因此, Redis 不只是将数据存储在内存上, 也会把存到硬盘中. 但是, 是以 "内存为主, 硬盘为辅", 硬盘上的数据只是作为 "备份", 以防数据丢失.
- Redis 对数据进行增删改查操作, 都是针对内存数据进行的, 硬盘数据只是内存数据的 "备份", 如果 Redis 重启了, 就会重新加载硬盘中的备份数据, 使 Redis 中的数据恢复到重启前的状态.
- 支持集群: 一个 Redis 存储的数据是有限的(内存空间有限), 因此 Redis 通过 水平扩展 引入多个主机, 部署多个 Redis 节点, 每个 Redis 节点存储一部分数据.
- 可用性高: Redis 支持 "主从" 结构的架构模式, 因此 "从节点" 就相当于 "主节点" 的备份, 当 主节点 出现问题时, 从节点就可以临时充当主节点.
- Redis 速度快(增删查改都快):
- Redis 把数据存到内存中, 因此比访问硬盘要快得多.
- Redis 核心功能都是比较简单的逻辑, 比较简单的操作内存的数据结构
- 从网络角度上看, Redis 采用了 IO 多路复用的方式(epoll). (使用一个线程, 管理很多 socket, 也就是, 一个线程, 监听和处理多个网络连接)
- Redis 使用的是单线程模型, 因此减少了不必要的线程之间的竞争开销.
- 注意: 多线程能够提高效率的前提是, 执行的是 CPU 密集型任务. 因此, 这类任务, 可以使用多线程充分利用 CPU 多核资源.
- 而 Redis 的核心任务, 就是操作内存上的数据结构, 这不会消耗很多 CPU.
- Redis 使用的是 C 语言开发的, 因此速度快. [?? 但是 MySQL 也是 C 开发的...]
注意:
redis 的 "快" 是相对于 mysql 来说快.
但是如果是直接和 内存中的操作变量 区去比(比如: 直接把键值对存到 HashMap 中), 那就慢很多了:
- 存 HashMap 属于内存中的数据操作, 直接在程序的内存空间中进行(这里是堆).
- 而 redis 是需要先经过网络, 再操作内存的.
- 因为 redis 是 客户端-服务器 程序, 因此 数据操作命令 是在客户端发起的, 那么这个命令就需要经过网络传输到达服务器, 服务器解析后, 再去内存中执行相应的数据操作, 执行完毕后, 操作结果还需要再经过网络传输回客户端, 客户端才收到响应结果.
2. Redis 应用场景

- 存储实时数据: 把 Redis 当做数据库使用. [对性能要求高的场景, 比如: 搜索引擎]
- 既然把 Redis 当做数据库, 那么就需要把所有的数据都 全量 的存储到 Redis 中, 因此就需要更大的内存空间(扩充硬件资源)
- 缓存存储 & 会话存储
- 缓存存储: Redis 用作缓存, 就是我们上篇文章提到的 "冷热分离", 把热点数据存到缓存(Redis)中.
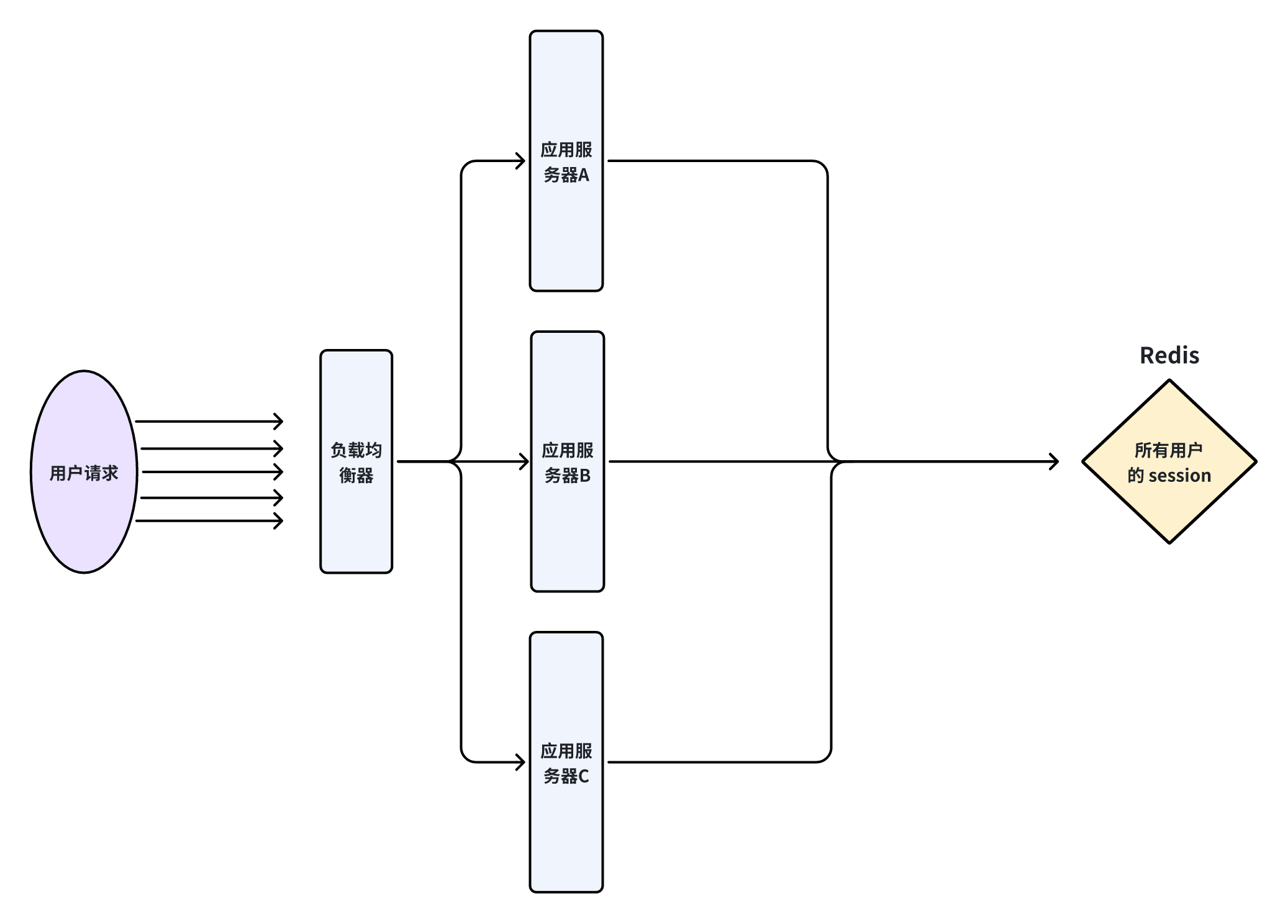
- 会话存储: Redis 用来保存应用服务器端的 session 信息.
