25-DAPO: An Open-Source LLM Reinforcement LearningSystem at Scale
目录
相关算法:
PPO:
Group Relative Policy Optimization (GRPO)
本文提出的DAPO:
改进策略:
Removing KL Divergence
CLip-Higer
Dynamic Sampling
Token-Level Policy Gradient Loss
Overlong Reward Shaping
实验结果:
编辑
总结:
反思与回溯行为
本文对grpo方法的训练过程以及细节进行了细致分析,并给出了针对各个组件针对性的改进意见,对GRPO算法出现的entropy collapse,reward noise,training instability来提升训练稳定性以及模型效果
相关算法:
PPO:

Group Relative Policy Optimization (GRPO)
loss计算方式:基于每个sample生成的序列计算组内的loss,再计算不同样本loss之间的均值

本文提出的DAPO:

其中约束条件为:与答案 a 等价的输出 oi 的数量,必须大于 0 且小于 G(即不能为 0,也不能等于总采样数 G)。
改进策略:
Removing KL Divergence
理由:
However, during training the long-CoT reasoning model, the model distribution can
diverge significantly from the initial model, thus this restriction is not necessary.
CLip-Higer
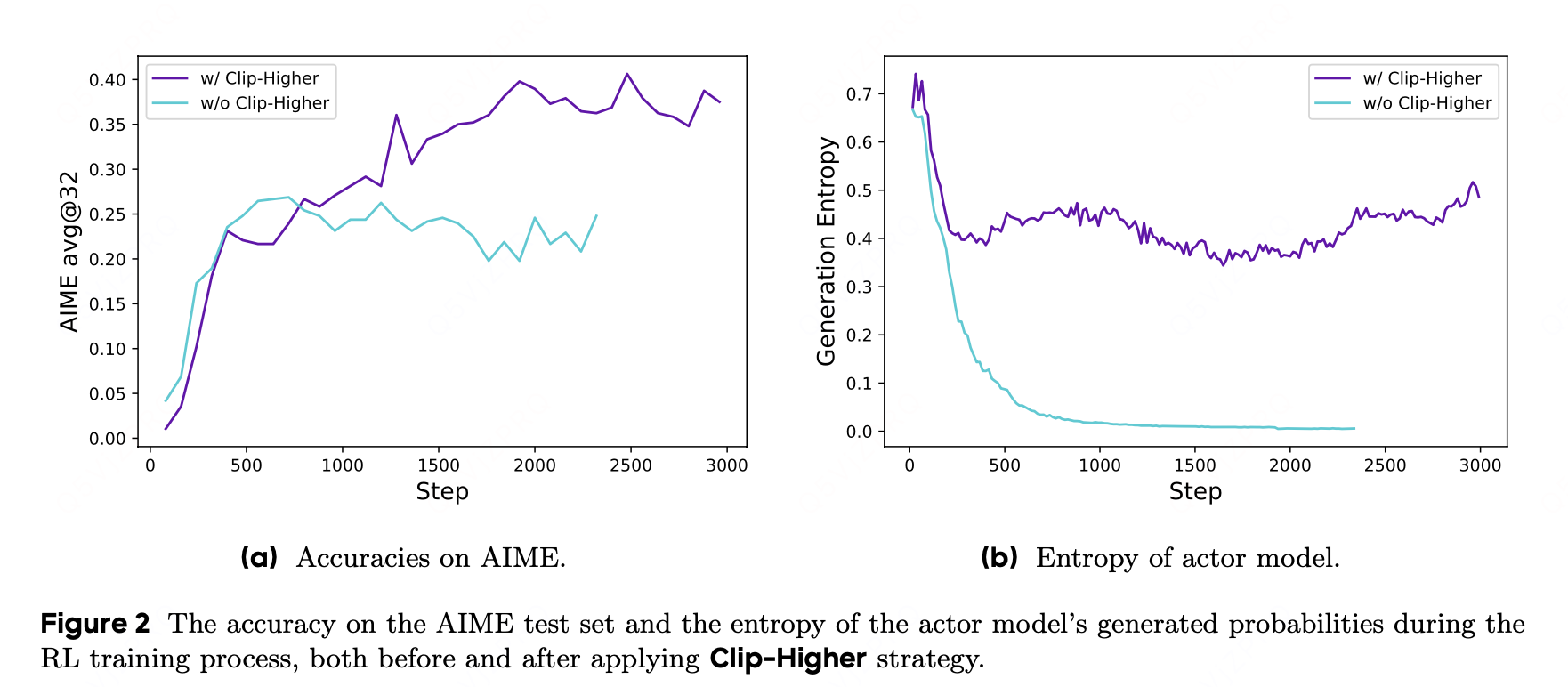
上截断(upper clip)会限制策略的探索能力:在这种情况下,提高 “利用性(exploitation)token” 的概率会容易得多,而那些不太可能被选中的 “探索性(exploration)token” 的概率却受到过于严格的约束,难以得到提升。
- ε(epsilon):PPO 中控制策略更新幅度的超参数,默认 0.2 表示策略新老概率比的允许范围为 [0.8, 1.2](即 1±ε)。
- 核心矛盾:高概率 token(如 0.9)的上限 1.08 实际可宽松到 1.0(概率最大为 1)(
),几乎无约束;而低概率 token(如 0.01)的上限仅 0.012,提升空间被严重压缩,导致模型难以探索潜在的优质低概率选项。
- 实验佐证:图 3a 显示被截断的 token 本身概率就低于 0.2,进一步说明上截断主要抑制了低概率探索行为,而非高概率利用行为。
解释:
-
