技术面:Spring(循环依赖,spring与springboot的区别)
Spring的循环依赖
循环依赖是指在使用Spring框架的过程中,两个或多个Bean之间在初始化的过程相互依赖,形成一个依赖闭环,导致容器无法顺利完成Bean的创建和注入,从而可能引发启动失败或运行异常。
@Service
public class ServiceA {@Autowiredprivate ServiceB serviceB;
}@Service
public class ServiceB {@Autowiredprivate ServiceA serviceA;
}
在上面这段代码中:
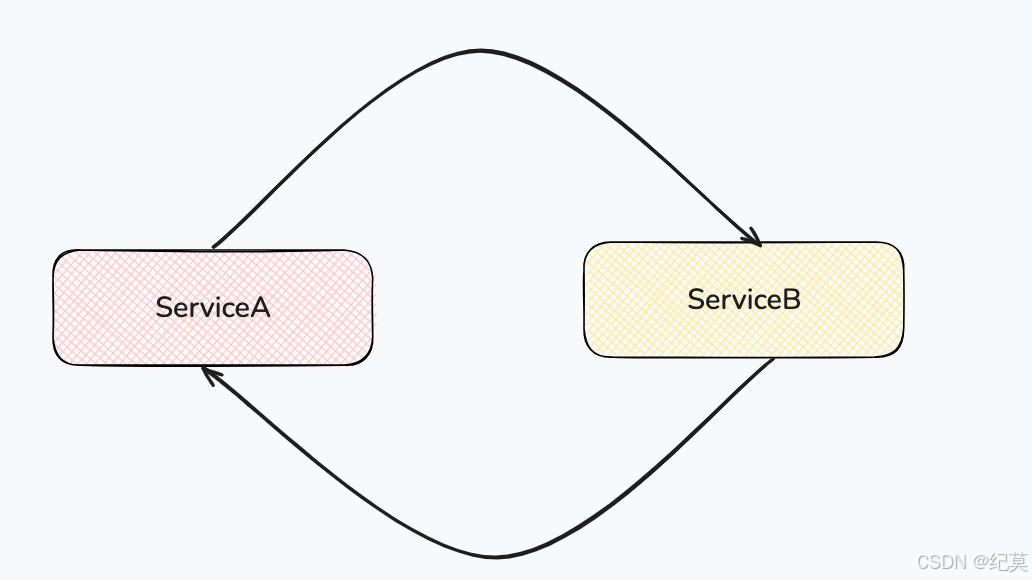
类 ServiceA 的实例需要注入 ServiceB 的实例。
类 ServiceB 的实例又需要注入 ServiceA 的实例。
这就形成了一个 ServiceA → ServiceB → ServiceA 的循环依赖。
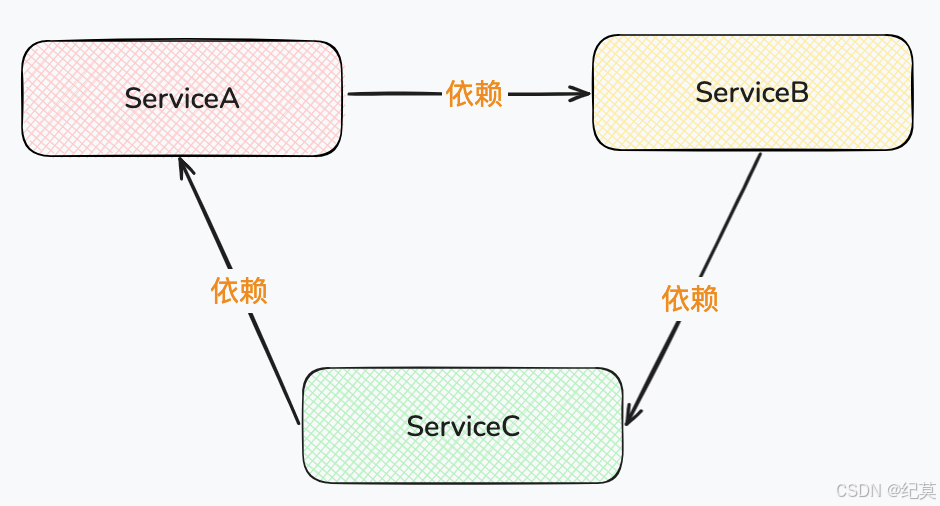
当然大于两个的类也可能存在循环依赖,例如:A→ B→ C→ A
如何解决循环依赖
在Spring中解决循环依赖也是有一定限制的。
- 循环依赖的Bean都是单例模式的Bean。
- 依赖注入的方式不能都是构造函数注入的方式。
Spring解决循环依赖为什么只支持单例模式的Bean
从本质上来说Spring解决循环依赖的方式是通过提前暴露未初始化完成的Bean来解决循环依赖的,这个尚未初始化完成的Bean是个半成品的Bean,就是未了解决循环依赖才提前放到缓存中的。
