DeepSeek-OCR可能成为开启新时代的钥匙
概述
前天,DeepSeek 发了一篇 DeepSeek-OCR 工作[1],并开源了模型和代码[2]。
这里的 OCR 指的是广义的 OCR,狭义的 OCR 往往是指文本检测和识别,而这里是指文档解析任务,即它能把一个完整 PDF 解析成 Markdown 格式。
我们之前仔细看过 MinerU 2.5 和 PaddleOCR-VL 之类的文档解析模型,和这些模型相比,DeepSeek-OCR 的性能如何呢?
答案是,无可奉告。
因为 DeepSeek-OCR 的卖点不是性能,而是视觉Token的压缩,因此,在性能基准比较中,它没有和最新的 SOTA 模型进行比较。
什么是视觉Token压缩?
在做文档解析任务时,需要利用视觉编码器,把图像编码成视觉Token,这样才能让语言模型理解。视觉Token压缩就是指可以用更少的视觉Token来表示图像的完整信息,有效降低语言模型的上下文长度。
DeepSeek-OCR 的视觉压缩到一个什么水平?先看看摘要里的结论:
- 压缩比<10:可实现 97% 的OCR准确率
- 压缩比=20:可实现 60% 的OCR准确率
下面这张图能够更直观地看出 DeepSeek-OCR 的整体情况。
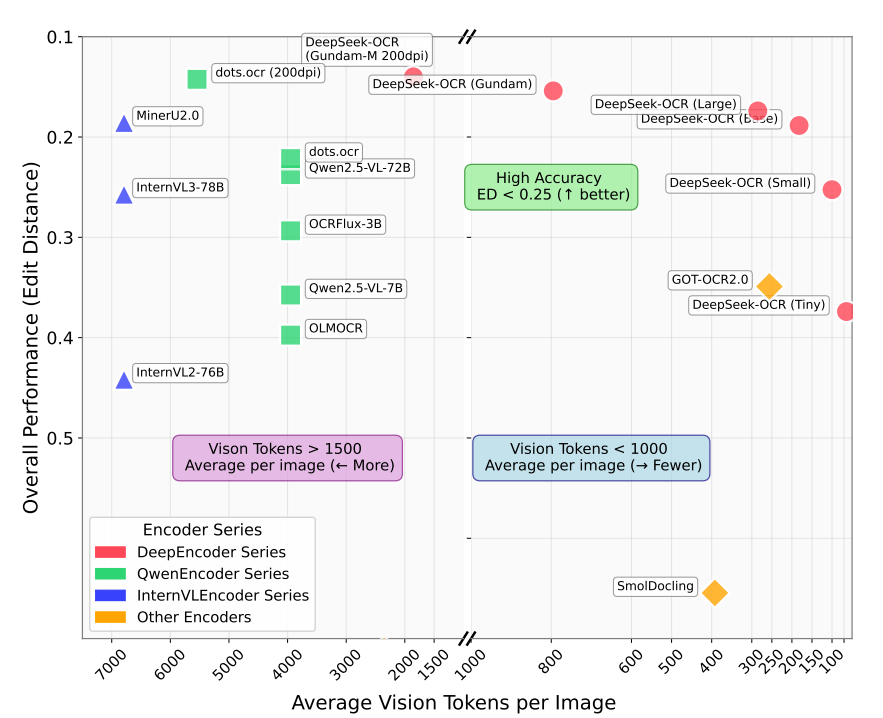