- 背景: 在传统的服务器集群中, 如果将用户 session 保存在单个服务器的内存里, 会产生一个问题: 当负载均衡器将用户的后续请求分配到另一台服务器时, 新服务器无法识别用户的登录状态, 会导致用户需要重新登录.
- 解决办法:
- 想办法让负载均衡器把同一个用户的请求分配到同一个机器上.(可以根据 userId 进行分配)
- 把 session 从服务器中抽取出来, 存储到一个独立的服务器上(Redis). 哪怕应用服务器重启, session 数据也不会丢失.
- 用作消息队列, 实现一个生产者消费者模型(在分布式系统中, 服务器和服务器之间, 需要通过消息队列来 解耦合/削峰填谷). (这里说的 "消息队列" 是一个服务器, 就像 RabbitMQ/Kafka/RocketMQ 那些)
3. 安装 Redis
在 Linux Ubuntu 系统上安装 Redis.
redis 和 mysql 一样, 都是 客户端-服务器 结构的程序, 因此我们需要先安装 redis-server, 再通过 redis 客户端操作 redis.
- 首先使用 su 命令切换到 root 用户.
- 使用 apt 命令搜索 Redis 相关软件包.
apt search redis - 使用 apt 命令安装 Redis
apt insatll redis
此时, 我们已经安装好了 Redis, 使用 netstat 命令查看一下 Redis 网络状态.

发现, Redis 服务器 ip 为 127.0.0.1, 也就意味着这个 Redis 服务器只能由当前主机上的客户端访问, 跨主机就无法访问, 因此, 我们需要修改一下配置文件:
# 进入配置文件目录
cd /etc/redis/
使用 vim 命令编辑 redis.conf , 做出以下修改:
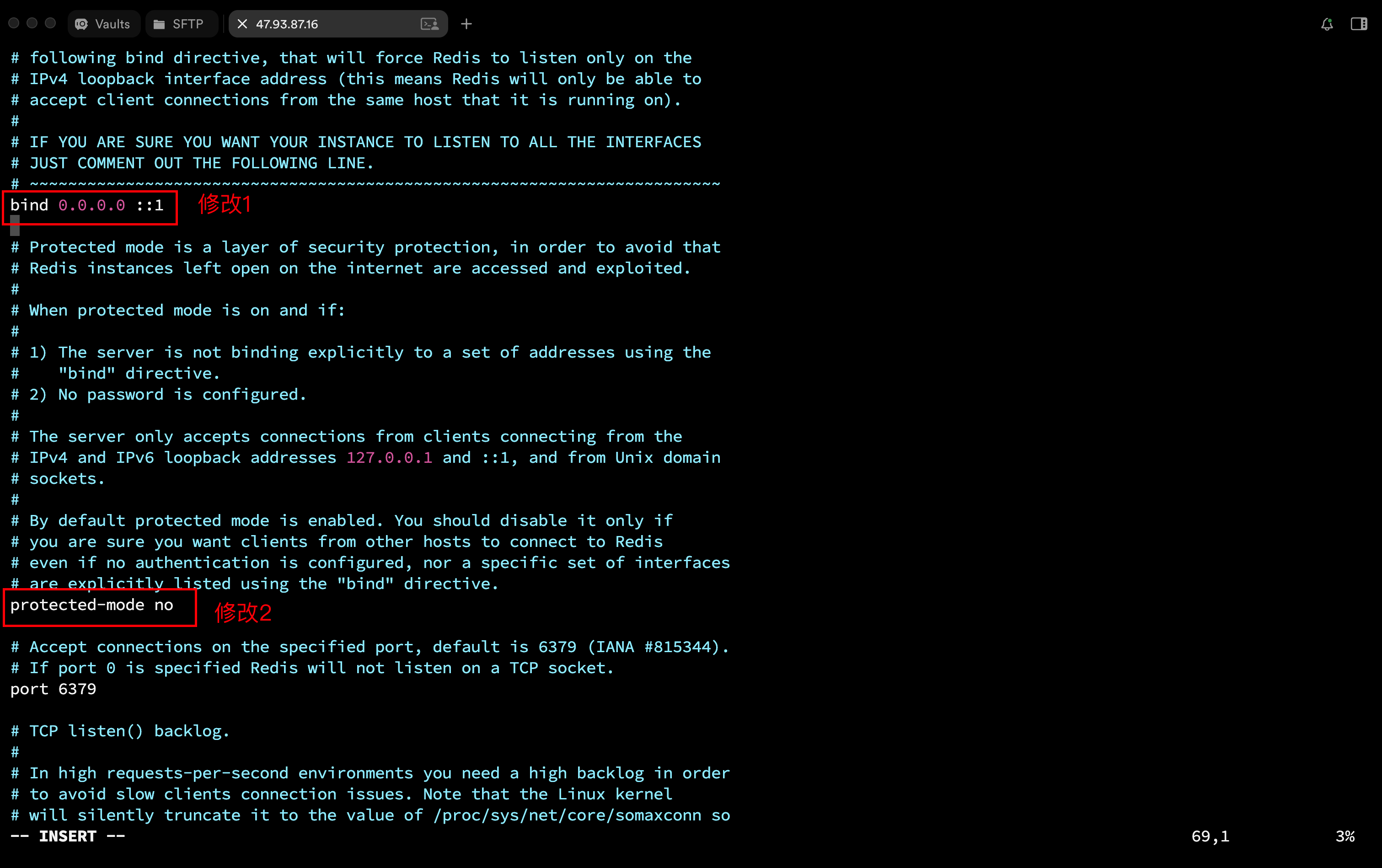
修改完配置后, 重启服务器让配置生效:
service redis-server restart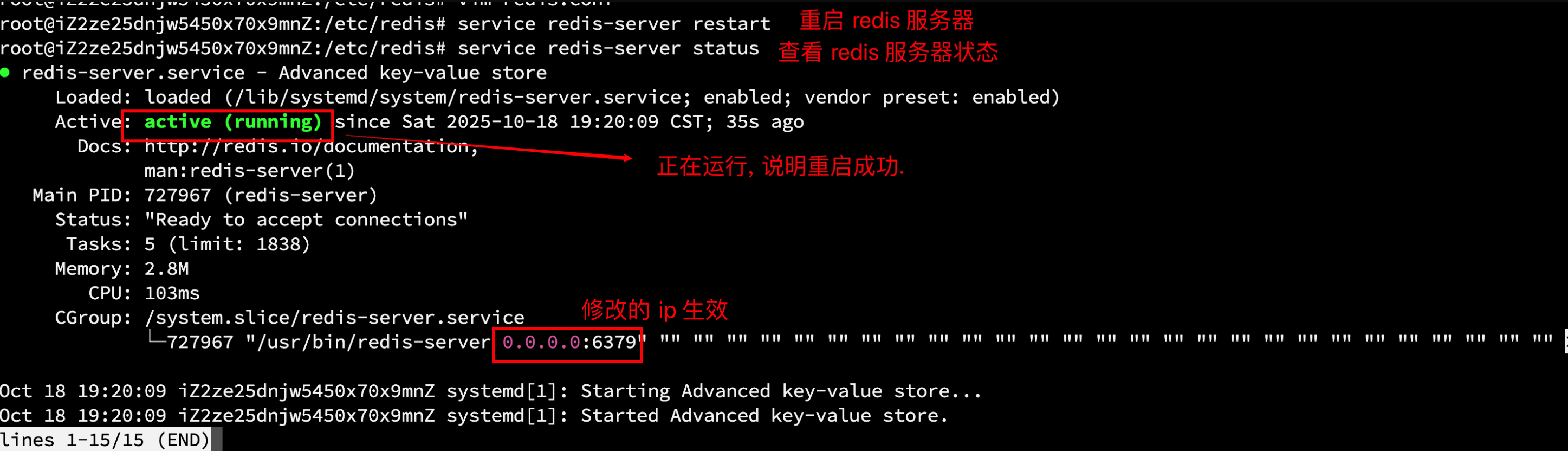
最后一步, 使用 redis 自带的客户端, 连接本机 redis 服务器:
redis-cli
也可以通过 redis-cli 连其他的 redis 服务器, 输入服务器对应 ip 和 port 即可:
redis-cli -h [IP] -p [端口]

检验: 输入 ping, 若出现 PONG 则说明连接成功

(使用 ctrl + d 退出 redis 客户端)
4. Redis 命令
4.1 set & get
get 和 set 是 Redis 中最核心的两个命令.
get 和 set 不是全局命令, 它们是专门针对 String 数据类型的命令. (也就是说, key 和 value 都是字符串, 但是不用手动加 引号, Redis 会自动加上)
- get: 根据 key 获取 value. (前面说过, Redis 是以 键值对 的形式存储数据的)
- set: 存储 key 和 value
其中, key 和 value 都是字符串.
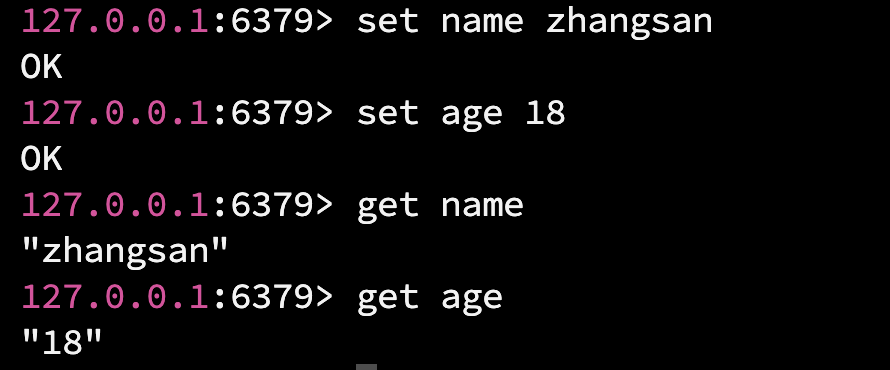
注意: Redis 中的命令, 不区分大小写, 但是存储的数据区分大小写.
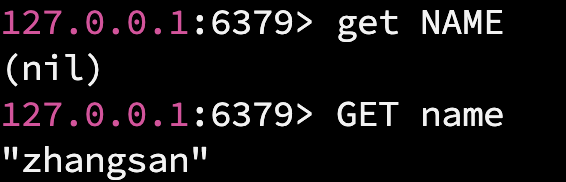
使用 get 根据 key 获取 value 时, 如果 key 不存在, 则返回 nil(如上图所示), nil 和 null/NULL/None 是一个意思.