上截断的规则与现象PPO 通过参数 ε(默认 0.2)限制新策略与旧策略的概率比值,即新策略概率≤旧策略概率 ×(1+ε)。当系统想提高某个动作的概率(Âi,t >0)时:
- 对于高概率的 “利用性 token”(如旧概率 0.9),其概率上限为 0.9×1.2=1.08,但实际概率最大只能到 1.0,几乎没有约束,因此可以轻松提升到 0.999 等极高值;
- 对于低概率的 “探索性 token”(如旧概率 0.01),其上限仅为 0.01×1.2=0.012,提升空间被严重压缩,很难实现显著增长。
-
实验证据实验观察到:被上截断机制限制的 token,其本身的概率普遍较低(πθ(oi|q) < 0.2)。这说明上截断主要影响的是那些低概率的 “探索性 token”,而高概率的 “利用性 token” 几乎不受限。
-
结论上截断机制虽然能稳定训练,但会抑制策略对低概率选项的探索 —— 模型更倾向于 “利用” 已知的高概率有效行为,而难以 “探索” 那些当前概率低但可能更优的新行为,最终可能限制系统的探索能力和找到更优解的潜力。
简单来说,就是 PPO 的上截断让模型 “守旧容易、创新难”,不利于探索新的可能性。
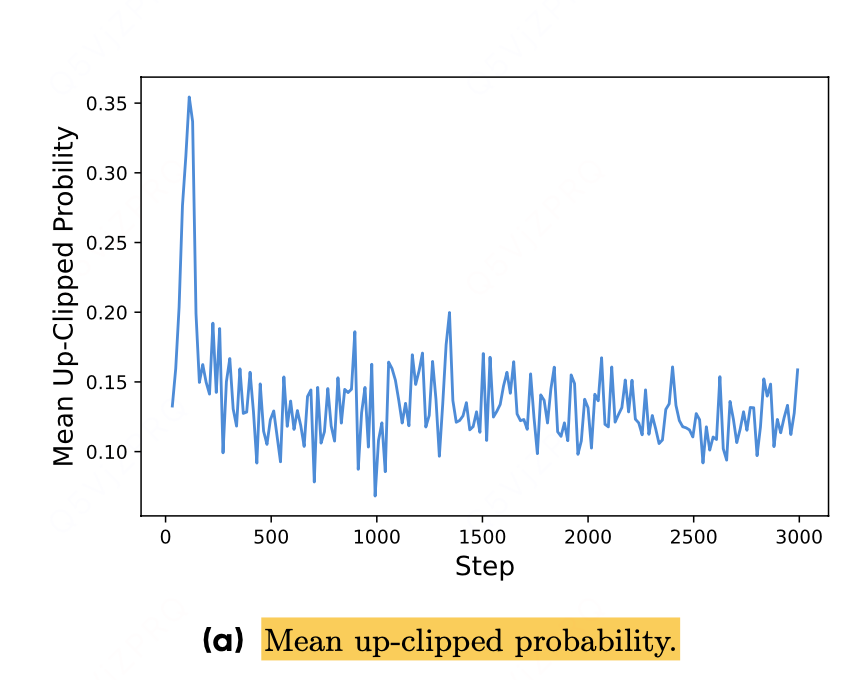
提高εhigh,这一调整有效提高了策略的熵值,进而有助于生成更多样化的样本。我们保持εlow参数不变,因为增大该参数会将这些token的概率抑制至0,最终导致采样空间坍缩。