横轴是每张图平均视觉Token,越往右表示tokens越小,压缩程度更高;
纵轴是不同模型的编辑距离,越往上表示编辑距离越小,模型性能越好;
主流模型的平均视觉 Token 往往在 4000 这条线以上,而 DeepSeek-OCR 的全系列模型基本都在 2000 这条线以下。
更大的压缩比势必造成精度损失,从图中的结果看,Base型号的这个模型,平均视觉Token在300附近,精度损失没有特别高,在可接受的范围内,如果拿这个模型去做对比,能把视觉Token 压缩了 10 倍还不止。
了解完这项工作的意义,下面就来具体看看,它是怎么做到的。
动机
当前的大型语言模型在处理长文本内容时,基本上采用自注意力(Self-Attention)的操作,即每个 token 都要和序列中其他所有 token 计算相似度得分。
注意力计算复杂度为 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d),n是指序列长度,d是指每个 token 的向量维度。
因此,随着序列长度增加,复杂度会二次方的形式上升。
作者提出的一个思路是:既然文本所占用的Token这么多,那么用视觉信息来表示文本信息(比如对一段文本截图),同样能表示相同的信息,但所需的Token可以更少。
为了验证这个理论,作者把OCR任务当作试验场景,提出了 DeepSeek-OCR。
现有视觉编码器的缺陷
主流的视觉语言模型往往采用以下三种类型:
1.以Vary为代表的双塔架构
通过并行SAM编码器增加视觉词汇参数量以处理高分辨率图像。
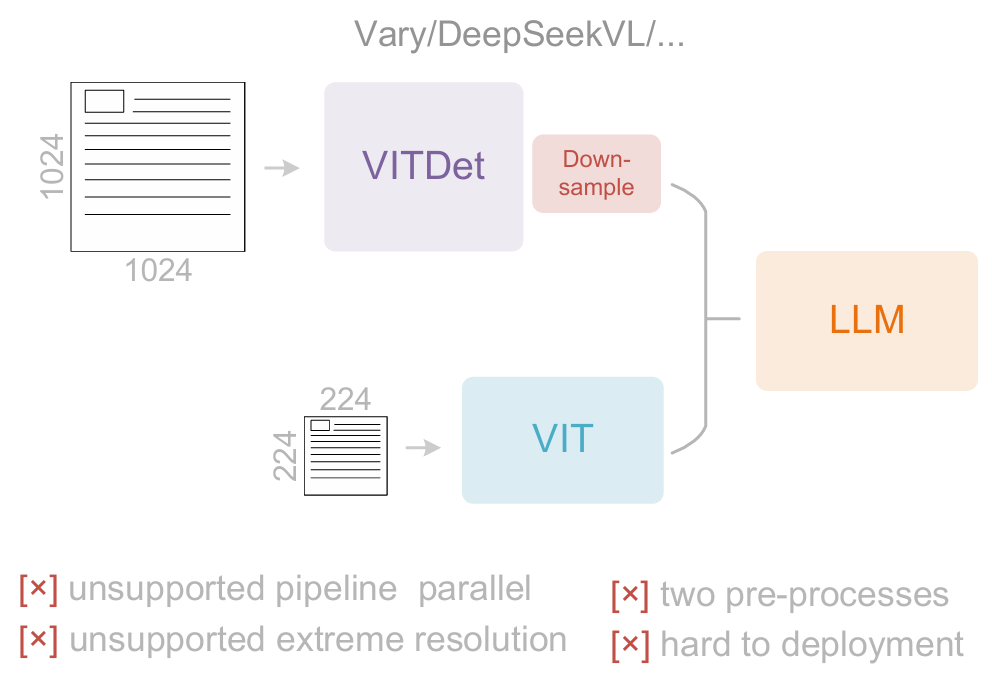
这种方案的缺陷是:需要双重图像预处理使部署复杂化,且在训练时难以实现编码器流水线并行。
2.以InternVL2.0为代表的基于图像分块的方法
将图像分割为小块进行并行计算,从而降低高分辨率下的激活内存。
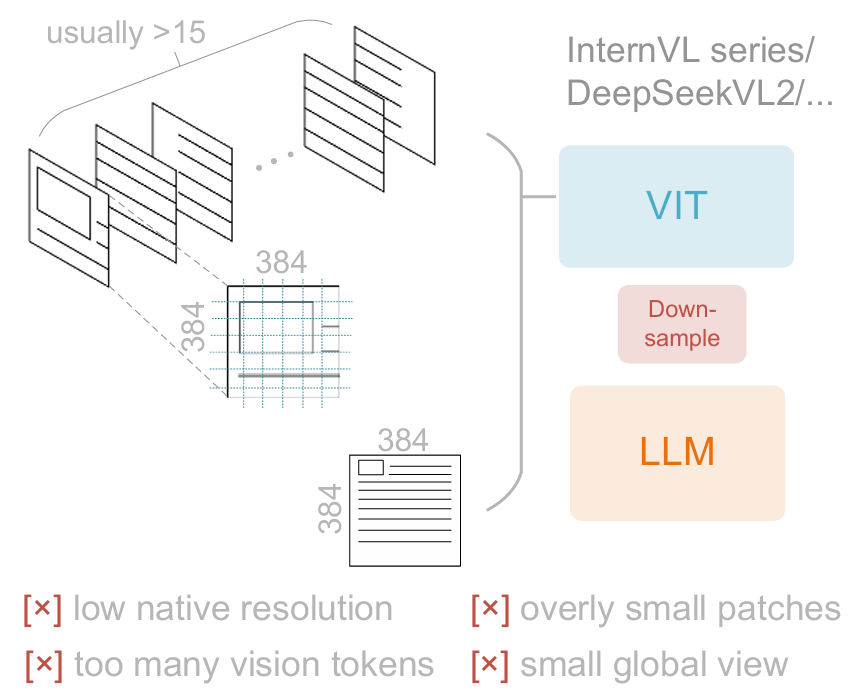
尽管能处理极高分辨率,但由于原生编码器分辨率通常较低(低于512×512),大尺寸图像会被过度分割产生大量视觉标记,存在局限性。
3.以Qwen2-VL为代表的自适应分辨率编码
采用NaViT直接通过基于图像块的分割处理完整图像,无需分块并行,能灵活适应不同分辨率。
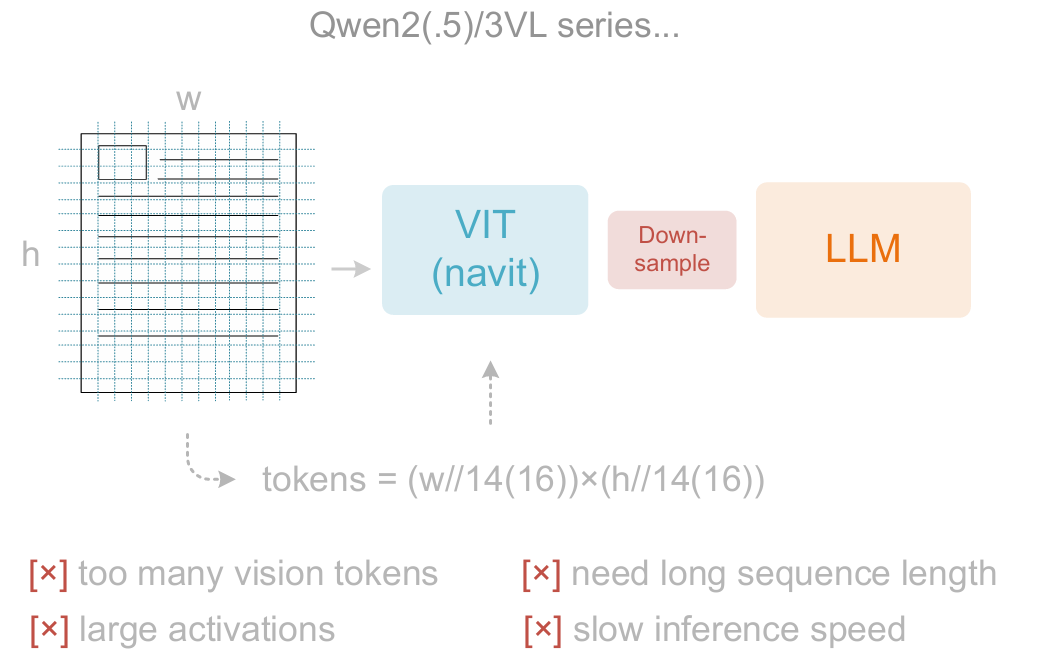
但大量激活内存消耗可能导致GPU内存溢出,且训练时序列打包需要极长的序列长度。过长的视觉标记会同时拖慢推理的预填充和生成阶段。
DeepSeek-OCR 架构
这些视觉编码器都有缺陷,那么 DeepSeek-OCR 是怎么做的呢?