4.2 全局命令/通用命令
之前提到, Redis 支持很多种数据结构, 比如: 字符串, 列表, 集合, 哈希....
在 Redis 中, 操作不同的数据结构, 使用的命令是不同的, 像上文的 get/set 就是操作字符串的专属命令.
但是, 而 全局命令, 可以操作所有数据结构.
4.2.1 keys
keys 是用来查询 Redis 服务器上所匹配的 key 的全局命令.
语法为: keys pattern
其中, pattern 是 包含特殊符号的字符串, 用来描述要查找的 key 的样式.
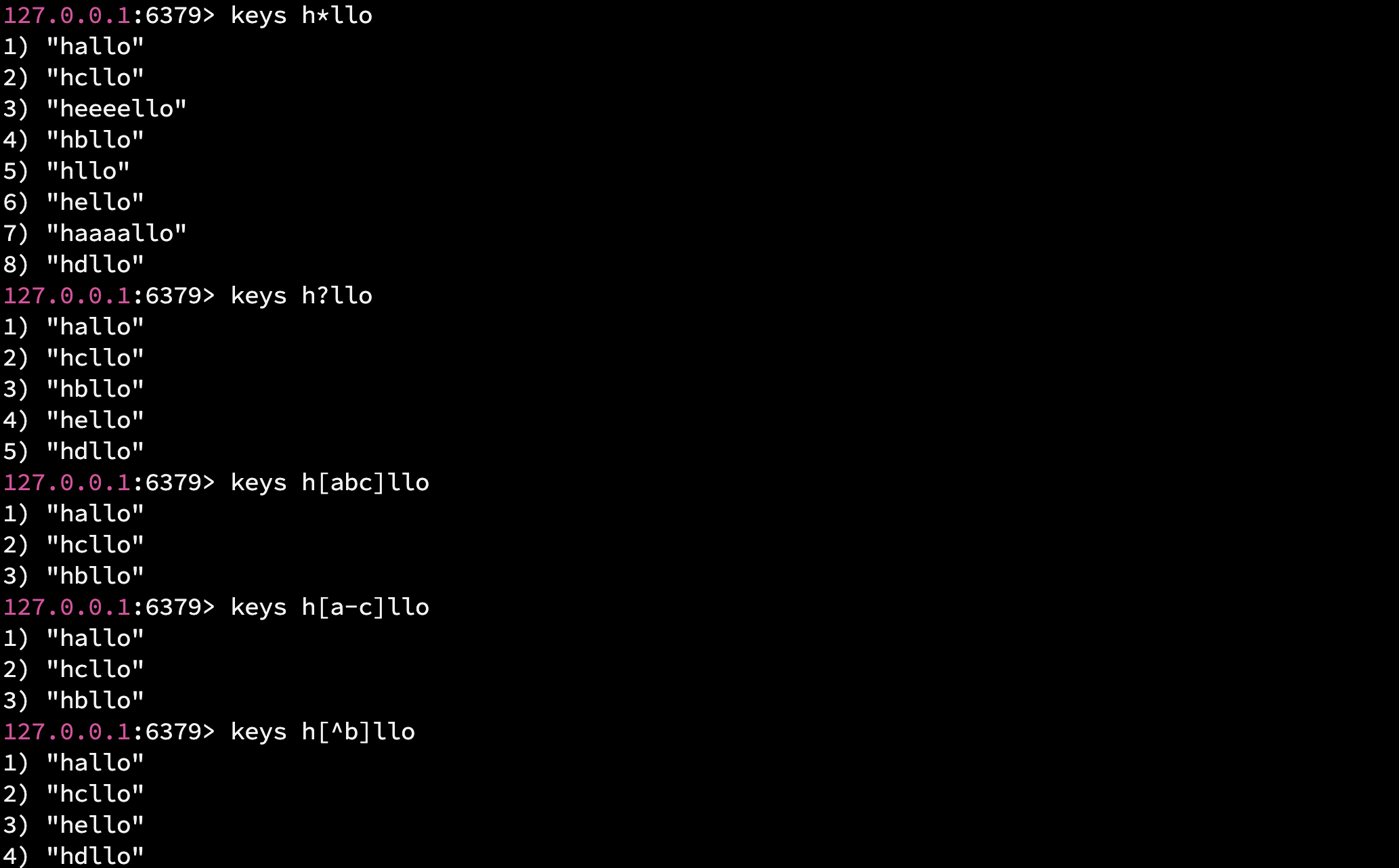
pattern 的使用如下:
- ? 匹配任意一个字符 => h?llo 匹配 hello/hallo/hbllo/...
- * 匹配 0 个或多个任意字符 => h*llo 匹配 hllo/heeeeello/haaaallo
- [abc] 只能匹配 a b c 其中一个字符 => h[abc]llo 匹配 hallo/hbllo/hcllo, 不匹配 habllo//hdllo
- [^e] 匹配任意一个不是 a 的单一字符 => h[^e]llo 不能匹配 hello
- [a-c] 匹配 a - c 范围内的任意一个字符(左闭右闭) => h[a-c]llo 匹配 hallo/hbllo/hcllo
注意:
keys 是从服务器中一个一个的找有没有符合条件的 key 的, 因此时间复杂度为 O(N).
在生产环境中, key 是非常多的, 而 Redis 是一个单线程服务器, 执行 keys 的时间就会非常长, Redis 服务器就会处于阻塞状态, 也就无法给其他 Redis 客户端提供服务了. 这是一个非常严重的事情!!
因此, 在生产环境中, 一般会禁用 keys 命令, 尤其是 keys *(查询 Redis 上的所有 key)
4.2.2 exists
exists 命令用于判断 key 是否存在(可以一次查一个或者多个 key).
语法: exists key1 [key2 ...]