在Spring容器中,单例Bean的创建和初始化只会发生一次,而且是在容器启动的时候就完成的。这就说明在整个容器运行期间,单例Bean的依赖关系不会再发生变化,因此可以在容器启动的时候,通过提前暴露半成品的Bean来一次性解决单例Bean循环依赖的问题。
而由于原型模式(property)的Bean或Session模型下的Bean,创建和初始化会发生多次,并且是在Spring容器运行期间动态的发生变化,因此提前暴露半成品的Bean并不能解决循环依赖的问题,因为在后续的创建过程中,可能会涉及到多个不同的原型Bean,这就无法像单例Bean那样缓存并复用半成品对象。
所以Spring只能自动解决单例Bean的循环依赖。
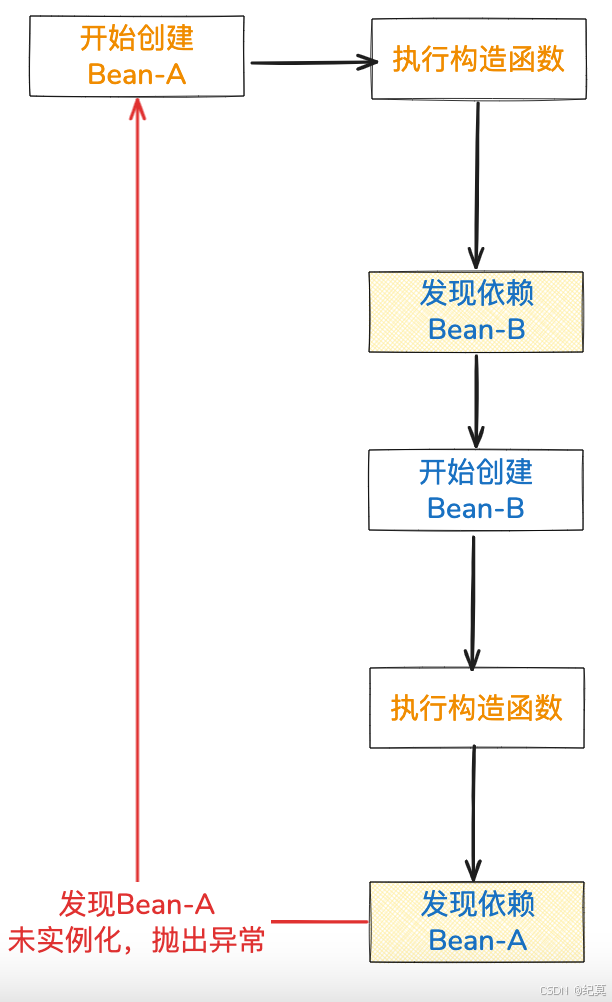
Spring为什么不支持自动解决构造函数的循环依赖
这个也很好理解,因为在整个Bean的实例化的过程中,是先执行构造函数,只有执行了构造函数后,才算是在堆内存中分配了内存,后面再填充属性,内存地址也不会有变化了。但是如果连构造函数都执行不成功,那这个Bean就连个半成品都不算,所以spring无法解决这种循环依赖。
解决这种构造函数的循环依赖有多种方式
- 重新设计,从代码层面就把循环依赖给杜绝掉,彻底避免循环依赖。
- 改成非构造函数依赖,可以采用setter注入或属性注入
- 使用
@Lazy注解解决:使用@Lazy注解时,Spring容器会在实际需要该Bean的时候才会进行实例化,而不是在容器启动的时候进行实例化。这样如果两个Bean存在循环依赖,可以使用这种延迟实例化,从而避免在容器启动时触发循环依赖,但并未真正解决循环依赖本身。
Spring三级缓存
Spring三级缓存是什么?