下图展现了 DeepSeek-OCR 架构,中间是 DeepSeek 提出的图像编码器 DeepEncoder,后面加了一个 DeepSeek-3B-MoE 解码器。
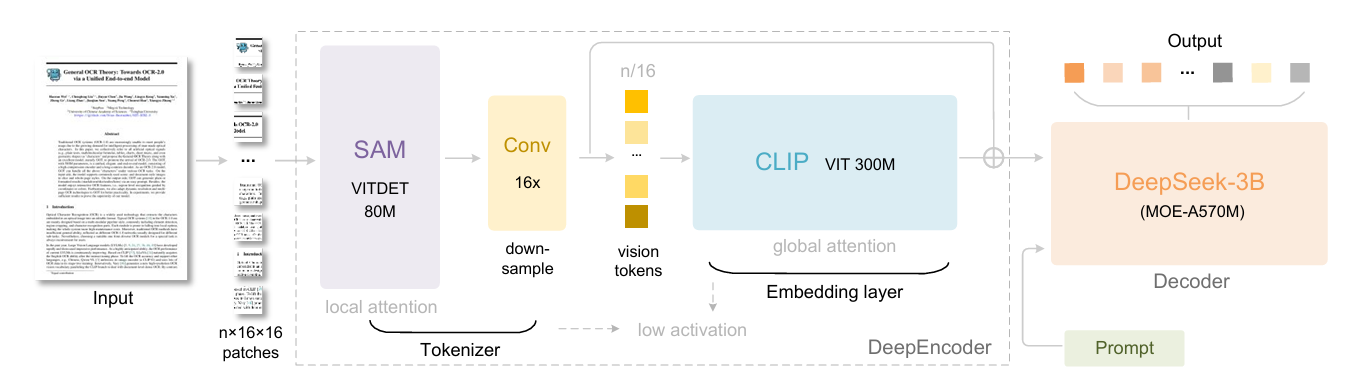
DeepEncoder 的设计是有迹可循的,总体分三部分:
- SAM-base:这个是 SAM 的编码器,SAM 做的是分割任务,它本身就具备强大结构理解能力
- Conv:借鉴 Vary 的设计,采用 2个卷积层的模块对视觉token进行 16 倍下采样,实现信息压缩
- CLIP:CLIP 具备强大的视觉-语言对齐能力,用 CLIP 进行二次编码,方便后面的语言模型理解
因此,总体思路是,先用 SAM 去尽可能精细提取特征信息,然后用卷积压缩,最后用 CLIP 去做翻译。
所以,DeepEncoder 并不是它本身有多强,而是它把 SAM 和 CLIP 两个“高手”串在了一块。
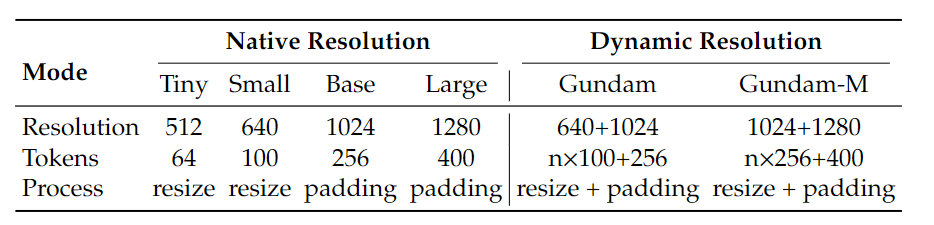
为了适配不同分辨率的图像输入,DeepEncoder 又推出了不同的固定分辨率型号和动态分辨率型号,具体参数如下表所示。
DeepSeek-OCR 最后的解码器 DeepSeek-3B-MoE 倒没什么特色,是一个基本语言模型的缩小版。
DeepSeek-OCR 性能评估
作者在 OmniDocBench 基准上进行了性能评估,采用编辑距离来度量性能,数值越小越好。
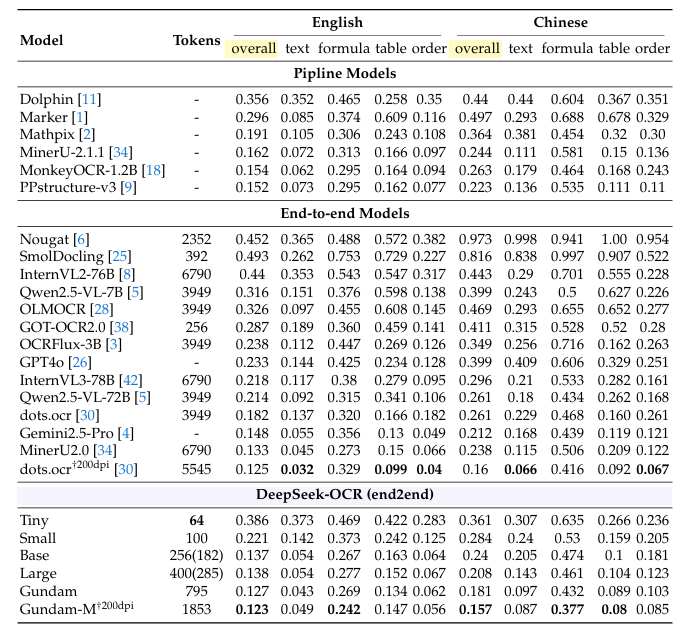
这里的对比结果和开头提到的可视化图是一致的,前面已经大致分析过,这里不作重复赘述。