Dynamic Sampling
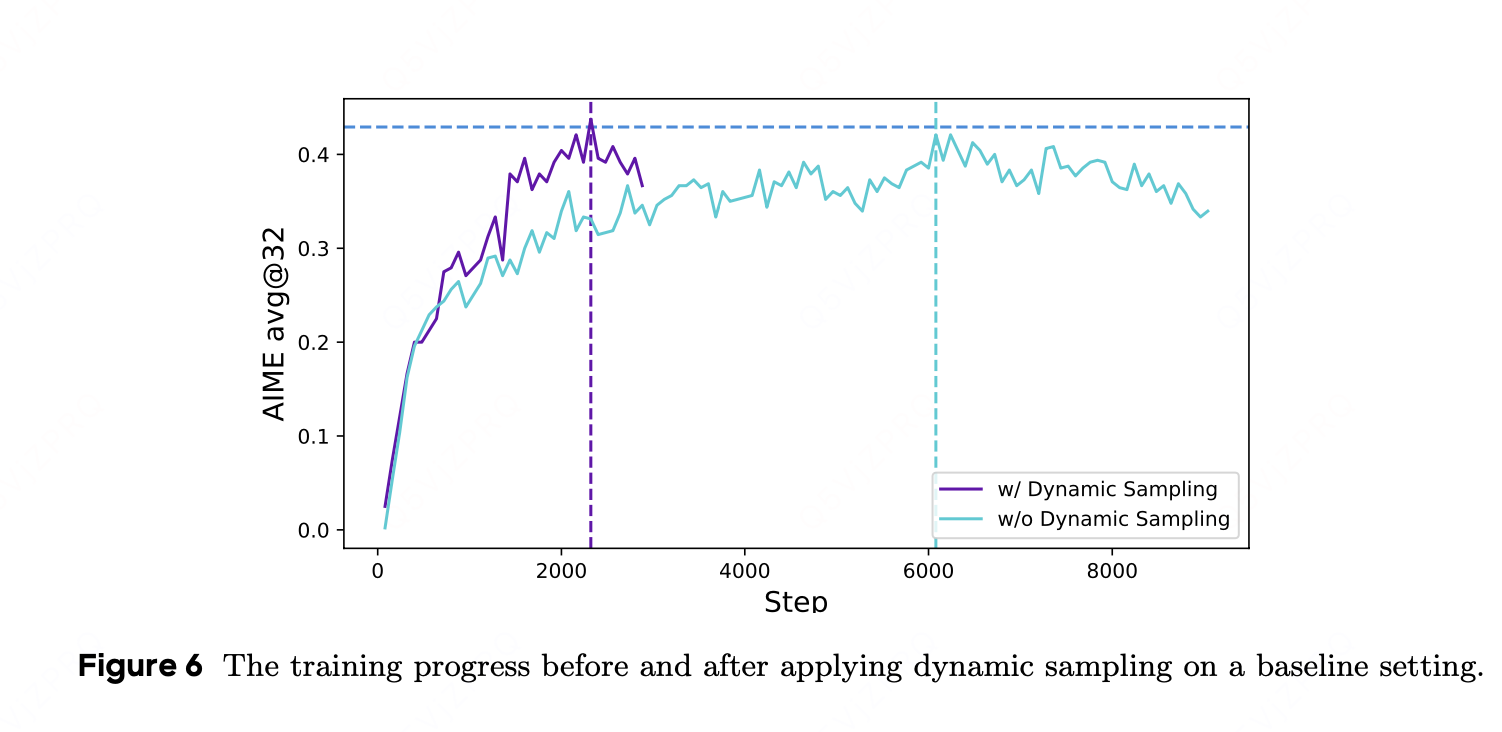
• 在长链推理中,若一个样本组中所有输出都完全正确(奖励为 1)或全部错误(奖励为 -1),则其优势函数会被“平均化”为 0,导致本轮该组数据对训练无贡献。
• DAPO 中,会额外采样并过滤掉这些全对/全错的组样本,使得最终保留下来的 batch 都是带有正负混合的奖励,为策略梯度提供实质训练信号,从而提升样本利用率。
虽然动态采样增加了采样成本,但是总step减少,并没有降低训练效率。
Token-Level Policy Gradient Loss
原始 GRPO 算法采用样本级损失计算方式,先对每个样本内的 token 损失进行平均,再对所有样本的损失进行聚合。在这种方法中,每个样本在最终损失计算中被赋予同等权重。但我们发现,在长思维链(long-CoT)强化学习场景下,这种损失归约方式会带来若干问题。
由于所有样本在损失计算中权重相同,较长响应(包含更多 token)中的 token 对总损失的贡献可能会不成比例地降低,进而导致两个不利影响。
第一,对于高质量的长样本,这种影响会阻碍模型学习其中与推理相关的模式。