在Spring框架中,BeanFactory是IOC的基础接口,其中DefaultSingletonBeanRegistry类实现了BeanFactory接口,并维护了三个Map,用来做Bean创建时的三级缓存。

这三级缓存的介绍
- 一级缓存,
singletonObjects单例缓存- 类型:ConcurrentHashMap<String, Object>
- 作用:存放完全初始化完成的单例Bean实例。
- 说明:这是最终的单例池,所有已经创建并装配好的Bean都会放在这里,供后续直接获取使用。
- 二级缓存:
earlySingletonObjects- 类型:ConcurrentHashMap<String, Object>
- 作用:存放早期暴露的Bean实例(原始对象,尚未完成属性注入和初始化,半成品)。
- 当一个Bean正在创建中,但还未完成所有初始化步骤时,可以提前暴露一个“半成品”对象,放入此缓存,供其他Bean引用,从而打破循环依赖。
- 三级缓存:
singletonFactories- 类型:ConcurrentHashMap<String, ObjectFactory<?>>
- 作用:存放能够创建早期Bean实例的工厂对象(
ObjectFactory)。 - 它并不直接存储Bean实例,而是存储一个lambda或匿名内部类,用于在需要时生成早期暴露的对象。这允许Spring在暴露早期对象的同时,还能应用一些后置处理器(如AOP代理)。
Spring三级缓存是怎么解决循环依赖的?
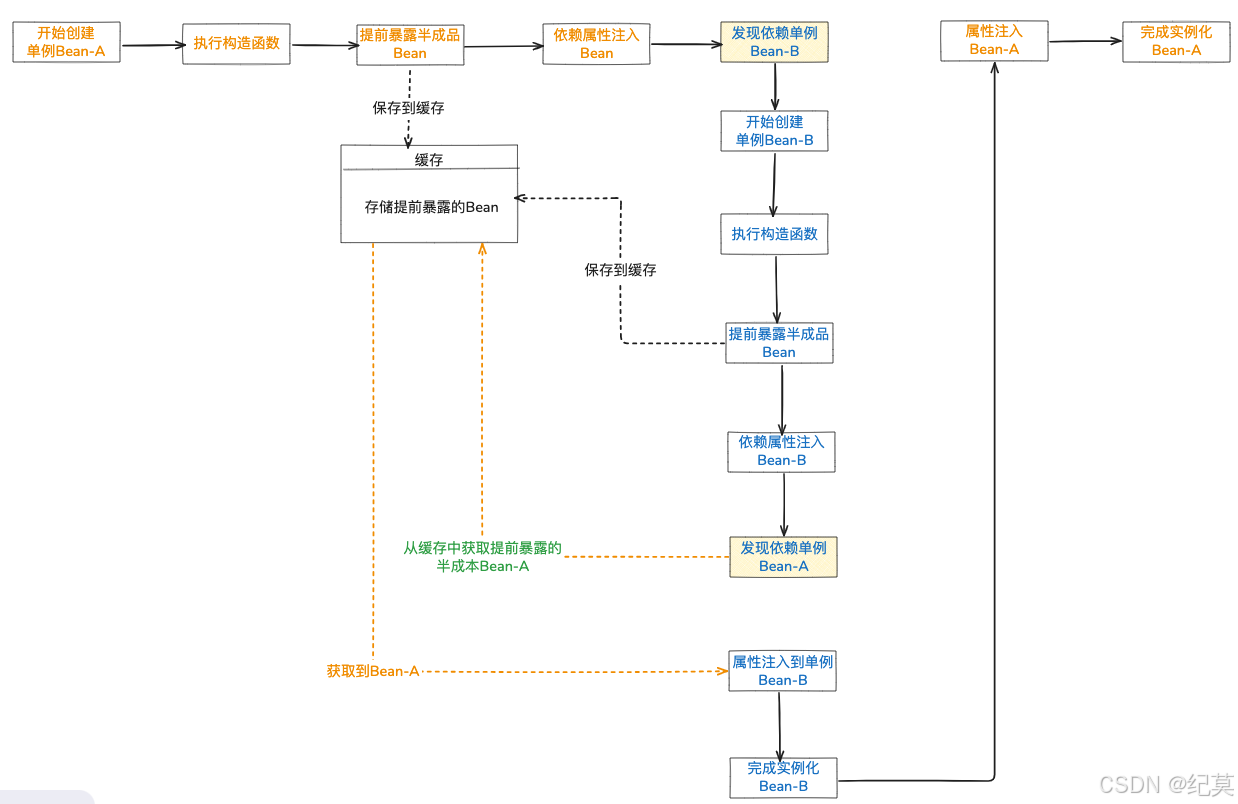
步骤一:创建Bean-A
- Spring 启动创建 Bean-A 的流程。在实例化(
instantiateBean)之后,属性注入(populateBean)之前,Spring 会将一个ObjectFactory(工厂)放入 三级缓存 (singletonFactories)。 - 这个
ObjectFactory的作用是:当被调用时,可以返回 Bean-A 的一个早期引用(通常是原始对象,或者如果需要AOP,则是一个代理对象)。
步骤二:创建 Bean-A 的依赖 (Bean-B)