返回值: 返回 key 存在的个数. 时间复杂度为 O(1)
注意: Redis 是用哈希表来管理所有的 key 的, 因此时间复杂度为 O(1). 正因如此, Redis 中的 key 是唯一的, 如果存入了重复的 key, 那么新的 value 会覆盖旧的 value.
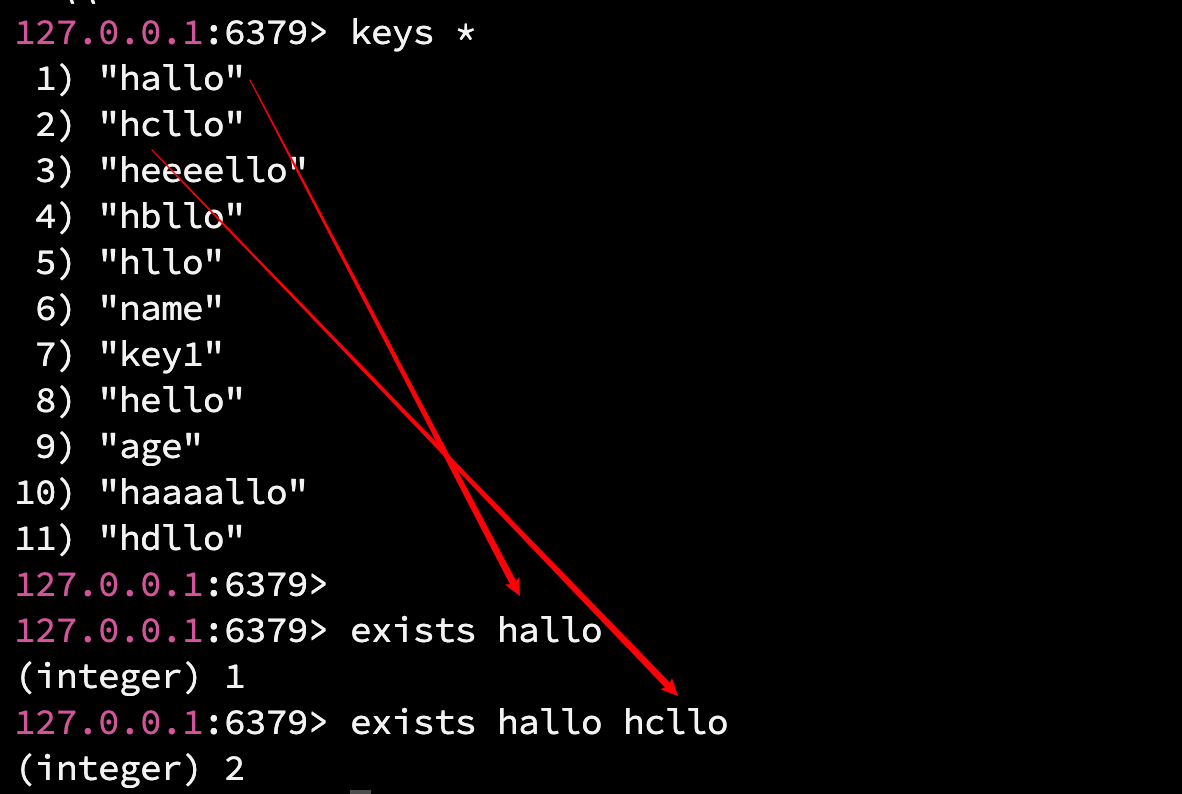
注意:
一次的 exists hallo hcllo(一次网络 IO)是比单独的一次的 exists hallo 加上单独的一次的 exists hcllo 效率要高的(两次网络 IO).
因为 Redis 是客户端-服务器结构的程序, 客户端和服务器之前是通过网络来通信的.
4.2.3 del
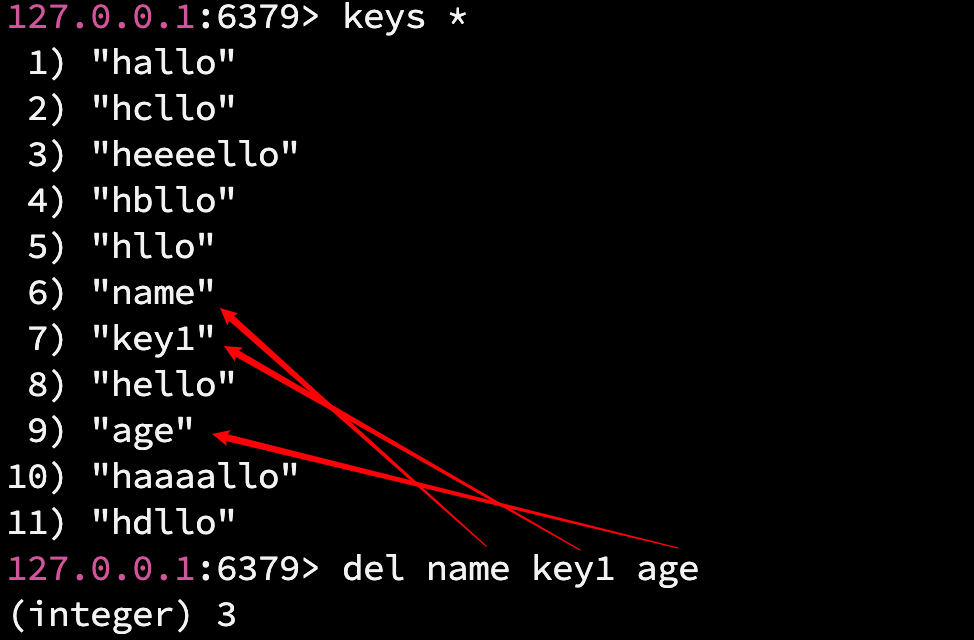
del 命令用于删除某个键值对(可以一次删除一个或多个 key).
语法: del key1 [key2 ...]