第二,我们观察到,过长的样本往往会呈现出低质量模式,例如无意义内容和重复词汇。因此,样本级损失计算无法有效惩罚长样本中的这些不良模式,最终导致熵值和响应长度出现非良性增长,如图 4a 和图 4b 所示。(样本级别loss无法显示出样本的长度)
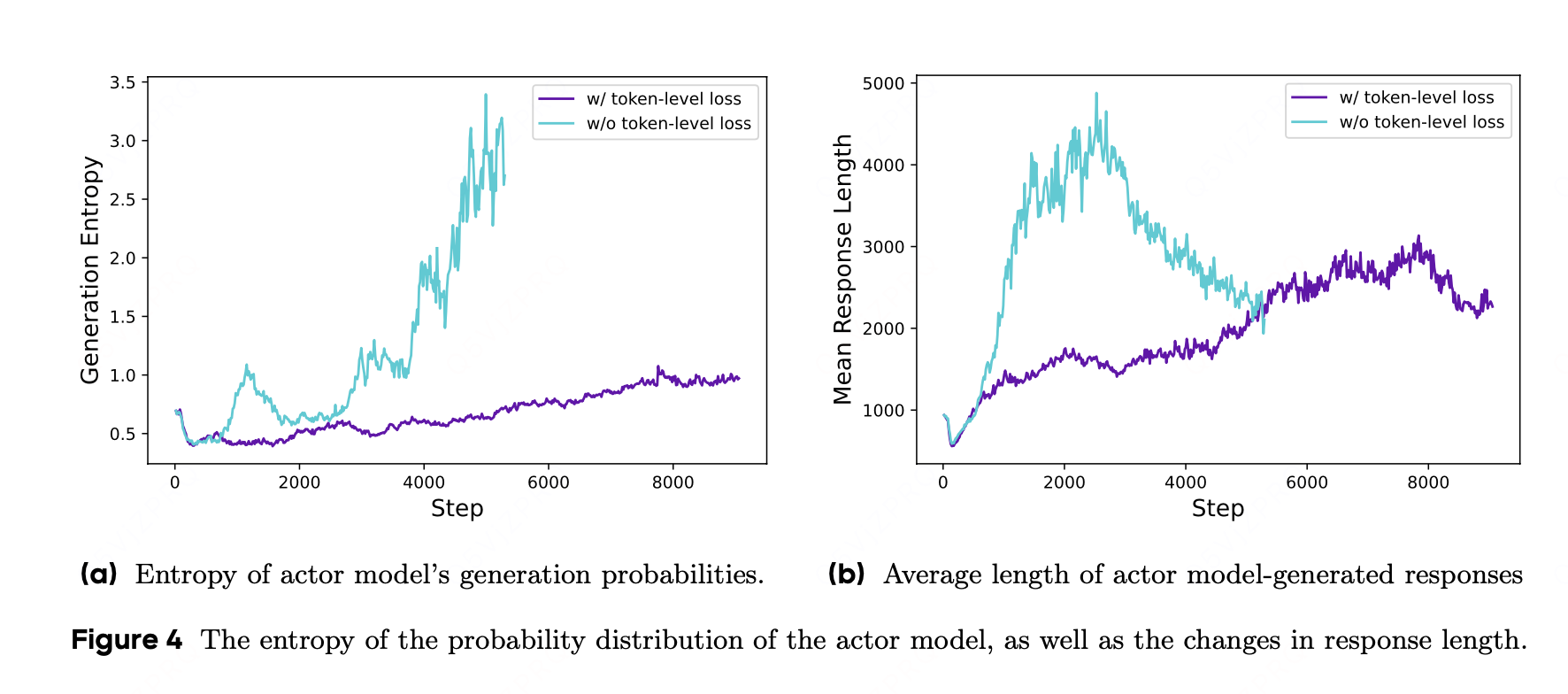
在该设置下,与较短序列相比,较长序列对整体梯度更新的影响可能更大。此外,从单个 token 的角度来看,若某种特定生成模式会导致奖励增加或减少,无论其出现在多长的响应中,该模式都会受到同等程度的促进或抑制。
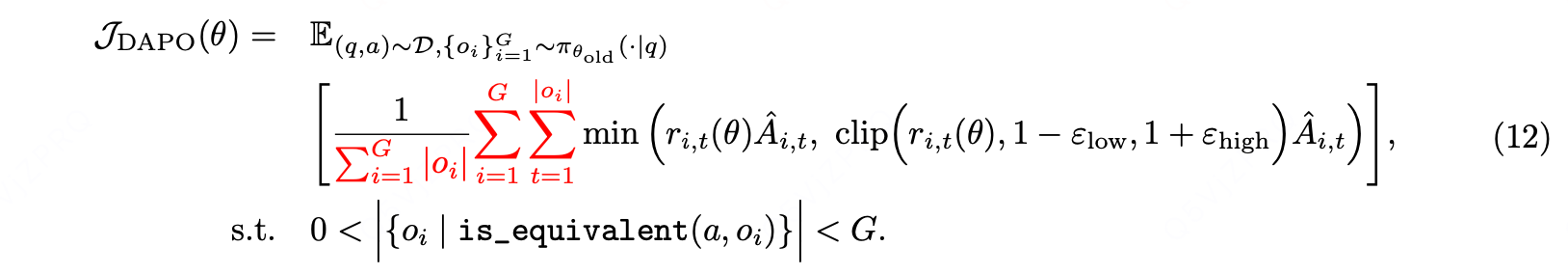
Overlong Reward Shaping
我们提出了 “软超长惩罚(Soft Overlong Punishment)” 机制(公式 13),这是一种基于长度的惩罚机制,用于调整对被截断样本的奖励。具体而言,当响应长度超过预定义的最大值时,我们设定了一个惩罚区间:在该区间内,响应越长,所受惩罚越大。这一惩罚会被叠加到基于规则的原始正确性奖励上,从而向模型传递 “避免过长响应” 的信号。
奖励函数定义如下:
- 当响应长度 | y|≤Lmax−Lcache 时,Rlength (y)=0(无惩罚);
- 当 Lmax−Lcache<|y|≤Lmax 时,Rlength (y)=[(Lmax−Lcache)−|y|]/Lcache(线性递增惩罚,长度越接近 Lmax,惩罚越大);