- Spring 开始为 Bean-A 注入属性,发现需要 Bean-B。
- 检查一级缓存 (
singletonObjects),没有找到 Bean-B。 - 检查二级缓存 (
earlySingletonObjects),也没有。 - 检查三级缓存 (
singletonFactories),同样没有 Bean-B。
因此,Spring 开始创建 Bean-B。
步骤三:开始创建 Bean-B
- Bean-B 被实例化。
- 同样地,Spring 将一个用于创建 Bean-B 早期引用的
ObjectFactory放入 三级缓存。
步骤四:创建 Bean-B 的依赖 (Bean-A)
- Spring 开始为 Bean-B 注入属性,发现需要 Bean-A。
- 检查一级缓存,没有完整的 Bean-A。检查二级缓存,没有。
- 检查三级缓存,发现存在 Bean-A 的 ObjectFactory!
- Spring 调用这个
ObjectFactory.getObject()方法。 - ObjectFactory 执行其逻辑(通常会调用
getEarlyBeanReference()),返回 Bean-A 的一个早期引用。 - 这个早期引用被放入 二级缓存 (
earlySingletonObjects),同时从三级缓存中移除对应的工厂。 - Spring 将这个早期引用的 Bean-A 注入到 Bean-B 中。
步骤五:完成 Bean-B 的创建
- Bean-B 完成属性注入和初始化。
- 完全初始化好的 Bean-B 被放入 一级缓存 (
singletonObjects)。 - 从二级缓存中移除 Bean-B 的早期引用。
步骤六:回到 Bean-A 的创建
- 现在 Bean-B 已经创建完毕并放入一级缓存。
- Spring 继续为 Bean-A 注入属性,需要 Bean-B。
- 直接从 一级缓存 中获取到完整的 Bean-B,注入到 Bean-A 中。
- Bean-A 完成后续的初始化流程。
- 完全初始化好的 Bean-A 被放入 一级缓存 (singletonObjects)。
- 此时,Bean-A 和 Bean-B 都已创建完毕,循环依赖成功解决。
解决循环依赖一定要三级缓存吗?