返回值: 删除掉的 key 的个数.
时间复杂度: O(1)
4.2.4 expire
expire 是给指定的 key 设置过期时间, 单位为 秒, 到期后 key 就会自动被删除. (如果想设置毫秒, 使用 pexpire)
语法: expire key seconds
返回值: 设置成功返回 1, 设置失败返回 0 (如果 key 不存在, 就会返回 0)
时间复杂度: O(1)
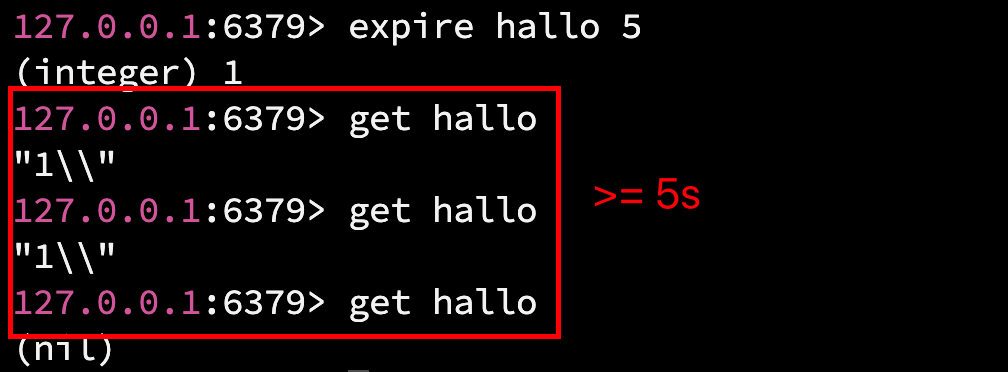
expire 有很多的使用场景, 比如:
- 手机验证码: 超过指定时间后, 服务器从 Redis 中就查不到这个值了, 就会判定用户验证失败.
- 外卖平台优惠券有效时间
- 基于 Redis 实现分布式锁: 在分布式系统中, 是针对不同的服务器加锁, 当一个服务器获取锁后, 若这个服务器突然挂机, 那么这把锁就无法被释放, 其他服务器就无法获取该锁. 为避免上述情况, 就会在加锁的时候设置一下锁的过期时间, 到期后锁就会自动释放. (基于 Redis 实现分布式锁, 就是在 Redis 中写入一个特殊的 key-value, 给这个 key 设置一个超时时间, 到期后这个 key 就会自动被删除, 也就释放锁了)
4.2.5 ttl
ttl(time to live), 查看 key 剩余的过期时间(秒), (key 还有多久过期), 通常和 expire 搭配使用.
语法: ttl key
返回值: 剩余过期时间, -1 表示这个 key 没有设置过期时间(秒), -2 表示 key 不存在.
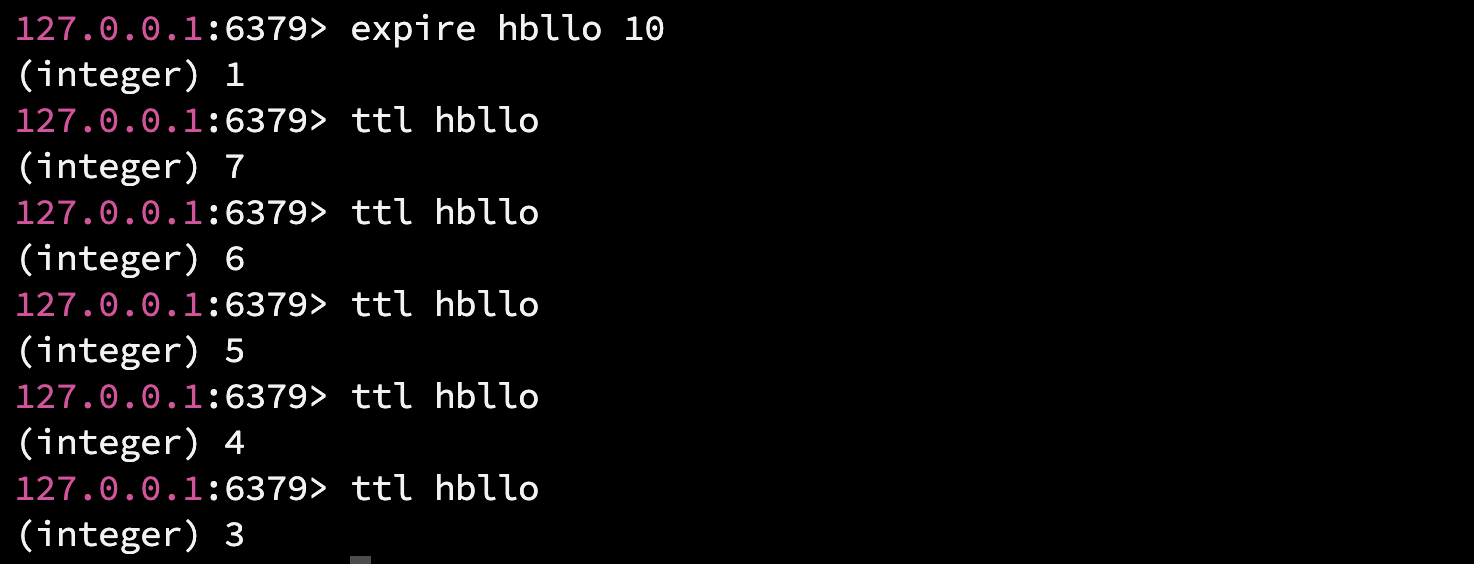
若查看剩余的毫秒, 使用 pttl
4.2.6 type
type 用来查询 key 对应的 value 的数据类型.