当然,我们不要忘了 DeepSeek-OCR 的核心目标是想让视觉Token来替代文本Token,以实现压缩,下表展现了不同文本Tokens和视觉Token所对应的准确率和压缩比。
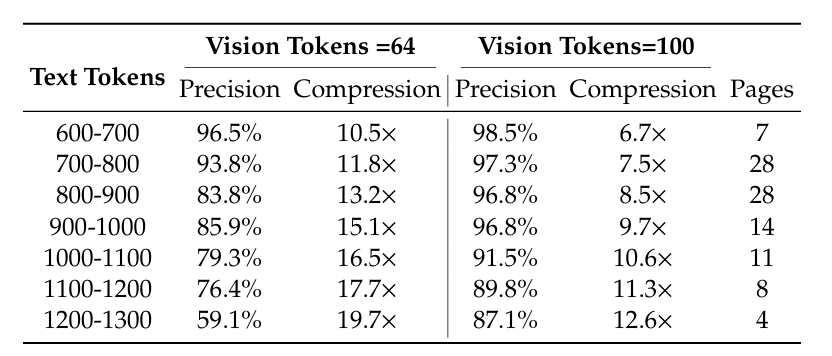
假设以90%的精度作为及格线(即认为通过压缩所造成的10%的精度损失可以忽略不计),那么:
- 64 个视觉Tokens 可以等效 700-800 个文本Tokens
- 100 个视觉Tokens 可以等效 1000-1100 个文本Tokens
以这个尺度进行估算,压缩率在1/10左右。
讨论
在这一节,作者进一步解释了为什么设置Tiny、Small、Gundam等不同分辨率的编码器。
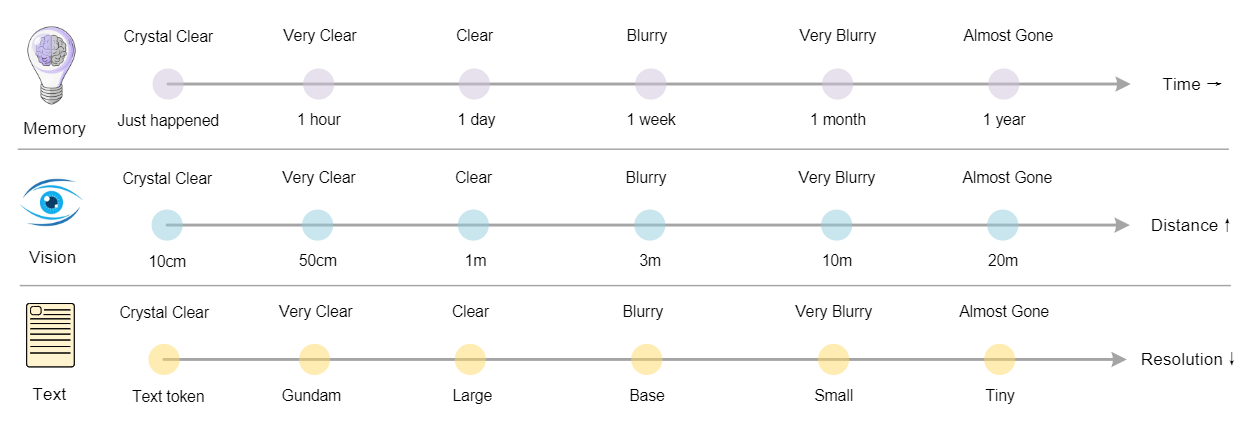
遗忘机制是人类记忆最基本的特征之一,随着时间慢慢边长,越久远的记忆会越模糊。
类比于视觉,越远端的内容应该用更小的分辨率去编码(看得会模糊),越近端的内容则用更大的分辨率去编码(看清更多细节)。
AI 的起源就是对人体大脑结构的模型,这段直接用仿生学去解释这种设计的合理性,真是绝了。
如果这套范式被主流的语言模型采用,会出现的一个结果就是无限上下文!
现在的很多Agent,当历史内容快要超过模型上下文窗口时,就会去进行一个历史内容压缩,生成摘要。
如果是视觉模式,整个流程就是完全动态的,每进行一轮新的对话,历史内容就会被重新压缩,越古老的压缩得越狠,直到完全看不清,这就是无限上下文的设计模式。
当然,目前这篇文章也只是提出了这个构想,实际做起来肯定还有无数问题需要验证和解决。
总结