其实理论上,一级加二级缓存就可以解决简单场景的单例Bean的循环依赖,但是三级缓存的设计还涉及到更丰富场景的支持,例如:支持AOP(动态代理)的代理对象的提前暴露。
如果只有二级缓存:在 Bean-A 实例化后,直接将其原始对象放入二级缓存。当 Bean-B 需要时,直接从二级缓存拿到原始的 Bean-A。
如果 Bean-A 需要被 AOP 代理(例如添加事务),那么最终放入一级缓存的应该是 代理对象,而不是原始对象。
但如果二级缓存里已经存了原始对象,那么 Bean-B 拿到的就是原始对象,这就导致了 不一致性:Bean-B 持有的是原始对象,而其他地方(一级缓存)持有的是代理对象。
即便没有 AOP,三级缓存的设计也有其必要性。它通过 ObjectFactory 延迟暴露早期引用,确保 Spring 可以在需要时介入生成代理或执行后置处理器,而不仅仅是直接返回原始对象。
Spring默认支持循环依赖吗
这个是看具体版本而言的,在SpringBoot2.6之前是默认支持循环依赖的,但是从Spring Boot 仍支持循环依赖,但变为可配置项,且默认关闭,也就是说从SpringBoot2.6以后是默认不支持循环依赖的,如果启动时存在循环依赖,这个配置未打开,是会报错的。
虽然默认不再支持循环依赖,但是我们可以通过以下方式开启对循环依赖的支持。
- 在配置文件中加入此配置
spring.main.allow-circular-references=true - 用
@Lazy注解,在@Autoired地方增加即可。
Spring 团队已明确表示 未来可能彻底移除循环依赖支持,建议开发者避免依赖此机制
Spring和SpringBoot的区别
Spring 和 SpringBoot 是 Java 生态中非常重要的两个框架,它们密切相关,但定位和目标不同。
简单来说,Spring 是一个功能强大的基础框架,而 SpringBoot 是建立在 Spring 之上的“脚手架”工具,旨在简化 Spring 应用的开发和部署。
以下几点是SpringBoot在Spring的基础上做的最主要的几点来提升开发效率与降低开发成本:
- 自动配置,SpringBoot通过
Auto-Configuration来减少开发人员的配置工作。可以通过引入一个starter一次性引入所需的所有依赖,使开发人员可以更专注于业务逻辑而不是配置。 - 内嵌Web服务器,SpringBoot内置了常见的Web服务器(如Tomcat、Jetty),这意味着您可以轻松创建可运行的独立应用程序,而无需外部Web服务器。
- 约定大于配置,SpringBoot中有很多约定大于配置的思想的体现,通过一种约定的方式,来降低开发人员的配置工作。如他默认读取
spring.factories来加载starter、读取application.properties或application.yml文件来进行属性配置等。
更详细的区别
| 特性 | Spring | SpringBoot |
|---|---|---|
| 核心定位 | 一个全面的、基础的 Java 框架,提供企业级应用开发的核心功能(如依赖注入、面向切面编程) | Spring 框架的扩展,专注于简化 Spring 应用的开发和配置,实现"开箱即用" |
| 配置方式 | 需要大量手动配置(XML 或 Java 配置类),例如: - 配置数据源 - 配置 MVC 分发器 - 配置事务管理 | 通过自动配置(Auto-Configuration)机制,根据 classpath 中的依赖自动配置应用,只需少量配置(如 application.properties) |
| 依赖管理 | 需要手动管理所有 Spring 模块(如 spring-core, spring-webmvc)和其他第三方库的版本,容易出现版本冲突 | 通过起步依赖(Starter Dependencies)简化依赖管理: - 例如 spring-boot-starter-web 自动引入 Spring MVC、Tomcat 等所有必要依赖- Spring Boot 的父 POM 管理了所有依赖版本,确保兼容性 |
| 内嵌服务器 | 传统 Spring 应用需要将应用打包成 WAR 文件,部署到外部 Servlet 容器(如 Tomcat、Jetty) | 内置了 Tomcat、Jetty 或 Undertow 等 Web 服务器,应用可打包成可执行 JAR 文件,通过 java -jar 直接运行 |
| 开发效率 | 需要大量基础配置工作,初始搭建速度较慢 | 极大提高开发效率,开发者可以专注于业务逻辑,无需关注基础配置 |
| 监控与管理 | 需要自行集成健康检查、指标收集等功能 | 通过 Spring Boot Actuator 提供开箱即用的生产级监控功能: - 健康检查( health)- 指标收集( metrics)- 外部化配置( configprops)- 环境信息( env) |
| 适用场景 | 适合需要高度定制化、复杂配置的大型企业级应用 | 适合快速开发微服务、RESTful API、需要快速迭代的中小型项目,是构建现代云原生应用的首选 |