语法: type key
返回值: value 的数据类型. 常见的类型有:
- none: key 不存在
- string: 字符串
- list: 列表
- hash: 哈希
- set: 集合
- zset: 有序集合
- stream: Redis 作为消息队列时, 才使用这个类型的 value
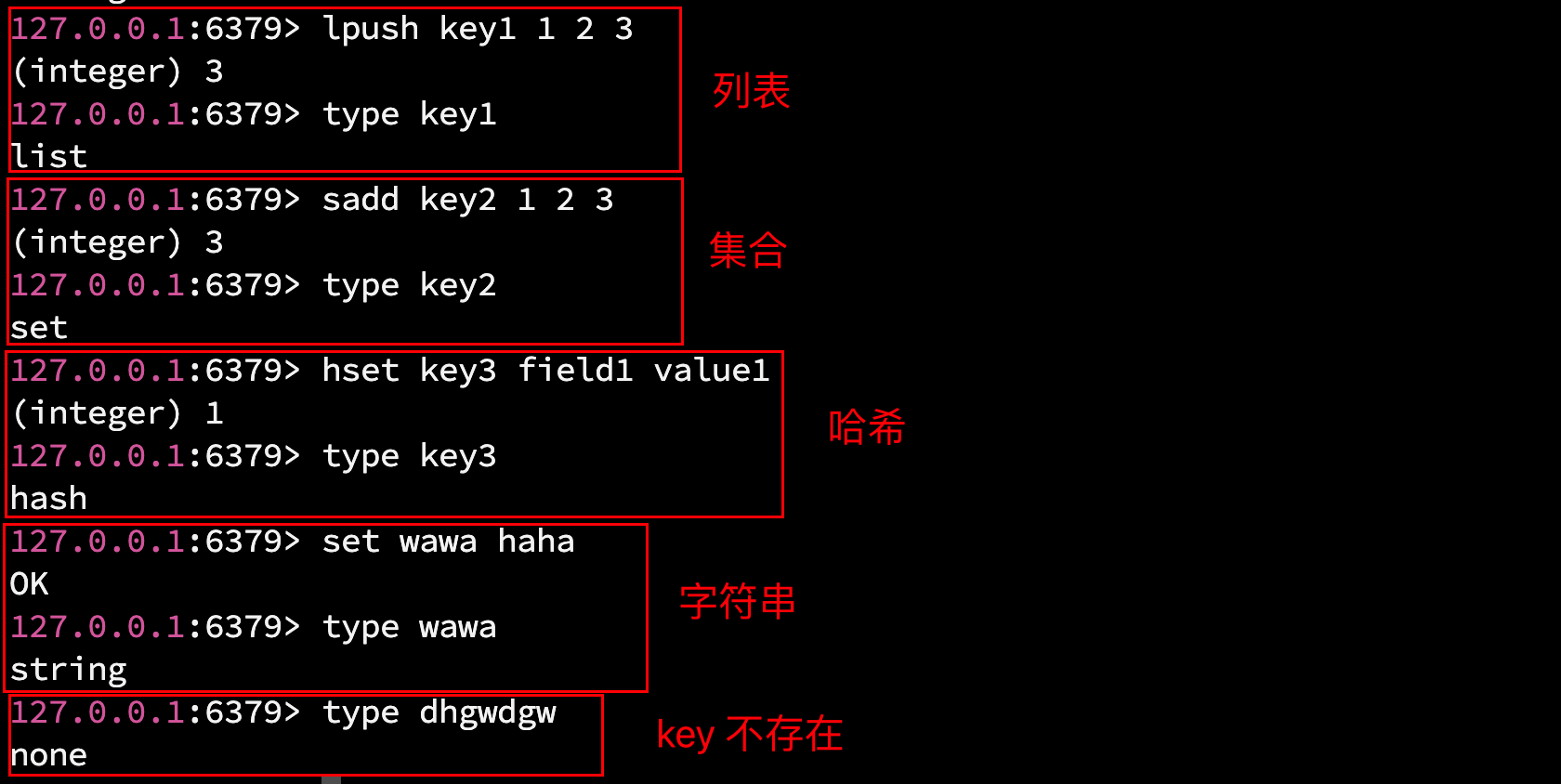
注: Redis 中, key 对应的 value 可能存在多种类型, 不同类型对应的命令不同, 因此要使用某个 value 时, 可以先用 type 查一下类型, 再使用对应的命令去操作.
5. Redis 过期策略 [经典面试题]
一个 Redis 服务器中, 可能存在存在非常多的 key, 那 Redis 是怎样判断哪些 key 过期了, 那哪些 key 没有过期呢? 如果是一个一个遍历, 那么时间复杂度为 O(N), 效率很低.
Redis 采取的是 "惰性删除" 和 "定期删除" 结合的策略:
- 惰性删除: 假设某个 key 已经到期了, 但是 Redis 没有主动的删除他, 而是当用户后续请求访问这个 key 时, Redis 才发现他已经过期了, 于是这次访问触发了 Redis 对这个 key 的删除操作, 同时给这次请求返回一个 nil
- 定期删除: 每隔一段时间, 抽取一部分的 key, 验证他们的过期时间, 如果过期就删除. (因为 Redis 中存的 key 是很多的, 如果检查所有的 key , 那么效率是很低的, 因此就通过控制抽取 key 的数量, 来约束消耗的时间. )
为啥要定期删除:
因为 Redis 是单线程的程序, 主要的任务(处理每个命令, 如: get set/扫描过期 key)都是在一个线程中完成的, 如果扫描过期 key 消耗的时间太多, 那么就会导致 处理正常请求的命令(上面的各种 get/set/...) 被阻塞, 用户看起来就像 Redis 挂了一样. (会产生类似 keys * 的效果)
虽然 Redis 采取的是 惰性删除 和 定期删除 结合的策略, 但是效果一般, 仍然会存在很多过期 key 残留的情况, 因此, Redis 还采取了 内存淘汰策略.