现在再回头看这篇文章,会觉得它只是一个文档解析的工作吗?
当然不是,因为文档解析所需要输入的提示Prompt基本是固定的,所以解码器能做的比较小,DeepSeek-OCR 刚好看中了这块容易验证的领域,来对视觉Token压缩的设想进行验证。
当我和同门讨论这篇工作时,他说,他几年前刚学人工智能时,就有个疑问:“为什么要用语言来推动视觉,而不是视觉驱动语言?我们用眼睛看东西,输入的是视觉信号,文本只是图像被大脑过滤之后形成的信息。”
文本比图像更易存储和传播,因此具备先发优势,能更快地搜集并应用于大规模模型训练。
然而,这条路线是对的吗?DeepSeek-OCR 把这个问题再一次摆到了所有人面前。
文本是一维的,图像是二维的,图像比文本天然带有更多信息,比如,一张人物关系图,用文本需要描述半天,而图片用简单了连线就能表达清楚。
制约研究者用文本而不用图像的另一个重要原因是,如果把图像中每一个像素点作为一个Token,显然视觉Token会比文本Token的长度大很多。
但是现在,DeepSeek-OCR 得到一个结论:相同信息下,视觉Token可以做到比文本Token更少。
如果这点可以被推而广之,就没理由不用图像作为首选的信息输入。
所以我说,DeepSeek-OCR可能成为开启新时代的钥匙。
在未来,输入的所有文本,可能会被当做图像,然后再交给模型处理。
这样不仅成本低,且高效。
参考
[1] 论文地址:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
[2] github仓库:https://github.com/deepseek-ai/DeepSeek-OCR