- 当 | y|>Lmax 时,Rlength (y)=−1(最大惩罚,固定值)。
优势:
相比 “一刀切” 的截断惩罚(如只要超长就固定扣分),这种 “软惩罚” 更细腻 —— 既约束了过度超长的问题,又减少了对 “合理长响应” 的误伤,避免模型因恐惧惩罚而过度压缩有效推理步骤
结合路径规划场景举例:若 Lmax=100(最大步骤),Lcache=20,则 80 步以内的路径无惩罚;81-100 步的路径随长度增加惩罚递增;超过 100 步的路径直接扣 1 分。这既允许模型在复杂环境中生成稍长的合理路径,又防止路径冗余过长。
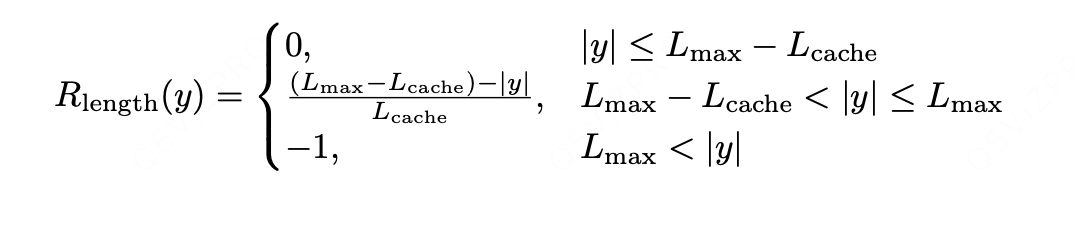
实验结果:
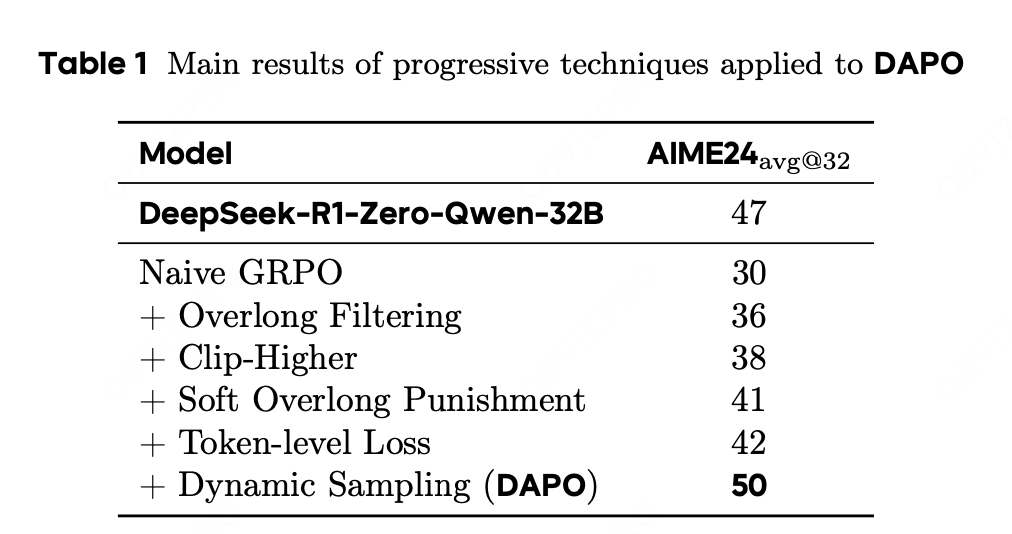
对于 token 级损失而言,尽管它带来的性能提升较为有限,但我们发现它能增强训练的稳定性,并使长度增长更为健康。
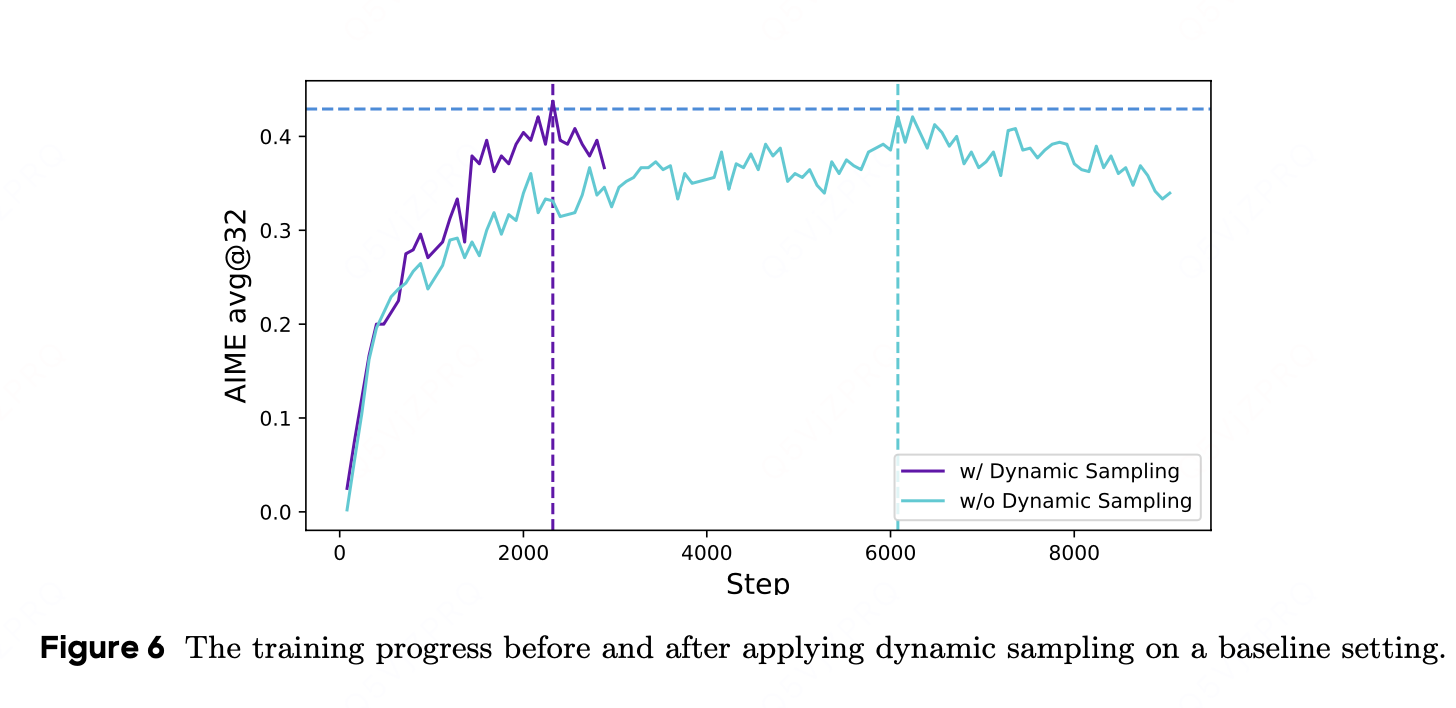
在应用动态采样时,尽管由于过滤掉零梯度数据而需要采样更多数据,但整体训练时间并未受到显著影响。如图 6 所示,虽然采样实例的数量有所增加,但由于所需的训练步骤减少,模型的收敛时间反而缩短了。
总结:
在大型语言模型上应用强化学习不仅是一个前沿研究方向,更是一项本质复杂的系统工程挑战,其特点是各个子系统之间存在相互依赖关系。对任何单个子系统的修改都可能在整个系统中传导,由于这些组件之间的复杂相互作用,可能导致不可预见的后果。即使是初始条件中看似微小的变化(如数据和超参数的差异),也可能在迭代式强化学习过程中被放大,最终导致结果出现显著偏差。这种复杂性常常使研究人员陷入困境:即使经过细致分析并有理有据地预期某项修改会改善训练过程的特定方面,实际结果也往往与预期轨迹不符。因此,在实验过程中监控关键中间结果至关重要,这有助于快速定位差异来源,并最终实现系统的优化。
生成响应长度(Length of Generated Responses)
训练过程中的奖励动态(Dynamics of Reward)
Actor 模型的熵与生成概率(Entropy of the Actor Model and Generation Probability)
反思与回溯行为
在强化学习训练过程中,我们观察到一个有趣的现象:Actor 模型的推理模式会随时间动态演变。具体来说,算法不仅会强化那些有助于正确解决问题的现有推理模式,还会逐渐催生出原本不存在的全新推理模式。这一发现揭示了强化学习算法的适应性与探索能力,也为理解模型的学习机制提供了新视角。
例如,在模型训练初期,几乎不存在对先前推理步骤的检查与反思行为;但随着训练推进,模型展现出了明显的反思与回溯行为,如表 2 所示。这一观察为进一步探索强化学习过程中推理能力的涌现机制提供了方向,我们将其留作未来的研究内容。