注意: 除了上述的策略外, 网上还流传 "定时删除" (给 key 创建定时器, 时间到了就删除)的策略, 但实际上, Redis 并没有采取这种方式.
6. [拓展] 通过定时器实现 Redis 过期策略
定时器: 当约定的时间到达后, 就执行某个任务.
在 Redis 这里, 就是到达 key 的过期时间后, 删除这个 key.
实现方式有两种:
- 优先级队列/堆
- 时间轮
注意: Redis 并没有采取这两种方式, 仅为拓展.
6.1 基于优先级队列/堆
根据 key 的过期时间, 定义优先级规则: 把过期时间早的 key, 放到堆顶, 也就是最先出队列.
分配一个线程, 去检查堆顶元素的剩余过期时间, 如果堆顶元素到达过期时间了, 就把堆顶元素移除. 此时, 这个线程只需关注堆顶元素即可, 如果堆顶元素都还没有过期, 那么其他元素也一定没有过期.
注意: 检查堆顶元素的操作, 不能检查的太频繁, 如果以循环的方式去检查, 那么就类似 "忙等", 会一直消耗 CPU 资源. 那么, 可以根据当前时刻 和 堆顶元素的过期时间, 给线程设置一个等待, 当 堆顶元素 快要过期时, 再去唤醒这个线程. (比如: 堆顶元素 12 点过期, 现在是 11 点, 那么就让线程休眠 1h, 1h 后再唤醒这个线程)
如果在线程休眠的过程中, 来了一个新的 key(可能比当前堆顶元素更提前执行), 那么就可以在添加元素的时候, 唤醒线程, 根据时间差距再重新设置一下阻塞时间.
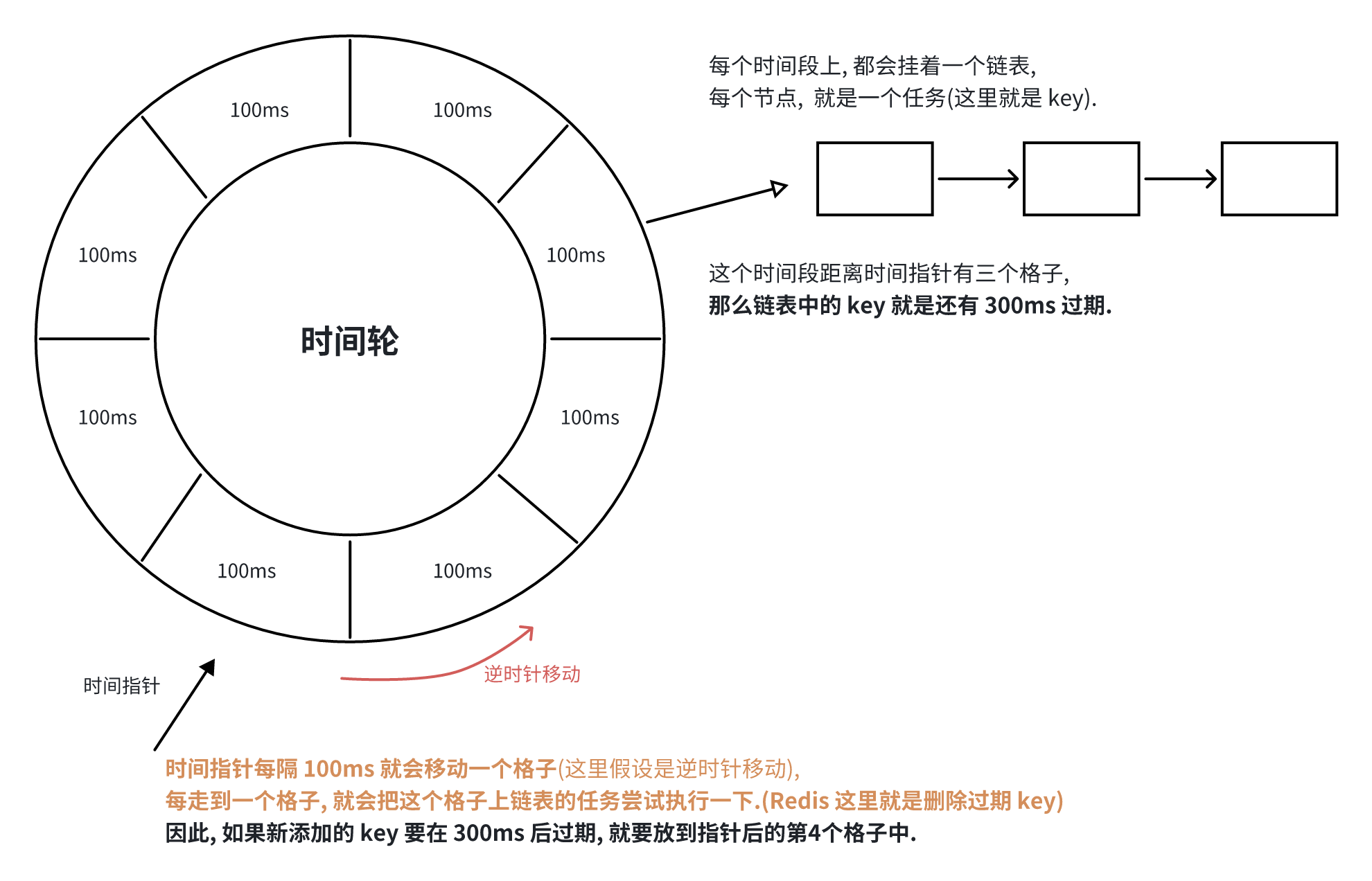
6.2 基于时间轮
时间轮, 就是把时间分成很多时间段.(每小段时间的粒度, 根据实际需求调整)
有一个时间指针, 这个时间指针每隔一个时间段, 就会移动一下, 并且执行对应格式上的任务.
END